
B站热门榜单爬虫+可视化(详细过程和解释)
数据爬取和保存数据分析和可视化及页面展示和保存
系统功能模块划分
①数据爬取和保存
②数据分析和可视化
③页面展示和保存
(2)各功能模块的算法处理流程图及相关说明
①数据爬取和保存
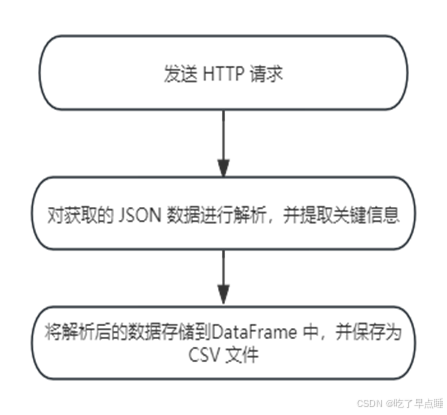
图2.1 数据爬取和保存(流程)
使用 requests 库发送 HTTP 请求,获取指定B站排行榜的数据。
对获取的 JSON 数据进行解析,并提取关键信息如视频标题、播放数、弹幕数等。
将解析后的数据存储到 Pandas 的 DataFrame 中,并保存为 CSV 文件,便于后续数据分析和处理。
②数据分析和可视化
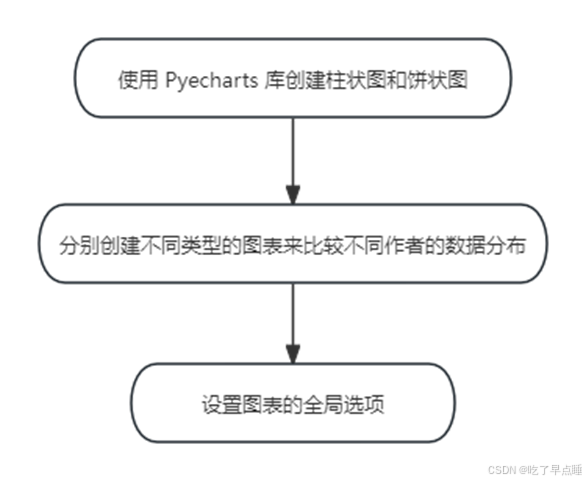
图2.2 数据分析和可视化(流程)
使用 Pyecharts 库创建柱状图、柱状图和饼状图,展示视频的播放数、弹幕数、投币数、点赞数、分享数和收藏数的分布情况。
分别创建不同类型的图表来比较不同作者的数据分布,例如播放数的分布、弹幕数的分布等。
设置图表的全局选项,如标题、轴标签的旋转角度等,以美化图表呈现效果。

图2.3 页面展示和保存(流程)
使用 Pyecharts 的 Page 类创建页面实例,通过 add 方法将所有图表添加到同一个页面中。
最终将整个页面保存为 HTML 文件,便于在浏览器中查看和分享分析结果。
详细设计
导入python相关的库和模块,用于数据处理和可视化
在cmd中输入pip install 库名来先配置相应的库到python中
若下载过慢可添加国内的镜像源来进行下载
