构建量化交易系统核心技术栈详解:从数据到实盘的全链路实践(含代码)
想亲手打造专属量化交易系统?这篇超硬核干货,手把手带你从0到1,深度解析数据、策略、执行、风控、监控五大核心技术栈!更有大量代码实战助你避坑,快速构建你的“交易印钞机”
1. 引言
量化交易系统是一个集数据处理、策略研究、高速执行、风险控制及系统运维于一体的复杂工程。本文旨在为读者提供一个从零开始构建量化交易系统的实践指南,详细阐述其核心技术栈,并通过具体的代码示例,帮助开发者深入理解每个模块的实现细节和技术选型考量。
我们将系统分为五个核心层级进行讲解:数据层、策略研究与回测层、交易执行层、风险管理层,以及监控与运维层。每个层级都将探讨其主要功能、涉及的技术挑战及相应的技术解决方案,并辅以Python或C++代码进行演示。
2. 数据层:量化交易系统的基石
数据是量化交易系统的生命线。高质量、低延迟的数据是策略有效性的前提。数据层主要负责数据的采集、清洗、存储和内部传输。
2.1 数据采集与清洗
数据源多样,包括交易所API、券商API、第三方数据服务商或自建爬虫。原始数据常包含缺失值、异常值、格式不统一等问题,需要进行严格清洗和预处理。
- 技术选型: Python是数据采集和清洗的主流语言,尤其
Pandas库提供了强大的数据处理能力。 - 代码示例:使用Pandas进行数据清洗
# 数据清洗示例:处理缺失值与异常值
import pandas as pd
import numpy as np
# 模拟原始K线数据,包含NaN和异常大值
raw_kline_data = pd.DataFrame({
'timestamp': pd.to_datetime(['2023-01-01', '2023-01-01', '2023-01-02', '2023-01-02', '2023-01-03']),
'symbol': ['AAPL', 'GOOG', 'AAPL', 'GOOG', 'AAPL'],
'close_price': [170.0, 95.0, 171.5, np.nan, 172.0], # 模拟缺失值
'volume': [1000, 2000, 1200, 50000000, 1500] # 模拟异常值
})
print("--- 原始数据 ---")
print(raw_kline_data)
# 1. 缺失值处理:使用前一个有效值填充(ffill)
cleaned_data = raw_kline_data.fillna(method='ffill')
# 2. 异常值处理:例如,将交易量超过某个阈值的视为异常并处理
volume_anomaly_threshold = 1_000_000
cleaned_data['volume'] = cleaned_data['volume'].apply(lambda x: x if x < volume_anomaly_threshold else np.nan)
cleaned_data['volume'] = cleaned_data['volume'].fillna(method='ffill') # 再次填充处理异常后产生的NaN
# 3. 确保数据类型正确性
cleaned_data['close_price'] = pd.to_numeric(cleaned_data['close_price'])
cleaned_data['volume'] = pd.to_numeric(cleaned_data['volume'], errors='coerce') # coerce会将无法转换的值设为NaN
print("\n--- 清洗后的数据 ---")
print(cleaned_data)
2.2 数据存储方案
根据数据特性选择合适的存储方案,以实现高效的写入和查询。
-
时序数据库 (TSDB): 适用于高频行情数据(Tick、K线),例如KDB+ (高性能商业数据库) 或 InfluxDB (开源)。它们针对时间序列数据的写入和查询进行了优化。
-
关系型数据库 (RDBMS): 适用于基本面数据、财务数据、交易记录等结构化数据,如PostgreSQL、MySQL。
-
文件存储: 对于大规模数据集或需要高效批量读写场景,可采用HDF5、Parquet等列式存储格式。
-
代码示例:时序数据库写入(伪代码)
# 示例:向时序数据库写入Tick数据(伪代码)
# 实际操作需调用具体TSDB客户端API,如 InfluxDB-Python
from datetime import datetime
def write_tick_to_tsdb(timestamp: datetime, symbol: str, price: float, volume: int):
"""
模拟将Tick数据写入时序数据库。
在实际系统中,这将通过RPC调用或数据库客户端API完成。
"""
data_point = {
"measurement": "stock_ticks", # 测量名称
"time": timestamp, # 时间戳
"tags": {"symbol": symbol}, # 标签,用于快速过滤
"fields": {"price": price, "volume": volume} # 字段数据
}
# client.write_points([data_point]) # 实际的数据库写入操作
print(f"[TSDB] 写入: 时间={timestamp}, 标的={symbol}, 价格={price}, 量={volume}")
# 示例调用
# write_tick_to_tsdb(datetime.now(), "NVDA", 1000.5, 500)
2.3 数据传输机制
系统内部各模块之间的数据传输需要高效、低延迟。
-
消息队列 (Message Queue): 实现模块间异步解耦和数据流分发。Redis的Pub/Sub模式、Kafka、ZeroMQ等是常用选择。
-
共享内存: 在同一服务器内实现进程间超低延迟通信。
-
代码示例:Redis Pub/Sub实现数据传输(Python)
# 示例:使用Redis Pub/Sub实现模块间数据通信
import redis
import json
import time
import threading
# 假设Redis服务器运行在本地默认端口
r = redis.Redis(host='localhost', port=6379, db=0)
CHANNEL_NAME = 'market_data_feed'
# 模拟一个数据发布者(如行情接收模块)
def data_publisher():
print("[Publisher] 启动行情数据发布...")
