
【SpiderDemo】爬虫练习案例实战全题型教程
目录
SpiderDemo爬虫全题型实战
T1 请求头检测

什么?第一题就卡住了吗?不甘心。一开始使用requests库搞了很久,怀疑是不是对请求头的顺序做了检测,后续发现并没有。之后使用httpx库实现了。请求接口先要登录,所以我们看一下登录接口,发现都没有加密,且不会变动,直接固定后带参请求,循环请求页面接口即可。或者可以取消勾选禁用缓存,发现可以,request时不用带no-cache。
import httpx
headers = {
"Host": "www.spiderdemo.cn",
"Connection": "keep-alive",
"sec-ch-ua": '"Not;A=Brand";v="99", "Microsoft Edge";v="139", "Chromium";v="139"',
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": '"Windows"',
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": "https://www.spiderdemo.cn/sec1/header_check/",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Cookie": "sessionid=xxxxx"
}
total = 0
for i in range(1,101):
url = f"https://www.spiderdemo.cn/sec1/api/challenge/page/{i}/?challenge_type=header_check"
# 发送请求
response = httpx.get(url, headers=headers, cookies=cookies)
# 打印状态码和响应内容
print(response.status_code)
total += sum(response.json()["page_data"])
print(f"100页的和为:{total}")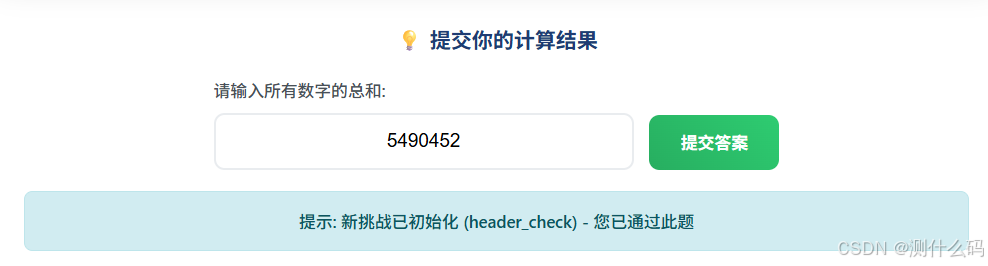
T2 加解密