出现如图所示页面后说明相应库已经配置完成

然后导入相应的库比如
pandas:用于数据操作和分析,特别是数据表格的创建、修改和存储,以及对数据进行统计和计算
- requests:用于发送HTTP请求,主要用来获取网页数据
- pyecharts;一个基于Echarts实现的python可视化库,可以生成多种图表,包括柱状图(Bar)、饼状图(Pie)
其中具体模块的作用如下:
- options:提供用于配置图标选项的类和方法,例如标题设置、轴标签设置等
- charts:提供了各种图表的类,例如Bar和Pie,用于创建不同类型的图表实例
- Page:提供了页面管理的类,可以将多个图表组合到一个页面中,并进行统一管理和展示
借助字典dict[],创建url_dict: 包含了不同视频类别对应的API链接。每个键值对表示一个视频类别(全站、舞蹈、美食)和对应的API链接。

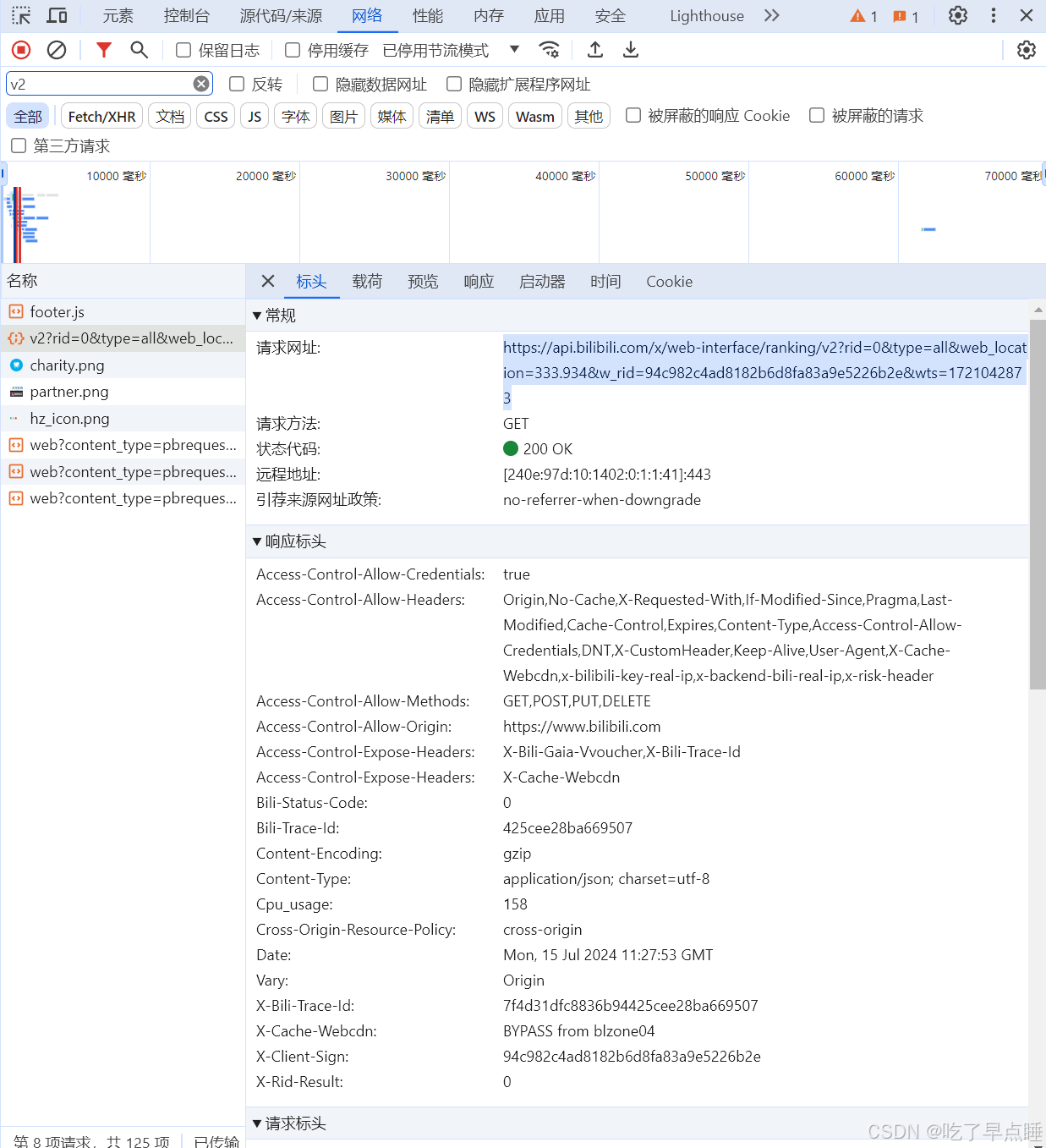
寻找相应APIi链接的步骤,打开相应的网页
在空白处点击鼠标右键,后选择审查元素,打开如下界面,选择其中的网络,记住要按F5进行刷新,然后筛选处对v2进行筛选
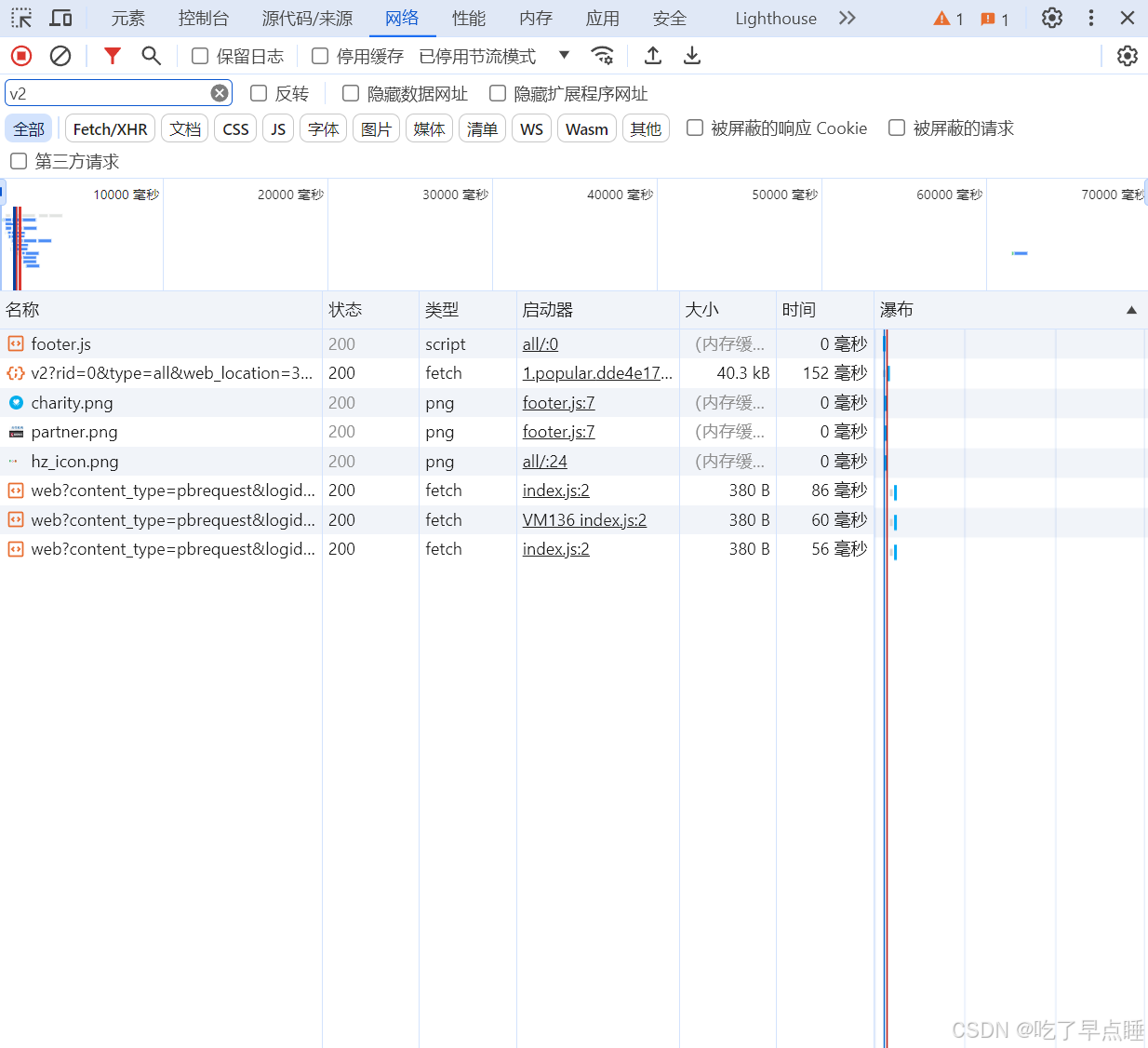
复制其中相应的请求网址即可
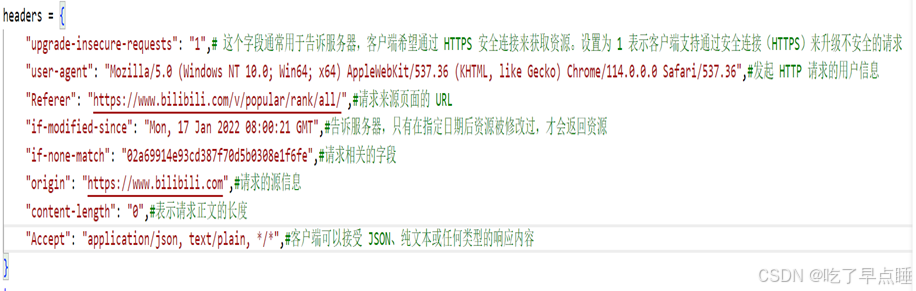
headers: 包含了请求的头部信息,用于模拟浏览器发起请求。其中包括了
“upgrade_insecure-requests”:”1”是一个HTTP请求头部字段,用于指示客户端希望通过安全连接(HTTPS)来获取资源,设置为1,表示客户端支持通过安全连接来升级不安全的请求