for i in range(5):
data = {"symbol": "BTC", "price": 60000.0 + i * 100.0, "timestamp": time.time()}
r.publish(CHANNEL_NAME, json.dumps(data)) # 发布JSON格式数据
print(f"[Publisher] 发布数据: {data}")
time.sleep(0.5)
print("[Publisher] 数据发布结束。")
# 模拟一个数据订阅者(如策略模块)
def data_subscriber():
print("[Subscriber] 启动策略模块订阅行情...")
pubsub = r.pubsub()
pubsub.subscribe(CHANNEL_NAME) # 订阅指定频道
for message in pubsub.listen(): # 循环监听消息
if message['type'] == 'message':
decoded_data = json.loads(message['data'].decode('utf-8'))
print(f"[Subscriber] 接收到行情: {decoded_data}")
# 实际策略会在这里处理行情数据,生成交易信号
# 在多线程中运行发布者和订阅者以演示并发
if __name__ == "__main__":
publisher_thread = threading.Thread(target=data_publisher)
subscriber_thread = threading.Thread(target=data_subscriber)
publisher_thread.start()
subscriber_thread.start()
# 等待发布者完成,订阅者会持续监听直到程序关闭
publisher_thread.join()
# 实际应用中订阅者线程会长时间运行
# subscriber_thread.join() # 这里不join订阅者,让其保持监听
3. 策略研究与回测层:量化思想的验证平台
本层负责将量化交易思想转化为可执行的策略代码,并在历史数据上进行模拟验证(回测),以评估策略的有效性和鲁棒性。
3.1 策略开发语言与库
- Python: 作为数据科学和机器学习的主流语言,Python凭借其丰富的库(Pandas, NumPy, SciPy, Scikit-learn, TensorFlow/PyTorch)成为策略开发的首选。
- R/Julia: 在统计建模和数值计算领域也有应用。
3.2 回测框架与实现
回测框架提供了一个模拟真实市场环境的“沙盘”,用于测试策略。它会按时间顺序处理历史数据,模拟订单撮合、资金管理等过程。
-
主流框架: Backtrader、Zipline、PyAlgoTrade、vn.py(国产优秀框架)等。
-
代码示例:Python策略逻辑骨架(简易均线策略)
# 示例:Python策略逻辑骨架(简易均线策略)
# 这是一个概念性示例,实际回测框架会提供更完善的API
class SimpleMovingAverageStrategy:
def __init__(self, short_period: int = 10, long_period: int = 30):
"""
策略初始化。
:param short_period: 短期均线周期
:param long_period: 长期均线周期
"""
self.short_period = short_period
self.long_period = long_period
self.price_history = [] # 存储历史收盘价
self.has_position = False # 当前是否有持仓
def on_bar(self, bar_data: dict):
"""
每当收到新的K线数据时被调用。
:param bar_data: 包含'close'价格等信息的字典
"""
current_price = bar_data['close']
self.price_history.append(current_price)
# 确保历史数据足够计算均线
if len(self.price_history) < self.long_period:
return
# 计算短期和长期均线
short_ma = sum(self.price_history[-self.short_period:]) / self.short_period
long_ma = sum(self.price_history[-self.long_period:]) / self.long_period
print(f"当前价格: {current_price:.2f}, 短均线({self.short_period}): {short_ma:.2f}, 长均线({self.long_period}): {long_ma:.2f}")
# 交易逻辑:金叉买入,死叉卖出
if short_ma > long_ma and not self.has_position:
# 模拟下单:self.send_order(symbol="STOCK_XYZ", quantity=100, type="BUY")
print(f"--> 金叉信号:买入 @ {current_price:.2f}")
self.has_position = True
elif short_ma < long_ma and self.has_position:
# 模拟下单:self.send_order(symbol="STOCK_XYZ", quantity=100, type="SELL")
print(f"--> 死叉信号:卖出 @ {current_price:.2f}")