先看请求参数,发现有三个,直接查看堆栈,找到请求数据的地方。

找到请求url拼接的地方,发现sign是由时间戳和page再加上两个固定的字符串的魔改MD5。
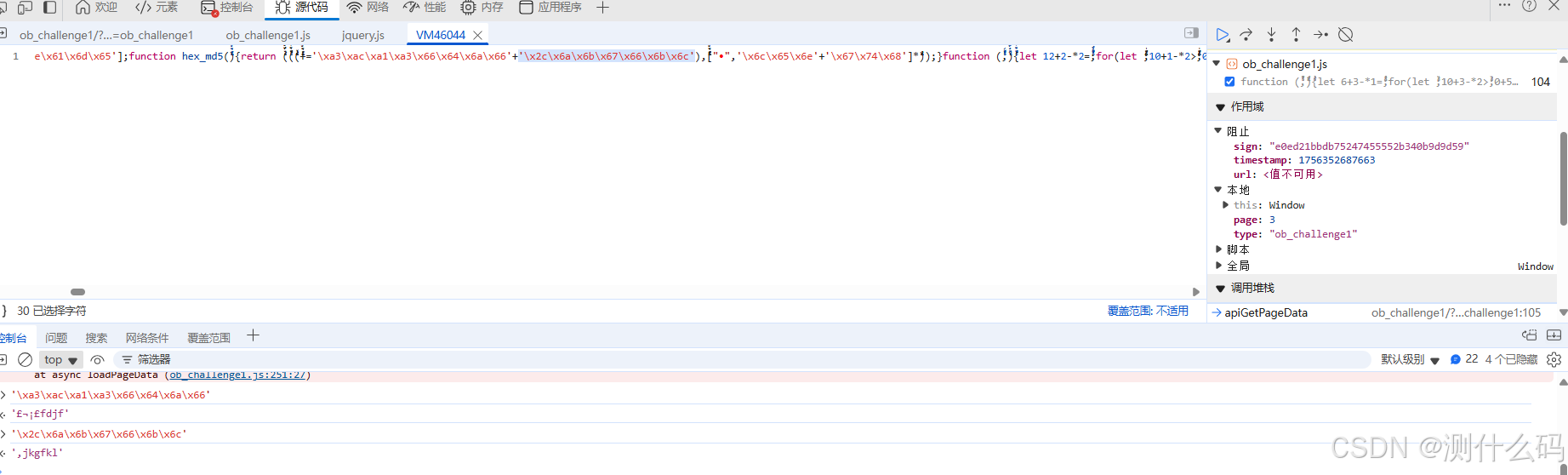
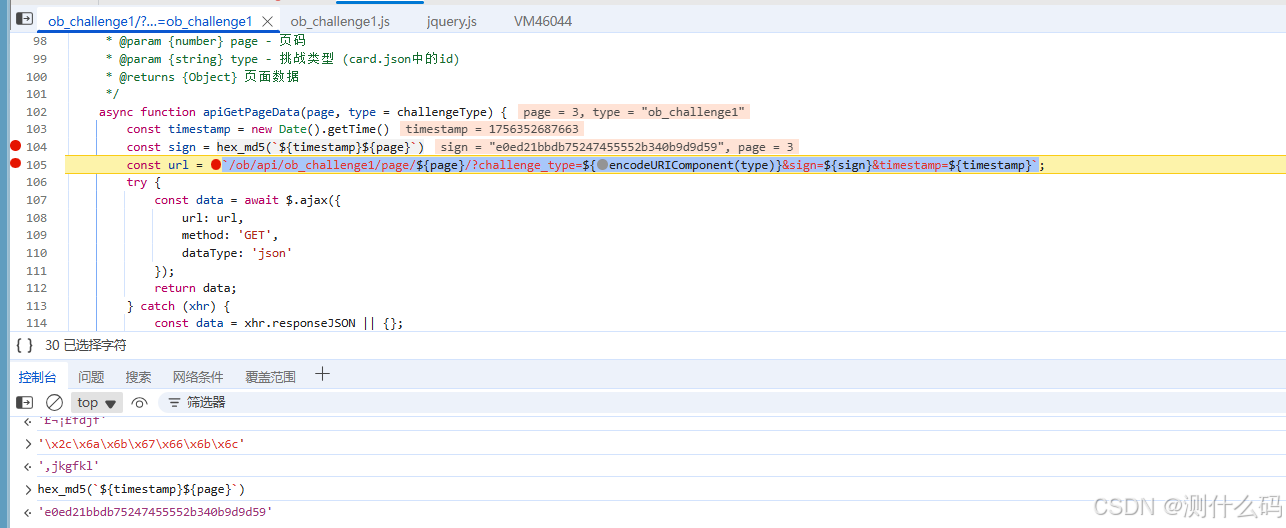