用户代理(user-agent)用于描述发起HTTP请求的用户信息
预期修改时间(if-modified-since)用于告诉服务器,只有在指定日期后资源被修改过的才会返回资源
“if-none-match”:将之前获取资源时的 ETag 发送给服务器。如果服务器端的资源的当前 ETag 与客户端提供的 ETag 相匹配(即资源未发生变化),服务器可能会返回状态码 304 Not Modified,并且不返回实际内容,而是建议客户端使用本地缓存的副本。
请求的源信息(origin)用于指示请求的源信息
"content-length": "0"由于由对B站网页进行检索,发现为GET请求所以设置’content-length’为0
"Accept"用于指定客户端能都接受的响应内容类型
之后通过使用 Python 中的 requests 库向Bilibili的排行榜API发送 GET 请求,并传递了自定义的请求头部信息 headers,以此来获取每个类别的排名数据,并且抛出发出HTTP请求后响应的状态码来进行异常检测,使用r.json()方法来将其转换为Python对象

通过遍历循环一个包含字典中所有键值对的视图对象,来读取相应的排行榜名称和相应的API请求地址,初始化相应的空列表
title_list = []
play_cnt_list = [] # 播放数
danmu_cnt_list = [] # 弹幕数
coin_cnt_list = [] # 投币数
like_cnt_list = [] # 点赞数
share_cnt_list = [] # 分享数
