
FPGA在HFT(高频交易)中的应用
摘要:本文探讨了FPGA在高频交易系统中的实现方案,重点分析了三大核心模块:行情数据解析与预处理(纳秒级协议解析)、策略逻辑硬件化(统计套利/做市策略)和低延迟执行引擎(订单生成与网络协议卸载)。关键技术包括时钟分频管理、计算单元优化(定点数运算/DSP阵列)和数据传输优化(跨时钟域同步)。相比GPU方案,FPGA在简单指令处理上延迟优势显著(总延迟<1μs)。部署可采用FPGA+GPU异构
目录
FPGA在高频交易中的核心优势在于并行处理能力和纳秒级延迟控制,通过硬件逻辑直接处理市场数据流,规避CPU的指令调度瓶颈。其原理架构分为三层:
1.数据采集层:解析交易所二进制协议(如FAST/FIX),实时捕获行情(Order Book)与成交数据。
2.策略逻辑层:在FPGA内实现定价模型、套利算法或预测策略(如统计套利、做市策略)。
3.执行层:生成订单指令并通过低延迟网络接口(如10G以太网)发送至交易所。
关键性能指标:端到端延迟需控制在1微秒以内(CPU方案通常>10微秒)
1.基于FPGA的高频交易系统实现步骤与数学建模概述
步骤1:行情数据解析与预处理
输入:交易所二进制数据流(如ITCH协议)
协议解码:使用状态机解析字段(如StockLocate、Price、Shares)。
always @(posedge clk) begin
case (current_state)
PARSE_HEADER: next_state = PARSE_BODY;
PARSE_BODY: if (field_type == PRICE) price_reg <= data_in;
endcase
end
订单簿重建:维护买卖盘口(Bid/Ask)的深度数据,使用双端口Block RAM(BRAM) 存储价格-数量映射。
时间戳同步:利用FPGA的Delay-Locked Loop (DLL/PLL) 对齐全球原子钟(PTP协议),精度达纳秒级。
步骤2:策略逻辑硬件化实现
(a) 统计套利策略(配对交易)
协整关系建模:计算两只标的资产价格序列的残差
交易信号生成:当残差偏离均值±2σ时触发:
(b) 做市商策略
最优报价计算:基于库存风险调整报价偏移
硬件优化:
使用流水线计算单元并行处理多标的策略(如32路并行)。
定点数运算:将浮点模型转换为Q格式定点数(如Q16.16),减少资源消耗。
步骤3:低延迟执行引擎
订单生成:策略信号触发后,在单个时钟周期内生成订单字段。
网络协议栈卸载:
UDP/IP硬核:通过FPGA内置MAC实现协议封装,绕过操作系统协议栈。
校验和计算:使用循环冗余校验(CRC32)硬件模块。
2.FPGA实现高频量化的几个关键技术
2.1 时钟管理与分频
使用PLL/DLL生成多相位时钟,实现时间交织处理:
例如:将100MHz主时钟分频为4相25MHz时钟,并行处理4组数据流1。
分频代码示例(Verilog):
reg [11:0] counter;
always @(posedge clk) begin
if (counter == 12'd4095) begin // 2^12-1分频
counter <= 0;
out <= ~out; // 输出翻转
end else counter <= counter + 1;
end
