
Python深度学习:从入门到精通
目录
第一部分:基础篇 —— 奠定智慧的基石
第1章:开启深度学习之旅
- 1.1 人工智能、机器学习与深度学习:正本清源,理解三者关系。
- 1.2 深度学习的“前世今生”:从赫布理论到神经网络的复兴。
- 1.3 为何选择Python?—— 生态、社区与哲学的统一。
- 1.4 本书的结构与学习路径图:如何高效地利用这本书。
- 1.5 心法总纲:保持好奇、勤于实践、拥抱开源。
第2章:数学与编程基础 —— 内功心法
- 2.1 线性代数:向量、矩阵、张量及其运算(不仅是计算,更是空间的变换)。
- 2.2 微积分:导数、偏导数、链式法则与梯度(理解变化与优化的语言)。
- 2.3 概率论与信息论:概率分布、期望、熵与交叉熵(衡量不确定性与信息)。
- 2.4 NumPy:精通多维数组操作,为数据处理提速。
- 2.5 Pandas:结构化数据的探查、清洗与预处理。
- 2.6 Matplotlib & Seaborn:数据的可视化,让洞察直观呈现。
第3章:机器学习经典回顾 —— 温故而知新
- 3.1 机器学习的三大范式:问道于天地。
- 3.2 经典模型剖析:一花一世界,一叶一菩提。
- 3.3 模型的评估与优化:知其然,更要知其所以然。
第二部分:核心篇 —— 深入神经网络的殿堂
第4章:神经网络基础
- 4.1 从生物神经元到人工神经元:模型的灵感来源。
- 4.2 感知机模型:最简单的神经网络及其局限性。
- 4.3 多层感知机(MLP):构建深度网络的第一步。
- 4.4 激活函数大全:Sigmoid、Tanh、ReLU、Leaky ReLU、ELU等(为何需要非线性)。
- 4.5 损失函数:MSE、交叉熵等(衡量“理想”与“现实”的差距)。
- 4.6 反向传播算法:梯度下降与链式法则的完美结合(网络如何学习)。
第5章:深度学习框架入门与实战
- 5.1 TensorFlow 2.x 与 Keras:Google的工业级解决方案。
- 5.2 PyTorch:Facebook的动态图与研究者首选。
- 5.3 环境搭建:Conda、Jupyter Notebook与GPU配置指南。
第6章:深度学习的“炼丹术” —— 训练与优化
- 6.1 优化器详解:SGD、Momentum、Adagrad、RMSprop、Adam。
- 6.2 正则化技术:L1/L2正则化、Dropout、早停(防止模型“走火入魔”)。
- 6.3 批归一化(Batch Normalization):加速收敛的利器。
- 6.4 超参数调优:网格搜索、随机搜索与贝叶斯优化。
- 6.5 权重初始化策略:Xavier、He初始化等。
第三部分:进阶篇 —— 掌握核心网络架构
第7章:卷积神经网络(CNN) —— 洞悉图像的奥秘
- 7.1 CNN的核心思想:局部连接、权值共享与池化。
- 7.2 卷积层、池化层与全连接层详解。
- 7.3 经典CNN架构演进:LeNet-5, AlexNet, VGG, GoogLeNet , ResNet。
- 7.4 迁移学习与微调(Fine-tuning):站在巨人的肩膀上。
- 7.5 CNN应用:图像分类、目标检测(YOLO, Faster R-CNN)、图像分割。
第8章:循环神经网络(RNN) —— 理解序列的智慧
- 8.1 RNN的结构与挑战:短期记忆与梯度消失/爆炸问题。
- 8.2 长短期记忆网络(LSTM):记忆门的设计哲学。
- 8.3 门控循环单元(GRU):LSTM的简化与变体。
- 8.4 双向RNN与深度RNN。
- 8.5 RNN应用:自然语言处理(文本分类、情感分析)、时间序列预测。
第9章:注意力机制与Transformer —— 现代NLP的基石
- 9.1 注意力(Attention)机制的原理与魅力。
- 9.2 Transformer架构详解:自注意力、多头注意力、位置编码。
- 9.3 BERT、GPT及其他预训练语言模型:新范式的崛起。
- 9.4 Transformer在计算机视觉中的应用(Vision Transformer, ViT)。
第10章:生成式模型 —— 创造与想象
- 10.1 生成对抗网络(GAN):生成器与判别器的博弈。
- 10.2 变分自编码器(VAE):概率生成的美学。
- 10.3 扩散模型(Diffusion Models):从噪声中生成高清图像的艺术。
- 10.4 应用:图像生成、风格迁移、数据增强。
第四部分:实战篇 —— 从理论到价值的转化
第11章:项目实战:计算机视觉
- 11.1 图像分类:构建一个垃圾分类系统。
- 11.2 目标检测:实现一个实时人脸或车辆检测器。
- 11.3 图像风格迁移:将照片变成梵高风格的油画。
第12章:项目实战:自然语言处理
- 12.1 文本情感分析:分析电影评论的情感倾向。
- 12.2 机器翻译:构建一个简单的中英翻译模型。
- 12.3 智能问答机器人:基于知识库的问答系统。
第13章:项目实战:其他领域
- 13.1 时间序列预测:预测股票价格或天气变化。
- 13.2 推荐系统:使用深度学习构建电影或商品推荐引擎。
- 13.3 强化学习入门:使用深度Q网络(DQN)玩转简单游戏。
第14章:模型部署与工程化
- 14.1 模型轻量化:剪枝、量化与知识蒸馏。
- 14.2 模型部署:ONNX、TensorFlow Serving、TorchServe。
- 14.3 将模型封装为API服务(使用Flask或FastAPI)。
- 14.4 MLOps简介:数据、模型与代码的版本控制。
第五部分:展望篇 —— 探索未来的边界
第15章:前沿专题与未来趋势
- 15.1 图神经网络(GNN):处理非欧几里得数据。
- 15.2 联邦学习:隐私保护下的分布式学习。
- 15.3 可解释性AI(XAI):打开神经网络的“黑箱”。
- 15.4 多模态学习:融合文本、图像与声音。
- 15.5 AI伦理与社会责任:作为技术创造者的思考。
附录:行者的“宝库”与“路书”
- A:常用数据集与资源链接。
- B:数学符号表。
- C:常见问题与排错指南。
- D:进一步阅读建议。
第一部分:基础篇 —— 奠定智慧的基石
第一章:开启深度学习之旅
- 1.1 人工智能、机器学习与深度学习:正本清源,理解三者关系。
- 1.2 深度学习的“前世今生”:从赫布理论到神经网络的复兴。
- 1.3 为何选择Python?—— 生态、社区与哲学的统一。
- 1.4 本书的结构与学习路径图:如何高效地利用这本书。
- 1.5 心法总纲:保持好奇、勤于实践、拥抱开源。
亲爱的读者,当您翻开这一页,您正站在一个时代的入口。这个时代由数据驱动,由算法赋能,它的核心引擎,便是我们即将深入探索的“深度学习”。它不仅是工程师和科学家的工具,更是一种全新的思维方式,正在以磅礴之势重塑我们所知的世界。本章将作为您的向导,为您描绘一幅宏大的地图,让您明白我们从何而来,身在何处,又将去向何方。
1.1 人工智能、机器学习与深度学习:正本清源,理解三者关系
在踏上深度学习的奇妙旅程之前,我们必须先校准罗盘,明确几个最基本却也最容易混淆的概念:人工智能(Artificial Intelligence, AI)、机器学习(Machine Learning, ML)和深度学习(Deep Learning, DL)。它们并非同义词,而是一个层层递进、相互包含的有机整体。理解它们之间的精妙关系,是您构建清晰认知框架的第一步。
1.1.1 人工智能(AI):最初的梦想与宏大愿景
人工智能,是这场伟大探索的终极梦想。它的核心目标,是创造出能够像人类一样思考、学习、感知和行动的智能机器。这个梦想,如同一颗古老的星辰,在人类文明的夜空中闪耀了数千年,从古希腊神话中的自动机械,到中世纪炼金术士的“人造人”传说,无不寄托着人类对创造智慧生命的无限遐想。
什么是人工智能?
在现代科学语境下,人工智能的正式诞生,通常被追溯到1956年的达特茅斯会议。一群富有远见的科学家齐聚一堂,首次提出了“人工智能”这一术语,并对其进行了初步定义:让机器能够执行通常需要人类智能才能完成的任务。其中,英国数学家、逻辑学家艾伦·图灵在1950年提出的著名“图灵测试”,至今仍是衡量机器是否具备智能的经典标准:如果一台机器能够与人类进行对话,而人类无法分辨出对方是机器还是人,那么我们就可以认为这台机器具备了智能。
人工智能的宏大愿景,又可细分为两个层次:
- 强人工智能(Strong AI): 指的是能够真正拥有自我意识、具备与人类同等甚至超越人类智慧的通用智能体。它能够像人类一样进行抽象思维、解决通用问题、甚至拥有情感和创造力。这是科幻电影中常见的题材,也是我们追求的星辰大海,但目前仍处于理论探索和遥远未来的阶段。
- 弱人工智能(Weak AI)或称应用型人工智能: 指的是专注于在特定任务上模拟甚至超越人类表现的智能系统。例如,您的手机语音助手、为您精准推荐电影的算法、以及在围棋盘上战胜世界冠军的AlphaGo。本书所讨论的一切,都属于弱人工智能的范畴,它们在特定领域展现出令人惊叹的智能,但并不具备通用智能和自我意识。
AI的发展简史:
AI的发展并非一帆风顺,它如同一条蜿蜒曲折的河流,经历了数个“黄金时代”与“AI寒冬”的交替。早期,研究者们对基于逻辑推理和符号操作的“专家系统”寄予厚望,取得了一些初步成功。然而,当这些系统面对现实世界中海量、模糊、不确定的数据时,其局限性便暴露无遗。当期望无法兑现,资金和热情便会退潮,AI研究便进入“寒冬”。然而,正是这些起伏,促使研究者们不断反思,最终找到了一条更具潜力的道路——让机器自己去学习,从数据中发现规律,而非依赖人类预设的僵硬规则。这为机器学习的兴起埋下了伏笔。
1.1.2 机器学习(ML):实现人工智能的核心途径
如果说人工智能是“造出聪明的机器”这个宏伟目标,那么机器学习就是实现这个目标最主流、最有效的一条路径。它的核心思想,正如其名,是让机器拥有学习的能力,从经验中自动改进其性能。
什么是机器学习?
计算机科学家亚瑟·萨缪尔(Arthur Samuel)在1959年给出了一个经典且精辟的定义:“机器学习是在没有被明确编程的情况下,给予计算机学习能力的研究领域。”
这意味着,我们不再像传统编程那样,为机器编写详尽的指令(例如:“如果输入是猫的图片,那么判断为猫”)。取而代之的是,我们给机器提供大量的数据(例如,成千上万张猫的图片),并设计一个算法,让它从这些数据中自动发现规律、模式,甚至生成知识。这就像教一个孩子认识猫:您不是告诉他“猫有两只耳朵、四条腿、一条尾巴……”,而是不断地指着各种各样的猫告诉他“这是猫”,久而久之,他自然就学会了识别猫,即使遇到前所未见的品种,也能举一反三。
机器学习的范畴:
根据学习方式和数据特性的不同,机器学习主要分为三大范式,它们构成了机器学习领域的核心骨架:
- 监督学习(Supervised Learning): 这是最常见的一种学习范式。我们提供给机器的数据是“带标签”的,就像有标准答案的练习册。模型通过学习输入数据(特征)与对应输出(标签)之间的映射关系来做出预测。例如,给模型成千上万封邮件,并明确标明哪些是“垃圾邮件”,哪些是“正常邮件”,让它学会分类;或者根据房屋面积、卧室数量等特征,预测房屋价格。
- 无监督学习(Unsupervised Learning): 与监督学习不同,无监督学习提供给机器的数据是没有标签的,就像一本没有答案的习题集。机器需要自己去发现数据中隐藏的结构、模式或关联性。例如,将海量用户数据进行聚类,找出具有相似兴趣的群体;或者通过降维技术,发现数据中最重要的潜在特征。
- 强化学习(Reinforcement Learning): 这是一种通过“试错”来学习的范式。我们不给机器明确的输入-输出对,而是给它一个目标和一个奖惩系统。机器(代理)通过不断地与环境进行交互,根据环境的反馈(奖励或惩罚)来学习如何采取行动以获得最大的累积奖励。AlphaGo下围棋、机器人学习行走,都是强化学习最典型的应用。它让机器学会了如何在复杂动态的环境中做出最优决策。
1.1.3 深度学习(DL):机器学习的强大分支
现在,我们来到了这场探索的核心——深度学习。如果说机器学习是让人工智能得以实现的康庄大道,那么深度学习就是这条大道上目前最快、最强大的超级跑车。它以其卓越的性能和广泛的应用,将人工智能推向了前所未有的高度。
什么是深度学习?
