
Python爬虫入门详细教程,通俗易懂,看一遍就会!(含实例)
***
Python爬虫入门详细教程,通俗易懂,看一遍就会!(含实例)
一、什么是爬虫 ?**
**
1、简单介绍爬虫
爬虫的全称为网络爬虫,简称爬虫,别名有网络机器人,网络蜘蛛等等。
网络爬虫是一种自动获取网页内容的程序,为搜索引擎提供了重要的数据支撑。
搜索引擎通过网络爬虫技术,将互联网中丰富的网页信息保存到本地,形成镜像备份。
如果形象地理解,爬虫就如同一只机器蜘蛛,它的基本操作就是模拟人的行为去各个网站抓取数据或返回数据。

2、爬虫的分类 网络爬虫一般分为传统爬虫和聚焦爬虫。
聚焦爬虫需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入待抓取的 URL 队列,再根据一定的搜索策略从队列中选择下一步要抓取的网页 URL,并重复上述过程,直到满足系统的一定条件时停止。
另外,所有被爬虫抓取的网页都将会被系统存储、分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
使用防爬虫机制的基本上是企业,我们平时也能见到一些对抗爬虫的经典方式,如图片验证码、滑块验证、封禁 IP 等等。
二、爬虫的工作原理 **
**
1、网络爬虫的基本框架
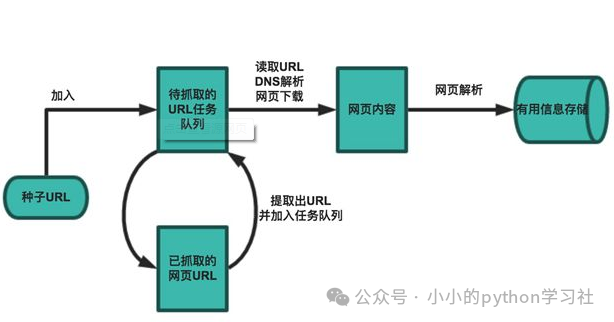
对应互联网的所有页面可划分为五部分:
a. 已下载未过期网页。
b. 已下载已过期网页:
抓取到的网页实际上是互联网内容的一个镜像文件,互联网是动态变化的,一部分互联网上的内容已经发生了变化,这时,这部分抓取到的网页就已经过期了。
c. 待下载网页:
待抓取 URL 队列中的页面。
d. 可知网页:
既没有被抓取也没有在待抓取 URL 队列中,但可通过对已抓取页面或者待抓取 URL 对应页面进行分析获取到的 URL,认为是可知网页。
e. 不可知网页:
爬虫无法直接抓取下载的网页。
待抓取 URL 队列中的 URL 顺序排列涉及到抓取页面的先后次序问题,而决定这些 URL 排列顺序的方法叫做抓取策略。
下面介绍六种常见的抓取策略:
1. 深度优先遍历策略 ·网络爬虫从起始页开始,由一个链接跟踪到另一个链接,这样不断跟踪链接下去直到处理完这条线路,之后再转入下一个起始页,继续跟踪链接。
·例如:遍历路径:A-F-GE-H-IBCD。需要注意的是,深度优先可能会找不到目标节点(即进入无限深度分支),因此,深度优先策略不一定能适用于所有情况。
2. 宽度优先遍历策略
·宽度优先遍历策略的基本思路是,将新下载网页中发现的链接直接插入待抓取 URL 队列的末尾。
·例如:遍历路径:第一层:A-B-C-D-E-F,第二层:G-H,第三层:I。广度优先遍历策略会彻底遍历整个网络图,效率较低,但覆盖网页较广。
3. 反向链接数策略 ·反向链接数是指一个网页被其他网页链接指向的数量。因此,很多时候搜索引擎的抓取系统会使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后顺序。而现实是网络环境存在各种广告链接、作弊链接的干扰,使得许多反向链接数反映的结果并不可靠。
4. PartialPageRank 策略 ·PartialPageRank 策略借鉴了 PageRank 算法的思想:
对于已下载网页,连同待抓取 URL 队列中的 URL,形成网页集合,计算每个页面的 PageRank 值,然后将待抓取 URL 队列中的 URL 按照 PageRank 值的大小进行排列,并按照该顺序抓取页面。
若每次抓取一个页面,就重新计算 PageRank 值,则效率太低。
一种折中方案是:每抓取 K 个页面后,重新计算一次 PageRank 值。
5. OPIC 策略
·此算法其实也是计算页面重要程度。在算法开始前,给所有页面一个相同的初始现金(cash)。当下载了某个页面 P 之后,将 P 的现金分摊给所有从 P 中分析出的链接,并且将 P 的现金清空。
6. 大站优先策略
·对于待抓取 URL 队列中的所有网页,根据所属的网站进行分类。待下载页面数多的网站优先下载。

三、熟悉python编程
熟悉Python编程,Python是一种计算机程序设计语言。是一种面向对象的动态类型语言,最初被设计用于编写自动化脚本(shell),随着版本的不断更新和语言新功能的添加,越来越多被用于独立的、大型项目的开发。
所以Python编程也就是利用Python语言进行计算机编程。
四、正确认识自己到底适不适合Python爬虫
入门Python爬虫最重要,也是最简单的一步,一定要对Python爬虫感兴趣!感兴趣!
作为一名资深的Python爬虫迷,我觉得无论学习任何一件事情,都应该要做到兴趣入门,持之以恒,最后才能真正出师。
在刚开始入门爬虫时,你甚至不需要去学习python的类、多线程、模块之类的略难内容。而是一切按照自己的能力来,基于你学习的目的,工作、爱好、甚至于你想要在后续阶段成长为一名Python爬虫大神。
建议入门一定不要在网上自己瞎碰,因为现在网上的Python爬虫教程虽多,但真正面向于Python零基础的却不多,找好真正有用的优质学习资料,加上专业老师指导,不仅能够学习Python爬虫,还能学习其他Python相关的内容,多掌握一些内容,工作前景也会更大。
零基础入门Python爬虫的要点我就说到这了,学习Python爬虫一定要反复咀嚼语法逻辑,比如列表、字典、字符串、if语句、for循环等最核心的东西都得捻熟于心、于手。
网络安全学习资源分享:
给大家分享一份全套的网络安全学习资料,给那些想学习 网络安全的小伙伴们一点帮助!
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。
因篇幅有限,仅展示部分资料,朋友们如果有需要全套《网络安全入门+进阶学习资源包》,需要点击下方链接即可前往获取
读者福利 | CSDN大礼包:《网络安全入门&进阶学习资源包》免费分享 (安全链接,放心点击)

👉1.成长路线图&学习规划👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。

👉2.网安入门到进阶视频教程👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,其中一共有21个章节,每个章节都是当前板块的精华浓缩。(全套教程文末领取哈)

👉3.SRC&黑客文档👈
大家最喜欢也是最关心的SRC技术文籍&黑客技术也有收录
SRC技术文籍:

黑客资料由于是敏感资源,这里不能直接展示哦!(全套教程文末领取哈)
👉4.护网行动资料👈
其中关于HW护网行动,也准备了对应的资料,这些内容可相当于比赛的金手指!

👉5.黑客必读书单👈

👉6.网络安全岗面试题合集👈
当你自学到这里,你就要开始思考找工作的事情了,而工作绕不开的就是真题和面试题。
所有资料共282G,朋友们如果有需要全套《网络安全入门+进阶学习资源包》,可以扫描下方二维码或链接免费领取~
读者福利 | CSDN大礼包:《网络安全入门&进阶学习资源包》免费分享 (安全链接,放心点击)


加入社区!打开量化的大门,首批课程上线啦!
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)