
爬虫(仅基于静态网页)
④服务器接收到请求后,会根据请求的路径和头信息,找到对应的资源(对于静态页面,就是直接读取那个HTML文件),然后组成一个HTTP响应报文,并通过之前建立的TCP连接发回给你的程序。这一段我们不是已经获得了网页的内容嘛,接下来使用lxml 库进行HTML解析和数据提取,你可以通过浏览器右键检查,很方便的获取网页元素的css选择器路径和xpath路径。我们爬虫获取的HTML内容,就包含在这个响应之中
一、DOM结构
DOM(Document Object Model,文档对象模型)是浏览器将接收到的HTML文档解析后,在内存中创建的一个树形结构表示,是一个W3C组织定义的规范。
假设我们现在有一个这样的html文件:
<!DOCTYPE html>
<html>
<head>
<title>我的页面</title>
</head>
<body>
<h1>欢迎</h1>
<p id="content">XXXXXXX</p>
</body>
</html>其对应的DOM树可以简化为:
document
└── html
├── head
│ └── title
│ └── "我的页面" (文本节点)
└── body
├── h1
│ └── "欢迎" (文本节点)
└── p (id="content")
└── XXXXXXXX二、静态页面
页面上展示的所有内容(文本、图片链接、布局等)都直接书写在服务器的那个HTML文件中。你通过浏览器“查看网页源代码”所看到的内容,就是浏览器接收到的全部内容。
像上面介绍DOM的时候给出来的html文件就是典型的静态页面。无论谁、在什么时间、用什么设备访问这个html页面,它显示的内容都是一模一样的。
这样的代码内容固定,容易被浏览器或CDN缓存,减轻服务器压力;所有数据全都写在html源码里,爬虫的目标非常明确;但如果网站有多个页面都包含相同的页脚,当需要修改页脚信息时,必须手动修改所有的文件;其次无法根据用户身份、时间等因素提供个性化的内容。
三、如何获取这些html页面上的内容
1.我们是怎么和网页建立连接的(超文本传输协议)
已有的网页集中存储在服务器上,而用户需要一种标准化的、可靠的方式来获取它们。HTTP协议就是为此目的而设计的应用层协议。
我们的Python程序充当客户端(Client),向作为服务器(Server) 的网站发起一个请求(Request),服务器处理这个请求后,返回一个响应(Response)。我们爬虫获取的HTML内容,就包含在这个响应之中。
2.具体过程
域名解析——>建立TCP连接——>发送HTTP请求——>服务器处理并返回HTTP响应——>关闭连接与解析响应
①程序首先需要将你提供的网址(https://mp.csdn.net/mp_blog/creation/editor)转换为其对应的服务器IP地址(138.197.63.211)。因为网络设备只认IP地址,不认域名。这个过程通常由操作系统的网络库自动完成,resquest库会调用它。程序会向配置的DNS服务器发送查询,获取目标域名的IP地址。②取到IP地址后,Python程序会通过操作系统网络栈,向该IP地址的端口发起一个TCP连接请求。resquest库会调用操作系统提供的socket接口来发起这个连接。③TCP连接建立后,程序就可以通过这个可靠的通道向Web服务器发送一个格式化的HTTP请求报文。这个报文不仅包含你想要访问的URL路径,还包含头信息(Headers),这些信息定义了请求的细节。④服务器接收到请求后,会根据请求的路径和头信息,找到对应的资源(对于静态页面,就是直接读取那个HTML文件),然后组成一个HTTP响应报文,并通过之前建立的TCP连接发回给你的程序。⑤响应接收完毕后,TCP连接通常会关闭(如果 header 中有Connection: keep-alive,连接可能会保持一段时间以供后续请求复用)
=>最终requests.get()函数会返回一个Response对象。这个对象的.text属性就包含了从响应报文中提取出的HTML主体内容(字符串)。
3.具体案例
现在我们需要从代码编写的角度来关注具体获取网页的过程。①准备请求参数:设置目标URL和必要的请求头(如User-Agent)②发送请求并获取响应:调用requests.get()方法,库会自动处理DNS解析、TCP连接、发送HTTP请求、接收响应等所有底层网络操作。③检查和处理响应:验证请求是否成功(状态码),然后从响应对象中提取我们需要的内容(如HTML文本)。
import requests
target_url = 'https://movie.douban.com/top250'
