
音频算法基础(语音识别 / 降噪 / 分离)
秋招抱佛脚之作,大纲由GPT提供,内容由博主本人整理。
日更直到拿到满意的offer为止。
1. 声学与信号基础
采样率、Nyquist 定理 ★★★★★
采样率:
每秒从连续信号中提取并组成离散信号的采样个数,它用赫兹(Hz)来表示。
以语音为例,通俗的讲采样频率是指计算机每秒钟采集多少个声音样本。采样率决定了采样的精度。采样频率越高,即采样的间隔时间越短,则在单位时间内计算机得到的声音样本数据就越多,对声音波形的表示也越精确。注意:采样频率必须大于信号的频率(不失真),fs/N(频率分辨率)越小,精度越高,通过补0增加的FFT点数无法提高FFT精度。
参考链接:CSDN
Nyquist定理:
对于带限信号进行离散采样时,只有采样频率高于其最高频率的2倍,(即一个周期内,至少采2个点),我们才能从采样信号中惟一正确地恢复原始带限信号。此处最高频率的2倍叫奈奎斯特频率 (Nyquist frequency)。若采样频率不满足此条件,就会让原始信号频谱产生频谱混叠 (aliasing)现象,从而无法正确恢复原始信号。
参考链接:知乎 - 采样定理推导
短时傅里叶变换(STFT/ ISTFT) ★★★★★
预备知识(?):
频域信号:分析信号包含的频率成分。各频率分量的频率和功率参数。在频域中,复数信号(即,由一个以上频率组成的信号)被分离成它们的频率分量,并显示每个频率的电平。
时域信号:分析信号参数随时间的变化过程。时域是信号在时间轴随时间变化的总体概括。在时域中,将信号的所有频率分量相加并显示。
参考链接:信号的频域是什么意思?和时域有什么区别? - 知乎
短时傅里叶变换 - STFT:对信号进行分帧处理后,对每一帧应用傅里叶变换。其基本思想是将信号视为在短时间内近似平稳的,从而可以分析其频谱特性。

