
期货_股票量化交易软件:MQL5中的范畴论自我注意的迂回与转换
偶尔,尽管有这4种频率,但两个单词可能具有相同的“坐标”,但这应该不是问题,因为如果确实发生了这种情况,那么许多单词(或在我们的情况下是价格点)被用来否定这种轻微的异常。为了对我们的位置编码进行某种程度的“规范化”,可以在+5.0到-5.0之间波动,有时甚至超过5.0的位置编码值,在被添加到价格变化之前,将被乘以所讨论的证券的点值大小。正如这个问题最初看起来的那样,量化这个词的相对重要性的能力可以
概述
我认为,在范畴论和自然变换的主题上继续写这些系列文章,而不去碰房间里的大象,也就是 chatGPT,那将是失职的。到目前为止,每个人都以某种形式熟悉了chatGPT和许多其他人工智能平台,并见证和欣赏了变换神经网络(transformer neural network)的潜力,它不仅使我们的研究更容易,而且还能从琐碎的任务中抽走急需的时间。因此,我在这些系列中浏览了一圈,试图解决这样一个问题,即范畴论的自然变换是否在某些方面是 Open AI 所采用的生成预训练变换器(Generative Pretrained Transformer,GPT)算法的关键。
除了用“变换”的措辞检查任何同义词外,我认为在MQL5中查看GPT算法代码的部分,并在证券价格系列的初步分类上测试它们也会很有趣。

添加图片注释,不超过 140 字(可选)
正如论文中所介绍的,“注意力就是你所需要的一切”是用于跨口语(如意大利语到法语)进行翻译的神经网络的一项创新,它建议消除递归和卷积。它的建议是?自注意力机制(Self-Attention)。据了解,许多正在使用的人工智能平台都是这一早期努力的大脑产物。
Open AI使用的实际算法当然是保密的,但人们仍然认为它使用单词嵌入(Word-Embedding)、位置编码(Positional Encoding)、自注意力机制(Self-Attention)和前馈网络(Feed-Forward network),作为仅解码转换器(decode-only transformer)中堆栈的一部分。这些都没有得到证实,所以你不应该相信我的话。需要明确的是,这个参考是关于单词/语言翻译部分的算法。