
爬虫初学----爬取古诗文网数据
1.首先分析需要爬取网站的情况:分析一下地址,找到其中的规律URL前面都是一样的,在“.html”前的数字不一样,这个数字就是对应的页面。右键单击检查右键 复制 选择复制XPath得到 依次卷一 卷二 卷三 多复制几列对比一下:在控制台验证下输入得到成功了。
爬取网址:https://www.diyifanwen.com/guoxue/quantangshi/
1.首先分析需要爬取网站的情况:
卷一:https://www.diyifanwen.com/guoxue/quantangshi/233258094232332581650067.htm
卷二:https://www.diyifanwen.com/guoxue/quantangshi/233258094232332581287227.htm
卷三:https://www.diyifanwen.com/guoxue/quantangshi/23325809423233258893726.htm
分析一下地址,找到其中的规律
URL前面都是一样的,在“.html”前的数字不一样,这个数字就是对应的页面。
右键单击检查
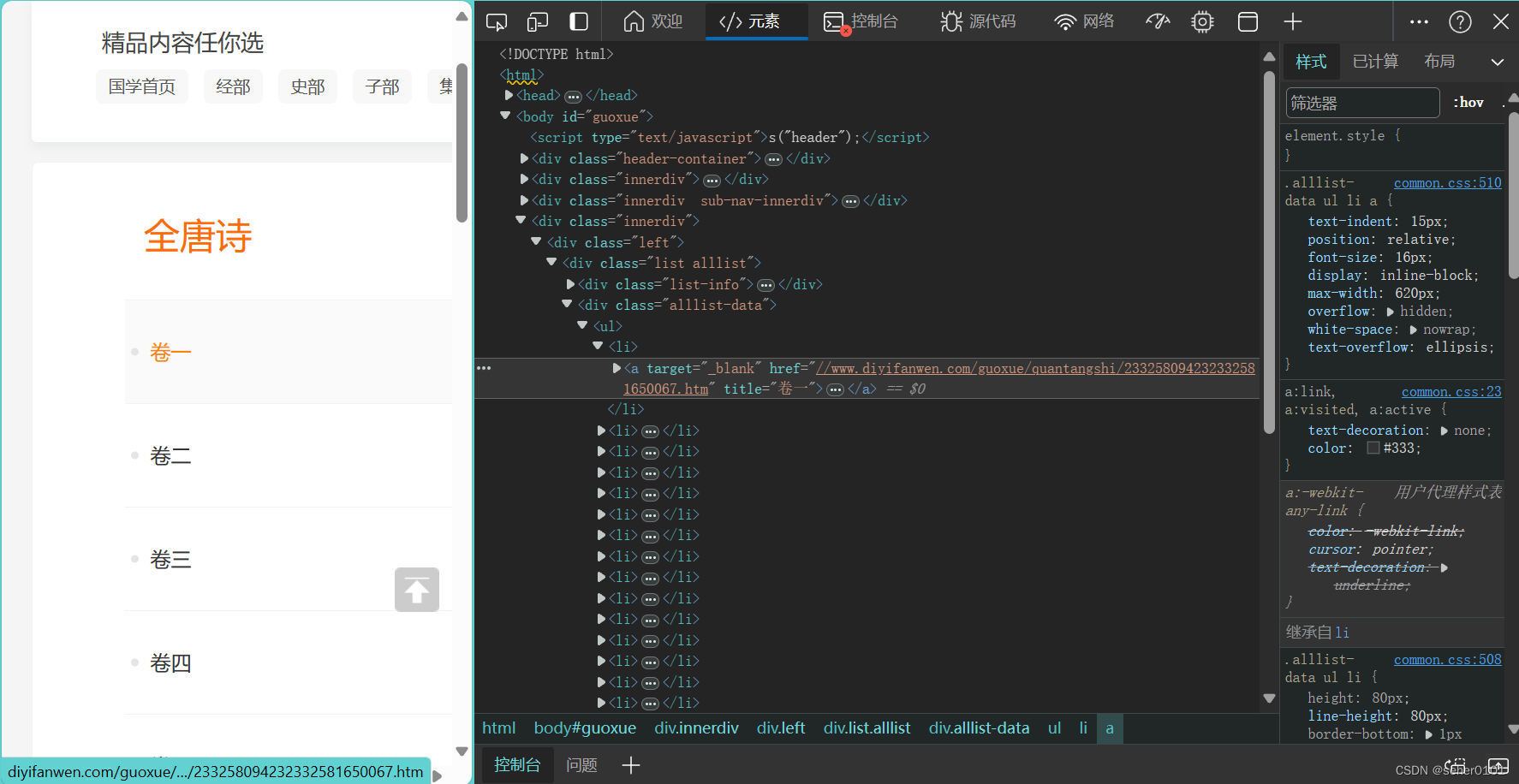
右键 复制 选择复制XPath
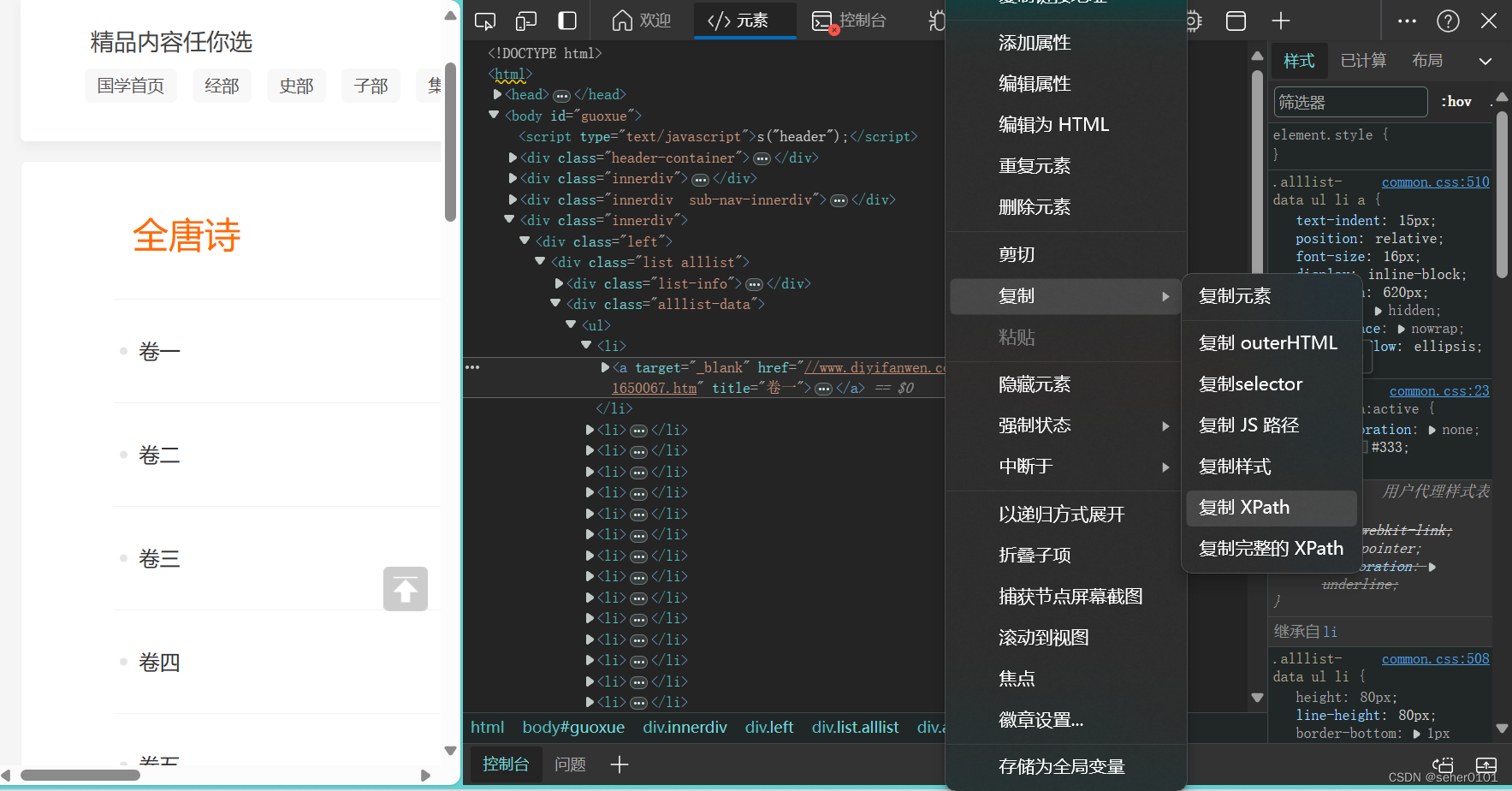
得到 依次卷一 卷二 卷三 多复制几列对比一下:
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[1]/a
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[2]/a
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[3]/a
在控制台验证下
输入
&x('//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[1]/a')
得到

成功了
下一步 找请求表头:右键 ——> 检查 ——> Network ——> Doc ——> 在 Name 里找到对应的请求文件 ——> 在右边选择 Headers 标签页,找到“Request Headers”,就可以看到我们发送给服务器的 headers
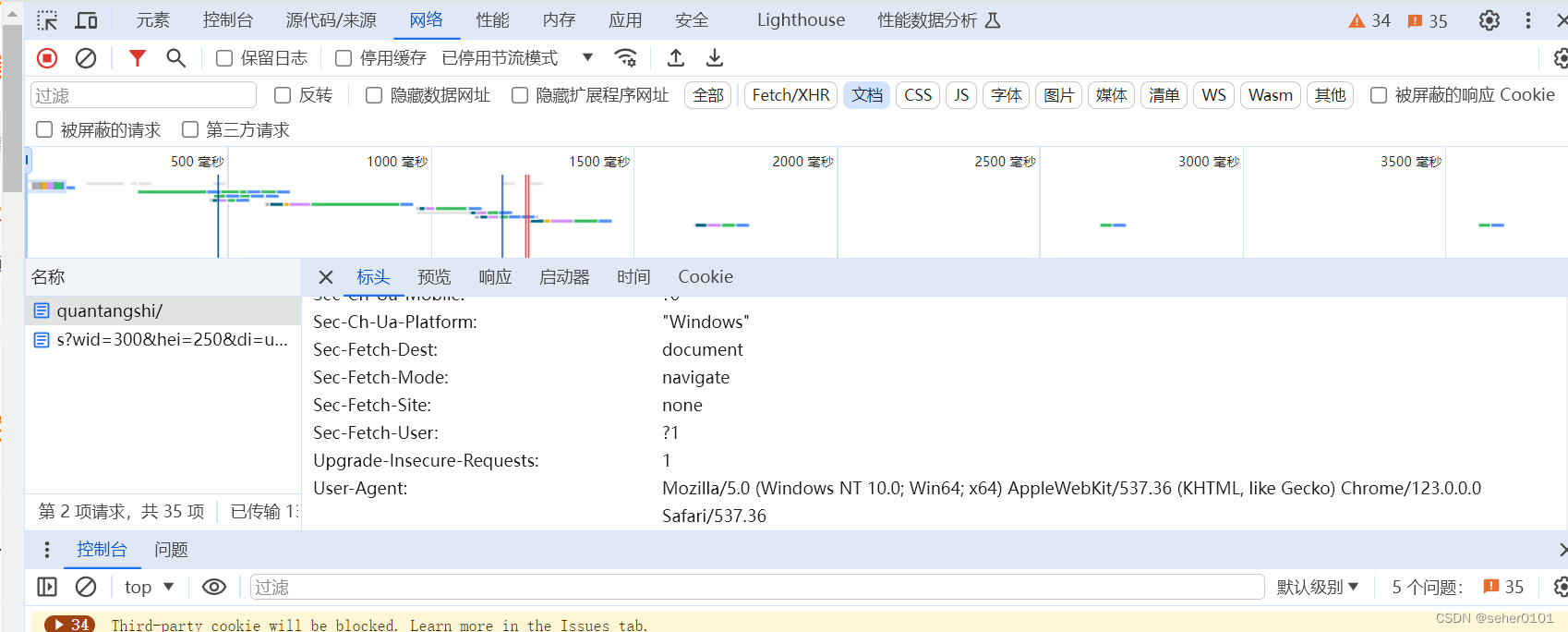