逆短时傅里叶变换 - ISTFT:将频域信号转换回时域信号的过程。它是 STFT 的逆操作,旨在重建原始信号。

参考链接:CSDN - 时频分析之STFT
短时傅里叶变换(STFT)与逆变换(ISTFT)- CSDN
Mel 频率与 Mel 滤波器组 ★★★★★
频谱表示了信号在不同频率上的分布,然而,科学家发现人耳对低频信号的区别更加敏感,而对高频信号的区别则不那么敏感。也就是说低频段上的两个频度和高频段上的两个频度,人们会更容易区分前者。因此我们就明白了,频域上相等距离的两对频度,对于人耳来说他们的距离不一定相等。
梅尔刻度即是经过一种调整频域的方式,使得这个新的刻度上相等距离的两对频度,对于人耳来说也相等。
低频段的部分,梅尔刻度和正常频度几乎呈线性关系,而在高频段,因为人耳的感知变弱,因此两者呈对数关系。
梅尔滤波器组:
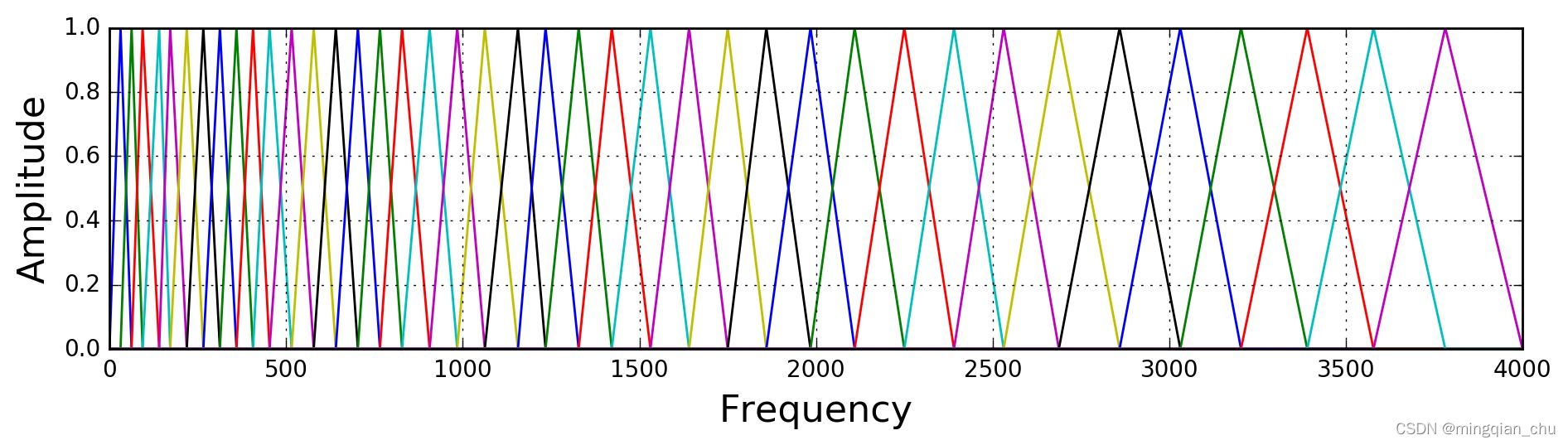
上图是梅尔滤波器组的一种情况,为等高梅尔滤波器组,用于非人声领域。
参考链接:语音合成基础(3)——关于梅尔频谱你想知道的都在这里 - 知乎
MFCC(梅尔倒谱系数)、CQT(常Q变换) ★★★★★
MFCC:
参考链接:深入理解MFCC(梅尔频率倒谱系数)-CSDN博客
CQT:
指中心频率按指数规律分布,滤波带宽(覆盖的频率范围)不同、但中心频率与带宽比为常量Q的滤波器组。它与傅立叶变换不同的是,它频谱的横轴频率不是线性的,而是基于log2为底的,并且可以根据谱线频率的不同该改变滤波窗长度,以获得更好的性能。由于 CQT 与音阶频率的分布相同,所以通过计算音乐信号的CQT谱,可以直接得到音乐信号在各音符频率处的振幅值,对于音乐的信号处理来说简直完美。
CQT 通过保持 Q 值不变,实现了滤波器的低频分辨高,高频分辨低的特点,加上频点的指数选取策略,使得 CQT 更加适合用来分析低频段信息密度高的信号。
参考链接:基于音乐识别的频谱转换算法——常数Q变换CQT(转载修改)_cqt变换-CSDN博客
窗函数(Hann、Hamming)与 N_FFT、Hop Length 参数含义 ★★★★★
参考链接:https://www.zhihu.com/question/67565087/answer/3121693025
大佬对“泄露”的原理讲的很好
2. 语音识别(ASR)
-
CTC 原理(对齐、空白符、Beam Search)
★★★★★
-
Attention-CTC 混合模型
★★★★☆ -
Transducer(RNN-T)结构
★★★★☆ -
Whisper 模型(大规模多语言语音识别)
★★★★☆ -
VAD(语音活动检测)与流式识别
★★★★★
3. 音频增强与降噪
-
传统方法:谱减法、Wiener 滤波
★★★☆☆ -
深度方法:Conv-TasNet、Demucs、DCCRN、SEGAN
★★★★☆ -
自监督降噪方法(Noisy Student、Noise2Noise)
★★★☆☆ -
多通道阵列与波束形成(Beamforming)
★★★☆☆
4. 声源分离与多模态
-
盲源分离(ICA)
★★★☆☆ -
音视频联合建模(Lip reading, AV-Hubert)
★★★☆☆ -
多模态对齐(早融合、后融合、联合嵌入)
★★★☆☆
5. 评价指标与应用
PESQ(感知语音质量)、STOI(可懂度指标)、SNR ★★★★★
PESQ:
STOI:
WER(字错误率)、CER(字符错误率) ★★★★★
端到端与模块化系统的优缺点对比 ★★★☆☆

加入社区!打开量化的大门,首批课程上线啦!
更多推荐
 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)