是的,由于chatGPT中的大多数输入都是文本,它确实在算法中起着关键的、几乎是基础性的作用,赫兹量化交易软件现在知道chatGPT所做的远不止解释文本。例如,如果你上传了一个excel文件,它不仅可以打开它来阅读其内容,还可以绘制图表,甚至对所提供的统计数据发表意见。这里的重点是chatGPT算法显然没有在这里完全呈现,但它可能看起来只是被理解的一部分。
添加图片注释,不超过 140 字(可选)
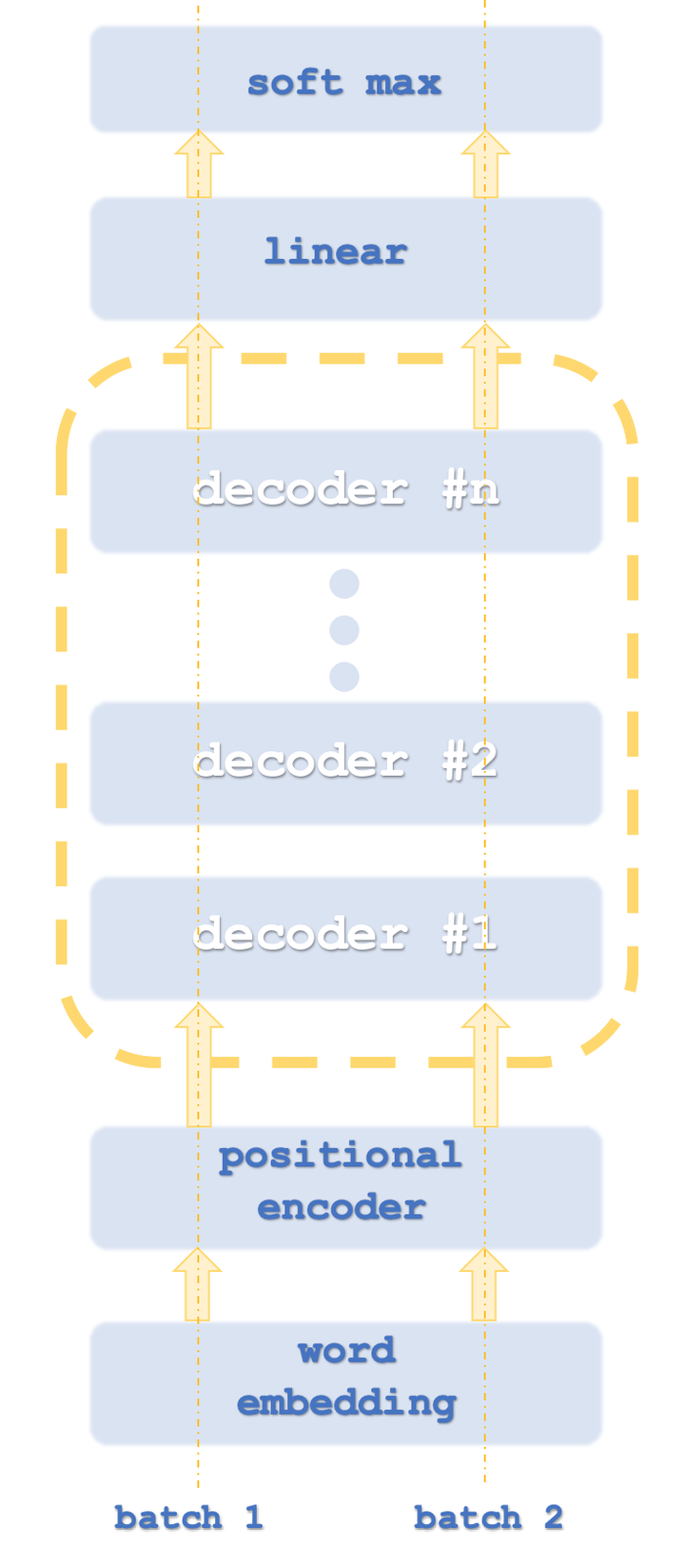
批处理1和2类似于计算机线程,因为转换器通常并行运行网络实例。
由于赫兹量化交易软件正在对数字进行分类,因此不需要嵌入单词。位置编码是指根据单词的位置来捕捉句子中每个单词的绝对重要性。这方面的算法是直接的,因为每个单词(也称为令牌)都被分配了一个正弦波上的读数,该读数来自不同频率的正弦波阵列。将每个波形的读数相加,得到该标记的位置编码。该值可以是一个矢量,这意味着您要将多个频率阵列的值相加。
这会导致自注意力机制。这样做的目的是计算一个句子中每个单词与该句子中出现在它之前的单词的相对重要性。这种看似微不足道的努力在通常以“it”一词为特征的句子中以及其他情况下都很重要。例如,在下面的句子中:
“The dish washer partly cleaned the glass and it cracked it.”(“洗碗机把玻璃洗得开裂了。”)
它代表什么?对人类来说,这是直接的,但对学习机器来说,不是这样。正如这个问题最初看起来的那样,量化这个词的相对重要性的能力可以说是启动变换神经网络的关键,因为变换神经网络被发现比其前身的递归和卷积网络更具并行性,需要更少的训练时间。
因此,对于本文来说,自注意力机制将是我们测试信号类的关键。有趣的是,尽管自注意算法在单词相互关联的方式上确实与一个范畴有相似之处。用于量化相对重要性(相似性)的词关系可以被认为是词本身形成对象的态射。事实上,这种关系有点怪异,因为每个单词都需要计算其相似性或重要性。这很像身份态射!此外,除了推断态射和对象之外,赫兹量化交易软件还可以分别关联函子和范畴,正如我们在后面的文章中所看到的那样。
了解变换解码器
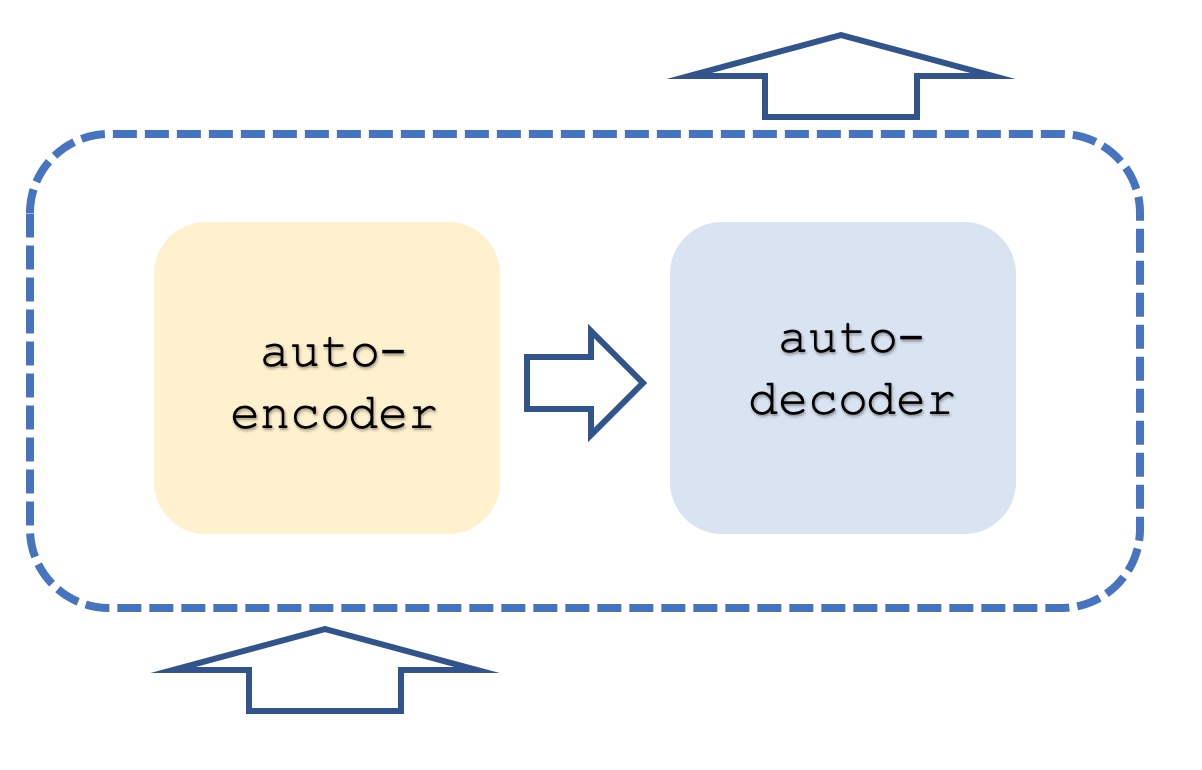
