
爬虫---豆瓣
模拟登录豆瓣的问题滑块验证码滑块验证码验证码在iframe子页面,需要browser.switch_to.frame()背景图豆瓣页面中可以加载到,但是单独请求src就拿不到响应! 为什么?滑块到缺口处的距离,是固定的。...
·
滑块验证码
- 验证码在iframe子页面,需要切换,browser.switch_to.frame(iframe_node)
- 背景图 <img src=“xxx”> 豆瓣页面中可以加载到,但是单独请求src就拿不到响应! 为什么?
因为请求的地址是跨源的,为
https://t.captcha.qq.com/hycdn;
而原始页面的地址为
https://accounts.douban.com/passport/login?source=movie
跨源发送GET请求,而此t.captcha.qq.com服务器需要验证Cookie等信息才可以返回图片数据。在原始页面中的<img src=“xxx”>跨源取资源时,除了发送GET请求,还把Cookie等信息带到服务端验证,所以服务端正常返回数据,如图: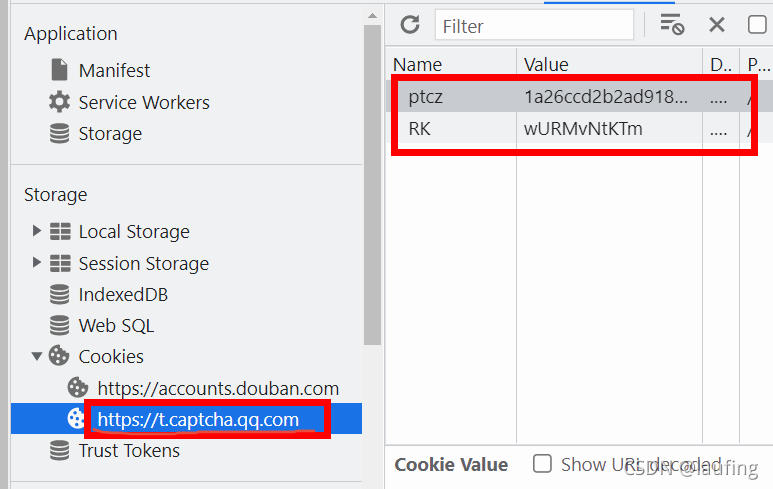
而自己新打开标签页,并没有域名t.captcha.qq.com的Cookie信息,服务端验证失败,所以不返回数据。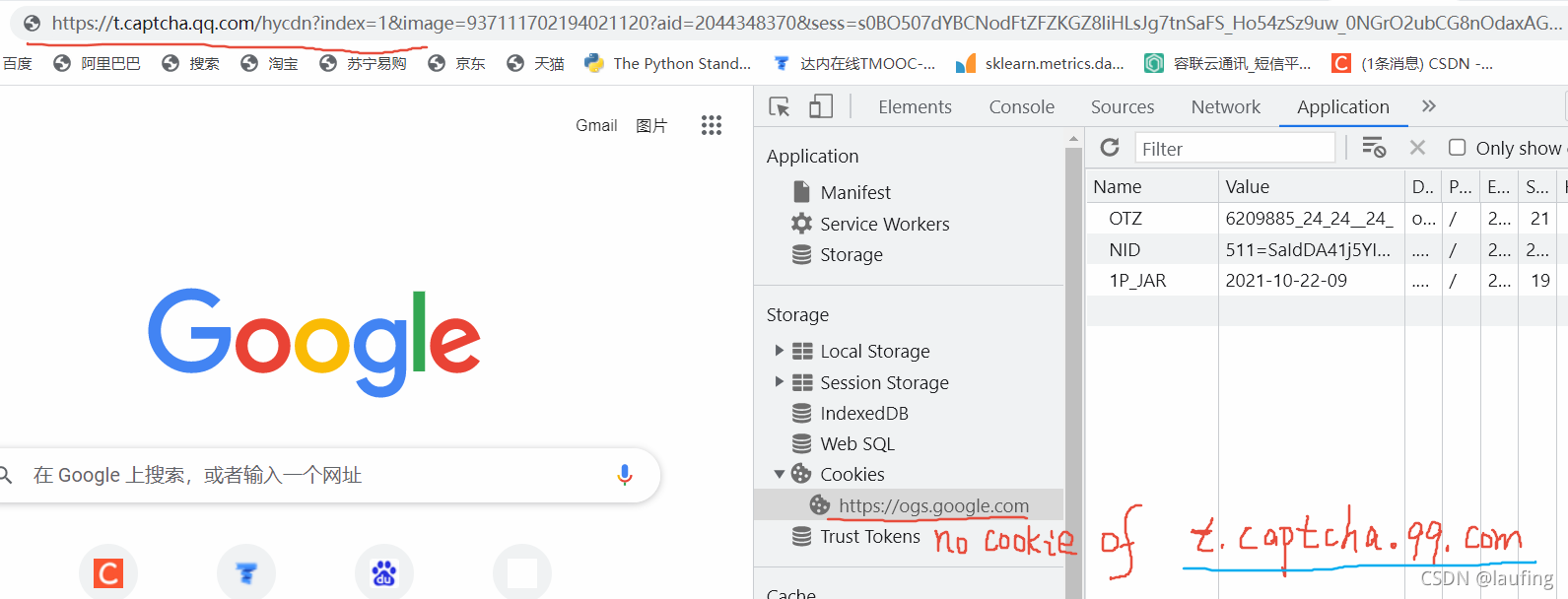
获取图片的代码:
#导入请求库
import requests
#导入自己封装的包,随机产生一个user-agent
from lauf_useragent import UserAgent
#伪装一下请求头
headers = {
"User-Agent":UserAgent().get(),
}
#Cookie信息搞里头
cookies = {
"ptcz":"1a26ccd2b2ad918085c7f2e0317cfc46f83ece0daf6f9430476dc19eeeac289f",
"RK":"wURMvNtKTm",
}
# 加载图片的地址搞出来
url = "https://t.captcha.qq.com/hycdn?index=1&image=937111702194021120?aid=2044348370&sess=s0BO507dYBCNodFtZFZKGZ8liHLsJg7tnSaFS_Ho54zSz9uw_0NGrO2ubCG8nOdaxAGmSzOkNw07vRPz1TQ0t500ZCndJKrEnuEGc8f47LrgwksQGeCUl6gXAEBbbLybqSmmyp13ct3tlz9XtumegsC6KzBE9l5WBVXoYMlfItc0weo6U1k-O1V_vgZVODEZCL-2QYPv2GS8Mq-_TgWodQLNvUPY5DFX2tg97eINs1HaLOOG994NAvNeYaMGiKRheq5TSD7F_ALHcKCGyFP8pZ1rt7BSRvsw_eCTx_Vd1lb9SujIUymbEarA**&sid=6857250570733109249&img_index=1&subsid=3"