favorite_cnt_list = [] # 收藏数
author_list = []
video_url = []
这些列表来存储从API中返回的数据中提取出的各种信息,如视频标题,播放数,弹幕数等等
提取JSON数据中data下的list并遍历其中的每个条目,将所需的信息逐个田添加到相应的列表中,添加时应注意在B站的视频数据结构中存在相应的存放视频统计信息的字典,例如data[‘stat’]是B站中存放播放量,弹幕数,投币数,点赞数,分享数还有收藏数的结构,在B站(哔哩哔哩)的视频平台中,每个视频都有一个唯一的标识符,称为 BV号(Bilibili Video号)。BV号是B站内部用于标识视频的一种编码格式video_url.append('https://www.bilibili.com/video/' + data['bvid']) 的作用是将每个视频的完整播放页面URL添加到 video_url 列表中,以便后续使用
使用Pandas创建DataFrame,列名和数据从之前收集的列表中提取,使用 to_csv() 方法将 DataFrame 中的数据采取‘utf_8_sig’的方式解码,保存到 CSV 文件中,文件名格式为 'B站TOP100-{}.csv'.format(tab_name)。
使用pd.read_csv()方法从相应的csv文件中读取熟读到DataFrame’df’中,提取前15行数据,并将所需的列借助tolist()方法转换为列表
创建柱状图 bar:
使用 pyecharts 的 Bar() 方法创建一个柱状图实例。
使用 .add_xaxis() 添加 X 轴数据(视频标题)。