从技术上讲,深度学习的本质是使用“深层”人工神经网络(Deep Neural Networks, DNN)的机器学习技术。这里的“深”(Deep),是其最关键的特征,指的是神经网络的层数非常多,有时可达数十甚至上千层。这些层级并非简单堆叠,而是通过复杂的连接和非线性变换,共同协作,从原始数据中逐层提取和抽象出越来越高级的特征。
这个思想的灵感,精妙地源自于我们人类自己的大脑视觉皮层。当我们看到一只猫时,您的大脑并非“一步到位”就完成了识别。真实的过程是一个高度层次化的信息处理流程:
- 底层神经元可能只对视野中非常简单的模式做出反应,比如光点、边缘、特定的颜色或角度。
- 这些底层信息被汇集到中层神经元,它们将简单的模式组合成稍微复杂的局部特征,比如眼睛的轮廓、胡须的线条、耳朵的三角形状。
- 信息继续向上传递,更高层的神经元再将这些局部特征进行组合,最终形成“猫”这个完整的、抽象的概念。
深度学习正是模拟了这种层次化的特征学习(Hierarchical Feature Learning)机制。通过构建一个多层的网络结构,深度学习模型能够自动地从最原始的输入数据中(例如,图像的像素点),逐层学习到从简单到复杂的特征,最终完成识别、分类或生成等高级任务。这种端到端(End-to-End)的自动学习特征的能力,是它相较于传统机器学习算法最强大、最具颠覆性的优势之一,极大地简化了特征工程的复杂性。
三者关系的可视化:
为了让您对这三者的关系有一个直观且牢固的印象,我们可以用一个关系图来描绘它们:
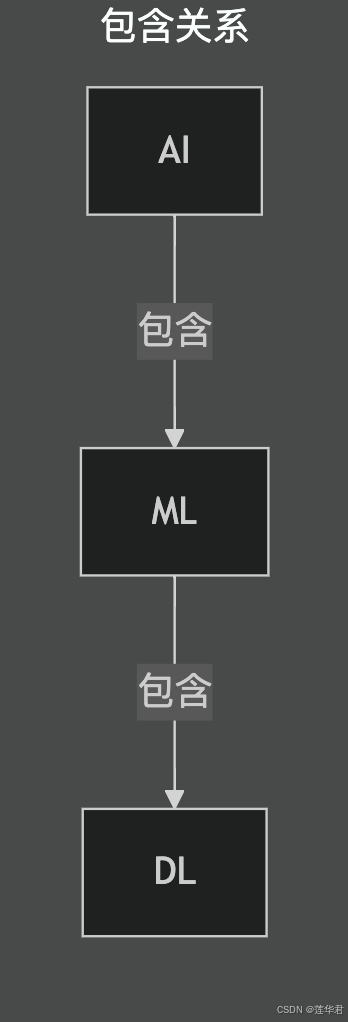
- 人工智能(AI) 是最上层的生态,代表着我们创造智能机器的宏大愿景和整个研究领域。
- 机器学习(ML) 是中间层的架构,它是实现人工智能的一种核心方法论,其核心是让机器从数据中学习。
- 深度学习(DL) 是最内层的核心,它是机器学习技术中的一个极其强大且成果斐然的分支,它以深层神经网络为主要工具,实现了高效的层次化特征学习。
现在,您可以自信地向他人解释:深度学习是实现机器学习的一种流行且强大的技术,而机器学习是通往人工智能的一条核心路径。 我们学习深度学习,正是为了掌握当前实现人工智能最强大的那把钥匙,开启通往未来智能世界的大门。
1.2 深度学习的“前世今生”:从赫布理论到神经网络的复兴
任何一门伟大的技术,都不是凭空出现的。深度学习的发展史,如同一部波澜壮阔的史诗,充满了天才的洞见、长久的沉寂、不懈的坚守与最终的辉煌。了解这段历史,能让我们更深刻地理解其核心思想的演进,从而更好地把握其未来走向。
1.2.1 思想的萌芽:理论奠基时代(1940s-1960s)
深度学习的根源,可以追溯到上世纪中叶对人脑神经元工作机制的初步探索。
赫布理论与感知机: 1949年,加拿大心理学家唐纳德·赫布(Donald Hebb)提出了著名的赫布理论(Hebb's Rule),其核心思想是“一起激发的神经元会连接在一起”(Cells that fire together, wire together)。这为神经网络的学习机制提供了生物学上的启发和理论基础。基于此,1958年,美国心理学家弗兰克·罗森布拉特(Frank Rosenblatt)发明了感知机(Perceptron),这是第一个能够通过学习来解决问题的神经网络模型。它能够对输入进行二元分类,在当时引起了巨大的轰动,被视为人工智能的曙光。
“异或”问题与第一次寒冬: 然而,初生的喜悦是短暂的。1969年,人工智能领域的先驱马文·明斯基(Marvin Minsky)和西摩尔·佩普特(Seymour Papert)在其著作《感知机》(Perceptrons)中,从数学上严格证明了单层感知机无法解决线性不可分问题,其中最著名的例子就是“异或”(XOR)问题。这个结论给当时过于乐观的神经网络研究泼了一盆冷水,导致了该领域的资金和研究兴趣急剧下降,神经网络研究进入了长达近20年的第一次“AI寒冬”。许多研究者转向了基于逻辑和符号推理的AI方向。
1.2.2 沉寂中的坚守:连接主义的复兴(1980s-1990s)
尽管处于寒冬,但仍有一批坚定的研究者(被称为“连接主义者”)在默默坚守,他们相信神经网络的潜力。转机出现在20世纪80年代。
反向传播算法的普及: 1986年,由戴维·鲁姆哈特(David Rumelhart)、杰弗里·辛顿(Geoffrey Hinton)和罗纳德·威廉姆斯(Ronald Williams)等人推广的反向传播(Backpropagation)算法,有效地解决了多层神经网络的训练难题。它利用微积分中的链式法则,能够高效地计算出损失函数对网络中每一层参数的梯度,从而对网络进行迭代更新。反向传播算法的成熟,是神经网络能够处理复杂任务的关键一步,至今仍是深度学习的核心算法。
经典模型的诞生: 有了训练方法,多层网络的威力开始显现。1998年,杨立昆(Yann LeCun)等人提出的LeNet-5模型,一个经典的卷积神经网络(Convolutional Neural Network, CNN),在手写数字识别任务上取得了巨大成功,并被广泛应用于银行的支票识别系统中。这证明了深层网络在真实世界问题中的应用潜力,尤其是在图像处理领域。
1.2.3 爆发的前夜:瓶颈与突破(2000s-2010s)
进入21世纪初,尽管有了反向传播和LeNet-5的成功,但深度学习的发展再次陷入瓶颈,被称为第二次“AI寒冬”。这主要源于三大挑战,它们如同三座大山,阻碍着深度学习的进一步发展:
- 梯度消失/爆炸问题: 在深层网络中,梯度在反向传播时会逐层衰减(消失)或急剧增大(爆炸),导致靠近输入层的网络无法得到有效训练,模型难以收敛。
- 算力不足: 训练深度网络需要巨大的计算量,当时的CPU性能远不能满足需求,使得训练时间过长,难以进行大规模实验。
- 数据匮乏: 深度学习是数据驱动的,需要海量标注数据才能发挥其优势。而当时缺乏大规模、高质量、带标签的公开数据集,限制了模型的训练规模和泛化能力。
然而,正是为了解决这些问题,三大关键的催化剂应运而生,它们如同三把火炬,共同点燃了深度学习复兴的火焰:
- 算法突破: 研究者们提出了新的激活函数(如ReLU,修正线性单元)来有效缓解梯度消失问题,以及新的正则化技术(如Dropout)来防止过拟合,提高模型的泛化能力。此外,预训练(Pre-training)和微调(Fine-tuning)等技术也开始崭露头角。
- 算力飞跃: 人们发现,用于图形渲染的GPU(图形处理器)其大规模并行计算的架构,天然适合神经网络的矩阵运算。NVIDIA等公司开始提供用于通用计算的GPU(GPGPU),使得训练速度提升了数十甚至上百倍,为深度学习的大规模实验提供了硬件基础。
- 数据爆炸: 互联网的普及带来了海量数据。更重要的是,像由李飞飞教授团队创建的ImageNet这样包含数百万张带标签图像的大型公开数据集的出现,为训练和评测深度模型提供了前所未有的“燃料”,使得模型能够从海量真实数据中学习到更丰富、更鲁棒的特征。
1.2.4 黄金时代:AlexNet至今(2012-至今)
三大催化剂的汇聚,最终在2012年引爆了深度学习的黄金时代。
AlexNet的里程碑意义: 2012年,在ImageNet图像识别挑战赛上,由杰弗里·辛顿(Geoffrey Hinton)的学生亚历克斯·克里热夫斯基(Alex Krizhevsky)所设计的AlexNet模型,以远超第二名(超过10个百分点)的惊人准确率夺得冠军。它成功地将ReLU、Dropout、GPU加速等技术融于一个深层卷积神经网络中,其压倒性的胜利,无可辩驳地向全世界宣告:深度学习的时代,正式到来。 这也标志着人工智能领域从“符号主义”向“连接主义”的范式转移。
百花齐放: AlexNet之后,深度学习进入了爆炸式发展的黄金时代。VGG、GoogLeNet、ResNet等更深、更精巧的CNN架构不断刷新着图像识别的记录,推动了计算机视觉领域的飞速发展;循环神经网络(RNN)及其变体长短期记忆网络(LSTM)在处理序列数据(如文本和语音)上大放异彩,为自然语言处理和语音识别带来了革命;生成对抗网络(GAN)让我们看到了机器创造的可能,生成逼真的图像和艺术作品;而近年来,Transformer架构更是颠覆了自然语言处理领域,催生了BERT、GPT等一系列预训练大模型,并开始在计算机视觉等多个领域展现其统治力。
深度学习,已然成为人工智能领域最耀眼的主旋律,其应用已渗透到我们生活的方方面面,从智能手机到自动驾驶,从医疗诊断到科学研究,无不闪耀着其智慧的光芒。
1.3 为何选择Python?—— 深度学习的“应许之地”
在深度学习的宏大叙事中,编程语言是我们赖以将思想蓝图构筑为现实奇观的基石。而在众多优秀的编程语言中,Python以一种近乎“天选”的姿态,成为了深度学习乃至整个数据科学领域的通用语(Lingua Franca)。
这种压倒性的优势并非偶然,而是源于其内在哲学、外在生态与社区文化三者的完美共鸣,共同将Python塑造成了深度学习的“应许之地”。对于有志于此的探索者而言,理解Python为何胜出,就如同剑客懂得自己手中之剑的特性,是踏上征途前的重要一课。
1.3.1 “开发效率优先”的内在哲学
Python的核心设计哲学,可以用“The Zen of Python”(Python之禅)中的几句话来概括:“优美胜于丑陋,明了胜于晦涩,简洁胜于复杂”。这种对可读性和简洁性的极致追求,直接转化为无与伦比的开发效率。
低认知负荷: Python的语法结构清晰,接近自然语言,让开发者可以将宝贵的脑力资源集中于解决问题本身——即模型的设计、算法的优化和实验的迭代——而不是耗费在处理繁琐的语法细节、指针管理或内存分配上。在需要快速迭代和实验的深度学习研究中,这种“所思即所得”的表达能力至关重要。
快速原型验证: 从一个算法构思到可运行的原型代码,Python的开发周期极短。这使得研究者和工程师能够迅速检验新想法的有效性,大大加速了整个领域的创新步伐。
1.3.2 “胶水特性”与“巨人肩膀”的外在生态
如果说简洁的哲学是Python的灵魂,那么其强大的科学计算生态就是它坚实的躯体。Python本身并非以极致的运行速度见长,但它拥有强大的“胶水特性”,能够高效地粘合由C、C++或Fortran等高性能语言编写的底层计算库。这让Python得以“站在巨人的肩膀上”,兼具开发效率与运行性能。
科学计算的“三驾马车”:
- NumPy: 提供了高性能的多维数组对象ndarray和丰富的数学函数,是几乎所有数据科学工具的底层依赖,为Python注入了强大的数值计算能力。
- Pandas: 提供了DataFrame这一灵活、强大的数据结构,让结构化数据的清洗、处理、分析变得异常轻松。
- Matplotlib/Seaborn: 提供了从基础到高级的数据可视化能力,是探索数据、呈现结果不可或缺的工具。
深度学习框架的“一致选择”: 当今深度学习领域的两大巨头——Google支持的TensorFlow和Facebook(Meta)支持的PyTorch——都将Python作为其最主要、最优先支持的前端开发接口。它们通过Python封装了底层的CUDA核心,让开发者可以用简洁的Python代码,驱动GPU进行大规模并行计算。这种业界巨头的一致选择,反过来也极大地巩固了Python在深度学习领域的统治地位。
1.3.3 “共建共享”的社区文化
技术的发展,归根结底是人的发展。Python拥有一个全球范围内规模最大、最活跃、最具协作精神的开源社区。这种社区文化是Python生态能够持续繁荣的活水源头。
- 知识的民主化: 无论是初学者遇到的一个简单报错,还是前沿研究所需的复杂算法实现,在Python社区中(如Stack Overflow、GitHub、各类论坛),几乎总能找到答案、教程或现成的开源代码。这极大地降低了学习和进入该领域的门槛。
- 创新的加速器: 一篇重要的深度学习论文发表后,往往在几天甚至几小时内,社区中就会出现其PyTorch或TensorFlow的开源复现代码。这种“思想-代码-应用”的快速转化链条,得益于开源社区的“共建共享”文化,它以前所未有的速度推动着整个领域的边界向前拓展。
- 人才的蓄水池: 庞大的社区也意味着庞大的人才库。对于企业而言,选择Python技术栈意味着更容易招聘到合适的开发人才;对于个人而言,掌握Python则意味着拥有了通往数据科学和人工智能领域最重要的一张“通行证”。
综上所述,选择Python作为学习深度学习的语言,并非仅仅是选择一个工具,更是选择融入一个高效的开发范式、一个成熟强大的技术生态,以及一个充满活力与智慧的全球性社区。它将是您在这趟探索之旅中最值得信赖的伙伴。
1.4 本书的结构与学习路径图:如何高效地利用这本书
为了引导您系统地、由浅入深地掌握深度学习,本书精心设计了五个循序渐进的篇章,它们共同构成了一张从“知”到“行”再到“思”的完整智慧地图。
1.4.1 全书五大篇章概览
1.基础篇(奠定智慧的基石): 本篇章将为您打下坚实的理论与实践基础。您将厘清人工智能、机器学习与深度学习的内在逻辑,回顾其波澜壮阔的发展历程,并掌握深度学习所必需的数学语言和Python编程工具。同时,通过对传统机器学习的温故知新,您将更好地理解深度学习的突破与创新。
2.核心篇(深入神经网络的殿堂): 在本篇章中,您将正式踏入神经网络的核心领域。从最基本的神经元到多层感知机,从反向传播算法到主流深度学习框架(TensorFlow/PyTorch)的实战运用,您将系统学习神经网络的构建、训练与优化技巧,掌握深度学习的“炼丹术”。
3.进阶篇(掌握核心网络架构): 本篇章将带您深入探索深度学习领域最重要、最具影响力的几类网络架构。您将学习用于图像处理的卷积神经网络(CNN)、用于序列数据分析的循环神经网络(RNN),以及在自然语言处理领域掀起革命的Transformer架构。此外,还将介绍生成式模型,开启您的创造之旅。
4.实战篇(从理论到价值的转化): 理论的价值在于指导实践,而实践的意义在于创造价值。本篇章将带您走出象牙塔,用所学知识解决真实世界的问题。通过多个完整的项目实战,涵盖计算机视觉、自然语言处理等热门领域,您将体验从数据处理、模型训练、评估到最终部署的完整流程,具备将AI技术产业化的能力。
5.展望篇(探索未来的边界): 技术的发展永无止境,智慧的探索也永不停歇。本篇章将带您站在时代的前沿,眺望深度学习的未来发展方向。您将了解图神经网络、联邦学习、可解释AI、多模态学习等前沿技术,并深入探讨AI伦理与社会责任等重要议题,成为一个有远见、有责任感的AI从业者。
1.4.2 建议的学习路径
学习深度学习,如同攀登一座高峰,需要循序渐进,步步为营。我们为您提供以下两种建议的学习路径:
- 对于初学者(零基础或基础薄弱): 强烈建议您按部就班地阅读本书。请务必投入足够的时间和精力,认真消化基础篇的内容,尤其是数学与编程基础。在学习过程中,请务必亲手敲入并运行书中的每一个代码示例,完成每一个练习。不要急于求成,打牢基础是您未来能够走得更远、攀得更高的关键。
- 对于有经验者(有一定编程或机器学习基础): 如果您已经具备一定的Python编程经验或机器学习基础知识,可以将基础篇作为快速回顾和查漏补缺的工具。您可以重点投入到核心篇和进阶篇的学习中,深入理解各种模型架构和训练技巧。同时,请直接挑战实战篇的项目,通过实际操作来检验和提升自己的能力,并将本书作为一本实用的参考手册。