#发送请求,葱、姜、胡椒粉、辣椒面、生抽、老抽搞里头
res = requests.get(url,headers=headers,cookies=cookies)
print(res.content)
#服务端给字节烤串,吃不完,保存起来。
with open("bg.png","wb") as f:
f.write(res.content)
注意cookie很快过期
- 滑块到缺口处的距离,是固定的,只需分析出一个距离即可,后续每次拖动滑块,都移动该距离。
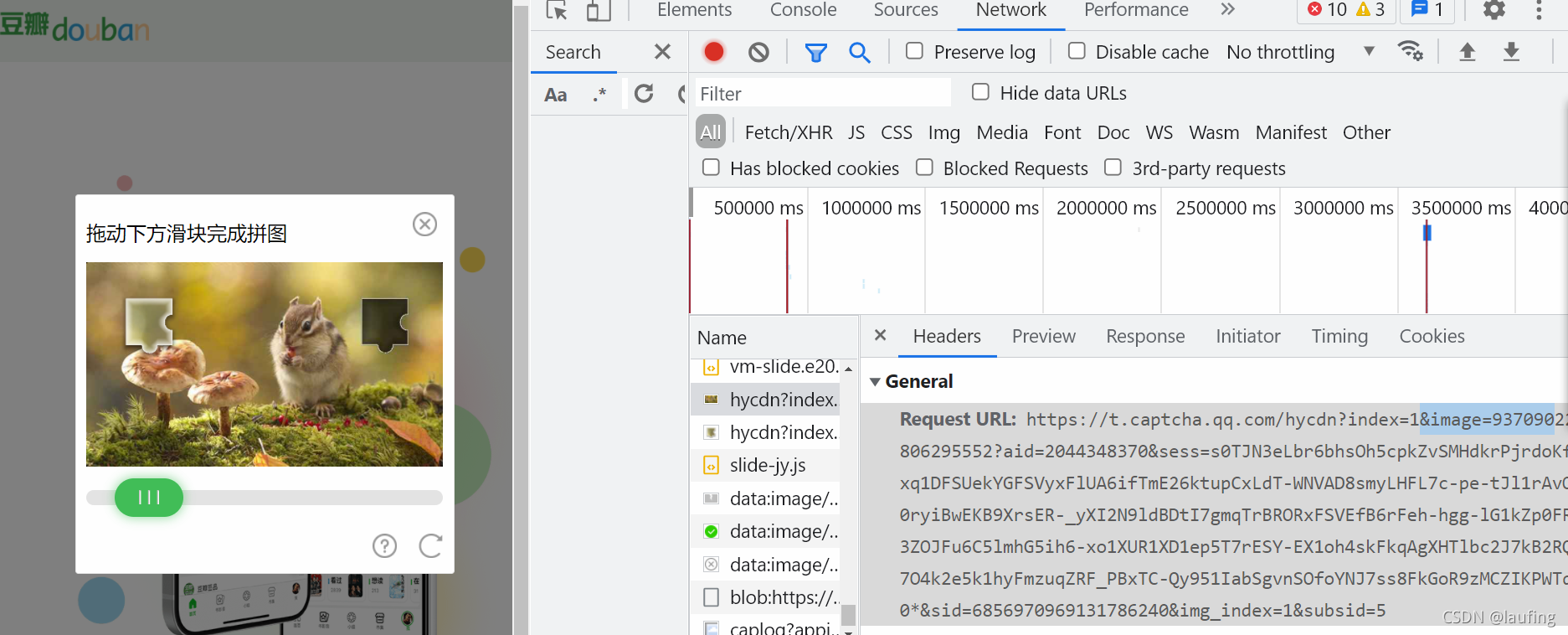
解析滑块到缺口的距离,搞起来。
#browser.get_cookies() 获取当前会话中的Cookie字典集合
#不能跨源,且browser不能切换到内部iframe
#browser.delete_all_cookies()
#browser.add_cookie({"domain":"xxx",})
#r = browser.execute_script("return localStorage.getItem('name')")
- 任意的js混淆粑粑,都可以搞一搞断点测试。
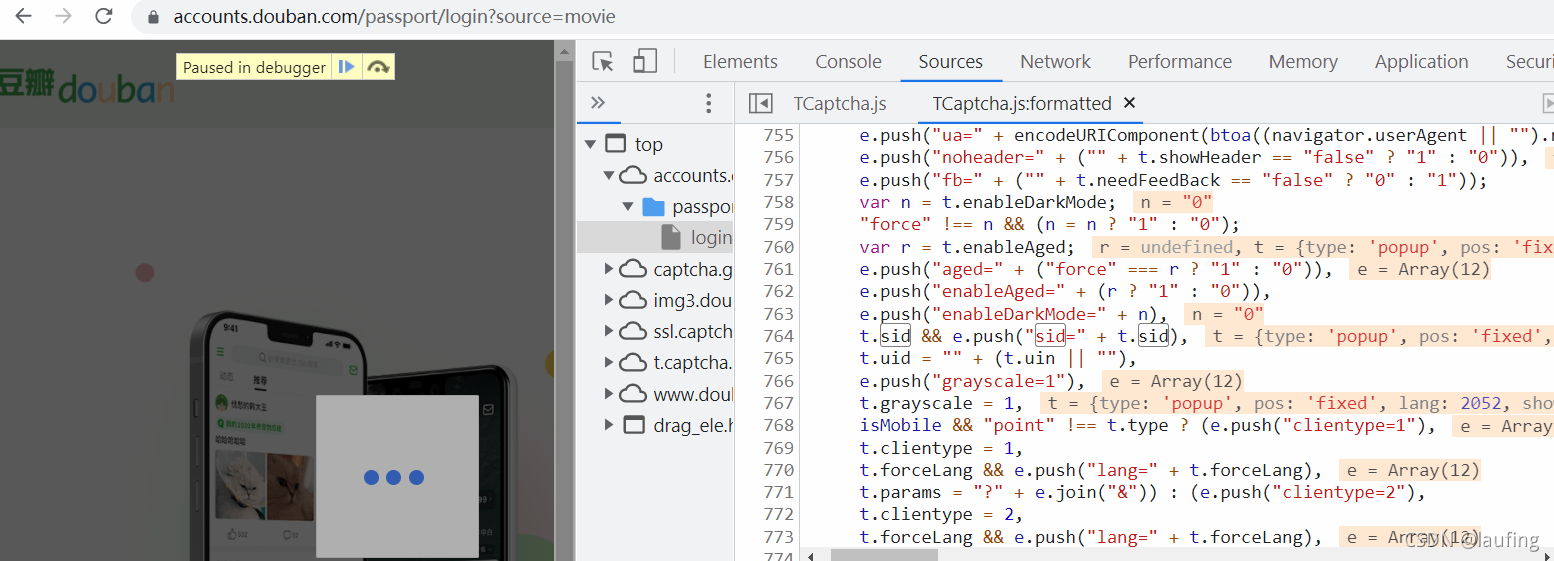
完整项目代码
"""
爬虫程序中的Cookie过期后,使用该脚本,重新登录--->获取Cookie
豆瓣的滑块验证码,缺口与滑块之间的距离固定,模拟人滑动固定距离
"""
from numpy.core.defchararray import translate
from selenium import webdriver
from selenium.webdriver import ActionChains
import time
import random
import base64
from PIL import Image
import io
import numpy as np
#获取移动的一小段
def getTracks(distance,delay=2):
"""(1 - (0.5)^k)*distance"""
offset = 0
tracks = []
for i in np.arange(0.1,delay,0.1):
s = round((1 - np.power(0.5,7*i))*distance)
delta = s - offset
tracks.append(delta)
offset += delta
#最后一段 移动
tracks.append(distance - offset)
return tracks
options = webdriver.ChromeOptions()
options.add_argument("--headless")
browser = webdriver.Chrome()
url = "https://movie.douban.com/"