使用 .add_yaxis() 添加多个 Y 轴数据(播放数、弹幕数、投币数、点赞数、分享数、收藏数)。
使用 .set_global_opts() 设置全局选项,包括标题和轴标签的旋转角度。

创建饼状图 pie_play_counts 到 pie_favorite_counts:
使用 pyecharts 的 Pie() 方法分别创建多个饼状图实例。
使用 .add() 方法添加饼状图的数据,每个饼状图代表不同的数据(播放数、弹幕数、投币数、点赞数、分享数、收藏数)。
使用 .set_global_opts() 设置全局选项,包括标题、图例的位置等。

使用 .set_series_opts() 设置系列选项,包括标签格式化等。
创建页面实例 page:
使用 pyecharts 的 Page() 方法创建一个页面实例。
使用 .add() 方法将各个图表(柱状图和饼状图)添加到页面中。
保存为 HTML 文件:
使用 .render() 方法将页面实例 page 保存为名为 "video_stats.html" 的 HTML 文件。
这样,最终生成的 HTML 文件包含了多个图表,展示了不同作者在各项指标(播放数、弹幕数、投币数等)上的数据分布情况。
测试部分


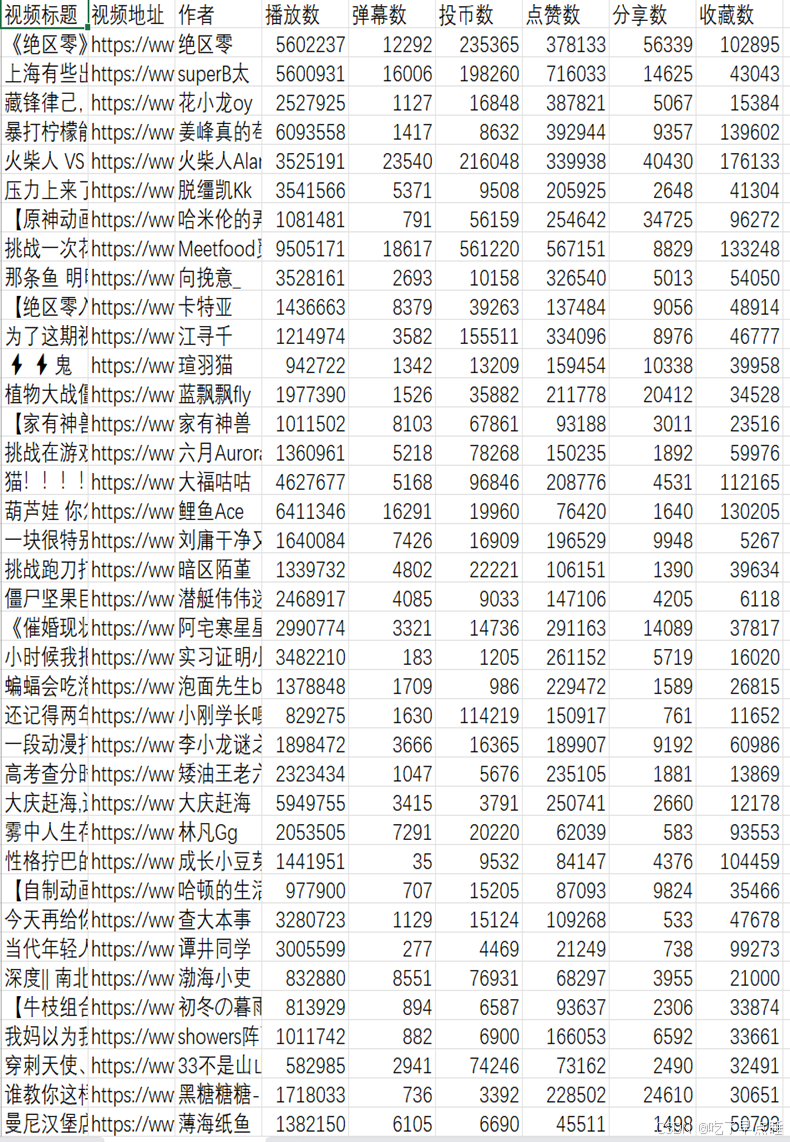 图B站TOP100-全站的一部分数据
图B站TOP100-全站的一部分数据
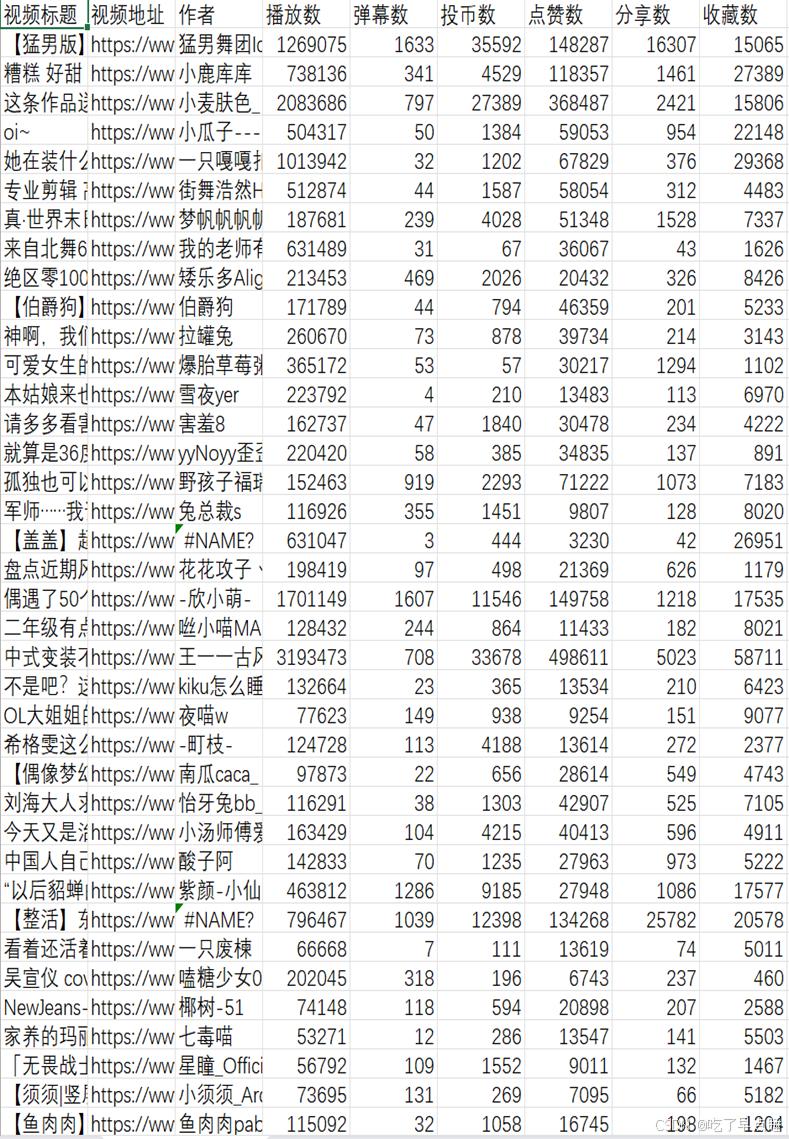 图 B站TOP100-舞蹈的一部分数据
图 B站TOP100-舞蹈的一部分数据