无论您选择哪种路径,请记住:实践是检验真理的唯一标准。 理论知识的掌握固然重要,但只有通过大量的动手实践,才能真正将知识内化为您的能力。
1.4.3 本书特色:理论、代码与心法的结合
为了确保您能够高效、深入地学习,本书在内容编排和呈现方式上,力求做到以下几点:
- 理论深度与实践广度并重: 我们不仅会深入剖析算法的数学原理和设计思想,更会提供丰富的代码示例和实战项目,确保您既能“知其然”,更能“知其所以然”,并最终“行其道”。
- 图文并茂,深入浅出: 复杂的概念和抽象的原理,我们将通过大量精心设计的图表、流程图和可视化案例来辅助解释,力求化繁为简,让晦涩难懂的知识变得直观易懂。
- 代码即修行,注重实操: 书中所有代码均提供完整注释,并鼓励您亲手敲入、运行、修改和实验。我们相信,只有经您之手的代码,才能真正内化为您的能力。所有代码都将是可运行、可复现的,并与真实项目接轨。
- “智慧锦囊”,点拨迷津: 在关键章节或易错点处,我们会以“智慧锦囊”的形式,分享一些书本之外的实践经验、常见误区、调试技巧和思维洞见,希望能助您在探索之路上少走弯路,直抵核心。
1.5 心法总纲:保持好奇、勤于实践、拥抱开源
在结束本章之前,请允许我分享三条贯穿整个学习旅程的“心法总纲”。它们比任何具体的知识点都更为重要,是您在深度学习乃至任何复杂领域取得成功的基石。
1.5.1 好奇心是第一驱动力
请永远保持一颗孩童般的好奇心。当您面对一个新的算法、一个复杂的模型时,不要仅仅满足于知道它“如何工作”,更要追问“为什么这样设计?”、“它解决了什么问题?”、“有没有其他可能性?”。这种对原理的不断追问,是您从知识的消费者蜕变为创造者的不二法门。好奇心将驱动您不断探索,发现知识的边界,并最终超越它。
1.5.2 实践是检验真理的唯一标准
计算机科学领域流传着一句名言:“Talk is cheap, show me the code.”(空谈无益,代码为证)。深度学习是一门高度实践性的学科。学习游泳最好的方式就是跳下水。请不要只停留在阅读和思考,一定要动手编程、复现论文中的模型、参加Kaggle等数据科学竞赛、用学到的知识去解决一个您自己感兴趣的真实问题。在实践中遇到的问题和获得的成功,将是您最宝贵的财富,也是您能力提升最快的途径。
1.5.3 拥抱开源,站在巨人的肩膀上
现代科技的飞速发展,离不开开源精神。请积极地学习、使用和贡献于开源社区。去GitHub上阅读优秀项目的源码,学习他人的代码风格和架构思想;当您从社区获益后,也请尝试通过提交问题、改进文档甚至贡献代码的方式回馈社区。这种开放、协作的文化,极大地缩短了前沿算法从论文到工业应用的周期,推动了整个领域的快速发展。融入开源,您将不再是孤军奋战,而是与全球顶尖的开发者共同成长。
第二章:数学与编程基础 —— 内功心法
- 2.1 线性代数:向量、矩阵、张量及其运算(不仅是计算,更是空间的变换)。
- 2.2 微积分:导数、偏导数、链式法则与梯度(理解变化与优化的语言)。
- 2.3 概率论与信息论:概率分布、期望、熵与交叉熵(衡量不确定性与信息)。
- 2.4 NumPy:精通多维数组操作,为数据处理提速。
- 2.5 Pandas:结构化数据的探查、清洗与预处理。
- 2.6 Matplotlib & Seaborn:数据的可视化,让洞察直观呈现。
格物致知 —— 深度学习背后的数学与代码之道
欢迎来到本书最具奠基意义的章节。在读者们即将启程,探索深度学习这个由算法、模型与数据构成的奇妙新世界之前,我们必须首先修炼一套“内功心法”。这套心法,由两部分组成:一部分是洞察万物规律的数学之道,另一部分则是将思想化为现实的编程之术。
或许,部分读者会对标题中的“数学”二字心生畏惧,联想到枯燥的公式推导与繁复的计算。请放心,这恰恰是本章致力于破除的迷思。我们不会将重点放在“如何计算”上,而是聚焦于“为何如此”——我们将一同建立起对关键数学概念直观的几何想象,理解其在现实世界中的物理意义,甚至品味其背后蕴含的哲学思辨。您会发现,线性代数是描述结构与变换的语言,微积分是谱写变化与优化的乐章,而概率论则是衡量不确定性的标尺。它们是理解算法本质的“世界观”。
与此相辅相成的,是编程的“方法论”。如果说数学思想是设计师的蓝图,那么Python及其强大的科学计算库,就是我们手中巧夺天工的工具。本章将引导读者精通NumPy、Pandas、Matplotlib这三柄“神兵利器”,它们是数据处理、分析与可视化的基石,是驱动深度学习这驾豪华马车的双轮中,坚实有力的那一环。
本章的修行路径清晰而坚定:先通“理”,再利“器”。我们将首先漫步于数学的殿堂,而后在编程的工坊里挥洒实践。唯有内外兼修,理术合一,方能在后续的深度学习实战中,做到知其然,更知其所以然,从而游刃有余,直抵精通。
现在,请抛开疑虑,保持一颗好奇与开放的心,与我们一同开始这场“格物致知”的旅程。
2.1 线性代数:描绘世界的结构与变换
线性代数,是现代数学的支柱之一,更是深度学习不可或缺的语言。它为我们提供了一套强大的工具和视角,来理解和操作高维数据。本质上,线性代数研究的是向量、向量空间以及线性变换。在本节中,我们将摒弃繁杂的证明,专注于建立这些概念的直观理解,看它们如何描绘出世界的结构,并执行优雅的变换。
2.1.1 向量(Vector):定义空间中的“存在”
向量的几何与物理意义
-
何为向量 在最浅的层面,一个向量可以看作是列表中的一串数字,例如
v = [3, 4]。然而,它的内涵远比这丰富。在深度学习的语境中,一个向量是对现实世界某个对象关键特征的数字化抽象。更重要的是,它在几何上代表了多维空间中的一个点,或一个从原点出发、带有方向和长度的箭头。一个直观的例子: 假设我们想描述一个人的健康状况,我们选择了两个特征:身高(厘米)和体重(公斤)。如果某人的身高是175cm,体重是70kg,我们就可以用一个二维向量
p = [175, 70]来表示他。这个向量,就是“健康特征空间”这个二维平面上的一个确定的点。从文本、图像到声音,深度学习的第一步,往往就是将这些复杂的、非结构化的信息,转化为一个个高维空间中的向量(这个过程称为“嵌入”或“特征提取”)。因此,理解向量,就是理解深度学习如何“看待”世界万物。
-
向量的模与方向 每一个向量都包含两个核心信息:
- 模(Magnitude/Norm):代表向量的“长度”。在几何上,它是从原点到向量所指向的点的距离。在物理上,它通常代表了特征的强度或事物的大小。例如,在推荐系统中,一个用户向量的模可能代表其兴趣的广泛程度。向量
v = [3, 4]的模(L2范数)为√(3² + 4²) = 5。 - 方向(Direction):代表向量在空间中所指的朝向。它通常代表了特征的性质或事物的类别归属。两个方向相近的向量,通常意味着它们所代表的对象在本质上是相似的。
- 模(Magnitude/Norm):代表向量的“长度”。在几何上,它是从原点到向量所指向的点的距离。在物理上,它通常代表了特征的强度或事物的大小。例如,在推荐系统中,一个用户向量的模可能代表其兴趣的广泛程度。向量
向量的运算与应用
-
点积(Dot Product) 向量点积是线性代数中一个极其有用的运算。对于两个向量
a = [a₁, a₂]和b = [b₁, b₂],它们的点积是a · b = a₁b₁ + a₂b₂。这个简单的计算背后,蕴含着深刻的几何意义:a · b = |a| * |b| * cos(θ)其中|a|和|b|是两个向量的模,θ是它们的夹角。这个公式告诉我们,点积的结果融合了两个向量的长度和它们方向上的一致性。 -
实战应用:余弦相似度 在很多应用中,我们只关心两个向量的方向是否一致,而不想受到它们长度的影响。例如,在判断两篇文章的主题是否相似时,一篇长文章和一篇短文章只要主题相同,它们的向量方向就应该接近,我们不希望因为文章长度(向量的模)不同而影响判断。
为此,我们从点积公式中推导出余弦相似度(Cosine Similarity):
Similarity = cos(θ) = (a · b) / (|a| * |b|)余弦相似度的值域在[-1, 1]之间:这个简单的指标,是现代推荐系统、搜索引擎和自然语言处理中衡量“相似性”的基石。
- 当值为
1时,表示两个向量方向完全相同,代表的对象最相似。 - 当值为
0时,表示两个向量方向正交(垂直),代表的对象不相关。 - 当值为
-1时,表示两个向量方向完全相反。
- 当值为
2.1.2 矩阵(Matrix):组织“关系”与执行“变换”
如果说向量是单个“存在”,那么矩阵就是这些“存在”的有序集合,是描绘群体关系与执行系统性变化的宏大画卷。
矩阵的本质
- 何为矩阵 一个矩阵,就是一个二维的数字阵列。它可以被看作是一组行向量或一组列向量的有序集合。矩阵是二维关系的天然载体。
- 一张灰度图片,其每个像素的灰度值可以构成一个矩阵。
- 一个包含多个学生、多门课程成绩的数据集,本身就是一个“学生-课程”矩阵。
- 在深度学习中,一个神经网络层的权重,通常就存储在一个矩阵中。
矩阵乘法的核心——空间变换
-
矩阵与向量相乘 这是线性代数中最核心、最神奇的操作。当一个矩阵
M与一个向量v相乘得到一个新的向量v'时(v' = Mv),这绝不仅仅是一次算术计算。从几何的角度看,这是一次由矩阵M所定义的对整个空间的线性变换。一个生动的想象: 想象一张画着许多点的、无限大的橡胶膜(代表我们的二维空间)。一个
2x2的矩阵,就是一套对这张膜进行操作的指令集。当这个矩阵作用于空间中的每一个点(向量)时,整张橡胶膜可能会被旋转一个角度,或者在某个方向上被拉伸/压缩(缩放),也可能被扭曲(剪切)。原始空间中所有平行且等距的网格线,在变换后依然保持平行且等距,这就是“线性”变换的含义。
实战哲思:神经网络的“魔法” 现在,我们可以揭示神经网络“魔法”的第一层奥秘了。一个神经网络由许多层堆叠而成,而每一层的核心计算,本质上就是一次由该层的权重矩阵(W)所主导的空间变换,再叠加上一个偏置向量(b)的平移,最后通过一个非线性激活函数(下一章详述)进行“弯曲”。
output = activation(W * input + b)
网络的“学习”或“训练”过程,正是在不断地、精巧地调整这些权重矩阵 W,试图找到一系列最佳的空间变换组合。其最终目的,是希望将原始特征空间中那些混杂在一起、难以区分的数据点(例如,代表“猫”的图片向量和代表“狗”的图片向量),通过层层变换,扭转到一个新的、高维的空间中去。在这个新的空间里,原本纠缠的数据被“解开”,不同类别的数据被清晰地推向了不同的区域,从而可以被一个简单的平面轻易地分开。
因此,理解了矩阵是空间变换的执行者,也就理解了神经网络进行特征学习与分类的核心机制。
2.1.3 张量(Tensor):高维数据的标准“容器”
在掌握了向量和矩阵之后,我们自然地迈向一个更广义、更强大的概念——张量。
从向量、矩阵到张量
- 维度的扩展 张量是多维数组的统称,是向量和矩阵在更高维度上的推广。我们可以这样理解它们的关系:
- 0阶张量:一个标量(Scalar),即一个单独的数字(如
5)。它没有方向,只有一个大小。 - 1阶张量:一个向量(Vector),即一维数组(如
[1, 2, 3])。 - 2阶张量:一个矩阵(Matrix),即二维数组(如
[[1, 2], [3, 4]])。 - 3阶及以上张量:我们通常直接称之为张量(Tensor)。
- 0阶张量:一个标量(Scalar),即一个单独的数字(如
张量在深度学习中的角色
张量,正是承载这些复杂高维数据的标准数据结构。所有主流的深度学习框架,如TensorFlow和PyTorch,其核心数据单元都是张量。因此,熟练地理解和操作张量,是进行深度学习编程的必备技能。
为何需要张量 因为深度学习所处理的现实世界数据,其结构天然就是高维的。
- 一张彩色图片:它有高度、宽度和颜色通道(如RGB三通道)三个维度,因此它是一个3阶张量,形状(Shape)可以表示为
(高度, 宽度, 3)。 - 一段视频:它是由连续的图片帧组成的,所以在图片的基础上增加了一个时间(或帧数)的维度,构成一个4阶张量,形状为
(帧数, 高度, 宽度, 3)。 - 一个批次(Batch)的数据:在训练神经网络时,我们通常不会一次只处理一张图片,而是将多张图片组成一个“批次”来并行处理,以提高效率。这就又增加了一个“批量大小”的维度。例如,一个包含64张彩色图片的批次,就是一个4阶张量,形状为
(64, 高度, 宽度, 3)。
至此,我们完成了对线性代数核心概念的直观解读。读者应建立起这样的认知:向量定义了空间中的存在,矩阵执行了对空间的变换,而张量则是容纳这一切高维数据的标准容器。这套语言,为我们后续理解和构建复杂的深度学习模型,打下了坚实的结构性基础。接下来,我们将引入“变化”的维度,探索微积分的奥秘。
2.2 微积分:理解变化的语言与优化的艺术
如果说线性代数给了我们描述世界状态的“名词”和“形容词”(向量、矩阵),那么微积分则为我们提供了描述世界运动与变化的“动词”和“副词”。它是关于“变化率”的数学,是理解机器学习模型如何“学习”和“优化”的关键所在。
2.2.1 导数与偏导数:捕捉“瞬时变化”的慧眼
导数的本质
-
从斜率到变化率 读者可能还记得,导数在几何上被定义为函数曲线上某一点的切线斜率。但这只是其表象,导数更深刻的本质是函数在该点的“瞬时变化率”。它精准地回答了这样一个核心问题:“当函数的输入
x发生一个极其微小的扰动时,其输出y会如何随之响应?”这个“响应”的剧烈程度,就是导数的值。导数为正,表示函数在此处呈上升趋势;导数为负,则呈下降趋势;导数的绝对值越大,表示变化的趋势越“陡峭”。
偏导数的智慧 现实世界的问题,其结果往往由多个因素共同决定。例如,一个商品的销量 S,可能同时受到价格 P、广告投入 A 和季节 T 的影响,即 S = f(P, A, T)。如果我们想知道“在保持广告和季节不变的情况下,价格每上涨一元,销量会如何变化?”,这时就需要偏导数。
偏导数的智慧在于,它允许我们在多变量的复杂系统中,暂时“冻结”其他所有变量,单独考察某一个变量对函数结果的影响力。这是一种强大的“归因”工具,让我们能够逐一分析每个因素的贡献。在数学上,函数 f 对变量 P 的偏导数记作 ∂f/∂P。
2.2.2 链式法则:层层解构“因果链条”
链式法则的核心思想 许多系统中的因果关系是层层嵌套的。比如,施肥量 x 影响土壤肥力 u,土壤肥力 u 又影响作物产量 y。如果我们想知道“施肥量 x 的微小变化,最终会对产量 y 产生多大影响?”,就需要用到链式法则。
链式法则揭示了在一个由 y = f(u) 和 u = g(x) 构成的复合函数 y = f(g(x)) 中,最终结果的变化率是如何由各个环节的变化率相乘传递而来的: dy/dx = dy/du * du/dx 最终影响等于中间环节影响与初始环节影响的乘积。这是一个极其深刻的规律,它让我们能够解构一个复杂的因果链条。
反向传播的灵魂 深度神经网络,就是一个极深、极复杂的复合函数。网络的输入 X 经过第一层变换得到 H₁,H₁ 经过第二层变换得到 H₂,……,最终经过输出层得到预测结果 Ŷ,而预测结果 Ŷ 与真实标签 Y 之间会产生一个误差(或损失)L。
我们训练网络的目标,是调整网络中成千上万的参数(权重 W 和偏置 b),以最小化这个最终的误差 L。但问题是,身处网络深处的某个参数 Wᵢⱼ,它一个小小的变动,是如何通过层层传递,最终影响到 L 的呢?