#open the page
browser.get(url)
#give some time to browser to load page
time.sleep(random.uniform(1,2))
#parse node
browser.find_element_by_xpath('//*[@id="db-global-nav"]/div/div[1]/a').click()
#give browser some time to load login page
time.sleep(random.uniform(1,2))
#find the "password login" node and check if it inside iframe
# here it is not in iframe, so it is easy to find this node,then click.
browser.find_element_by_xpath('//*[@id="account"]/div[2]/div[2]/div/div[1]/ul[1]/li[2]').click()
#get the username node,then input account
browser.find_element_by_xpath('//*[@id="username"]').send_keys('17335320686')
#get the password node,then input password
browser.find_element_by_xpath('//*[@id="password"]').send_keys("laufing123")
#click login
browser.find_element_by_xpath('//*[@id="account"]/div[2]/div[2]/div/div[2]/div[1]/div[4]/a').click()
#give enough time to browser for loading slide code
time.sleep(random.uniform(2,3))
# solve slide code which inside iframe,so need to switch_to
iframe = browser.find_element_by_xpath('//*[@id="tcaptcha_iframe"]')
#cookies = browser.get_cookies() #当前会话中的Cookie字典集合
browser.switch_to.frame(iframe)
time.sleep(1)
#find slide button
slide_button = browser.find_element_by_xpath('//*[@id="tcaptcha_drag_button"]')
#get bg image 滑块背景图
bg_img_url = browser.find_element_by_xpath('//*[@id="slideBg"]').get_attribute("src")