self.has_position = False
def on_order_filled(self, order_info: dict):
"""订单成交事件处理"""
print(f"订单成交: {order_info}")
def on_error(self, error_msg: str):
"""错误事件处理"""
print(f"策略错误: {error_msg}")
# 实际回测引擎会加载历史数据,并按顺序调用策略的on_bar等方法
# backtest_engine = SomeBacktestFramework(data, SimpleMovingAverageStrategy())
# results = backtest_engine.run()
3.3 回测中的常见问题与应对
- 未来函数 (Look-Ahead Bias): 策略不小心使用了未来才能获得的数据。严格审查数据加载和指标计算过程是关键。
- 过度拟合 (Overfitting): 策略在历史数据上表现完美,但在新数据上失效。通过样本外测试、交叉验证、减少模型复杂度等方法应对。
4. 交易执行层:策略指令的高效落地
交易执行层是量化系统与市场直接交互的模块,其核心目标是低延迟、高吞吐、高可靠性地执行交易指令。
4.1 执行引擎语言选型
- C++: 高频交易(HFT)领域的首选,提供极致的性能控制和内存管理能力。
- Go: 在并发处理、性能和开发效率之间取得良好平衡,适用于中高频和微服务架构。
- Java: 在传统金融机构后台系统中应用广泛,以其稳定性著称。
4.2 高性能网络通信
与交易所或券商的交易网关通信,对网络延迟有极高要求。
-
FIX Protocol: 金融信息交换协议,行业标准。需使用高效的FIX协议库。
-
Socket编程: 底层网络通信,可实现精细控制。
-
Kernel Bypass (内核旁路): 通过专用硬件和驱动绕过操作系统内核协议栈,将网络延迟降到极致(如Solarflare网卡配合OpenOnload/DPDK)。
-
代码示例:C++高性能发送订单(伪代码)
// 示例:C++高性能发送订单函数(高度简化,用于概念演示)
// 实际生产环境会涉及更复杂的连接池、错误处理、FIX协议编码等
#include <iostream>
#include <string>
#include <vector>
#include <atomic> // 用于原子操作
// 模拟预连接的Socket文件描述符(实际会是一个到交易网关的连接)
int g_trading_socket_fd = -1;
// 模拟订单消息结构体,通常是二进制或FIX协议定义
struct OrderMessage {
char symbol[8]; // 股票代码
double price; // 价格
int quantity; // 数量
char side; // 'B'uy / 'S'ell
// ... 其他字段,如订单ID,报单类型等
};
// 假设已经有内存池或预分配的缓冲区来避免动态内存分配
// char g_send_buffer[1024];
void init_connection_fast() {
// 实际:创建Socket,设置非阻塞、TCP_NODELAY等,并连接到交易网关
g_trading_socket_fd = 123; // 模拟一个有效的fd
std::cout << "[Exec] 交易连接初始化成功 (伪)。" << std::endl;
}
void send_order_fast(const std::string& symbol, double price, int quantity, char side) {
if (g_trading_socket_fd == -1) {
std::cerr << "[Exec] 错误:交易Socket未连接!" << std::endl;
return;
}
OrderMessage msg;
strncpy(msg.symbol, symbol.c_str(), sizeof(msg.symbol) - 1);
msg.symbol[sizeof(msg.symbol) - 1] = '\0'; // 确保字符串终止
msg.price = price;
msg.quantity = quantity;
msg.side = side;
// 1. 高效组装消息(实际可能直接操作预分配的内存块,避免拷贝)
// memcpy(g_send_buffer, &msg, sizeof(OrderMessage));
// 2. 通过已连接的Socket发送
// ssize_t bytes_sent = send(g_trading_socket_fd, g_send_buffer, sizeof(OrderMessage), MSG_DONTWAIT);
// 这里用cout模拟发送
std::cout << "[Exec] 发送订单: " << msg.symbol << ", 价格: " << msg.price
<< ", 数量: " << msg.quantity << ", 方向: " << msg.side << std::endl;
// 实际会检查bytes_sent是否成功
}
// 示例调用:
// init_connection_fast();
// send_order_fast("IBM", 150.25, 200, 'B');
4.3 并发处理与内存优化
为应对海量行情和订单处理,并发模型和内存优化至关重要。
-
多线程/多进程: 实现任务并行化。
-