反向传播(Backpropagation)算法,正是链式法则在神经网络中的一次宏大而辉煌的应用。它从最终的误差 L 出发,“反向”地、逐层地运用链式法则,计算出误差 L 对网络中每一个参数的偏导数(∂L/∂Wᵢⱼ)。这个偏导数,就精确地衡量了该参数对最终误差的“贡献度”,并指明了它应该调整的方向。可以说,没有链式法则,就没有反向传播,也就没有现代深度学习的根基。
2.2.3 梯度:指向“最优”的罗盘
梯度的几何意义
对于一个多变量函数,我们将它对所有自变量的偏导数,打包成一个向量,这个向量就叫做梯度(Gradient)。例如,对于函数 f(x, y),其梯度为 ∇f = [∂f/∂x, ∂f/∂y]。
梯度这个向量,具有一个非凡的几何意义:它指向函数值增长最快的方向。
负梯度:相应地,梯度的反方向(-∇f),就指向了函数值下降最快的方向。
梯度下降的修行
梯度为我们指明了方向,而梯度下降算法,就是沿着这个方向去寻找函数最小值的具体方法。它是深度学习中最核心、最常用的优化算法。我们可以用一个生动的比喻来理解它的修行过程:
黑夜下山的比喻: 想象一位读者深夜被困在一座连绵的山脉中(山脉的表面就是我们想要最小化的损失函数)。目标是尽快走到山脉的最低点(损失函数的最小值)。
由于天黑,无法看清全局地貌。但这位读者可以做一件事:用脚在原地试探一圈,感受哪个方向是下坡最陡峭的。这个“最陡峭的下坡方向”,正是负梯度方向。
于是,他朝着这个方向迈出一步。这一步的“大小”,我们称之为学习率。
如果步子迈得太大(学习率过高),可能会直接跨过谷底,甚至跑到对面的山坡上,导致“振荡”或“发散”。
到达新位置后,他再次重复这个过程:环顾四周,找到当前位置最陡的下坡方向,再迈出一步……周而复始,通过无数次的迭代,他将一步步地逼近山谷的最低点。
神经网络的训练过程,就是一场在亿万维度参数空间中的“梯度下降”之旅。通过不断地计算损失函数关于所有参数的梯度,并沿着负梯度方向去更新这些参数,模型最终能找到一组使损失最小化的最优参数。
如果步子迈得太小(学习率过低),下山的速度会非常缓慢。
2.3 概率论与信息论:衡量不确定性与知识
世界充满了随机与未知。概率论为我们提供了拥抱和描述不确定性的数学语言,而信息论则为我们提供了一把度量“信息”与“知识”的尺子。
2.3.1 概率分布与期望:拥抱不确定性
概率分布(Probability Distribution) 它是一张描绘随机变量所有可能取值及其对应概率的蓝图。例如,一个公平骰子的概率分布是 {1:1/6, 2:1/6, ..., 6:1/6}。在机器学习中,分类模型的输出,往往就是一个概率分布,如 {猫: 0.8, 狗: 0.15, 其他: 0.05}。
期望(Expectation) 它是概率分布的加权平均值,是在不确定性中我们能做出的最“合理”的长期平均猜测。掷骰子的期望点数是3.5。虽然单次掷不出3.5,但大量重复实验的平均结果会趋近于它。
2.3.2 熵:度量“混乱”与“信息”
信息熵(Information Entropy) 信息熵是信息论的奠基概念,用于量化一个系统的不确定性或混乱程度。一个系统越混乱、结果越不可预测,其熵值就越高。
- 一个作弊的、总出“6”的骰子,其结果完全确定,熵为0。
- 一个公平的骰子,其结果最不确定,熵最大。 熵还有另一层深刻含义:它等于彻底搞清楚该系统状态所需要的最少信息量。
2.3.3 交叉熵:衡量“认知”与“真相”的距离
从KL散度到交叉熵 如果我们有两个概率分布,一个代表“真相”的分布 P,另一个代表我们模型的“认知”(预测)的分布 Q,我们如何衡量它们之间的差距?**KL散度(Kullback-Leibler Divergence)**正是为此而生。 在机器学习的分类任务中,我们更常用一个与KL散度紧密相关的量——交叉熵(Cross-Entropy)来作为损失函数。
损失函数的哲学 交叉熵损失函数衡量的是:用我们的“认知”Q 去编码来自“真相”P 的事件,平均需要多少信息量。如果 Q 与 P 完全一致,交叉熵就达到最小值。 因此,模型训练的过程,就是不断调整参数,以最小化预测分布与真实标签分布之间的交叉熵。这在哲学上,可以看作是一个模型不断放下自己的“我执”(错误的认知),努力去趋近“真相”的修行过程。
2.4 NumPy:科学计算的基石与加速器
理论学习完毕,现在我们开始铸造“神兵”。NumPy(Numerical Python)是Python科学计算生态的核心,它为我们提供了高性能的多维数组对象及相关工具。
2.4.1 ndarray:NumPy的灵魂
高性能的多维数组对象 NumPy的核心是ndarray对象。它的高性能源于两个关键设计:
- 内存布局:
ndarray在内存中是一块连续的、未分装的存储区域,所有元素类型相同。这使得它可以利用现代CPU的向量化指令(SIMD),进行并行计算。 - C语言后端:其底层运算由高度优化的C语言代码执行,避免了Python原生解释器的性能开销。
数组的创建与变形
import numpy as np
# 从列表创建
a = np.array([1, 2, 3])
# 创建特定数组
zeros = np.zeros((2, 3)) # 2x3的全0矩阵
ones = np.ones(5) # 长度为5的全1向量
arange = np.arange(0, 10, 2) # [0, 2, 4, 6, 8]
# 改变形状
b = np.arange(6).reshape((2, 3)) # 创建一个1x6向量并重塑为2x3矩阵
# 转置
c = b.T
2.4.2 向量化运算与广播机制
向量化(Vectorization):告别低效循环 向量化是指直接对整个数组或数组间进行运算,而无需编写显式的for循环。
# 非向量化 (慢)
a = list(range(1000000))
b = list(range(1000000))
c = []
for i in range(len(a)):
c.append(a[i] + b[i])
# 向量化 (快)
a_np = np.arange(1000000)
b_np = np.arange(1000000)
c_np = a_np + b_np
在性能上,向量化版本通常比循环版本快几个数量级。
广播(Broadcasting):智能的维度对齐 广播是NumPy最强大的特性之一,它允许不同形状的数组在一定规则下进行算术运算。
规则核心:从两个数组的尾部维度开始逐一比较,如果维度相等,或其中一个为1,则可以广播;否则报错。缺失的维度会被视为1。
matrix = np.array([[1, 2, 3], [4, 5, 6]]) # shape (2, 3)
vector = np.array([10, 20, 30]) # shape (3,)
# 广播机制会自动将vector“扩展”为[[10,20,30], [10,20,30]]
result = matrix + vector
# result is [[11, 22, 33], [14, 25, 36]]
2.5 Pandas:驾驭结构化数据的瑞士军刀
Pandas是建立在NumPy之上的数据分析库,提供了Series和DataFrame两种强大的数据结构,是处理和分析表格类(结构化)数据的首选工具。
2.5.1 Series与DataFrame:带标签的数据容器
Series:一个带标签的一维数组,可以看作是NumPy数组和Python字典的结合体。DataFrame:一个二维的、带标签的表格型数据结构,拥有行索引和列索引。它是Pandas中使用最广泛的核心。
2.5.2 数据的探查、清洗与预处理
import pandas as pd
# 假设我们有一个CSV文件 'titanic.csv'
df = pd.read_csv('titanic.csv')
# 2.5.2.1 数据探查
print(df.head()) # 查看前5行
print(df.info()) # 查看列信息、数据类型、非空值数量
print(df.describe()) # 查看数值列的统计摘要
# 2.5.2.2 数据清洗
# 处理缺失值:将Age列的缺失值用年龄中位数填充
median_age = df['Age'].median()
df['Age'].fillna(median_age, inplace=True)
# 2.5.2.3 数据转换与操作
# 选择与过滤:选择所有年龄大于60岁的乘客
seniors = df.loc[df['Age'] > 60]
# 分组与聚合:按性别计算平均票价
avg_fare_by_sex = df.groupby('Sex')['Fare'].mean()
print(avg_fare_by_sex)
2.6 Matplotlib & Seaborn:让数据开口说话的艺术
数据可视化是理解数据、展示洞见的强大手段。Matplotlib是Python可视化的基础库,而Seaborn则是在其之上构建的、更侧重统计美学的高级库。
2.6.1 Matplotlib:Python可视化的基石
快速绘图:Pyplot接口
import matplotlib.pyplot as plt
x = np.linspace(0, 10, 100)
y = np.sin(x)
plt.plot(x, y, label='sin(x)')
plt.xlabel('x axis')
plt.ylabel('y axis')
plt.title('A Simple Plot')
plt.legend()
plt.show()
精细控制:面向对象接口
fig, ax = plt.subplots() # 创建一个Figure对象和一个Axes对象
ax.plot(x, y, label='sin(x)')
ax.set_xlabel('x axis')
ax.set_ylabel('y axis')
ax.set_title('A Simple Plot (OO Style)')
ax.legend()
plt.show()
面向对象的方式在绘制复杂图表时更具优势。
2.6.2 Seaborn:基于Matplotlib的统计美学
Seaborn的优势 Seaborn的优势在于其美观的默认样式和内置的、面向统计分析的高级绘图函数。
常用高级图表
import seaborn as sns
# 使用pandas加载的titanic数据集 df
# 绘制一个箱形图,观察不同船舱等级乘客的年龄分布
sns.boxplot(x='Pclass', y='Age', data=df)
plt.title('Age Distribution by Passenger Class')
plt.show()
# 绘制一个热力图,可视化数值特征间的相关性
numeric_cols = df.select_dtypes(include=np.number)
correlation_matrix = numeric_cols.corr()
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Matrix of Numeric Features')
plt.show()
小结
至此,我们完成了第二章“内功心法”的全部修行。从线性代数的空间变换,到微积分的优化艺术,再到概率论的量化不确定性,我们为理解深度学习算法铺设了坚实的理论基石。紧接着,我们亲手掌握了NumPy、Pandas、Matplotlib/Seaborn这三大编程利器,它们是将理论付诸实践、与数据对话的强大工具。
读者现在应深刻理解,数学并非算法的障碍,而是洞察其本质的钥匙;代码亦非冰冷的指令,而是实现创想的画笔。当“理”与“器”在您手中融会贯通,深度学习的大门已然为您敞开。带着这份内功,我们将在后续的章节中,充满信心地构建、训练并剖析各种复杂的神经网络模型。
第三章:机器学习经典回顾 —— 温故而知新
- 3.1 机器学习的三大范式:问道于天地。
- 3.2 经典模型剖析:一花一世界,一叶一菩提。
- 3.3 模型的评估与优化:知其然,更要知其所以然。
为何要回顾经典?