那就很简单了,直接python实现。(纯py实现不知道为何容易出现爬虫检测,使用了邪修手法)
import time
from hashlib import md5
import httpx
from DrissionPage import Chromium, ChromiumOptions
headers = {
"Host": "www.spiderdemo.cn",
"Connection": "keep-alive",
"sec-ch-ua-platform": "\"Windows\"",
"X-Requested-With": "XMLHttpRequest",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0",
"Accept": "application/json, text/javascript, */*; q=0.01",
"sec-ch-ua": "\"Not;A=Brand\";v=\"99\", \"Microsoft Edge\";v=\"139\", \"Chromium\";v=\"139\"",
"sec-ch-ua-mobile": "?0",
"Sec-Fetch-Site": "same-origin",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Dest": "empty",
"Referer": "https://www.spiderdemo.cn/ob/ob_challenge1/?challenge_type=ob_challenge1",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"Cookie": "sessionid=xxxxx"
}
# 初始化对象 无头模式
co = ChromiumOptions().headless()
co.set_argument('--no-sandbox')
co.set_user_agent(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/138.0.0.0 Safari/537.36 Edg/138.0.0.0")
co.set_argument("--window-size=1920,1080")
co.set_argument("--disable-gpu")
co.set_argument("--disable-dev-shm-usage")
co.set_argument("--enable-webgl")
co.set_argument("--ignore-gpu-blocklist")
co.set_argument("--enable-automation=false")
browser = Chromium(co)
page = browser.new_tab()
total = 0
page.get("https://www.spiderdemo.cn/ob/ob_challenge1/?challenge_type=ob_challenge1")
for i in range(1,101):
timestamp = int(time.time() * 1000)
a = f"{timestamp}{i}"
sign = page.run_js(f'return hex_md5("{a}")')
# text = str(timestamp) + str(i) + "£¬¡£fdjf,jkgfkl"
# sign = md5(text.encode('iso-8859-1')).hexdigest()
url = f"https://www.spiderdemo.cn/ob/api/ob_challenge1/page/{i}/"
params = {
"challenge_type": "ob_challenge1",
"sign": sign,
"timestamp": timestamp,
}
# 发送请求
response = httpx.get(url, headers=headers, params=params)
print(f"第{i}页, {response.json()}")
total += sum(response.json()["page_data"])
print(f"100页的和为:{total}")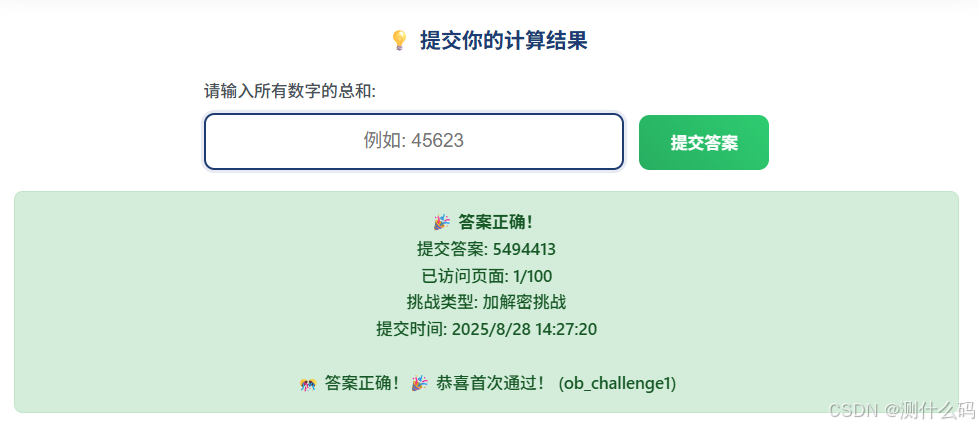
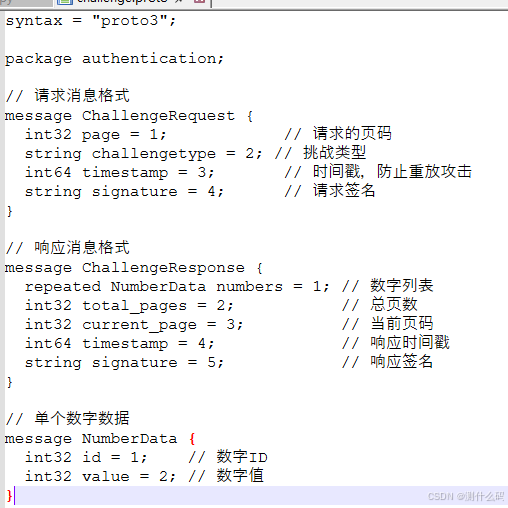
T3 protobuf加密