做完准备工作,我们来测试下运行情况。现在开始写代码:
改代码遇到了以下问题
报错1:from lxml import etree 导入模块报错
解决:pip install lxml
报错2:输出<Element a at 0x39a9a80>
或者类似 Element a at 0x???????,这样的一个值,某种意义上来说,当你打印变量的时候得到的这个值,其实它是一个列表,然后列表中的每一个值都是一个字典
解决:
for index in range(len(name_list)):
# links[index]返回的是一个字典
if (index % 2) == 0:
print(name_list[index].tag)
print(name_list[index].attrib)
print(name_list[index].text)
- Element类型是'lxml.etree._Element',某种意义来说同时是一个列表
- 列表的需要使用tag\attrib\text三个不同的属性来获取我们需要的东西
- 变量.tag获取到的是标签名是---字符串
- 变量.attrib获取到的是节点标签a的属性---字典
- 变量.text获取到的是标签文本--字符串
代码:
import requests
from lxml import html
etree = html.etree
import time
url = 'https://www.diyifanwen.com/guoxue/quantangshi/'
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
data = requests.get(url, headers=header).text
html=data.encode('ISO 8859-1')
f = etree.HTML(html)
name_list = f.xpath('//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[1]/a')
for index in range(len(name_list)):
# links[index]返回的是一个字典
if (index % 2) == 0:
print(name_list[index].tag)
print(name_list[index].attrib)