亲爱的读者朋友,在您即将踏入深度学习那片广袤而深邃的森林之前,我们要先带您走过一片风景秀丽、基石坚固的丘陵。这片丘陵,便是由那些经典的机器学习算法构成的。或许您会问,我们不是要学最前沿的深度学习吗?为何要在此“逗留”?
答案很简单:思想,总有其传承。
您可知道,深度学习的基石——神经网络中的单个神经元,其思想源头便是本章将要介绍的线性模型吗?您可知道,那些动辄拥有亿万参数的庞大网络模型,其背后蕴含的“群体智慧”,早已在“随机森林”这样的集成方法中初现端倪?经典模型,正是深度学习的“思想源头”和“活水”。不溯其源,则难以知其流。
其次,我们要有性价比的智慧。深度学习固然强大,但它也像一柄需要巨大能量催动的“屠龙刀”。在许多现实场景中,问题可能只是一只“鸡”,用一把精致的“水果刀”——比如逻辑回归或决策树——便能以极低的计算成本、极快的时间和完美的解释性来解决。学会“杀鸡用牛刀”之前,必先要懂得何时该用、如何用好那把“水果刀”。这是一种工程师的务实,也是一种实践家的智慧。
最后,也是最重要的,学习这些相对简单的模型,是为了帮助您建立一种宝贵的“算法直觉”。通过亲手实现一个线性回归,您会直观地感受到什么是“拟合”;通过调试一棵决策树,您会深刻地理解什么是“过拟合”;通过比较不同的评估指标,您会明白“泛化能力”的真正含义。这些核心概念,在经典模型上显得清晰而具体。有了这份直觉,当您未来面对深度学习这个复杂的“黑箱”时,才能不畏惧、不迷茫,拥有洞察其本质的眼光。
所以,请先静下心来。让我们一起,站上这些巨人的肩膀,不是为了停留,而是为了看得更远、更清。这趟“温故知新”的旅程,将为您未来的深度学习之路,打下最坚实的思想地基。
3.1 机器学习的三大范式:问道于天地
在正式接触具体的算法之前,读者需要先建立一个宏观的认知框架。机器学习根据其学习方式和数据特点,主要可以分为三大范式:监督学习、无监督学习和强化学习。这三种范式,可以看作是机器向世界“问道”的三种不同途径,每一种都对应着一类独特的现实问题。
3.1.1 监督学习:有师之学,依标而行
核心思想 监督学习是目前应用最广泛、最成熟的机器学习范式。它的核心思想,是从带有明确“标签”(Label)或“答案”(Answer)的数据中进行学习。这里的“标签”就是我们预先知道的、正确的输出。整个学习过程,就如同有一位无所不知的老师(即标签数据)在旁边进行指导,每当模型做出一次预测,老师就会告诉它正确答案是什么,模型则根据这次反馈来修正自己,力求下次做得更好。
因此,“监督”二字的精髓在于,学习的每一步都有来自“正确答案”的直接反馈。
两大任务 根据标签类型的不同,监督学习主要解决两类问题:
回归(Regression):当我们的目标是预测一个连续的数值时,这类问题就被称为回归。预测值的范围是连续的,可以取任意实数。
- 譬如:根据房屋的面积、位置、房龄等特征,预测其市场价格(一个连续的金额);根据历史气象数据,预测明天最高气温(一个连续的温度值)。
分类(Classification):当我们的目标是预测一个离散的类别时,这类问题就是分类。预测的结果是有限个类别中的一个。
- 譬如:根据邮件的内容和发件人信息,判断该邮件是**“垃圾邮件”还是“非垃圾邮件”(二分类问题);根据一张动物图片,识别出它是“猫”、“狗”还是“鸟”**(多分类问题)。
学习的本质 从数学的角度看,监督学习的本质,就是寻找一个最优的映射函数 f。这个函数能够建立起从输入特征 X 到输出标签 Y 之间的稳定关系,即 Y ≈ f(X)。模型的训练过程,就是通过海量的已知 (X, Y) 数据对,来不断调整函数 f 的内部参数,使其尽可能地逼近这个真实存在的、但我们未知的潜在映射规律。
3.1.2 无监督学习:无师之学,观物自省
核心思想 与监督学习截然相反,无监督学习所面对的数据是**完全没有“标签”**的。这意味着没有现成的“正确答案”可供参考。学习的目标,是在没有外部指导的情况下,仅仅依靠数据自身,去发现其中隐藏的结构、模式或内在规律。
这个过程,好比一位古代的天文学家,他所拥有的只是满天繁星的位置数据(没有标签的输入 X),通过日复一日的观察与思考,他自己发现了某些星星组合起来,形态上很相似,于是将它们命名为“猎户座”、“北斗七星”等(即聚类)。他是在数据中自我发现了规律。
典型任务 无监督学习的应用场景同样广泛,主要包括:
聚类(Clustering):将数据集中的样本,根据它们内在的相似性,自动地划分为若干个簇(Cluster)。目标是让同一簇内的数据点尽可能相似,不同簇之间的数据点尽可能相异。
- 譬如:电商平台根据用户的购买历史、浏览行为等数据,将庞大的客户群体自动划分为**“高价值客户”、“潜力客户”、“待激活客户”**等不同的群体,以便实施精准营销。
降维(Dimensionality Reduction):在尽可能保留原始数据主要信息的前提下,用更少的特征来表示数据。这有助于数据可视化、去除噪声、以及提升后续其他学习算法的效率。
- 譬如:衡量一个地区宏观经济状况的指标可能有上百个(GDP、CPI、PMI、进出口额等),这些指标间可能存在高度相关性。降维技术可以将这上百个指标压缩为几个核心的“经济景气指数”,抓住主要矛盾。
学习的本质 无监督学习的本质,不是去拟合一个输入到输出的映射,而是深入探索数据 X 自身内在的分布、关联与结构。它试图回答的问题是:“这堆数据本身,可以被如何组织和理解?”
3.1.3 强化学习:行万里路,动中觉悟
核心思想 强化学习是三大范式中最具“行动智慧”的一种。它关注的是一个智能体(Agent)如何在一个复杂的、动态的环境(Environment)中,通过与环境的互动来学习如何做出最优决策,以达成一个长远的目标。
它的学习方式既非依赖标签,也非纯粹观察,而是**“试错”(Trial and Error)。智能体做出一个动作(Action),环境会因此发生改变并反馈给智能体一个奖励(Reward)或惩罚(Punishment)信号。智能体的目标,就是学习一个最优的策略(Policy)——即在何种状态(State)下应该采取何种动作——来最大化它在未来能够获得的累积奖励**。
核心要素 一个强化学习问题,通常由以下几个核心要素构成:
- 智能体(Agent):学习者和决策者。
- 环境(Environment):智能体外部的世界,与智能体进行交互。
- 状态(State):对当前环境的一个描述。
- 动作(Action):智能体可以采取的行为。
- 奖励(Reward):环境对智能体上一步动作的即时反馈信号。
学习的隐喻 强化学习的过程,与生物学习新技能的过程极为相似。
譬如,婴儿学走路。婴儿(智能体)在客厅(环境)中,他当前的姿势和位置是(状态)。他尝试迈出一步(动作)。如果成功前进了,父母的鼓励就是(正奖励);如果不幸摔倒了,疼痛感就是(负奖励/惩罚)。通过无数次的尝试,婴儿的大脑逐渐学会了在各种状态下,如何协调肌肉做出正确的动作,以实现“持续行走不摔倒”这个长期目标。
在技术领域,强化学习被广泛应用于训练AI下棋(AlphaGo)、玩电子游戏、控制机器人行走、优化交通信号灯调度等动态决策问题。
好了,读者朋友们,通过以上介绍,相信大家对机器学习的三大范式已经有了一个清晰的认识。它们分别从“有师之学”、“无师之学”和“动中觉悟”三个维度,为机器赋予了学习的能力。接下来,我们将深入到监督学习的阵营中,从最经典、最基础的模型开始,剖析它们的内在机理。
3.2 经典模型剖析:一花一世界,一叶一菩提
本节将要介绍的几个经典模型,各自都代表了一种核心的建模思想。它们就像几扇不同的窗户,让我们从不同的角度窥见机器学习解决问题的智慧。每一个模型,都是一个自成体系的小世界。
3.2.1 线性回归与逻辑回归:从线性到非线性的桥梁
线性模型是机器学习世界中最基础、最重要的模型家族。它们以其简洁、高效和高度的可解释性,成为了许多复杂算法的基石。
线性回归(Linear Regression):大道至简,直来直往
模型哲学 线性回归的背后,是一种朴素而强大的世界观:它相信世间万物的许多联系是简单的、线性的。它试图用一条笔直的线(在一维空间中)或一个平整的面(在多维空间中),来描述输入特征与输出值之间的关系。这种“直来直往”的假设,虽然简单,却惊人地有效,能够抓住许多现实问题的核心趋势。
数学形式 对于一个拥有 n 个特征的样本 x = (x₁, x₂, ..., xₙ),线性回归模型预测其输出 ŷ (读作 y-hat) 的公式为: ŷ = w₁x₁ + w₂x₂ + ... + wₙxₙ + b 这个公式可以用更简洁的向量形式表示:ŷ = wᵀx + b
- 权重(weights)
w:向量w = (w₁, w₂, ..., wₙ)中的每一个元素wᵢ,代表了第i个特征xᵢ对最终预测结果的影响力。wᵢ的绝对值越大,说明该特征越重要。 - 偏置(bias)
b:它是一个截距项,代表了在不考虑任何输入特征的情况下,预测值的基准水平。
损失函数:最小二乘法 模型如何知道哪条直线才是“最佳”的呢?我们需要一个标准来衡量“好”与“坏”。在线性回归中,这个标准就是均方误差(Mean Squared Error, MSE),也称为最小二乘法。 它的思想直观而优美:对于每一个训练样本,模型都有一个预测值 ŷ 和一个真实值 y。它们之间的差距 (y - ŷ) 就是预测误差。我们将所有样本的这个误差进行平方(以消除正负号并放大较大误差的影响),然后求其平均值。 几何意义:最小化均方误差,等价于寻找一条直线,使得所有数据点到这条直线的竖直距离的平方和最小。这条直线,就是对数据拟合得最好的直线。
代码实战 在Python中,Scikit-Learn库为我们实现线性回归提供了极大的便利。下面是一个简单的示例,我们将使用它来预测一个基于“学习小时数”的“考试分数”。
# 导入所需库
import numpy as np
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
# 1. 准备数据 (X: 学习小时数, y: 考试分数)
X = np.array([[2], [4], [5], [6], [8], [10]])
y = np.array([55, 60, 68, 75, 85, 95])
# 2. 创建并训练模型
model = LinearRegression()
model.fit(X, y)
# 3. 查看模型参数
w = model.coef_[0] # 权重 w
b = model.intercept_ # 偏置 b
print(f"学习到的模型: 分数 = {w:.2f} * 小时数 + {b:.2f}")
# 4. 进行预测并可视化
plt.scatter(X, y, color='blue', label='真实数据') # 绘制原始数据点
plt.plot(X, model.predict(X), color='red', label='回归直线') # 绘制拟合的直线
plt.xlabel('学习小时数')
plt.ylabel('考试分数')
plt.legend()
plt.show()
通过这段代码,读者可以亲眼看到一条红色的直线,它以“最小二乘”的准则,优雅地穿过了蓝色的数据点,揭示了学习时间与分数之间的线性关系。
逻辑回归(Logistic Regression):在边界处优雅转身
为何需要 如果我们想预测的不是连续的分数,而是“及格”与“不及格”这两个类别呢?线性回归的输出是 (-∞, +∞) 的连续值,无法直接用于分类。我们需要一个模型,它能输出一个表示“概率”的值。逻辑回归应运而生,它虽然名字里有“回归”,但其本质是一个经典的二分类算法。
核心机关:Sigmoid函数 逻辑回归的巧妙之处,在于它在线性回归的基础上,套上了一个“马甲”——Sigmoid函数(也称Logistic函数)。 Sigmoid函数的数学形式为:σ(z) = 1 / (1 + e⁻ᶻ) 它的神奇之处在于,无论输入 z 是多大或多小的实数,它的输出值 σ(z) 永远被压缩在 (0, 1) 这个区间内。这正好符合概率的定义! 逻辑回归的做法是:
- 先像线性回归一样,计算一个线性输出
z = wᵀx + b。 - 然后,将这个
z值送入Sigmoid函数,得到p = σ(z)。 这个输出p就可以被解释为样本属于“正类”(通常用1表示)的概率。如果p > 0.5,我们就预测为正类;反之,则预测为负类。
决策边界(Decision Boundary) p = 0.5 是分类的临界点,它发生在 z = 0 的时候。也就是说,wᵀx + b = 0 这条线(或高维平面)成为了两个类别的分界线,我们称之为决策边界。在决策边界一侧的点被划分为一类,另一侧的点被划分为另一类。逻辑回归的“学习”,就是在寻找这条最佳的决策边界。
代码实战 我们使用Scikit-Learn来完成一个简单的二分类任务,比如根据肿瘤大小预测其为良性还是恶性。
# 导入所需库
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_classification
# 1. 生成模拟分类数据
X, y = make_classification(n_samples=100, n_features=1, n_informative=1,
n_redundant=0, n_clusters_per_class=1, random_state=42)
# 2. 创建并训练模型
model = LogisticRegression()
model.fit(X, y)
# 3. 可视化决策边界 (此处仅为示意,真实可视化较复杂)
# 决策边界在 z=0 处,即 w*x + b = 0, x = -b/w
boundary_x = -model.intercept_ / model.coef_[0]
print(f"决策边界位于 x = {boundary_x[0]:.2f}")
# 绘制数据点
plt.scatter(X, y, c=y, cmap='bwr', edgecolor='k')
# 绘制决策边界
plt.axvline(x=boundary_x, color='green', linestyle='--', label='决策边界')
plt.xlabel('肿瘤大小')
plt.ylabel('类别 (0: 良性, 1: 恶性)')
plt.legend()
plt.show()