2. 2 计算单元优化
乘加器复用:利用FPGA的DSP Slice实现并行MAC运算(如A*B + C)。
Altera Stratix 10的DSP支持单周期完成18×19乘法。
查表加速:将复杂函数(如指数函数)预计算存入Block RAM,通过地址映射快速读取。
2.3 低延迟数据传输
内存架构:
行情数据流 → 寄存器(LUT级缓存) → Block RAM(深度存储) → 策略逻辑。
跨时钟域同步:使用双触发器消除亚稳态:
reg meta_reg, sync_reg;
always @(posedge dest_clk) begin
meta_reg <= async_signal;
sync_reg <= meta_reg; // 同步后信号
end
3.指标对比
通过FPGA实现高频量化交易,一般情况下,可以达到如下指标:
| 模块 | 典型延迟 | 优化方法 |
|---|---|---|
| 行情解析 | 200 ns | 流水线+状态机简化 |
| 策略计算 | 300~500 ns | 并行DSP阵列+定点化 |
| 网络传输 | 400 ns | 硬核协议栈+零拷贝DMA |
| 总延迟 | <1 μs | —— |
与GPU对比,高频交易的硬件架构需突破纳秒级延迟瓶颈。
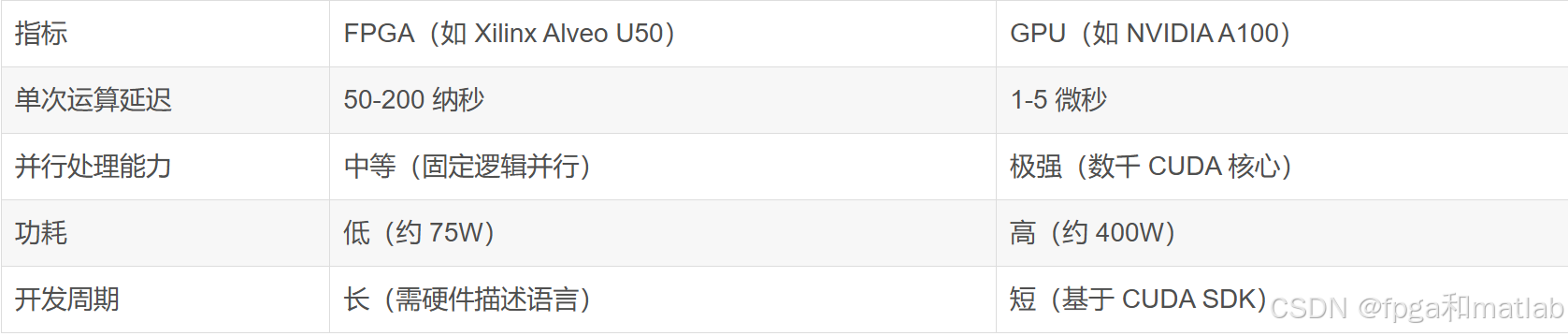
FPGA依托硬件级逻辑固化的核心特性,能够将简单指令执行过程中的延迟降至极低水平 —— 例如订单实时校验、报单路径路由这类操作,其延迟表现远优于GPU,因此尤其适配做市商策略等对响应速度有极端敏感需求的业务场景;
与之相对,GPU在复杂数据处理任务中更能发挥优势,典型如多维度订单流分析场景:以10档订单簿的实时特征提取为例,GPU可高效实现每秒百万级的运算处理,充分满足复杂数据运算对并行计算能力的需求。
4.部署方式
4.1“FPGA+GPU” 异构混合部署方案
为兼顾高频交易的低延迟响应与复杂数据处理需求,可采用 “FPGA+GPU” 异构架构设计:将核心低延迟环节交由FPGA处理,具体负责交易指令的实时生成(如根据策略信号生成报单指令),以及与交易所接口的直接交互(包括行情接收、订单发送等);而GPU则聚焦于高复杂度的数据运算任务,例如多维度订单流的深度分析、基于历史与实时数据的价格预测等,充分发挥其在并行计算上的优势。
高速数据交互通过PCIe 4.0接口实现FPGA与GPU之间的高效数据传输,该接口可支持纳秒级的传输延迟,确保两者间数据交互无瓶颈,保障整个交易系统的协同高效运行。
4.2低延迟网络优化方案
为进一步压缩数据传输延迟,需从硬件选型与软件优化两方面构建低延迟网络架构:
硬件层面:选用100Gbps低延迟光模块(如Arista 7050X3系列),该类模块具备高带宽与低传输时延的双重特性,可大幅减少数据在物理传输链路中的耗时。
软件层面:部署DPDK(数据平面开发套件),通过绕过操作系统内核直接操作网络硬件的方式,避免传统内核网络协议栈带来的延迟开销,最终将整体网络延迟严格控制在1微秒以内,满足高频交易对网络时延的严苛要求。

加入社区!打开量化的大门,首批课程上线啦!
更多推荐

 26
26 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)