# 步骤1: 设置请求头,模拟浏览器访问(具体的User-Agent可以参考https://useragent.buyaocha.com/)
request_headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
# 步骤2: 发送HTTP请求
douban_response = requests.get(target_url, headers=request_headers)
# 步骤3: 处理服务器响应
if douban_response.status_code == 200:
print("请求成功")
# 获取HTML内容
html_content = douban_response.text
# 预览内容
print("\nHTML内容预览(前500字符):")
print(html_content[:500])最终你就可以看到我们得到html页面源码如下:
四、HTML内容解析
我们已经拿到了HTML内容,但还没提取数据,因此接下来需要解析具体的html源码,常用的解析库包括 beautifulsoup 和 lxml。
我们现在先讲思路,①我们需要将requests获取到的response.text加载到解析库中。解析库将字符串解析成内存中的节点树状结构(也就是最开始所说得DOM树)②使用选择器定位到包含目标数据的节点,从节点中提取文本、属性等信息。
# 获取HTML内容
html_content = douban_response.text这一段我们不是已经获得了网页的内容嘛,接下来使用lxml 库进行HTML解析和数据提取,你可以通过浏览器右键检查,很方便的获取网页元素的css选择器路径和xpath路径
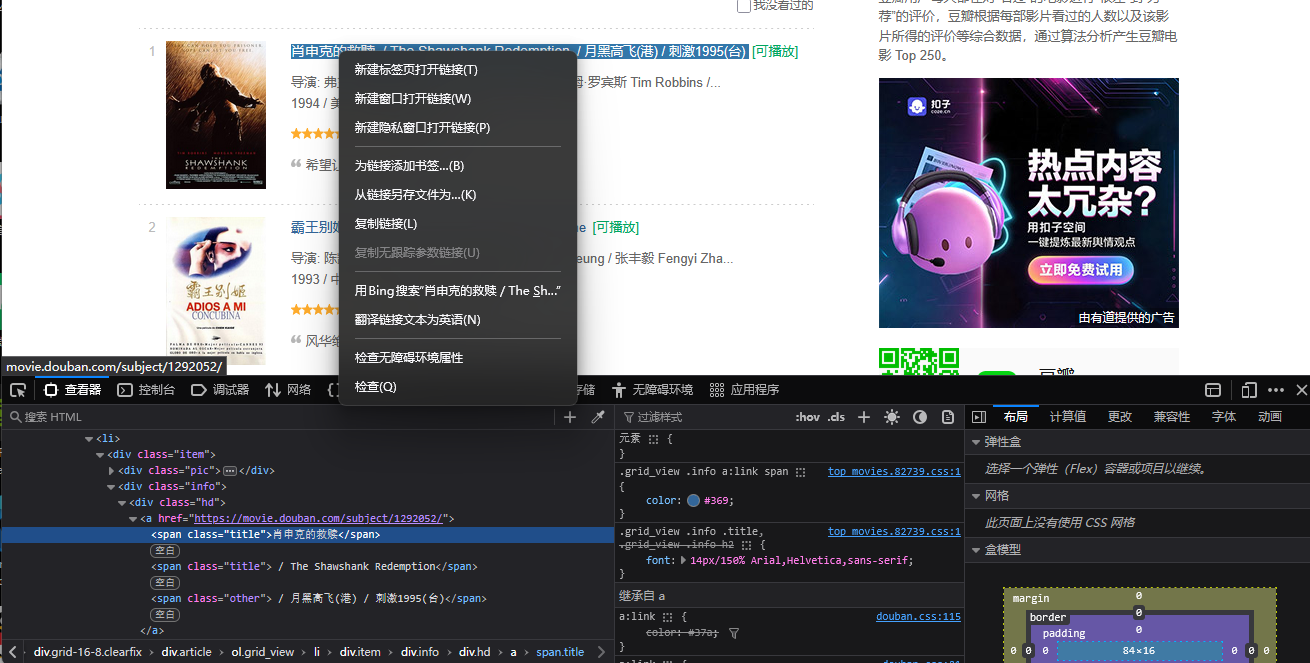
# 使用lxml解析HTML内容,构建DOM树
# html.fromstring()函数将HTML字符串转换为一个元素树对象
dom_tree = html.fromstring(html_content)
# 使用XPath定位所有电影条目
# 分析页面结构后发现,每个电影都在一个class="item"的div中
# XPath: //div[@class='item'] 表示查找所有class属性为'item'的div元素
movie_items = dom_tree.xpath('//div[@class="item"]')因此我们能够得到一个包含 lxml.html.HtmlElement 对象(在这里是每个<div class="item">节点)的列表movie_items
# XPath: .//span[@class='title'][1]
# . 表示从当前节点(item)开始查找
# //span 表示查找所有span后代元素
# [@class='title'] 表示class属性为'title'
# [1] 表示取第一个匹配的元素
# /text() 表示获取元素的文本内容
title_cn = item.xpath('.//span[@class="title"][1]/text()')
title_cn = title_cn[0] if title_cn else "未知标题"
# 提取评分
rating = item.xpath('.//span[@class="rating_num"]/text()')
rating = rating[0] if rating else "暂无评分"
print(f"中文名: {title_cn}")
print(f"评分: {rating}")五、分页处理
豆瓣Top250有10页,要如何构建URL和循环请求所有页面。我们观察
第一页: https://movie.douban.com/top250第二页: https://movie.douban.com/top250?start=25&filter=……即:url使用参数控制分页,每页显示25条数据,start参数以25递增,共有10页,那么按照以下方式就可以实现分页操作了。
for page in range(0, 10): # 0到9,共10页
start = page * 25
# 构建当前页的URL
if start == 0:
current_url = base_url # 第一页没有start参数
else:
current_url = f'{base_url}?start={start}&filter='
加入社区!打开量化的大门,首批课程上线啦!
更多推荐


 47
47 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)