这段代码展示了逻辑回归如何找到一个分界点(绿色的虚线),将代表良性与恶性的两类数据点清晰地分开。
3.2.2 决策树与随机森林:集成思想的初步体现
如果说线性模型是用一个全局的、统一的函数来划分世界,那么决策树则是一种完全不同的、分而治之的哲学。
决策树:格物致知的典范
模型哲学 决策树的思考方式,与人类的决策过程如出一辙。它通过提出一系列“是/否”的问题,对数据进行层层划分,最终导向一个结论。
例如,判断一个瓜是不是好瓜,我们可能会问:“它的颜色是青绿吗?” -> “是的。” -> “它的根蒂是蜷缩的吗?” -> “是的。” -> “它的敲声是沉闷的吗?” -> “不是。” -> “结论:这是个坏瓜。” 这个过程,就是一棵决策树。
它的最大优点是模型具有极强的可解释性,我们可以清晰地看到每一个决策的依据。
构建过程:如何选择最佳问题 决策树构建的关键,是在每一步,如何选择一个“最佳”的问题(即特征)来划分当前的数据集,使得划分后的数据“纯度”最高。这里的“纯度”指的是数据的类别一致性。 我们使用**信息增益(Information Gain)或基尼不纯度(Gini Impurity)**来衡量一个问题的好坏。一个好的问题,应该能让划分后的子集,其不确定性(信息熵)或不纯度(基尼指数)大幅下降。决策树会贪心地选择那个能带来最大信息增益的特征进行分裂。
剪枝(Pruning) 如果任由决策树生长,它会为每一个训练样本都找到一条完美的路径,最终导致树变得异常“茂盛”和复杂。这样的树对训练数据拟合得很好,但对新数据的泛化能力会很差,这就是过拟合。 为了防止这种情况,我们需要对树进行剪枝。可以在树生长时就限制其深度或叶子节点数量(预剪枝),也可以等树完全长成后再砍掉一些不必要的枝叶(后剪枝)。
代码实战 使用Scikit-Learn构建决策树,并利用graphviz工具将其决策过程可视化。
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.datasets import load_iris
import graphviz
# 1. 加载鸢尾花数据集
iris = load_iris()
X, y = iris.data, iris.target
# 2. 创建并训练决策树模型
model = DecisionTreeClassifier(max_depth=3) # 限制最大深度以防过拟合
model.fit(X, y)
# 3. 将决策树可视化
dot_data = export_graphviz(model, out_file=None,
feature_names=iris.feature_names,
class_names=iris.target_names,
filled=True, rounded=True,
special_characters=True)
graph = graphviz.Source(dot_data)
# graph.render("iris_decision_tree") # 可以保存为文件
# 在Jupyter Notebook中,可以直接显示graph对象
# graph
运行上述代码(需安装graphviz库),读者将能得到一张清晰的决策树图,直观地看到模型是如何根据花瓣、花萼的长宽来判断鸢尾花品种的。
随机森林(Random Forest):三个臭皮匠,赛过诸葛亮
集成学习(Ensemble Learning)思想 单棵决策树,尤其是深度较大的决策树,容易过拟合,对数据的微小扰动很敏感。一个自然的想法是:我们能不能综合多棵不同决策树的意见来做决定?这就是集成学习的核心思想,俗称“群体智慧”。随机森林正是这种思想最杰出的代表。
“随机”体现在何处 为了让森林中的每一棵树都有所不同,从而形成互补,随机森林引入了两个“随机”机制:
- 数据随机(行抽样):森林中的每一棵树,都不是用全部的训练数据来训练的。而是通过自助采样法(Bootstrap Aggregating,简称Bagging),从原始数据集中有放回地抽取一个与原始数据集同样大小的子集。这样,每棵树看到的“世界”(训练数据)都是不完全一样的。
- 特征随机(列抽样):在构建每一棵树的每一个节点时,不再是从全部特征中选择最优分裂特征,而是随机抽取一部分特征,再从这部分特征中选择最优的。这进一步增加了树之间的差异性。
为何有效 这两个“随机”机制,极大地保证了森林中树的多样性(Diversity)。有些树可能在这个问题上犯错,但另一些树可能恰好是正确的。当森林进行预测时,它会采用“投票”的方式(分类问题)或“取平均”的方式(回归问题),综合所有树的意见。这种机制可以有效地降低整体模型的方差,使得随机森林具有非常好的抗过拟合能力和稳定性。
代码实战 我们使用Scikit-Learn的RandomForestClassifier,在同样的数据上比较它与单棵决策树的性能。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_score
# 仍然使用鸢尾花数据集
X, y = iris.data, iris.target
# 创建单棵决策树模型
tree_clf = DecisionTreeClassifier(random_state=42)
# 创建随机森林模型
forest_clf = RandomForestClassifier(n_estimators=100, random_state=42) # n_estimators是树的数量
# 使用交叉验证比较性能
tree_scores = cross_val_score(tree_clf, X, y, cv=5)
forest_scores = cross_val_score(forest_clf, X, y, cv=5)
print(f"单棵决策树的平均准确率: {tree_scores.mean():.4f}")
print(f"随机森林的平均准确率: {forest_scores.mean():.4f}")
通常情况下,读者会观察到随机森林的平均准确率会更稳定,也可能更高。
3.2.3 支持向量机(SVM):最大化间隔的艺术
支持向量机是一个功能强大且理论优美的分类算法。它的核心思想,不是简单地将数据分开,而是要以最“稳健”的方式分开。
核心思想:寻找最“宽”的街道
-
模型哲学 想象一下,在两种不同颜色的数据点之间,可以画出无数条线将它们分开。SVM认为,最好的那条分界线,应该是这样一条线:它位于两类数据点的正中间,并且离两边最近的数据点(我们称之为支持向量)的距离是最远的。 这条分界线就像一条街道,而街道两侧到最近的建筑(支持向量)之间的距离,就是街道的宽度,这个宽度在SVM中被称为间隔(Margin)。SVM的目标,就是最大化这个间隔。一条更宽的“街道”意味着模型对未知数据的容忍度更高,泛化能力更强。
-
线性SVM 在线性可分的情况下,SVM就是要找到由决策边界(街道中心线)、间隔和支持向量(街道两旁的建筑)构成的这个最优“街道系统”。一个有趣的特点是,最终的决策边界仅仅由这些少数的支持向量决定,与其他数据点无关。
核技巧(The Kernel Trick):乾坤大挪移
-
处理非线性问题 现实世界的数据往往不是线性可分的。比如,一类数据点被另一类数据点包围,无法用一条直线将它们分开。此时,SVM如何应对?
-
升维打击 SVM的精髓——核技巧登场了。它的思想,堪称“乾坤大挪移”。它通过一个称为核函数(Kernel Function)的数学变换,将数据从当前的低维特征空间,巧妙地映射到一个更高维的空间。神奇的是,在低维空间中线性不可分的数据,在映射到高维空间后,往往就变得线性可分了。
一个比喻:想象桌面上有一堆红色和蓝色的珠子混在一起,无法在桌面上画一条直线分开它们。现在您猛地一拍桌子,所有珠子都飞到了空中(升维)。在它们飞到最高点的那一瞬间,您用一个水平面(高维空间的“直线”)就能轻易地将红色和蓝色的珠子分开。
-
“核”的巧妙 更令人惊叹的是,SVM的核技巧无需真正地计算数据点在高维空间中的坐标,这在维度极高时(甚至是无限维)是无法做到的。它只需要通过核函数计算出数据点在低维空间中的内积,其结果就等价于它们在高维空间中的内积。这极大地降低了计算的复杂度,使得“升维打击”成为可能。常用的核函数有高斯核(RBF)、多项式核等。
代码实战 我们使用Scikit-Learn的SVC(Support Vector Classifier)来处理一个非线性可分的数据集。
from sklearn.svm import SVC
from sklearn.datasets import make_circles
# 1. 生成一个环形(非线性)数据集
X, y = make_circles(n_samples=100, noise=0.1, factor=0.5, random_state=42)
# 2. 创建并训练一个带RBF核的SVM模型
model = SVC(kernel='rbf', C=1.0, gamma='auto') # rbf是高斯核
model.fit(X, y)
# 3. 可视化决策边界 (此处代码较复杂,仅为示意,需要辅助函数)
# 核心是绘制出 model.predict() 结果的等高线图
# 在图中,读者会看到一条平滑的圆形边界,完美地分开了内外两圈数据点
# 并且可以看到,只有边界附近的点(支持向量)对决策边界有影响
通过这个例子,读者可以直观地感受到核技巧的威力,它如何毫不费力地解决了线性模型无法解决的问题。
3.3 模型的评估与优化:知其然,更要知其所以然
建立模型只是第一步。我们如何知道一个模型是好是坏?又如何诊断它存在的问题并加以改进?本节将介绍一套科学的评估与优化方法论。
3.3.1 模型的评估:明辨是非的标尺
选择合适的评估指标至关重要,它决定了我们优化模型的方向。
分类模型评估指标
-
混淆矩阵(Confusion Matrix) 它是所有分类指标的基石。对于一个二分类问题,混淆矩阵是一个2x2的表格,清晰地展示了模型预测的四种情况:
- 真正例 (TP): 真实为正,预测也为正。
- 假正例 (FP): 真实为负,预测却为正。(误报)
- 真负例 (TN): 真实为负,预测也为负。
- 假负例 (FN): 真实为正,预测却为负。(漏报)
-
准确率(Accuracy)
Accuracy = (TP + TN) / (TP + FP + TN + FN)这是最直观的指标,即“预测正确的样本数 / 总样本数”。但在样本不均衡(例如99%的邮件都是正常邮件)的情况下,它具有极大的误导性。一个无脑预测所有邮件都正常的模型,准确率也能达到99%。 -
精确率(Precision)与召回率(Recall)
- 精确率
Precision = TP / (TP + FP):在所有被模型预测为“正”的样本中,有多少是真正的正样本。它衡量的是模型的**“查准率”**,关心的是“别把坏人当好人”。 - 召回率
Recall = TP / (TP + FN):在所有真实为“正”的样本中,有多少被模型成功地找了出来。它衡量的是模型的**“查全率”**,关心的是“别放过任何一个坏人”。 精确率和召回率往往是一对矛盾的指标。在疾病诊断中,我们更关心高召回率(宁可误诊,不能漏诊);在垃圾邮件过滤中,我们更关心高精确率(宁可放过一些垃圾邮件,不能把重要邮件错判为垃圾)。
- 精确率
-
F1分数(F1-Score)
F1 = 2 * (Precision * Recall) / (Precision + Recall)它是精确率和召回率的调和平均数,是一个兼顾两者的综合性指标。
回归模型评估指标
-
均方误差(MSE)与均方根误差(RMSE)
MSE = (1/n) * Σ(y - ŷ)²RMSE = sqrt(MSE)它们衡量的是预测值与真实值之差的平方的均值。RMSE因为开了根号,其量纲与原始数据相同,更易于解释。它们对较大的误差(异常值)惩罚更重。 -
平均绝对误差(MAE)
MAE = (1/n) * Σ|y - ŷ|它衡量的是预测值与真实值之差的绝对值的均值。它对所有误差一视同仁,对异常值的鲁棒性比MSE/RMSE更好。
3.3.2 偏差与方差:执着于一与游移不定
这是理解模型行为、诊断问题的核心理论。
概念辨析 一个模型的泛化误差,可以分解为偏差、方差和噪声三部分。我们主要关注前两者。
- 偏差(Bias):描述的是模型的预测值的期望与真实值之间的差距。高偏差源于模型本身的“偏见”或“固执”,它无法捕捉到数据的真实规律。高偏差通常表现为欠拟合(Underfitting)。
- 方差(Variance):描述的是模型在不同训练集上进行训练时,其预测结果的波动性或不稳定性。高方差源于模型对训练数据中的噪声和细节过度“敏感”,把偶然当必然。高方差通常表现为过拟合(Overfitting)。
偏差-方差的权衡(Bias-Variance Tradeoff) 这是机器学习中一个永恒的核心矛盾。
- 一个简单的模型(如线性回归),对数据规律的假设很强,偏差较高,但对不同训练数据不敏感,方差较低。
- 一个复杂的模型(如高阶多项式回归或深度决策树),能拟合各种复杂规律,偏差较低,但极易学习到训练数据的噪声,导致在不同数据集上结果差异巨大,方差较高。 我们的目标,不是追求零偏差或零方差,而是在两者之间找到一个最佳的平衡点,使得总的泛化误差最小。
3.3.3 过拟合与欠拟合:学“废”了与没学会
这是偏差与方差在模型训练中的具体表现。
现象与诊断:
欠拟合(Underfitting):模型在训练集和测试集上表现都很差。
- 病因:模型太简单了(高偏差),连训练数据的基本规律都没学会。
- 诊断:观察到训练误差和测试误差都很高。
过拟合(Overfitting):模型在训练集上表现极好,但在未见过的测试集上表现很差。
- 病因:模型太复杂了(高方差),把训练数据中的噪声和偶然性也当成了普适规律来学习,失去了“泛化”到新数据的能力。
- 诊断:观察到训练误差很低,但测试误差远高于训练误差。
“诊断”方法:学习曲线 绘制学习曲线(Learning Curves)是一种有效的诊断方法。该曲线的横轴是训练样本的数量,纵轴是误差(或准确率)。通过观察训练误差曲线和验证误差曲线的走势和差距,可以清晰地判断出模型正处于欠拟合、过拟合还是理想状态。
3.3.4 交叉验证:更公平的“模拟考试”