print(name_list[index].text)
为了显示当前页所有的数据,我们根据前面xpath路径的对比,我们把路径修改一下试试
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[1]/a
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li/a
成功啦
import requests
from lxml import html
etree = html.etree
import time
url = 'https://www.diyifanwen.com/guoxue/quantangshi/'
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
data = requests.get(url, headers=header).text
html=data.encode('ISO 8859-1')
f = etree.HTML(html)
name_list = f.xpath('//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li/a')
for index in range(len(name_list)):
# links[index]返回的是一个字典
if (index % 2) == 0:
print(name_list[index].tag)
print(name_list[index].attrib)
print(name_list[index].text)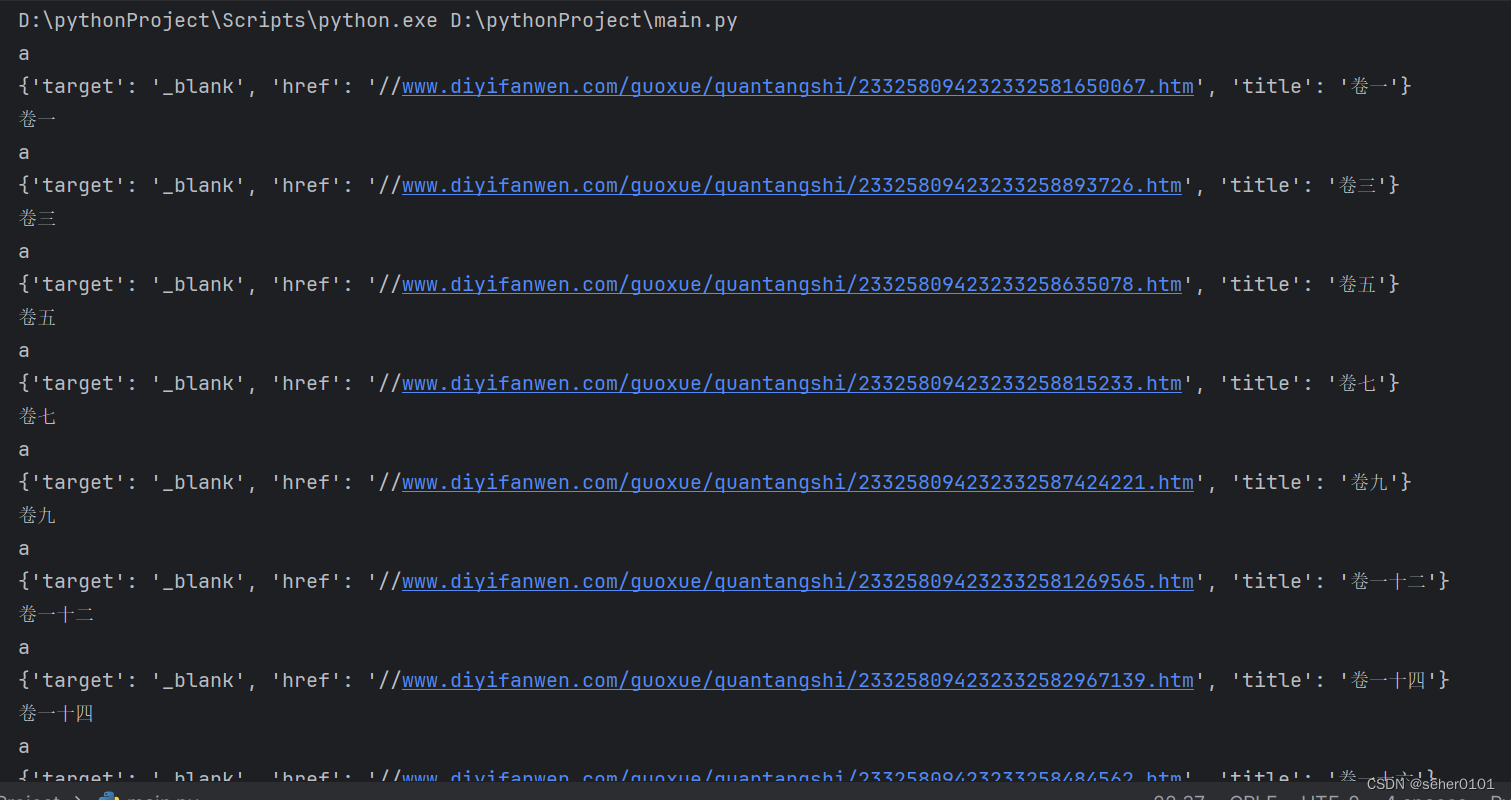
成功爬取了第一页数据
分析不同页url:
https://www.diyifanwen.com/guoxue/quantangshi/
https://www.diyifanwen.com/guoxue/quantangshi/index_2.html
https://www.diyifanwen.com/guoxue/quantangshi/index_3.html
最后一页https://www.diyifanwen.com/guoxue/quantangshi/index_20.html
我们原来URL尾部数值进行处理,使用for语句进行循环。range的数值,根据我们需要爬取的页数确认。这里设置的范围为1~20页的数据