无锁数据结构 (Lock-Free Data Structures): 如无锁队列、Ring Buffer,通过原子操作(
std::atomic等)避免传统互斥锁的开销,提高并发效率。 -
内存池 (Memory Pool): 预分配内存,减少系统调用,降低内存碎片。
-
CPU缓存优化: 内存对齐、避免伪共享,最大化缓存命中率。
-
代码示例:C++利用原子操作实现无锁计数器
// 示例:C++利用原子操作实现无锁计数器(演示并发安全)
#include <iostream>
#include <atomic> // 包含原子操作头文件
#include <thread> // 包含线程头文件
#include <vector>
// 定义一个原子计数器,保证在多线程环境下安全地递增
std::atomic<long long> processed_event_count(0);
// 模拟一个高并发事件处理函数
void process_event_concurrently() {
// 模拟复杂的事件处理逻辑...
// 每次处理一个事件,原子地增加计数
processed_event_count.fetch_add(1, std::memory_order_relaxed); // 原子递增操作
// memory_order_relaxed 是最宽松的内存序,在某些场景下足够,能提供最佳性能
}
int main() {
std::vector<std::thread> worker_threads;
int num_threads = 4; // 模拟4个线程并行处理事件
long long total_events_to_process = 1000000; // 总共要处理100万个事件
std::cout << "启动 " << num_threads << " 个线程模拟并行处理事件...\n";
for (int i = 0; i < num_threads; ++i) {
worker_threads.emplace_back([&] { // 使用lambda表达式创建线程函数
for (long long j = 0; j < total_events_to_process / num_threads; ++j) {
process_event_concurrently();
}
});
}
// 等待所有线程完成
for (auto& t : worker_threads) {
t.join();
}
// 读取最终的计数器值,保证线程安全
std::cout << "所有事件处理完毕。总共处理的事件数量: " << processed_event_count.load() << std::endl;
// 关键点:如果这里使用普通的long long而非atomic,多线程并发读写会导致结果不正确。
// 原子操作保证了即使在并发环境下,计数也是准确且线程安全的,同时避免了传统互斥锁的开销。
return 0;
}
5. 风险管理层:量化交易的“安全气囊”
风险管理是量化交易系统的“生命线”,其目标是实时监控风险、快速止损并保障资金安全。
5.1 实时风险指标计算与规则设定
-
系统需要毫秒级计算账户资金、持仓市值、最大回撤、杠杆率等实时风险指标。
-
设定多维度风险“红线”:如最大亏损、单品种持仓限额、单笔订单限额等。
-
技术选型: C++因其极致性能,常用于核心风险指标的实时计算;Python可用于更复杂的风险模型和报告生成。
-
代码示例:Python实时风控检查(伪代码)
# 示例:Python实时风控检查函数(伪代码)
# 实际生产中,这些检查会在交易路径的关键节点被调用
class RiskManager:
def __init__(self, initial_capital: float, max_drawdown_ratio: float = 0.05, max_single_pos_limit: int = 10000):
self.initial_capital = initial_capital
self.max_drawdown_ratio = max_drawdown_ratio # 最大总回撤比例
self.max_single_pos_limit = max_single_pos_limit # 单一标的最大持仓量
self.current_balance = initial_capital
self.current_positions = {} # {symbol: quantity}
def update_account_status(self, new_balance: float, new_positions: dict):
"""更新账户余额和持仓信息"""
self.current_balance = new_balance
self.current_positions = new_positions
print(f"\n[RiskMgr] 账户更新:余额 {self.current_balance:.2f},持仓:{self.current_positions}")
def check_all_risks(self) -> bool:
"""执行所有风险检查,如果触发风险则返回False"""
# 1. 检查最大总回撤
current_drawdown = (self.initial_capital - self.current_balance) / self.initial_capital
if current_drawdown > self.max_drawdown_ratio:
print(f"🚨 [RiskMgr] 警报!总回撤 {current_drawdown*100:.2f}% 已超限 {self.max_drawdown_ratio*100:.2f}%!")