查看请求,有两次,试着查看这个proto文件内容

看到请求消息和响应消息,根据堆栈进入到加密位置。
T4 WASM挑战

T9 字体反爬+雪碧图

查看接口,接口返回了字体偏移值和一个DataURI格式的图片地址(不会的某度),图片宽度500px,除以10就是50宽度一个值。直接拿到验证码,使用ddddorc识别每页的验证码列表。页面一共10组数据,每组4个数字,我们根据接口返回的样式,获取当前页面的40个偏移值,然后计算每个偏移量整除50的值,就得到了当前真实值在当前验证码图片中的位置(索引),四个一组拼接然后计算即可。
import io
import re
from pathlib import Path
import ddddocr
import requests
import base64
from PIL import Image
class crawl:
def preprocess_transparent_image(self, image_bytes):
"""预处理透明背景图片,将透明背景转换为白色,保留黑色字体。"""
# 将二进制数据转为PIL图像
image = Image.open(io.BytesIO(image_bytes)).convert("RGBA")
# 创建一个新的白色背景图片
new_background = Image.new("RGB", image.size, (255, 255, 255))
# 将原图(黑色字体在透明通道上)粘贴到白色背景上
# 仅当原图像素不透明时,才使用原图的颜色(即黑色字体部分)
new_background.paste(image, mask=image.split()[3]) # 使用alpha通道作为mask
# 将处理后的图片转换回二进制数据
byte_arr = io.BytesIO()
new_background.save(byte_arr, format='PNG')
return byte_arr.getvalue()
def process_and_recognize(self, processed_image_bytes):
"""
处理验证码图片并识别
Args:
processed_image_bytes: 图片字节
"""
# 1. 初始化ddddocr识别器
ocr = ddddocr.DdddOcr()
# 2. 执行识别
result = ocr.classification(processed_image_bytes)
result = result.replace('o','0')
return result
def save_img(self, img_data):
img = base64.b64decode(img_data)
filename = "T9.png"
filepath = Path(filename)
with open(filepath, "wb") as f:
f.write(img)
# image = Image.open(filepath)
# print(image.width)
def parse(self, num_list: list, gap: int):
return {str(num): str(int(num // gap)) for num in num_list}
def get_digits(self, data, yzm):
pos = re.findall(r"background-position:\s*-(\d+)px", data)
print('找到多少个偏移: ',len(pos))
print(pos)
result = []
for i in range(0, len(pos), 4):
group = pos[i:i + 4]
# 确保每组有4个元素,如果最后一组不足4个,可以跳过或特殊处理,这里假设都是4的倍数
if len(group) == 4:
# 将组中的每个键通过映射得到数字,然后拼接
num_str = ''
for key in group:
index = int(key) // 50
num_str += yzm[index]
#num_str += str(mapping[key])
result.append(int(num_str))
else:
pass
return result
if __name__ == '__main__':
headers = {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"pragma": "no-cache",
"priority": "u=1, i",
"referer": "https://www.spiderdemo.cn/font_anti/font_sprites_challenge/?challenge_type=font_sprites_challenge",
"sec-ch-ua": "\"Google Chrome\";v=\"143\", \"Chromium\";v=\"143\", \"Not A(Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"x-requested-with": "XMLHttpRequest"
}
cookies = {
"sessionid": "xxxx"
}
final = 0
for i in range(1,101):
if i == 1:
url1 = 'https://www.spiderdemo.cn/font_anti/api/font_sprites_challenge/init/?challenge_type=font_sprites_challenge'
response = requests.get(url1, headers=headers, cookies=cookies)
num = response.json()['page_data']
final += sum(num)
print(f"首页第{i}页的数据:{num}, 当前和: {final}")
i += 1
continue
url = f"https://www.spiderdemo.cn/font_anti/api/font_sprites_challenge/page/{i}/"
params = {
"challenge_type": "font_sprites_challenge"
}
response = requests.get(url, headers=headers, cookies=cookies, params=params)
data = response.json()
c = crawl()
c.save_img(data['sprite'])
with open('T9.png', 'rb') as f:
image_bytes = f.read()