#让该窗口浏览器去拿图片,可以拿到,但是整个页面就切换了
# browser.get(bg_img_url)
#解码base64编码的数据
#image/png;base64,iVBORw0KGgoAAAANSUhEUgAAAEQAAAAnCAYAAAC2c+5GAAAAZ0lEQVRoge3QMRHAMBDAsCT8YT6PZutgAu0gIfB5z8yzeJ2vA/7GkDAkDAlDwpAwJAwJQ8KQMCQMCUPCkDAkDAlDwpAwJAwJQ8KQMCQMCUPCkDAkDAlDwpAwJAwJQ8KQMCQMCUPCkLgMcgP5gqyNnwAAAABJRU5ErkJggg==
# b64encode_data = bg_img_data.split(",")[1]
# bytes_data = base64.b64decode(b64encode_data)
# with open("img1.png","wb") as f:
# f.write(bytes_data)
# img_obj = Image.open(io.BytesIO(bytes_data))
# img_obj.show()
# img_obj.save("bg_img.png")
# browser.switch_to.parent_frame()
#滑动滑块
action_chains = ActionChains(browser)
action_chains.click_and_hold(slide_button).perform()
distance = 216
#快速移动
ActionChains(browser).move_by_offset(distance*0.8,0).perform()
#剩下的距离缓慢移动
tracks = getTracks(distance*0.2)
print(tracks)
for i in tracks:
ActionChains(browser).move_by_offset(i,0).perform()
action_chains.pause(0.5).release().perform()
time.sleep(random.uniform(0.5,1))
#scan to login
try:
scan_node = browser.find_element_by_xpath('//*[@id="account"]/div[2]/div[2]/div/div[3]/div[1]/div[1]')
print("abnormal:",scan_node.text)
except:
print("normal to login")
time.sleep(100)
browser.quit()

加入社区!打开量化的大门,首批课程上线啦!
更多推荐

 0
0 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)