原:
url = 'https://www.diyifanwen.com/guoxue/quantangshi/'
修改为
for i in range(1,20):
if i == 1:
url1 = 'https://www.diyifanwen.com/guoxue/quantangshi/'
else:
url = 'https://www.diyifanwen.com/guoxue/quantangshi/index_'
url1 = url+str(i)+str('.html')分析不同页面xpath差别:
第一页:
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[1]/a
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li/a
第二页:
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[1]/a
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[2]/a
第十页:
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[1]/a
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[2]/a
第二十页:
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[1]/a
//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li[2]/a
好好好 每个页面xpath相同
import requests
from lxml import html
etree = html.etree
import time
for i in range(1,20):
if i == 1:
url1 = 'https://www.diyifanwen.com/guoxue/quantangshi/'
else:
url = 'https://www.diyifanwen.com/guoxue/quantangshi/index_'
url1 = url+str(i)+str('.html')
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
data = requests.get(url1, headers=header).text
html=data.encode('ISO 8859-1')
f = etree.HTML(html)
name_list = f.xpath('//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li/a')
for index in range(len(name_list)):
# links[index]返回的是一个字典
if (index % 2) == 0:
print(name_list[index].tag)
print(name_list[index].attrib)
print(name_list[index].text)运行结果
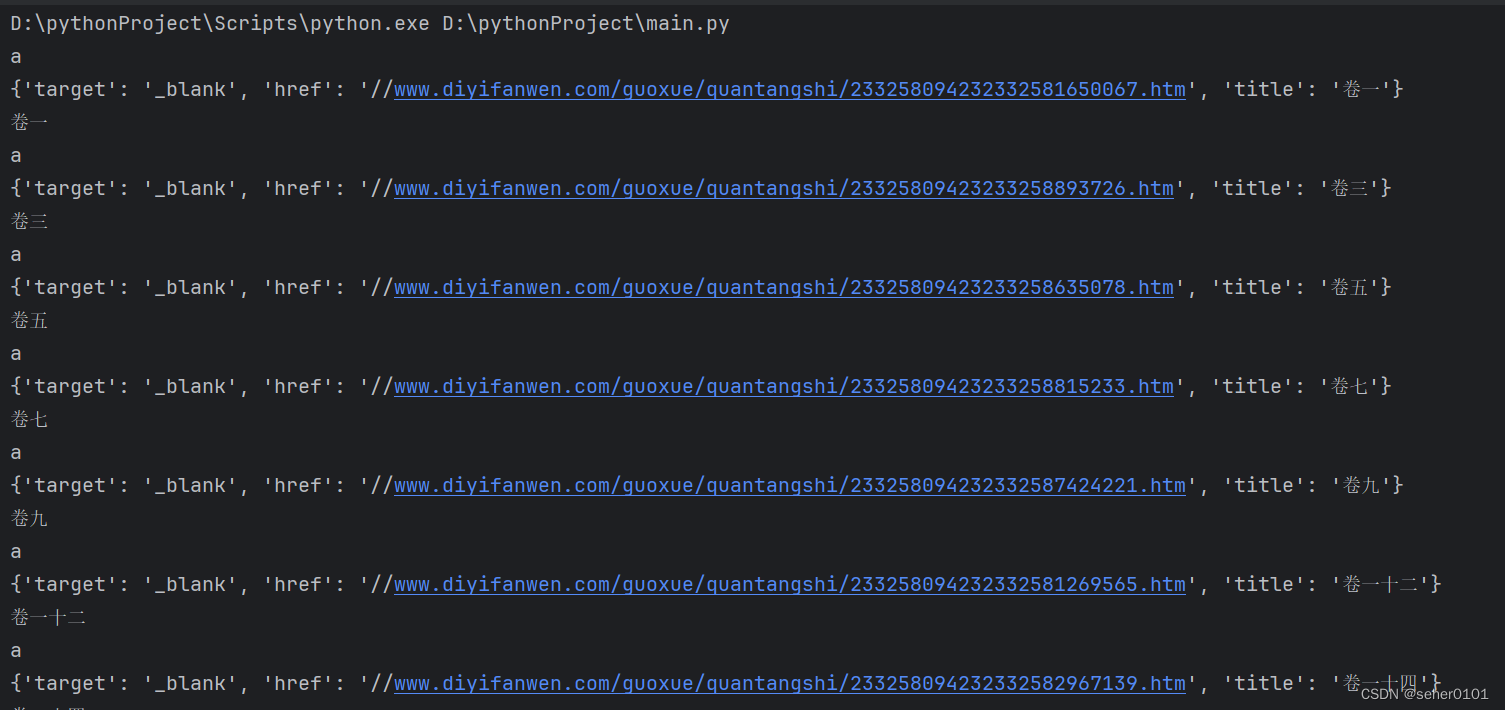
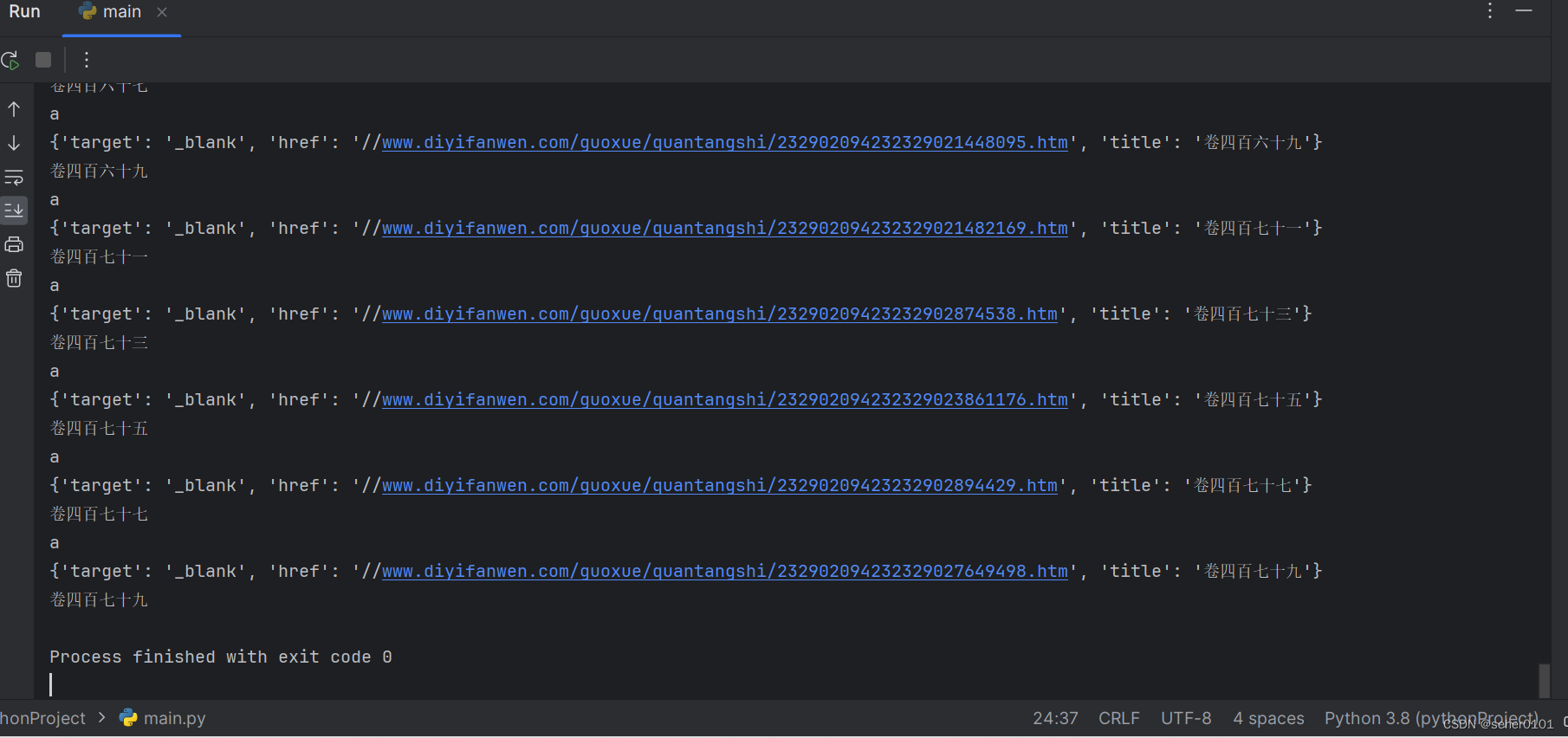
下来进行第二部分:对爬取的数据进行保存
我们接着开始写上我们的数据保存代码,我们这里把数据保存为CSV文件。
import csv #引用CSV
fp = open('需要保存的位置和文件名.csv',newline='',encoding='utf_8_sig')
writer = csv.writer(fp)
...
...
..
writer.writerow((name,company,address,money))#放在内容输出的位置。把每一条数据都保存下来
import requests
from lxml import html
etree = html.etree
import time
import csv #引用CSV
fp = open('D:/quantangshi.csv','wt',newline='',encoding='utf_8_sig')
writer = csv.writer(fp)
for i in range(1,20):
if i == 1:
url1 = 'https://www.diyifanwen.com/guoxue/quantangshi/'
else:
url = 'https://www.diyifanwen.com/guoxue/quantangshi/index_'