processed_image_bytes = c.preprocess_transparent_image(image_bytes)
yzm = c.process_and_recognize(processed_image_bytes)
print(f"ddddocr识别结果: {yzm}")
result = c.get_digits(data['css_code'], yzm)
final += sum(result)
print(data['css_code'])
print(f"第{i}页的数据: {result}, 当前和: {final}")
i += 1
print(f"100页的和: {final}")T11 第一代验证码

查看请求接口和验证码接口,很简单,验证码直接通过ddddocr识别,因为验证码太小,我们需要对这个验证码图标进行切割并放大,这样有利于识别更准确。
这里我使用的py3.13版本,发现安装PIL库都是大于9.5的,会报一个没有属性的错误,我们需要修改源码(自行百度就有结果,这里不展开)。
还有一个问题,首次访问是get请求,直接贴上代码。
import ddddocr
import time
from PIL import Image
import requests
def process_and_recognize(image_path, crop_box=(53, 20, 95, 36), scale_factor=2):
"""
处理验证码图片并识别
Args:
image_path: 原始图片路径
crop_box: 裁剪区域 (left, upper, right, lower)
scale_factor: 放大倍数
"""
# 1. 打开并处理图片
img = Image.open(image_path)
# 裁剪指定区域
cropped_img = img.crop(crop_box)
# 放大图片
width, height = cropped_img.size
resized_img = cropped_img.resize(
(width * scale_factor, height * scale_factor),
Image.Resampling.LANCZOS # 使用正确的重采样方法
)
# 可选:保存处理后的图片用于调试
resized_img.save("processed_captcha.png")
# 2. 初始化ddddocr识别器
ocr = ddddocr.DdddOcr()
# 3. 将PIL图像转换为字节数据
import io
img_byte_arr = io.BytesIO()
resized_img.save(img_byte_arr, format='PNG')
img_byte_arr = img_byte_arr.getvalue()
# 4. 执行识别
result = ocr.classification(img_byte_arr)
return result
cookies = {
"sessionid": "xxxx"
}
def get_img():
timestamp = int(time.time() * 1000)
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"pragma": "no-cache",
"priority": "u=0, i",
"sec-ch-ua": "\"Google Chrome\";v=\"143\", \"Chromium\";v=\"143\", \"Not A(Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36"
}
params = {
"t": timestamp
}
img_url = f"https://www.spiderdemo.cn/captcha/api/cap1_challenge/captcha_image/"
response = requests.get(img_url, headers=headers, cookies=cookies, params=params)
with open('1.png', 'wb') as f: # 打开文件以二进制写入模式
f.write(response.content)
headers = {
"Content-Type": "application/json",
"X-Requested-With": "XMLHttpRequest",
"Origin": "https://www.spiderdemo.cn",
"Referer": "https://www.spiderdemo.cn/captcha/cap1_challenge/?challenge_type=cap1_challenge",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36"
}
final = 0
i = 1
while i >= 1:
if i > 100:
break
if i == 1:
url1 = 'https://www.spiderdemo.cn/captcha/api/cap1_challenge/init/?challenge_type=cap1_challenge'
response = requests.get(url1, headers=headers, cookies=cookies)
num = response.json()['page_data']
final += sum(num)
print(f"第{i}页的数据:{num}")
i += 1
continue
get_img()
image_path = "1.png"
result = process_and_recognize(image_path).upper()
print(f"第{i}次识别结果: {result}")
url2 = "https://www.spiderdemo.cn/captcha/api/cap1_challenge/page/"
json_data = {
"captcha_input": f"{result}",
"page_num": i,
"challenge_type": "cap1_challenge"
}
response = requests.post(url2, headers=headers, cookies=cookies, json=json_data)
if not response.json()['success']:
print(response.json()['error'])
continue
num = response.json()['page_data']
final += sum(num)
print(f"第{i}页的数据:{num}")
i += 1
print(f"100页的和:{final}")T12 第一代验证码变种