通常,变换网络将包含编码和解码堆栈,每个堆栈表示自注意和前馈网络中的重复。它可能类似于下面的内容:
添加图片注释,不超过 140 字(可选)
除此之外,每个步骤都用平行的“线程”运行,这意味着,例如,如果自注意和前馈步骤可以由多层感知器表示,那么如果变换器有8个线程,则每个阶段将有8个多层感知机。这显然是资源密集型的,但正是这种方法的优势所在,因为即使使用了这种资源,它仍然比前代复杂网络更高效。
据了解,Open AI所使用的方法为其变体,因为它只是解码。它的步骤大致显示在我们的第一张图中。仅进行解码显然不会影响模型的准确性,但由于只处理了“一半”变换器,因此它肯定会带来更好的性能。这里指出,编码时的自注意映射与解码时的自关注映射不同,因为编码时计算所有单词的相对重要性,而与句子中的相对位置无关。这显然是更耗费资源的,因为正如解码器方面所提到的,只对每个单词本身以及句子中位于其之前的单词进行自关注(也称为相似性计算)。有些人可能会争辩说,这甚至否定了位置编码的必要性,但出于我们的目的,我们将把它包含在源代码中。因此,这种仅解码的方法是我们的重点。
自注意和前馈网络在变换器步骤中的作用是根据堆栈进行位置编码或先前堆栈输出,并为下一解码器步骤的输入中的线性SoftMax步骤产生输入。
位置编码,有些人可能会觉得对我们的信号类和文章来说有些过头了,它包含在这里是为了提供信息。输入价格柱信息的绝对顺序可能与句子中的单词序列一样重要。赫兹量化交易软件使用的是一个简单的算法,它返回一个 double 型值的4点向量,作为每个输入价格点的“坐标”。
有些人可能会争论为什么不对每个输入使用简单的索引。事实证明,当训练网络时,这会导致梯度消失和爆炸,因此需要一种不太稳定和规范化的格式。你可以认为这相当于一个标准长度的加密密钥,比如128,而不管加密的是什么。是的,它使破解隐藏的密钥变得更加困难,但它也提供了一种更有效的生成和存储密钥的方法。
所以,我们将使用4个不同频率的正弦波。偶尔,尽管有这4种频率,但两个单词可能具有相同的“坐标”,但这应该不是问题,因为如果确实发生了这种情况,那么许多单词(或在我们的情况下是价格点)被用来否定这种轻微的异常。这些坐标值被添加到我们的输入向量的4个价格点上,这代表了我们从单词嵌入中得到的东西,但没有,因为我们已经在处理安全价格形式的数字。我们的信号类将使用价格变化。为了对我们的位置编码进行某种程度的“规范化”,可以在+5.0到-5.0之间波动,有时甚至超过5.0的位置编码值,在被添加到价格变化之前,将被乘以所讨论的证券的点值大小。