url1 = url+str(i)+str('.html')
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
data = requests.get(url1, headers=header).text
html=data.encode('ISO 8859-1')
f = etree.HTML(html)
name_list = f.xpath('//*[@id="guoxue"]/div[4]/div[1]/div/div[2]/ul/li/a')
for index in range(len(name_list)):
# links[index]返回的是一个字典
if (index % 2) == 0:
#print(name_list[index].tag)
print(name_list[index].attrib)
print(name_list[index].text)
writer.writerow((name_list[index].attrib,name_list[index].text))
fp.close()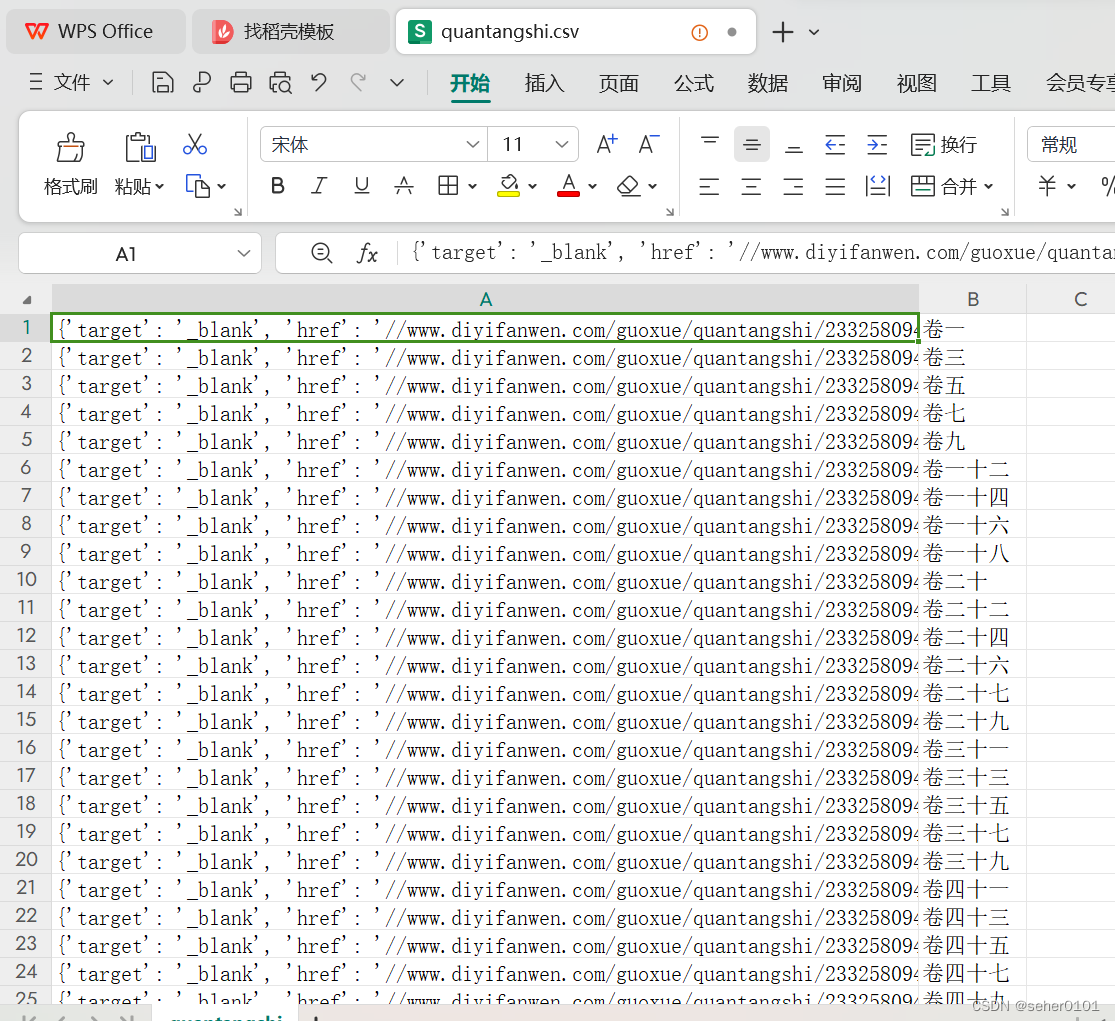
第三步 爬取二级页面
页面的构成:二级页面是点击一级页面跳转的。
解决思路:
1、在一级页面中获取二级页面的链接
2、在二级二面中获取想要的数据。
卷一每一页:https://www.diyifanwen.com/guoxue/quantangshi/233258094232332581650067.htm
https://www.diyifanwen.com/guoxue/quantangshi/233258094232332581650067_2.htm
https://www.diyifanwen.com/guoxue/quantangshi/233258094232332581650067_8.htm
找到规律
for i in range(1,8):
if i == 1:
url1 = 'https://www.diyifanwen.com/guoxue/quantangshi/233258094232332581650067.htm'
else:
url = 'https://www.diyifanwen.com/guoxue/quantangshi/233258094232332581650067_'