self._trigger_emergency_action("总回撤超限") # 触发紧急行动
return False
# 2. 检查单一持仓限制
for symbol, quantity in self.current_positions.items():
if abs(quantity) > self.max_single_pos_limit:
print(f"🚨 [RiskMgr] 警报!标的 {symbol} 持仓 {quantity} 已超单笔限制 {self.max_single_pos_limit}!")
self._trigger_emergency_action(f"单笔持仓超限: {symbol}") # 触发紧急行动
return False
# 可在此处添加更多风险检查,如:报单频率、资金杠杆率、隔夜仓位等
print("[RiskMgr] ✔ 风险检查通过。")
return True
def _trigger_emergency_action(self, reason: str):
"""触发紧急风控措施(如停止策略、强制平仓等)"""
print(f"🚫 [RiskMgr] 紧急行动触发!原因:{reason}。所有交易可能停止或被强制平仓。")
# 实际操作会向交易执行层发送指令:
# self.trading_engine.stop_all_strategies()
# self.trading_engine.force_close_position(symbol)
# 示例调用
# risk_manager = RiskManager(initial_capital=100000)
# risk_manager.update_account_status(98000, {"AAPL": 500}) # 正常
# risk_manager.check_all_risks()
#
# risk_manager.update_account_status(93000, {"AAPL": 500}) # 模拟触发总回撤
# risk_manager.check_all_risks()
#
# risk_manager.update_account_status(95000, {"GOOG": 12000}) # 模拟触发单笔持仓超限
# risk_manager.check_all_risks()
6. 监控与运维层:系统稳定运行的保障
本层确保量化交易系统稳定、高效、可靠运行,并在出现问题时能快速发现、定位和恢复。
6.1 日志管理系统
详尽的日志是系统调试、故障排查和事后分析的关键。
-
技术选型: Python的
logging模块;配合ELK Stack (Elasticsearch, Logstash, Kibana) 或 Loki + Grafana 实现日志的集中收集、存储、查询和可视化。 -
代码示例:Python日志记录
# 示例:Python日志记录配置与使用
import logging
import time
# 配置日志记录器
logger = logging.getLogger('QuantSystem') # 获取一个具名的logger实例
logger.setLevel(logging.INFO) # 设置日志级别为INFO,DEBUG级别的信息默认不显示
# 创建一个文件处理器,将日志写入文件
file_handler = logging.FileHandler("quant_system.log")
file_handler.setLevel(logging.INFO)
# 创建一个控制台处理器,将日志输出到标准输出
console_handler = logging.StreamHandler()
console_handler.setLevel(logging.INFO)
# 定义日志输出格式
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler.setFormatter(formatter)
console_handler.setFormatter(formatter)
# 将处理器添加到logger
logger.addHandler(file_handler)
logger.addHandler(console_handler)
# 示例日志输出
logger.info("量化交易引擎启动中...")