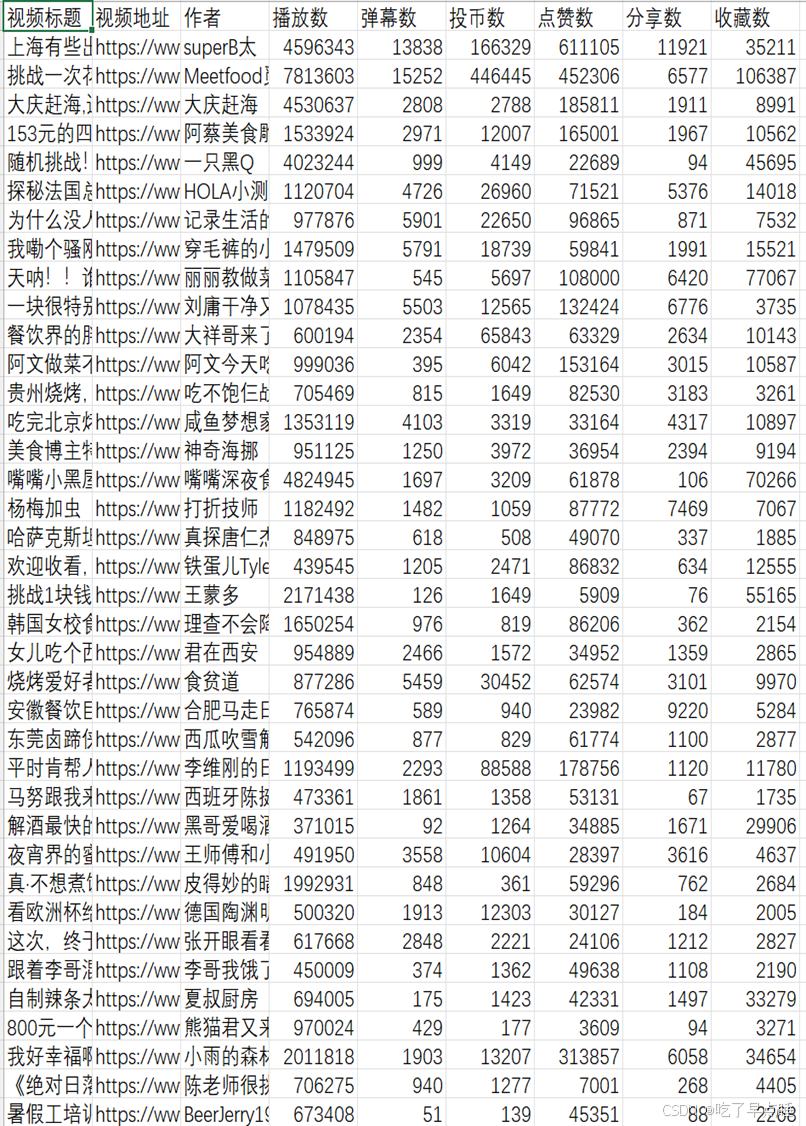 图B站TOP100-美食的一部分数据
图B站TOP100-美食的一部分数据
系统可视化分析
可视化效果
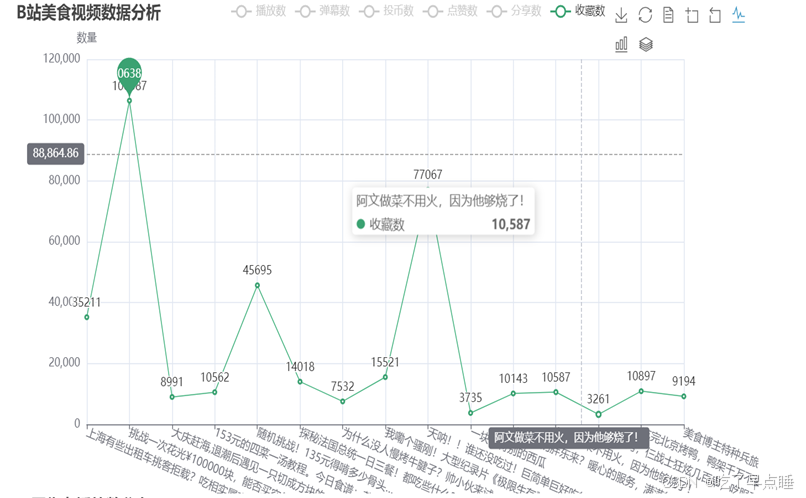
可通过右上的工具箱进行切换,实现柱状图和折线图的变换
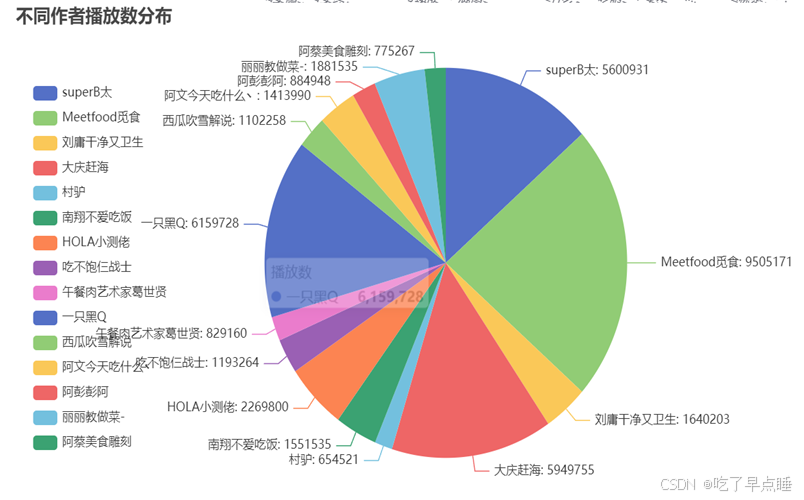
这是相应的饼状图,以作者名和播放数作为相应的元素
结果分析
由图表的可视化可知,在同类型的视频创作区中,不同作者的视频之间播放数,点赞数,收藏数,投币数,分享数有着较大的差异,排名的高低并不单单取决于其中的一项要素,更多的是整体的一个体现,一些知名的作者或拥有庞大粉丝基础的作者,其视频通常会有更高的观看量和互动数。他们的粉丝可能会更积极地点赞、收藏、投币和分享他们的视频,视频的内容质量和创意度是影响观众反馈的关键因素。高质量、独特或创新的内容往往能够吸引更多的观众,导致更高的播放量和点赞数,视频的互动性和是否能够引发社区讨论也是影响数据差异的因素。有些视频可能因为能够引发更多的评论和分享而表现突出。某些视频可能会因为抓住了时事热点或者社会趋势而获得更高的关注度和互动。同时,B站的推荐算法和推广机制对视频的曝光度有重要影响。一些视频可能因为被推荐给更多用户而获得更多的点击和互动。
附源码
1. import pandas as pd
2. import requests #发送请求
3. from pyecharts import options as opts
4. from pyecharts.charts import Bar,Pie,Page,Line
5.