和T11一样,只不过验证码图片由png=>gif,验证码请求返回两个值,一个真值一个假值,且返回的gif为DataURI,不懂的可以搜一下,基于base64编码,拿到后解码可以得到最终的gif。再根据每一帧的图片去识别验证码并验证拿到页面数据即可。这样相对来说可能慢一点,有更好的方案欢迎留言~
import os, imageio
import re
import time
import requests
import base64
from PIL import Image
from pathlib import Path
import ddddocr
cookies = {
"sessionid": "xxxx"
}
def process_and_recognize(image_path):
"""
处理验证码图片并识别
Args:
image_path: 原始图片路径
"""
# 1. 打开并处理图片
img = Image.open(image_path)
# 放大图片
width, height = img.size
resized_img = img.resize(
(width, height),
Image.Resampling.LANCZOS # 使用正确的重采样方法
)
# 可选:保存处理后的图片用于调试
resized_img.save("processed_captcha2.png")
# 2. 初始化ddddocr识别器
ocr = ddddocr.DdddOcr()
# 3. 将PIL图像转换为字节数据
import io
img_byte_arr = io.BytesIO()
resized_img.save(img_byte_arr, format='PNG')
img_byte_arr = img_byte_arr.getvalue()
# 4. 执行识别
result = ocr.classification(img_byte_arr)
return result
def get_gif_datauri():
timestamp = int(time.time() * 1000)
headers = {
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"pragma": "no-cache",
"priority": "u=0, i",
"sec-ch-ua": "\"Google Chrome\";v=\"143\", \"Chromium\";v=\"143\", \"Not A(Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "document",
"sec-fetch-mode": "navigate",
"sec-fetch-site": "none",
"sec-fetch-user": "?1",
"upgrade-insecure-requests": "1",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36"
}
params = {
"t": timestamp
}
img_url = f"https://www.spiderdemo.cn/captcha/api/cap2_challenge/captcha_image/"
response = requests.get(img_url, headers=headers, cookies=cookies, params=params)
print(response)
return response.json()
def data_uri_to_file(data_uri):
# 验证是否为data URI
if not data_uri.startswith('data:'):
raise ValueError("这不是一个有效的data URI")
# 分离header和data
header, data = data_uri.split(',', 1)
# 解码base64
try:
file_data = base64.b64decode(data)
except Exception as e:
raise ValueError(f"base64解码失败: {e}")
output_path = "T12.gif"
# 确保输出目录存在
output_path = Path(output_path)
output_path.parent.mkdir(parents=True, exist_ok=True)
# 写入文件
with open(output_path, 'wb') as f:
f.write(file_data)
print(f"文件已保存到: {output_path}")
return str(output_path)
def get_last_frame_of_gif(gif_path, output_path=None):
"""
Args:
gif_path: GIF文件路径
output_path: 输出PNG文件路径(可选,不指定则自动生成)
Returns:
保存的文件路径
"""
try:
# 打开GIF文件
with Image.open(gif_path) as gif:
# 获取GIF的帧数
frame_count = gif.n_frames
# print(f"GIF总帧数: {frame_count}")
yzm = ''
for i in range(frame_count):
gif.seek(i)
# 获取最后一帧图像
last_frame = gif.copy()
# 转换为RGBA模式(确保透明度支持)
if last_frame.mode != 'RGBA':
last_frame = last_frame.convert('RGBA')
# 如果未指定输出路径,则自动生成
if output_path is None:
output_dir = os.path.dirname(gif_path)
output_path = os.path.join(output_dir, "T12.png")
# 保存为PNG
last_frame.save(output_path, 'PNG')
# 调用识别
yzm = process_and_recognize(output_path)
pattern = r'^[a-zA-Z0-9]{4}$'
if yzm != '' and re.match(pattern, yzm):
break
# print(f"最后一帧已保存为: {output_path}")
# print(f"图像尺寸: {last_frame.size}")
# print(f"图像模式: {last_frame.mode}")
return yzm
except Exception as e:
print(f"处理GIF时出错: {e}")
return None
headers = {
"Content-Type": "application/json",
"X-Requested-With": "XMLHttpRequest",
"Origin": "https://www.spiderdemo.cn",
"Referer": "https://www.spiderdemo.cn/captcha/cap1_challenge/?challenge_type=cap1_challenge",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36"
}
final = 0
i = 1
while i >= 1:
if i > 100:
break
if i == 1:
url1 = 'https://www.spiderdemo.cn/captcha/api/cap2_challenge/init/?challenge_type=cap2_challenge'
response = requests.get(url1, headers=headers, cookies=cookies)
num = response.json()['page_data']
final += sum(num)
print(f"第{i}页的数据:{num}")
i += 1
continue
res = get_gif_datauri()
data_uri = 'data:image/gif;base64,' + f"{res['T']}"
data_uri_to_file(data_uri)
get_last_frame_of_gif('./T12.gif')
image_path = "T12.png"
result = process_and_recognize(image_path).lower()
print(f"第{i}次识别结果: {result}")
url2 = "https://www.spiderdemo.cn/captcha/api/cap2_challenge/page/"
json_data = {
"captcha_input": f"{result}",
"page_num": i,
"challenge_type": "cap2_challenge"
}
response = requests.post(url2, headers=headers, cookies=cookies, json=json_data)
print(response)
if response.status_code != 200:
continue
if not response.json()['success']:
print(response.json()['error'])
continue
num = response.json()['page_data']
final += sum(num)
print(f"第{i}页的数据:{num}")
i += 1
print(f"100页的和:{final}")T13 第一代验证码2