time.sleep(0.1)
logger.info("行情订阅服务已连接。")
time.sleep(0.1)
logger.warning("某个策略的信号生成模块运行缓慢,可能需要优化。")
time.sleep(0.1)
try:
result = 10 / 0 # 模拟一个运行时错误
except Exception as e:
logger.error("发生严重错误,程序可能崩溃!", exc_info=True) # exc_info=True 会记录完整的堆栈信息
# 或者使用 logger.exception(),它默认会在ERROR级别记录异常信息和堆栈
# logger.exception("发生未知异常")
6.2 性能指标监控与可视化
实时监控系统各项关键指标,提供直观的运行状态视图。
- 技术选型: Prometheus (指标收集和存储)、Grafana (仪表盘可视化)。
- 代码示例:Python暴露指标给Prometheus(使用
prometheus_client)
# 示例:Python暴露自定义指标给Prometheus
# 需要安装:pip install prometheus_client
from prometheus_client import Gauge, Counter, start_http_server
import time
import random
# 定义Gauge指标:可任意设定的数值,用于表示瞬时状态(如账户余额)
ACCOUNT_BALANCE = Gauge('quant_account_balance', 'Current balance of the trading account')
# 定义Counter指标:只增不减的计数器(如处理的总订单数)
PROCESSED_ORDERS_TOTAL = Counter('quant_processed_orders_total', 'Total number of orders processed')
# 定义Gauge指标:用于表示延迟,每次测量设置新值
ORDER_LATENCY_SECONDS = Gauge('quant_order_latency_seconds', 'Latency of order execution in seconds')
def run_metrics_server():
"""启动HTTP服务器,暴露Prometheus可抓取的指标接口"""
print("Prometheus指标服务器已启动在端口 8000。请配置Prometheus抓取 http://localhost:8000/metrics")
start_http_server(8000) # 默认在8000端口监听HTTP请求
# 模拟系统持续运行并更新指标
while True:
# 随机更新账户余额
ACCOUNT_BALANCE.set(random.uniform(95000, 105000))
# 模拟每次循环处理一个订单
PROCESSED_ORDERS_TOTAL.inc() # 计数器递增
# 模拟订单执行延迟
ORDER_LATENCY_SECONDS.set(random.uniform(0.001, 0.080)) # 1毫秒到80毫秒
time.sleep(random.uniform(0.5, 2)) # 模拟周期性更新
# 在你的量化系统主程序中启动这个Metrics Server线程
if __name__ == "__main__":
metrics_thread = threading.Thread(target=run_metrics_server)
metrics_thread.daemon = True # 设置为守护线程,主程序退出时自动退出
metrics_thread.start()
print("主程序继续运行,指标正在后台更新...")
# 模拟主程序长时间运行
try:
while True:
time.sleep(10)
except KeyboardInterrupt:
print("主程序退出。")
6.3 自动化部署与运维 (DevOps)
提高系统部署、更新和维护的效率和可靠性。
- 容器化 (Docker): 打包应用及其依赖,确保环境一致性。
- 容器编排 (Kubernetes): 自动化部署、扩展和管理容器化应用,构建高可用集群。
- 持续集成/持续部署 (CI/CD): Jenkins、GitLab CI/CD、GitHub Actions等,自动化测试、构建和部署流程。
7. 总结与展望
构建一个完整的量化交易系统是一个多学科交叉的复杂工程,涉及数据工程、算法开发、高性能计算、分布式系统、网络编程和风险管理等多个领域。本文从分层的角度,为您解析了量化交易系统的核心技术栈,并提供了相应的代码示例。
从数据采集到策略回测,从高速交易执行到严密风险控制,再到全面的系统监控与自动化运维,每一个环节都至关重要。开发者应根据自身策略的频率、对延迟的要求以及团队规模,合理选择技术栈并进行投入。
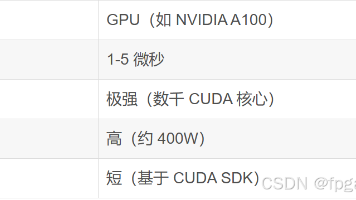
量化交易领域仍在快速发展,人工智能、机器学习、硬件加速(FPGA/GPU)等前沿技术正不断融入其中。持续学习和实践,是量化开发者保持竞争力的关键。
资源推荐:
欲深入学习更多量化交易开发相关知识,欢迎访问我的GitHub开源项目:
👉 0voice/Awesome-QuantDev-Learn
这里汇集了从入门到高阶的量化开发资源,期待您的关注和贡献!

专业量化交易与投资者大本营
更多推荐
 30
30 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)