6. url_dict = {
7. '全站': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all&web_location=333.934&w_rid=c5046c294974de7965582b20effeb091&wts=1719974349',
8. '舞蹈': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=129&type=all&web_location=333.934&w_rid=59e54bf82843f0ec91ddd94fbde7c187&wts=1719974376',
9. '美食': 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=211&type=all&web_location=333.934&w_rid=7489502d668486df34495219ca561d80&wts=1719974434',
10. }
11. headers = {
12. "upgrade-insecure-requests": "1",# 这个字段通常用于告诉服务器,客户端希望通过 HTTPS 安全连接来获取资源。设置为 1 表示客户端支持通过安全连接(HTTPS)来升级不安全的请求
13. "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36",#发起 HTTP 请求的用户信息
14. "Referer": "https://www.bilibili.com/v/popular/rank/all/",#请求来源页面的 URL
15. "if-modified-since": "Mon, 17 Jan 2022 08:00:21 GMT",#告诉服务器,只有在指定日期后资源被修改过,才会返回资源
16. "if-none-match": "02a69914e93cd387f70d5b0308e1f6fe",#请求相关的字段
17. "origin": "https://www.bilibili.com",#请求的源信息
18. "content-length": "0",#表示请求正文的长度
19. "Accept": "application/json, text/plain, */*",#客户端可以接受 JSON、纯文本或任何类型的响应内容
20. }
21. try:
22. r = requests.get(url_dict, headers=headers)
23. r.raise_for_status() # 如果请求不成功,抛出异常
24. print(r.status_code)
25. json_data = r.json()
26. list_data = json_data['data']['list']
27. # 继续处理数据
28. except requests.exceptions.RequestException as e:
29. print("请求失败:", e)
30. except KeyError as e:
31. print("数据解析失败:", e)
32.
33. for i in url_dict.items():
34. url = i[1] # url地址
35. tab_name = i[0] # tab页名称
36. title_list = []
37. play_cnt_list = [] # 播放数
38. danmu_cnt_list = [] # 弹幕数
39. coin_cnt_list = [] # 投币数
40. like_cnt_list = [] # 点赞数
41. share_cnt_list = [] # 分享数
42. favorite_cnt_list = [] # 收藏数
43. author_list = []
44. video_url = []
45. try:
46. r = requests.get(url, headers=headers)
47. print(r.status_code)
48. #获取目标数据所在数据并转成字典类型
49. json_data = r.json()
50. list_data = json_data['data']['list']
51.
52. for data in list_data:
53. title_list.append(data['title'])
54. play_cnt_list.append(data['stat']['view'])
55. danmu_cnt_list.append(data['stat']['danmaku'])
56. coin_cnt_list.append(data['stat']['coin'])
57. like_cnt_list.append(data['stat']['like'])
58. # dislike_cnt_list.append(data['stat']['dislike'])
59. share_cnt_list.append(data['stat']['share'])
60. favorite_cnt_list.append(data['stat']['favorite'])
61. author_list.append(data['owner']['name'])
62. # score_list.append(data['score'])
63. video_url.append('https://www.bilibili.com/video/' + data['bvid'])
64. # print('*' * 10)
65. except Exception as e:
66. print("爬取失败:{}".format(str(e)))
67. #创建dataframe保存数据
68. df = pd.DataFrame(
69. {'视频标题': title_list,
70. '视频地址': video_url,
71. '作者': author_list,
72. '播放数': play_cnt_list,
73. '弹幕数': danmu_cnt_list,
74. '投币数': coin_cnt_list,
75. '点赞数': like_cnt_list,
76. '分享数': share_cnt_list,
77. '收藏数': favorite_cnt_list,
78. })
79. #print(df.head())
80. #将数据保存到本地
81. df.to_csv('B站TOP100-{}.csv'.format(tab_name), index=False,encoding='utf_8_sig') # utf_8_sig修复乱码问题
82. print('写入成功: ' + 'B站TOP100-{}.csv'.format(tab_name))
83.