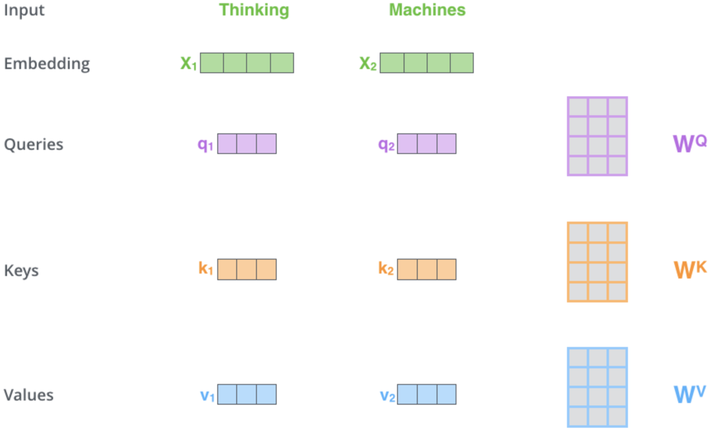
您可以从上面的共享超链接中收集到的自注意力机制负责确定3个向量,即查询向量、关键字向量和值向量。这些矢量是通过将位置编码输出矢量乘以权重矩阵得到的。这些权重是怎么来的?来自反向传播。不过,出于我们的目的,我们将使用多层感知器类的实例来初始化和训练这些权重,仅有一层。这一关键阶段的过程图示如下:
添加图片注释,不超过 140 字(可选)
这幅插图和本文中的一些要点来源于网页。上图表示两个单词作为输入(“思考”和“机器” - “Thinking”, “Machines”)。在嵌入时(将它们转换为数字矢量),它们将转换为绿色矢量。右边的矩阵表示我们将通过多层感知器获得的权重,如上所述。
因此,一旦我们的网络执行前向传递,得到查询、关键字和值向量,我们就对查询和关键字进行点积,将结果除以关键字向量基数的平方根,结果就是价格点与查询向量和价格点与关键字向量之间的相似性。这些乘法是在所有价格点上进行的,与我们只将价格点与自身和之前的价格点进行比较的自注意映射保持一致。结果得到了可能广泛的数字,这就是为什么使用SoftMax函数将它们归一化为概率分布的原因。所有这些概率权重的总和如预期的那样达到1,它们正在有效地加权。在最后一步中,将每个权重与其各自的向量值相乘,并将所有这些乘积相加为单个向量,形成自注意层的输出。
前馈网络通过多层感知器处理来自自注意的输出向量,并输出与自注意输入向量大小相似的另一个向量。
在MQL5中实现变换解码器(Transformer Decoder)的理论框架将通过简单的信号类而不是 EA 交易。这个主题目前有点复杂,因为其中一些想法存在还不到十年,所以人们认为测试和熟悉度现在比执行和结果更重要。当然,当读者感到舒适时,他可以自由地进一步接受和采纳这些想法。

加入社区!打开量化的大门,首批课程上线啦!
更多推荐


 19
19 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)