为何需要 在模型开发中,我们通常会将数据划分为训练集和测试集。但这种一次性的划分具有很大的偶然性。可能我们碰巧分到了一份“简单”的测试集,导致模型得分虚高;也可能碰巧分到了一份“困难”的测试集,导致好模型被冤枉。
K折交叉验证(K-Fold Cross-Validation) 为了得到一个更稳健、更公平的模型评估结果,我们采用交叉验证。K折交叉验证是其中最常用的方法。
这种方法让所有数据都有机会成为验证集,大大降低了单次划分带来的偶然性,得出的评估结果更具说服力。
- 将全部训练数据随机分成 K 个大小相等的、互不相交的子集(称为“折”)。
- 进行 K 轮“模拟考试”:
- 在每一轮中,选择其中 1 个“折”作为验证集(测试模型),其余 K-1 个“折”合并起来作为训练集(训练模型)。
- 最终,我们得到 K 个验证集上的得分,将它们取平均值,作为模型的最终评估分数。
代码实战 Scikit-Learn中的cross_val_score函数让执行交叉验证变得异常简单,我们在之前的随机森林代码实战中已经演示了它的用法。它封装了整个K折划分和循环训练评估的过程,一行代码就能返回K次“模考”的成绩列表。
小结
至此,我们完成了对机器学习经典算法的回顾。从三大范式的高屋建瓴,到线性模型、决策树、随机森林、支持向量机等核心算法的深入剖析,再到一套科学的模型评估与优化方法论,读者应当已经建立起了坚实的机器学习基础。
这些经典模型,不仅是解决现实问题的有力工具,更是通往深度学习殿堂的必经之路。它们所蕴含的关于拟合、泛化、偏差、方差、集成等核心思想,将在后续的章节中反复出现并不断升华。带着这些宝贵的知识和直觉,现在,我们终于准备好,去迎接下一章——真正踏入神经网络的世界。
第二部分:核心篇 —— 深入神经网络的殿堂
第四章:神经网络基础
从仿生学到数学模型 —— 智能的计算之路
欢迎来到深度学习的核心腹地。在前面的章节中,我们回顾了经典的机器学习算法,它们如同能工巧匠,使用着设计精巧的工具。从本章开始,我们将学习如何构建一个能够自我学习、自我演化的“有机体”——神经网络。
这个宏大构想的最初火花,源于人类对自己智慧源泉——大脑——的探寻。科学家们渴望在冰冷的硅基芯片上,模拟出由亿万神经元构成的生物神经网络的惊人能力。这,便是神经网络仿生学的浪漫起点。然而,浪漫的灵感必须经过严谨的数学抽象和工程实践的淬炼,才能化为真正强大的计算模型。现代神经网络,早已超越了简单的模仿,发展成为一门博大精深的、以数学和计算机科学为基础的独立学科。
在本章的旅程中,我们将追随先驱的脚步,完成这次从仿生到建模的伟大跨越。我们将从构成智能的最基本单元“神经元”出发,观察它是如何从生物概念被抽象为数学函数。接着,我们将用它搭建出最简单的“感知机”网络,并直面其历史性的局限。然后,我们将见证“深度”的诞生——通过引入隐藏层构建多层感知机,看它如何突破瓶颈。我们还将巡礼赋予网络非线性力量的“激活函数”,并为网络装上评判是非的“损失函数”。最后,我们将揭开网络学习的终极奥秘——反向传播算法,看梯度下降与链式法则如何完美结合,驱动整个网络进行自我优化。
准备好了吗?让我们深入源头,探寻神经网络思想的最初灵感,揭开神经网络的神秘面纱,并最终亲手构建起通往人工智能的阶梯。
4.1 从生物神经元到人工神经元:模型的灵感来源
在计算机科学的殿堂里,很少有哪个领域像神经网络一样,其最初的构想与生命科学的联系如此紧密。为了创造智能,先驱们首先将目光投向了已知的、最高效的智能系统——人类大脑。
4.1.1 生物神经元(Biological Neuron):生命智能的基石
我们的大脑是由大约860亿个称为神经元的特殊细胞组成的复杂网络。这些神经元是信息处理的基本单位,它们协同工作,构成了我们的思想、记忆和感知。一个典型的生物神经元,其结构和工作方式可以被简化为以下几个关键部分:
核心结构
- 树突(Dendrites):它们像天线一样,是神经元的“输入端”。树突从成千上万个其他的上游神经元那里接收电化学信号。
- 细胞体(Soma):这是神经元的“处理中心”。它将所有从树突接收到的信号进行整合、累加。
- 轴突(Axon):这是一条长长的“输出线”。当细胞体整合后的信号强度达到某个临界点时,轴突会将一个标准的电信号传递给下游的其他神经元。
工作原理: “全或无”的激活模式 生物神经元的工作方式,遵循一种**“全或无”(All-or-None)的原则。细胞体持续地累加来自树突的输入信号。只有当这些信号的总和,在短时间内超过一个特定的激活阈值(Activation Threshold)**时,这个神经元才会被“激活”(或称“兴奋”、“放电”)。
一旦被激活,它就会通过轴突,向下游的神经元发送一个强度和波形都完全相同的标准电化学脉冲。如果信号总和没有达到阈值,神经元则保持静默,不产生任何输出。这种非0即1的开关特性,是生物智能进行信息编码和传递的基础。
4.1.2 人工神经元(Artificial Neuron):一次优雅的数学抽象
早期的人工智能研究者们,被生物神经元这种简洁而强大的工作模式所启发,试图用数学的语言来对其进行建模。这个模型,就是人工神经元,它构成了所有神经网络的最基本单元。
模型的建立
让我们看看,生物过程是如何被一步步翻译为数学语言的:
-
输入与权重 生物神经元通过树突接收来自多个上游神经元的信号。在人工神经元模型中,这被抽象为一组输入
x₁, x₂, ..., xₙ。每个输入,都与一个权重w₁, w₂, ..., wₙ相关联。这个权重wᵢ,模拟了生物神经元中突触连接的“强度”。一个大的正权重,意味着这个输入信号对神经元的激活有很强的“兴奋”作用;一个大的负权重,则代表有很强的“抑制”作用。 -
整合与偏置 生物神经元的细胞体负责整合所有输入信号。在数学模型中,这个过程被简化为对所有输入的加权求和:
z = (w₁x₁ + w₂x₂ + ... + wₙxₙ)。 此外,模型还引入了一个额外的参数,称为偏置(Bias)b。加权和会与这个偏置项相加:z = (Σwᵢxᵢ) + b。偏置项可以被看作是神经元固有的激活倾向。一个大的正偏置,意味着这个神经元本身就更容易被激活,即使输入信号不强。它在数学上确保了即使所有输入都为0,神经元也能产生输出,增加了模型的灵活性。 -
激活函数 生物神经元“全或无”的激活机制,被一个称为激活函数(Activation Function)
f()的数学函数所取代。这个函数接收整合后的信号z作为输入,并产生神经元的最终输出y。激活函数决定了神经元在接收到特定强度的信号后,应该做出何种程度的响应。
数学形式
综上所述,一个人工神经元的完整数学表达形式为:
y = f( (w₁x₁ + w₂x₂ + ... + wₙxₙ) + b )
使用我们在第二章学过的线性代数知识,这个公式可以被更简洁地写成向量形式:
y = f(wᵀx + b)
其中:
x是输入的特征向量。w是权重的参数向量。b是偏置标量。wᵀx是权重与输入的点积。f是激活函数。
这个简洁而优雅的数学模型,就是人工神经元的核心。它虽然是对复杂生物过程的极大简化,却抓住了“加权输入、整合、非线性激活”这一核心思想。它将作为我们构建所有复杂神经网络的“乐高积木”。
4.2 感知机(Perceptron):最简单的神经网络
有了人工神经元这个基本构建块,我们就可以搭建出史上第一个、也是最简单的神经网络模型——感知机。它由科学家弗兰克·罗森布拉特于1957年提出,是神经网络研究的开山之作。
4.2.1 单层感知机:线性分类的先行者
模型结构 一个单层感知机,其结构极其简单:它仅包含一个输入层和一个输出层。输出层通常只有一个我们刚刚定义的人工神经元。数据从输入层进入,经过这个神经元的处理后,直接得到最终的输出结果。
激活函数:阶跃函数 在最初的感知机模型中,为了最直接地模拟生物神经元“全或无”的特性,它使用的激活函数是一个简单的阶跃函数(Step Function),也称为Heaviside函数: f(z) = 1 如果 z ≥ 0 f(z) = 0 如果 z < 0 这意味着,如果加权和 wᵀx + b 大于或等于0,神经元就输出1(被激活);否则,就输出0(不激活)。这使得感知机非常适合执行二分类任务。
学习规则 感知机的学习算法同样非常直观。对于一个训练样本,在做出预测后:
通过在训练数据上反复迭代这个简单的更新规则,感知机能够自动地学习到一组可以正确划分数据的权重和偏置。
- 如果预测正确,权重
w和偏置b保持不变。 - 如果预测错误:
- 真实为1,预测为0:说明加权和太小了,需要增大。因此,将输入向量
x按一定比例(学习率η)加到权重向量w上(w = w + ηx),同时增大偏置b。 - 真实为0,预测为1:说明加权和太大了,需要减小。因此,从权重向量
w中减去输入向量x(w = w - ηx),同时减小偏置b。
- 真实为1,预测为0:说明加权和太小了,需要增大。因此,将输入向量
4.2.2 感知机的局限性:XOR问题的困境
感知机在当时引起了巨大的轰动,人们一度认为通往机器智能的道路已经敞开。然而,它的一个致命缺陷很快被揭示出来,这个发现直接导致了神经网络研究的第一次“寒冬”。
线性可分性 让我们回顾一下感知机的决策过程。它将数据分为两类的边界是 wᵀx + b = 0。在二维空间中,这是一个方程 w₁x₁ + w₂x₂ + b = 0,这正是一条直线的方程。在三维空间中,它是一个平面;在更高维的空间中,它是一个超平面。
这意味着,单层感知机本质上是一个线性分类器。它只能解决那些可以用一条直线(或一个超平面)就能将两类样本完美分开的问题。这类问题,我们称之为线性可分(Linearly Separable)问题。
XOR困境 问题在于,现实世界中许多问题都不是线性可分的。其中最著名、最简单的例子,就是异或(XOR)问题。 XOR逻辑关系如下:
当我们将这四个点绘制在二维平面上时,会发现:我们永远无法用一条直线,将代表输出0的两个点 (0,0), (1,1) 和代表输出1的两个点 (0,1), (1,0) 分开。
这个看似简单的XOR问题,成为了单层感知机无法逾越的鸿沟。1969年,马文·明斯基和西摩尔·派普特在他们的著作《感知机》中,系统地论证了这一局限性,并悲观地预测了神经网络研究的前景。这给当时热情高涨的AI社区泼了一盆冷水,导致该领域的研究经费被大量削减,进入了长达近二十年的停滞期。
- 输入
(0, 0)-> 输出0 - 输入
(0, 1)-> 输出1 - 输入
(1, 0)-> 输出1 - 输入
(1, 1)-> 输出0
然而,正如历史上的许多危机一样,XOR困境也孕育着突破的种子。如何打破线性分类的枷锁?答案,就在于增加网络的“深度”。
4.3 多层感知机(MLP):构建深度网络的第一步
让我们从那片曾经让神经网络研究陷入沉寂的“XOR困境”出发,见证它是如何被克服,并由此开启通往“深度”学习的康庄大道的。
单层感知机的失败,并非宣告了神经网络思想的终结,而是激发了研究者们更深层次的思考。既然单层网络的能力有限,我们能否通过堆叠更多的层次来构建一个更强大的模型呢?答案是肯定的,这便引出了多层感知机(Multi-Layer Perceptron, MLP)。
4.3.1 突破局限:引入隐藏层
MLP的结构 多层感知机的结构,相较于单层感知机,其关键的、革命性的变化在于:在输入层(Input Layer)和输出层(Output Layer)之间,加入了一个或多个隐藏层(Hidden Layers)。
- 输入层:负责接收原始数据,其节点数等于特征的数量。它不进行计算,仅作为数据入口。
- 隐藏层:位于输入层和输出层之间,是MLP的核心。每个隐藏层都由若干个人工神经元组成。它们不直接与外界交互(既不接收原始输入,也不产生最终输出),其存在对用户来说是“隐藏”的,故得此名。
- 输出层:负责产生模型的最终预测结果。其节点数取决于任务类型(回归任务通常为1个,多分类任务通常为类别数)。
“深度”的诞生 一个网络中隐藏层的数量,决定了它的“深度”。拥有一个或多个隐藏层的神经网络,才开始具备了“深度”的含义,是**深度学习(Deep Learning)**这个术语的由来。虽然一个仅含单个隐藏层的MLP通常被称为“浅层”网络,但它已经播下了通往“深度”的种子。
4.3.2 隐藏层的作用:特征的组合与变换
隐藏层究竟施展了怎样的“魔法”,从而克服了单层感知机的局限呢?其核心在于特征的非线性组合与层次化学习。
解决XOR问题 让我们回到XOR困境。一个单层感知机只能画出一条直线,无法解决这个问题。但一个带有一个隐藏层(例如,包含两个神经元)的MLP却可以轻松应对。
一个直观的图解思路:
- 隐藏层的第一个神经元:它可以学习到一条决策边界(比如一条斜线),将点
(1,1)与其他三个点分开。- 隐藏层的第二个神经元:它可以学习到另一条决策边界(比如另一条斜线),将点
(0,0)与其他三个点分开。- 输出层的神经元:它不再直接处理原始的输入
(x₁, x₂),而是处理来自两个隐藏层神经元的输出。它可以学习到一个简单的逻辑:当且仅当第一个隐藏神经元和第二个隐藏神经元都不被激活时,才最终输出1。通过这种方式,MLP不再是画一条直线,而是通过隐藏层学习到了两个不同的线性边界,再由输出层对这两个边界的结果进行组合,从而构造出了一个能够完美包围住
(0,1)和(1,0)的非线性决策区域。单层感知机的线性枷锁,就此被打破。
特征的层次化学习 解决XOR问题只是牛刀小试。隐藏层更深刻的意义在于,它开启了特征的层次化学习(Hierarchical Feature Learning)。
- 第一层隐藏层:直接与原始输入数据相连。它可以学习到一些初级的、简单的特征。例如,在图像识别任务中,第一层可能学会识别边缘、角点、颜色块等基本模式。
- 更深的隐藏层:它们不再看原始数据,而是以上一层隐藏层的输出(即初级特征)作为输入。因此,它们可以在这些初级特征的基础上,学习到更复杂、更抽象的组合特征。例如,第二层可能学会将边缘和角点组合成眼睛、鼻子、耳朵等部件。
- 更深……:第三层可能将眼睛、鼻子等部件组合成一张人脸的轮廓。
这正呼应了我们在第二章中提到的“空间变换”的概念。MLP的每一层,都在对前一层所处的特征空间进行一次复杂的非线性变换,目的是将数据逐步映射到一个新的空间,在这个空间里,不同类别的数据能够被更容易地区分开来。这种自动学习有效特征表示的能力,是深度学习相比传统机器学习最核心的优势之一。
4.4 激活函数:赋予网络非线性
在MLP的讨论中,我们提到了“非线性”这个关键词。赋予网络这种至关重要的非线性能力的组件,正是激活函数。
4.4.1 为何需要非线性?
