
影刀RPA爬虫-采集微信读书
·

微信读书(WeChat Reading)是腾讯旗下的一款电子书阅读平台,依托微信社交生态,主打“社交化阅读”,提供海量正版书籍、听书、漫画等内容,并融合好友互动、书单分享、读书排行榜等社交功能。
1.采集分析
微信读书的反爬虫机制严格,采集微信读书的数据需要谨慎操作,避免违反其用户协议和版权法律,毕竟是大公司,有法务。
首先,系统页面对数据进行了保护,我们无法通过页面元素内容获取
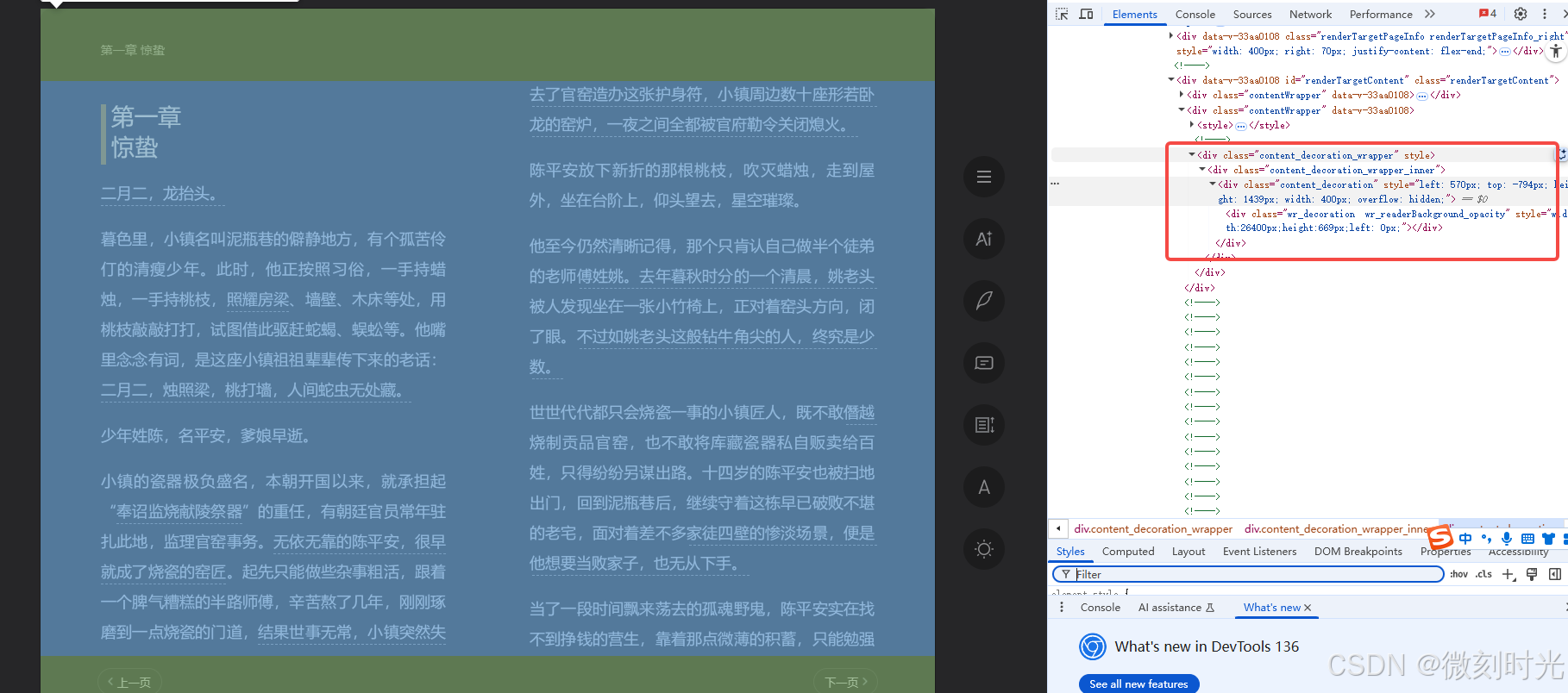
通过url请求,也无法实现
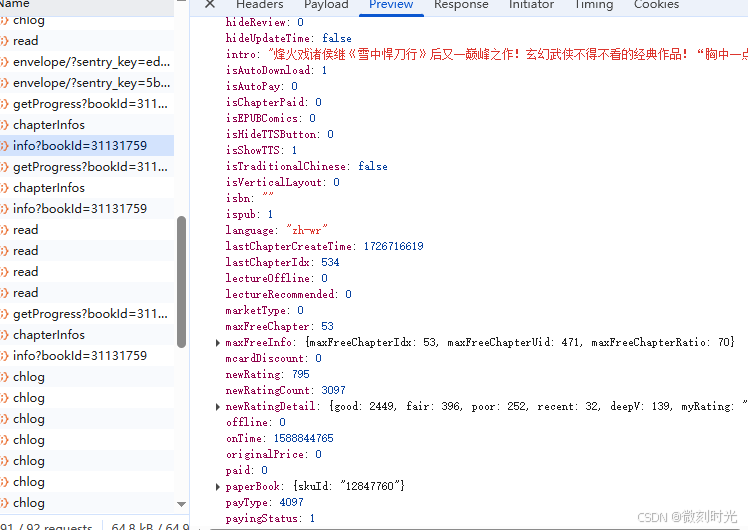
同时页面也设置了断点,所以通过页面代码来获取元素,或是http请求,都很难实现