84. #读取csv文件
85. df = pd.read_csv('B站-美食.csv', encoding='utf-8')
86. df2 = df.iloc[:15]
87.
88. # 提取需要的数据列
89. video_titles = df2['视频标题'].tolist()
90. author_titles=df2['作者'].tolist()
91. play_counts = df2['播放数'].tolist()
92. danmu_counts = df2['弹幕数'].tolist()
93. coin_counts = df2['投币数'].tolist()
94. like_counts = df2['点赞数'].tolist()
95. share_counts = df2['分享数'].tolist()
96. favorite_counts = df2['收藏数'].tolist()
97.
98. # 创建折线图实例
99. line = Line()
100.
101. # 添加数据系列
102. line.add_xaxis(video_titles)
103. line.add_yaxis("播放数", play_counts, markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max")]))
104. line.add_yaxis("弹幕数", danmu_counts, markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max")]))
105. line.add_yaxis("投币数", coin_counts, markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max")]))
106. line.add_yaxis("点赞数", like_counts, markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max")]))
107. line.add_yaxis("分享数", share_counts, markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max")]))
108. line.add_yaxis("收藏数", favorite_counts, markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max")]))
109.
110. # 设置全局选项
111. line.set_global_opts(
112. title_opts=opts.TitleOpts(title="B站美食视频数据分析"),
113. xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-20)), # 旋转x轴标签
114. yaxis_opts=opts.AxisOpts(name="数量"),
115. legend_opts=opts.LegendOpts(pos_right="20%"), # 调整图例位置
116. tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross"), # 设置提示框触发方式和指示器类型
117. toolbox_opts=opts.ToolboxOpts(is_show=True), # 显示工具栏
118. )
119.
120. # 确保所有输入数据列表的长度相同
121. data_lengths = [len(author_titles), len(play_counts), len(danmu_counts), len(coin_counts), len(like_counts), len(share_counts), len(favorite_counts)]
122. assert len(set(data_lengths)) == 1, "所有数据列表的长度必须相同"
123.
124. # 创建饼状图
125. pie_play_counts = (
126. Pie()
127. .add("播放数", [list(z) for z in zip(author_titles, play_counts)])
128. .set_global_opts(title_opts=opts.TitleOpts(title="不同作者播放数分布"),
129. legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"))
130. .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
131. )
132.
133. pie_danmu_counts = (
134. Pie()
135. .add("弹幕数", [list(z) for z in zip(author_titles, danmu_counts)])
136. .set_global_opts(title_opts=opts.TitleOpts(title="不同作者弹幕数分布"),
137. legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"))
138. .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
139. )
140.
141. pie_coin_counts = (
142. Pie()
143. .add("投币数", [list(z) for z in zip(author_titles, coin_counts)])
144. .set_global_opts(title_opts=opts.TitleOpts(title="不同作者投币数分布"),
145. legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"))
146. .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
147. )
148.
149. pie_like_counts = (
150. Pie()
151. .add("点赞数", [list(z) for z in zip(author_titles, like_counts)])
152. .set_global_opts(title_opts=opts.TitleOpts(title="不同作者点赞数分布"),
153. legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"))
154. .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
155. )
156.
157. pie_share_counts = (
158. Pie()
159. .add("分享数", [list(z) for z in zip(author_titles, share_counts)], center=["50%", "50%"])
160. .set_global_opts(title_opts=opts.TitleOpts(title="不同作者分享数分布"),
161. legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%") )
162. .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
163. )
164.
165. pie_favorite_counts = (
166. Pie()
167. .add("收藏数", [list(z) for z in zip(author_titles, favorite_counts)])
168. .set_global_opts(title_opts=opts.TitleOpts(title="不同作者收藏数分布"),
169. legend_opts=opts.LegendOpts(orient="vertical", pos_top="15%", pos_left="2%"))
170. .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
171. )
172.
173. # 创建页面实例,并添加所有图表
174. page = Page(layout=Page.SimplePageLayout)
175. page.add(line)
176. page.add(pie_play_counts)
177. page.add(pie_danmu_counts)
178. page.add(pie_coin_counts)
179. page.add(pie_like_counts)
180. page.add(pie_share_counts)
181. page.add(pie_favorite_counts)
182.
183. # 保存为 HTML 文件
184. page.render("video_stats.html")

加入社区!打开量化的大门,首批课程上线啦!
更多推荐

 45
45 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)