过程类似,这里不继续对此类进行编写。
T21 摘要算法

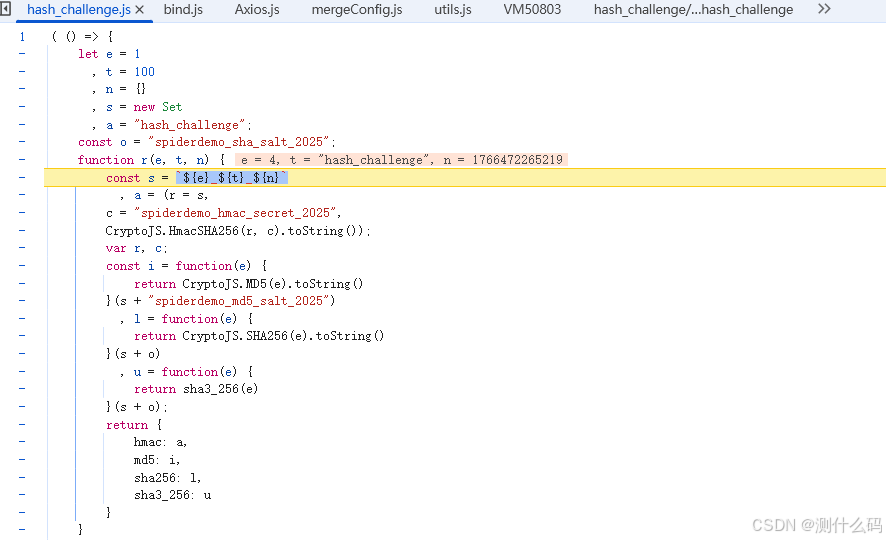
查看请求,发现sign和code加密参数,直接查看堆栈,进入到加密位置,会生成四个加密参数,两个为请求头x-request-token=>a和x-verify-code=>i,两个为请求参数sign=>l和code=>u。
根据题目给出的信息也很好判断具体加密过程,直接喂给ai,生成py代码,请求接口。
import hashlib
import hmac
import requests
import time
class SpiderDemoEncryptor:
def __init__(self):
self.o = "spiderdemo_sha_salt_2025"
self.hmac_secret = "spiderdemo_hmac_secret_2025"
self.md5_salt = "spiderdemo_md5_salt_2025"
def r(self, e, t, n):
"""
主加密函数,完全复现JavaScript中的加密逻辑
参数:
e: 页码或其他参数
t: 固定字符串或参数
n: 时间戳
返回: 包含四种哈希值的字典
"""
# 构建基本字符串: e_t_n
s = f"{e}_{t}_{n}"
# 1. 计算HMAC-SHA256
hmac_result = self._hmac_sha256(s, self.hmac_secret)
# 2. 计算MD5 (s + md5_salt)
md5_result = self._md5(s + self.md5_salt)
# 3. 计算SHA256 (s + sha_salt)
sha256_result = self._sha256(s + self.o)
# 4. 计算SHA3-256 (s + sha_salt)
sha3_256_result = self._sha3_256(s + self.o)
return {
"hmac": hmac_result,
"md5": md5_result,
"sha256": sha256_result,
"sha3_256": sha3_256_result
}
def _hmac_sha256(self, message, secret):
"""使用hmac和hashlib计算HMAC-SHA256"""
return hmac.new(
secret.encode('utf-8'),
message.encode('utf-8'),
hashlib.sha256
).hexdigest()
def _md5(self, text):
"""使用hashlib计算MD5哈希值"""
return hashlib.md5(text.encode('utf-8')).hexdigest()
def _sha256(self, text):
"""使用hashlib计算SHA256哈希值"""
return hashlib.sha256(text.encode('utf-8')).hexdigest()
def _sha3_256(self, text):
"""使用hashlib计算SHA3-256哈希值"""
# hashlib.sha3_256需要Python 3.6+
return hashlib.sha3_256(text.encode('utf-8')).hexdigest()
headers = {
"accept": "application/json, text/plain, */*",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"pragma": "no-cache",
"priority": "u=1, i",
"referer": "https://www.spiderdemo.cn/authentication/hash_challenge/?challenge_type=hash_challenge",
"sec-ch-ua": "\"Google Chrome\";v=\"143\", \"Chromium\";v=\"143\", \"Not A(Brand\";v=\"24\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
"x-request-token": "cc497e1b95f45c22fcd8a279d3dedc2cdef6c88c7d13d1e91b76c06cc1f558f3",
"x-verify-code": "6a22b2636ca50cedba66891bc3564630"
}
cookies = {
"sessionid": "xxxx"
}
encryptor = SpiderDemoEncryptor()
final = 0
for i in range(1,101):
timestamp = int(time.time() * 1000)
# 页码、固定字符、时间戳
result = encryptor.r(i, "hash_challenge", timestamp)
url = f"https://www.spiderdemo.cn/authentication/api/hash_challenge/page/{i}/"
headers['x-request-token'] = result['hmac']
headers['x-verify-code'] = result['md5']
params = {
"challenge_type": "hash_challenge",
"sign": result['sha256'],
"code": result['sha3_256'],
"t": timestamp
}
response = requests.get(url, headers=headers, cookies=cookies, params=params)
num = response.json()['page_data']
final += sum(num)
print(f"第{i}页的数据: {num}")
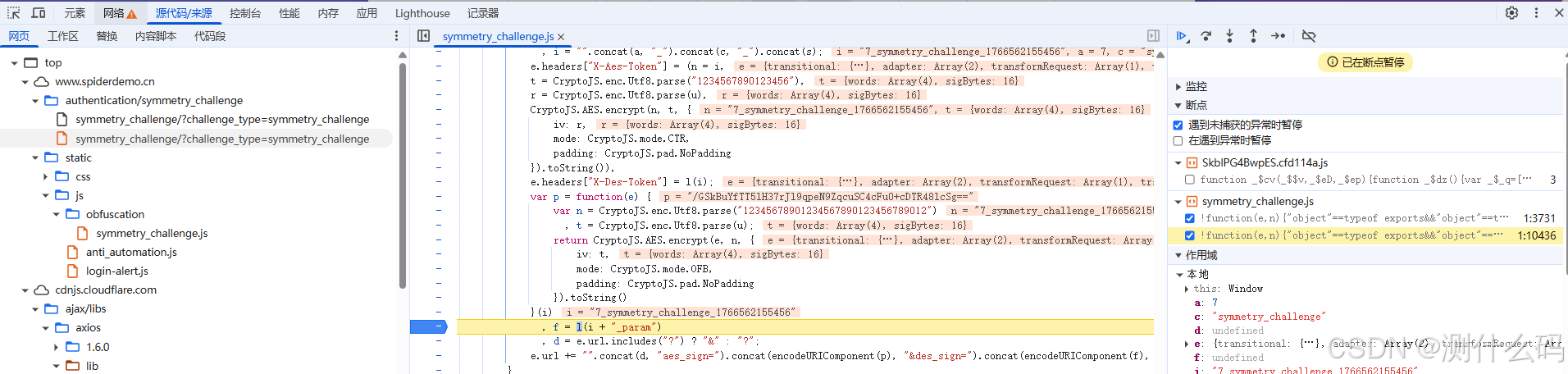
print(f"100页的和: {final}")T22 对称加密