url1 = url+str(i)+str('.htm')//*[@id="guoxue"]/div[3]/div[1]/div[1]/div[3]/text()[1]
//*[@id="guoxue"]/div[3]/div[1]/div[1]/div[3]/text()[2]
//*[@id="guoxue"]/div[3]/div[1]/div[1]/div[3]/text()[44]
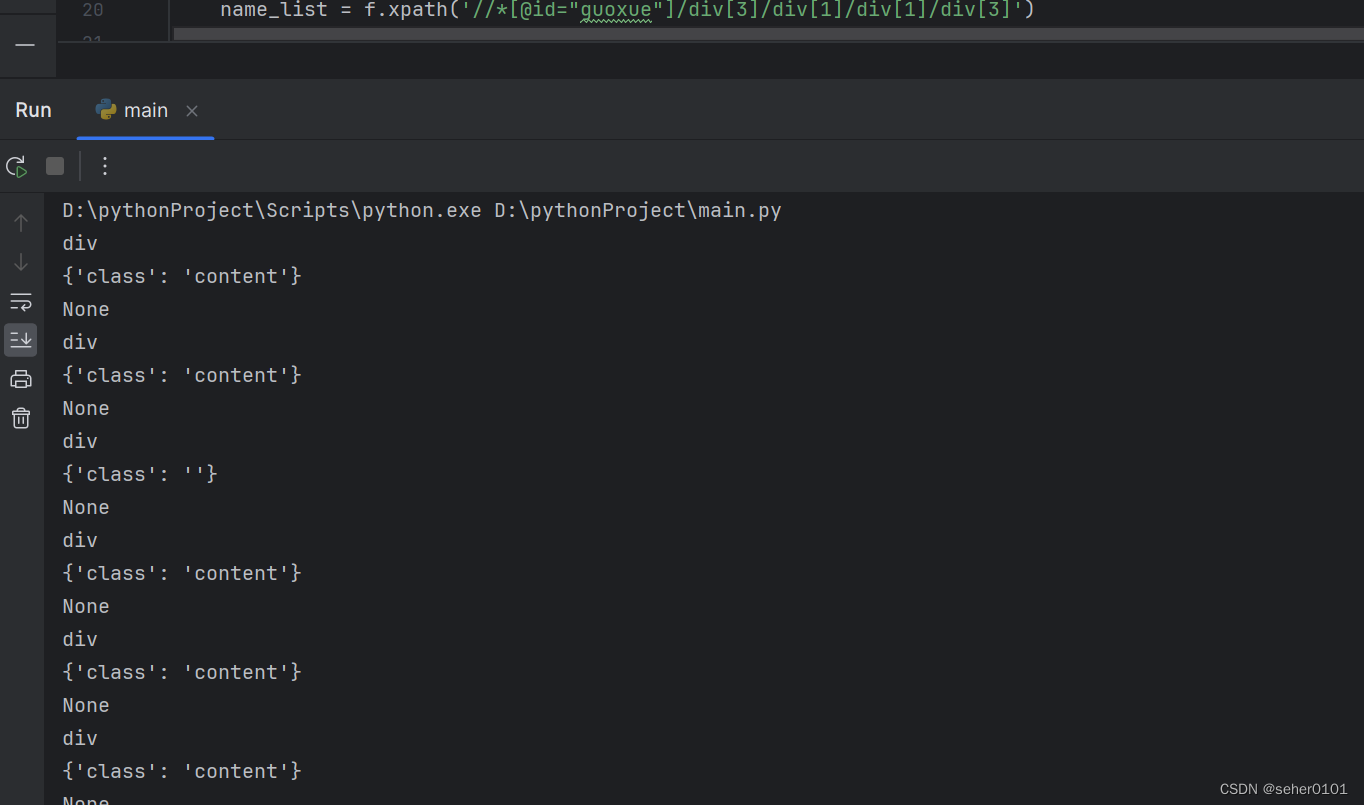
输出错误 找原因
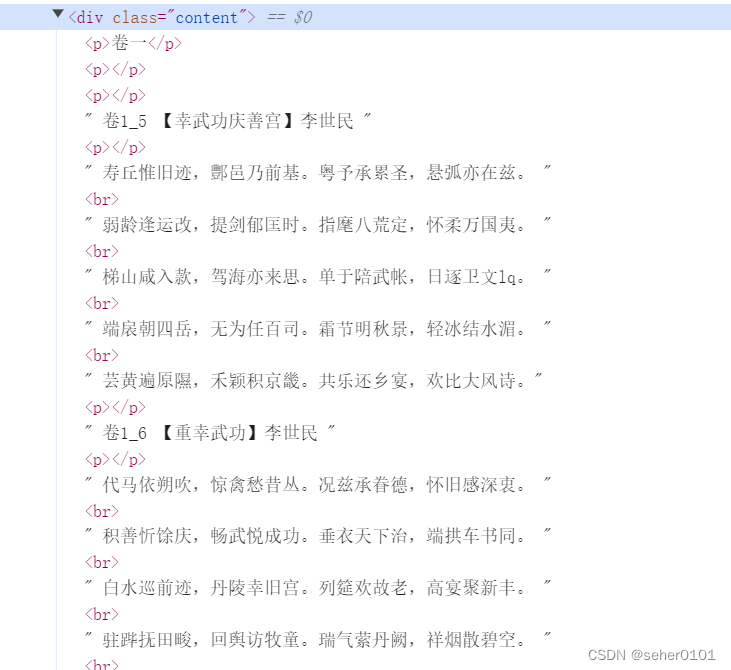
Python爬虫遇到网页中含有br标签,抓取相关的内容结果是None。为什么xpath爬取不到br标签后的内容?这是因为br标签可以表示数据的开始,也可以表示数据的结束。br标签的作用是在文本中换行。
br标签的作用是在文本中换行,它与python中换行符\n作用比较相似,每一次的出现都代表一次换行。同时,它也是一个空元素(只有一个开始标签,没有结束标签,没有元素内容)。
所以我们可以先遍历目标变量,然后用""空字符串为分隔符,去替换br标签,最后用join方法去连接字符串。
import requests
from lxml import html
etree = html.etree
import time
import csv #引用CSV
#fp = open('D:/quantangshi1.csv','wt',newline='',encoding='utf_8_sig')
#writer = csv.writer(fp)
for i in range(1,8):
if i == 1:
url1 = 'https://www.diyifanwen.com/guoxue/quantangshi/233258094232332581650067.htm'
else:
url = 'https://www.diyifanwen.com/guoxue/quantangshi/233258094232332581650067_'
url1 = url+str(i)+str('.htm')
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"}
data = requests.get(url1, headers=header).text