我们使用影刀RPA来解决这个问题,思路就是复制页面上的内容,选中内容后,弹出的菜单栏上有复制,我们复制后填写到文件中。
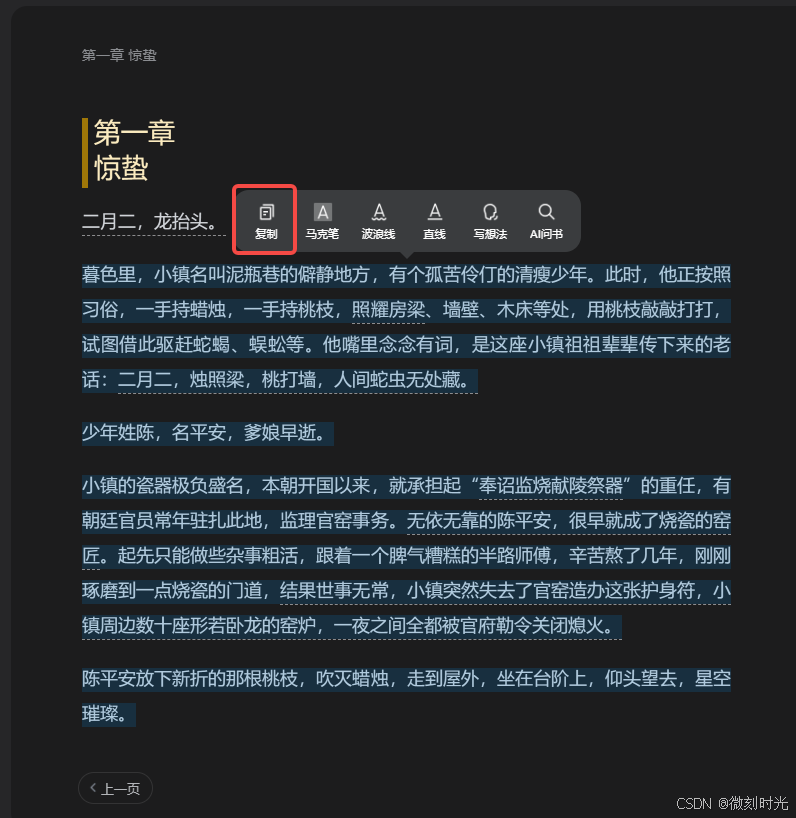
操作思维导图
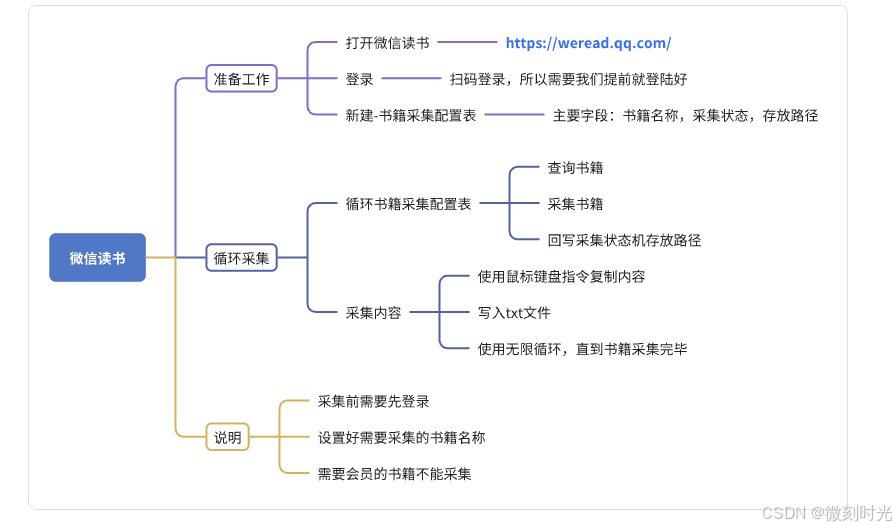
2.采集代码
2.1 设置采集目录
设置存放书籍的文件夹地址,设置成全局变量,便于调用

2.2 搜索进入书籍
打开微信读书页面,需要提前登录,在首页搜索书籍名称,进入数据详情页
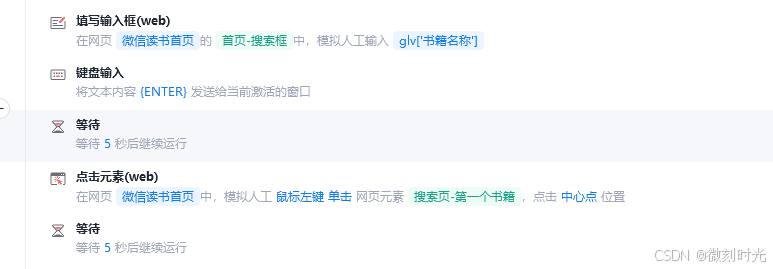
2.3 采集书籍
使用鼠标键盘指令,分别复制页面左右两端文本,保存到txt文件中,复制完当前页面,点击下一页继续复制。

2.4 写入文件
保存文本,每次到追加到文件末尾

对于付费的书籍,是无法采集全部的。所有在采集前,先确定好,该书籍是否可以正常打开
3.采集结果
视频演示

4.最后
以上的采集思路仅供思考,学习使用
影刀RPA办公自动化入门到实战![]() https://acnbxyhm60mi.feishu.cn/wiki/GOnpwWtMpit2MAkzDPzcro4VnPf
https://acnbxyhm60mi.feishu.cn/wiki/GOnpwWtMpit2MAkzDPzcro4VnPf

加入社区!打开量化的大门,首批课程上线啦!
更多推荐

 34
34 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)