查看请求,直接去看堆栈信息,跟到这,就知道加密的大概过程,还是喂给AI,直接模拟加密过程。
import base64
import requests
from Crypto.Cipher import AES, DES
from Crypto.Util.Padding import pad
from Crypto.Util import Counter
import time
# 如果需要完整复现JavaScript代码,这里还有一个更精确的版本
def exact_js_simulation(page, timestamp):
"""
精确模拟JavaScript代码,包括CryptoJS的细节
注意:由于CryptoJS和PyCryptodome在处理上可能有细微差异,
这个版本更接近原始JavaScript行为
"""
import hashlib
def crypto_js_like_aes_encrypt(data, key, iv, mode='CTR'):
"""
模拟CryptoJS的AES加密
CryptoJS默认使用CBC模式,但这里使用CTR/OFB
"""
# 确保key和iv是16/32字节
if mode == 'CTR':
cipher = AES.new(key, AES.MODE_CTR,
counter=Counter.new(128, initial_value=int.from_bytes(iv[:16], 'big')))
elif mode == 'OFB':
cipher = AES.new(key, AES.MODE_OFB, iv[:16])
else:
raise ValueError("Unsupported mode")
encrypted = cipher.encrypt(data.encode('utf-8'))
# CryptoJS的toString()返回Base64
return base64.b64encode(encrypted).decode('utf-8')
def crypto_js_like_des_encrypt(data, key, iv):
"""模拟CryptoJS的DES加密"""
cipher = DES.new(key, DES.MODE_CBC, iv)
# 使用PKCS7填充
padded_data = pad(data.encode('utf-8'), DES.block_size)
encrypted = cipher.encrypt(padded_data)
return base64.b64encode(encrypted).decode('utf-8')
# 参数
a = page
c = "symmetry_challenge"
s = timestamp
u = "abcdefghijklmnop"
# 构建i
i = f"{a}_{c}_{s}"
# 生成X-Aes-Token
aes_key1 = "1234567890123456".encode('utf-8')
iv1 = u.encode('utf-8')
x_aes_token = crypto_js_like_aes_encrypt(i, aes_key1, iv1, 'CTR')
# 生成X-Des-Token
des_key = "6f726c64".encode('utf-8')
des_iv = "01234567".encode('utf-8')
x_des_token = crypto_js_like_des_encrypt(i, des_key, des_iv)
# 生成p
aes_key2 = "12345678901234567890123456789012".encode('utf-8')
p = crypto_js_like_aes_encrypt(i, aes_key2, iv1, 'OFB')
# 生成f
f = crypto_js_like_des_encrypt(i + "_param", des_key, des_iv)
return {
'x_aes_token': x_aes_token,
'x_des_token': x_des_token,
'aes_sign': p,
'des_sign': f,
}
cookies = {
'sessionid': 'xxxx',
}
headers = {
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'no-cache',
'pragma': 'no-cache',
'priority': 'u=1, i',
'referer': 'https://www.spiderdemo.cn/authentication/symmetry_challenge/?challenge_type=symmetry_challenge',
'sec-ch-ua': '"Google Chrome";v="143", "Chromium";v="143", "Not A(Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-origin',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36',
'x-aes-token': '',
'x-des-token': '',
}
if __name__ == "__main__":
final = 0
for i in range(1, 101):
timestamp = int(time.time() * 1000)
result = exact_js_simulation(i, timestamp)
headers['x-aes-token'] = result['x_aes_token']
headers['x-des-token'] = result['x_des_token']
params = {
'challenge_type': 'symmetry_challenge',
'aes_sign': result['aes_sign'],
'des_sign': result['des_sign'],
't': f"{timestamp}",
}
response = requests.get(
f'https://www.spiderdemo.cn/authentication/api/symmetry_challenge/page/{i}/',
params=params,
cookies=cookies,
headers=headers,
)
data = response.json()
final += sum(data['page_data'])
print(f"第{i}页的数据: {data['page_data']}")
print(f"100页的数据和为: {final}")❤有空将持续更新❤

加入社区!打开量化的大门,首批课程上线啦!
更多推荐

 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)