html=data.encode('ISO 8859-1')
f = etree.HTML(html)
name_list = f.xpath('//*[@id="guoxue"]/div[3]/div[1]/div[1]/div[3]')
for index in range(len(name_list)):
#links[index]返回的是一个字典
if (index % 2) == 0:
print(name_list[index].tag)
print(name_list[index].attrib)
print(name_list[index].text)
# writer.writerow((name_list[index].attrib,name_list[index].text))
#fp.close()关于爬取json内容生成词云(疯狂踩坑)
import jieba
import matplotlib.pyplot as plt
from wordcloud import WordCloud
import numpy as np
from PIL import Image # 图像处理
# 读取文本文件
text = open(r"/home/aistudio/data/output.txt", encoding="utf-8").read()
# 对文本进行分词,默认精确模式
text1=jieba.cut(text)
# 以空格作为分隔符,将分词后的所有字符串合并成一个新的字符串
text = ' '.join(text1)
# 根据分词结果产生词云
wc = WordCloud(font_path = "/home/aistudio/msyh1.ttc",width=500, height=400, mode="RGBA", background_color=None).generate(text)
# 以图片的形式显示词云
plt.imshow(wc, interpolation="bilinear")
# 不显示图像坐标系
plt.axis("off")
# 显示图像
plt.show()
#保存词云图
wc.to_file(r"home/aistudio/res.png")

加入社区!打开量化的大门,首批课程上线啦!
更多推荐

 20
20 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)