线性叠加的瓶颈 假设我们构建一个多层网络,但不使用任何激活函数(或者说,使用一个线性的激活函数 f(x)=x)。那么,第一层的输出是 W₁x + b₁。第二层的输出将是 W₂(W₁x + b₁) + b₂ = (W₂W₁)x + (W₂b₁ + b₂)。 无论我们堆叠多少层,最终的结果 (W_n...W₂W₁)x + ... 始终可以被化简为一个等效的单层线性变换 W'x + b'。这意味着,如果没有非线性激活函数,一个深度神经网络的表达能力将被退化为一个单层的线性网络,从而完全失去了“深度”的意义,也无法解决像XOR这样的非线性问题。
表达能力的源泉 非线性激活函数是网络能够拟合任意复杂函数的关键。它在每一层线性变换(wᵀx + b)之后,对特征空间进行一次“弯曲”或“折叠”。正是这些连续的、非线性的扭曲操作,使得神经网络有能力去逼近(fit)数据中任何复杂的、非线性的潜在规律。根据通用近似定理(Universal Approximation Theorem),一个带有一个隐藏层和非线性激活函数的MLP,只要隐藏层神经元数量足够多,理论上就可以以任意精度近似任何连续函数。
4.4.2 常用激活函数巡礼
选择合适的激活函数,对网络的训练速度和性能至关重要。以下是几位在神经网络发展史中扮演了重要角色的激活函数。
Sigmoid函数:经典的S形曲线
- 函数:
σ(x) = 1 / (1 + e⁻ˣ) - 特性:将任意实数输入平滑地压缩到
(0, 1)区间。这使得它的输出可以被解释为概率,在早期被广泛应用于二分类问题的输出层。 - 缺点:
- 梯度消失(Vanishing Gradients):当输入值非常大或非常小时,Sigmoid函数的曲线变得非常平坦,其导数(梯度)接近于0。在深层网络中,这些接近0的梯度在反向传播时会层层相乘,导致传到浅层网络的梯度信号变得极其微弱,使得浅层网络的参数几乎无法更新。
- 输出非零中心:其输出恒为正,这会导致后续层的输入都是非零中心的,可能降低梯度下降的收敛效率。
Tanh函数(双曲正切):零中心化的S形曲线
- 函数:
tanh(x) = (eˣ - e⁻ˣ) / (eˣ + e⁻ˣ) - 特性:将输入压缩到
(-1, 1)区间。其输出是零中心的,这在实践中通常比Sigmoid函数有更好的性能,收敛速度更快。 - 缺点:它同样是一条S形曲线,因此也无法避免在饱和区的梯度消失问题。
ReLU (Rectified Linear Unit):现代网络的默认选择
- 函数:
ReLU(x) = max(0, x) - 特性:这是一个极其简单的分段线性函数。当输入为正时,输出等于输入;当输入为负时,输出为0。
- 优点:
- 缓解梯度消失:在正数区间,其导数恒为1,这极大地缓解了梯度消失问题,使得深层网络可以得到有效的训练。
- 计算高效:相比Sigmoid和Tanh涉及的指数运算,ReLU的计算成本极低。
- 稀疏性:它会使一部分神经元的输出为0,这造成了网络的稀疏性,可能有助于提取更有意义的特征。
- 缺点:
- Dying ReLU(死亡ReLU)问题:如果一个神经元的输入在训练过程中始终为负,那么它的输出将永远是0,梯度也永远是0。这个神经元将不再对任何数据有响应,也无法再进行学习,如同“死亡”了一般。
ReLU的变体:应对“死亡”问题 为了解决Dying ReLU问题,研究者们提出了一些改进版本:
- Leaky ReLU:
f(x) = x如果x > 0,f(x) = αx如果x ≤ 0。它为负区间引入一个微小的、固定的正斜率α(如0.01),确保神经元在负输入时也能有非零梯度。 - ELU (Exponential Linear Unit):在负区间,它是一条平滑的指数曲线,而不是直线。理论上它结合了ReLU和Leaky ReLU的优点,对噪声更具鲁棒性,但计算成本稍高。
4.5 损失函数:衡量“理想”与“现实”的差距
我们已经构建了网络的结构,并为其注入了非线性的活力。但我们如何告诉网络它的表现是好是坏呢?这就需要损失函数(Loss Function)。
4.5.1 损失函数(Loss Function)的角色
优化的“导航员” 损失函数(有时也称成本函数或目标函数)是一个用于量化模型预测值 Ŷ 与真实标签 Y 之间差距的函数。这个差距值,我们称之为损失(Loss)。 损失值就是一个标量,它代表了模型在当前训练样本上“犯错”的程度。损失越大,说明模型错得越离谱。
目标 整个神经网络的训练过程,其唯一的目标,就是通过不断调整网络内部的权重和偏置参数,来使得在整个训练数据集上的总损失函数的值尽可能小。损失函数为我们的优化过程(如梯度下降)提供了明确的、可量化的目标和方向。
4.5.2 常见的损失函数
损失函数的选择,取决于我们所面对的任务类型。
均方误差(MSE, Mean Squared Error)
适用场景:主要用于回归任务,即预测一个连续值(如房价、温度)。
数学形式:L(Y, Ŷ) = (1/n) * Σ(Yᵢ - Ŷᵢ)² 它计算的是预测值与真实值之差的平方的平均值。
交叉熵损失(Cross-Entropy Loss)
适用场景:是分类任务的标准损失函数。
二元交叉熵(Binary Cross-Entropy):用于二分类问题(如判断邮件是否为垃圾邮件)。它通常与输出层的单个Sigmoid激活函数配合使用。
分类交叉熵(Categorical Cross-Entropy):用于多分类问题(如识别图片是猫、狗还是鸟)。它通常与输出层的Softmax激活函数配合使用。Softmax函数能将一组任意实数转换为一个概率分布(所有输出值在(0,1)之间且总和为1)。
为何优于MSE:在分类任务中,如果使用MSE,当模型的预测概率远离真实标签(如真实为1,预测为0.001)时,其梯度可能会变得很小,导致学习非常缓慢。而交叉熵损失在这种情况下能提供一个非常大的梯度信号,从而促使模型更快地修正错误。
4.6 反向传播算法:网络学习的引擎
我们有了网络结构、激活函数和损失函数。现在,最关键的问题来了:我们究竟该如何系统性地调整那成千上万个参数,来最小化损失呢?答案就是大名鼎鼎的反向传播(Backpropagation)算法。
4.6.1 算法的宏观理解
目标 反向传播算法的唯一目标,就是高效地计算出损失函数 L 关于网络中所有参数(每一个权重 w 和偏置 b)的梯度(偏导数)。
两个阶段 一次完整的训练迭代,包含两个阶段:
- 前向传播(Forward Pass):将一个或一批训练数据输入网络。数据从输入层开始,逐层流过网络,经过每一层的线性变换和非线性激活,直到输出层产生最终的预测值
Ŷ。然后,用损失函数计算出Ŷ和真实标签Y之间的损失值L。 - 反向传播(Backward Pass):这是算法的精髓。它从最终的损失
L出发,“反向”地、逐层地穿越网络。在每一层,它都利用我们在第二章学过的链式法则,来计算损失L对当前层参数的梯度,并将误差信号继续向后传递。
4.6.2 梯度下降与链式法则的完美结合
梯度下降的应用 一旦反向传播完成了它的使命,为我们提供了所有参数的梯度,梯度下降(或其更高级的变体,如Adam、RMSprop,我们将在后续章节详述)就会接管工作。它根据以下公式来更新每一个参数: 新参数 = 旧参数 - 学习率 * 梯度 这个简单的更新步骤,会使参数向着能减小损失的方向移动一小步。
算法的直观感受 我们可以将一次完整的前向+反向传播过程,比作一次高效的“责任分配”大会:
- 前向传播是“业绩汇报”:模型根据现有能力(参数),对输入数据做出预测,并计算出与目标(真实标签)之间的“业绩差额”(Loss)。
- 反向传播是“责任追溯”:从这个“总差额”开始,算法像一位明察秋毫的审计官,利用链式法则,将总责任精准地、按贡献度地层层分解,最终落实到每一个基层员工(参数)头上,明确地告诉它:“您对这次的错误负有xx程度的责任,您应该朝着xx方向改正。”
通过在整个数据集上成千上万次地重复这个“汇报-追责-改正”的循环,神经网络这个庞大的组织,就能够从一个随机的、无序的状态,逐步演化为一个分工明确、配合默契、能够高效完成特定任务的智能系统。
小结
在本章中,我们完成了从零到一的构建。从生物神经元的灵感闪现,到人工神经元的数学抽象;从单层感知机的线性局限,到多层感知机通过引入隐藏层和非线性激活函数所实现的突破;我们还为网络装配了衡量对错的“损失函数”,并最终揭示了驱动其学习的引擎——反向传播算法。
读者现在应该对一个基本的神经网络是如何构成、如何工作、以及如何学习的,有了一个清晰而完整的认识。这些基础概念,是理解后续所有更高级、更复杂的网络结构(如卷积神经网络CNN、循环神经网络RNN)的绝对基石。带着这份坚实的基础,我们即将在下一章,真正踏入使用现代深度学习框架进行实战的激动人心的旅程。
第五章:深度学习框架入门与实战
从理论到代码 —— 巨人的力量
在前面的章节中,我们已经深入探索了神经网络的理论基石。我们理解了神经元的数学模型,见证了“深度”如何赋予网络强大的表达能力,也揭示了反向传播算法驱动模型学习的奥秘。然而,如果将这些理论从零开始,用纯粹的Python和NumPy来实现一个复杂的现代神经网络,那将是一项极其繁琐、易错且效率低下的工程。我们将不得不手动管理成千上万的参数,亲手编写复杂的梯度计算链条,并费尽心力去调用底层硬件进行加速。
幸运的是,我们不必重复造轮。我们站在巨人的肩膀上,这些巨人,就是深度学习框架。
一个现代的深度学习框架,如同一个专为神经网络打造的强大“操作系统”。它为我们封装了所有繁杂的底层细节:从高效的张量运算,到神奇的自动求导机制,再到对GPU/TPU等专用硬件的无缝利用。它将我们从纷繁的工程细节中解放出来,让我们能够将宝贵的精力专注于模型架构本身的设计、实验与创新。
在当今的深度学习世界,群雄并起,但真正的舞台主角,无疑是两大巨头:由Google支持的TensorFlow和由Facebook(Meta)主导的PyTorch。它们如同武林中的少林与武当,各自代表了一种独特的气质与哲学:TensorFlow以其无与伦比的生态系统、工业级的部署能力和稳健性著称,是业界应用的首选;而PyTorch则以其灵动、优雅、与Python深度融合的设计,赢得了广大学术研究者和算法工程师的青睐。
精通其中之一,足以让您在深度学习领域游刃有余;而两者皆通,则能让您洞察不同设计哲学下的利弊权衡,根据不同场景选择最合适的工具。
本章的目标,正是要带领读者跨越从理论到代码的鸿沟。我们将并肩探索TensorFlow 2.x与PyTorch的核心设计与使用方法,通过亲手编写代码,完成从数据准备、模型搭建、训练到评估的完整流程。最后,我们还将提供一份详尽的环境搭建指南,帮助您打造一个属于自己的、高效稳定的深度学习“炼丹炉”。
准备好将理论化为指尖的力量了吗?让我们即刻启程。
5.1 TensorFlow 2.x 与 Keras:Google的工业级解决方案
TensorFlow是深度学习领域无可争议的重量级选手。它不仅仅是一个库,更是一个庞大的生态系统,涵盖了从研究原型到生产部署,再到移动端和物联网设备的全链路解决方案。
5.1.1 框架的演进与哲学
从TensorFlow 1.x到2.x:一场深刻的变革 早期的TensorFlow 1.x采用的是一种称为**“静态图”(Define-and-Run)**的模式。开发者需要先像绘制电路图一样,完整地定义出整个计算图的结构,然后再向这个固定的图中“注入”数据来执行计算。这种模式虽然有利于进行全局优化和跨平台部署,但其编写和调试过程却相当繁琐和反直觉,令许多初学者望而却步。
认识到这一点后,Google在TensorFlow 2.x中进行了一场深刻的自我革命,其核心是拥抱了“动态图”(Define-by-Run)作为默认执行模式。这意味着代码会像普通的Python程序一样,按顺序立即执行,计算图在运行时动态构建。这使得调试变得异常简单,代码也更加直观。更重要的是,TF 2.x做出了一个明智的决定:将Keras提升为官方唯一指定的高级API。
Keras:为人类而非机器设计的API Keras是由François Chollet创建的一个深度学习库,其核心设计哲学是**“易用性优先”**。它追求以最少的代码、最清晰的逻辑来构建神经网络,让开发者能够快速地将想法转化为实验结果。Keras的API简洁、高度模块化且易于扩展,如同深度学习领域的“乐高积木”。在TF 2.x中,Keras不再是一个独立的库,而是深度整合为tf.keras,成为了与TensorFlow交互的首选方式。
5.1.2 TensorFlow核心概念:深入引擎室
尽管Keras为我们隐藏了许多底层细节,但理解其背后的核心组件,能让我们在使用时更加得心应手。
张量(tf.Tensor):不可变的基石 正如我们在第二章所学,张量是深度学习的基本数据单元。在TensorFlow中,tf.Tensor对象是承载数据的核心。它与NumPy的ndarray非常相似,可以存储标量、向量、矩阵等。一个关键特性是,tf.Tensor是不可变的(immutable)。一旦创建,您无法改变它的值,只能通过运算创建新的张量。
import tensorflow as tf
# 创建一个常量张量
a = tf.constant([[1.0, 2.0], [3.0, 4.0]])
print(a)
# 张量运算会创建新的张量
b = a + 10
print(b)
# 与NumPy的无缝转换
numpy_array = b.numpy()
print(type(numpy_array))
变量(tf.Variable):可变的模型参数 既然张量是不可变的,那我们如何存储和更新需要在训练中不断变化的**模型参数(权重和偏置)**呢?答案是使用tf.Variable。它是一个特殊的、可变的张量,专门用于存储模型状态。
# 创建一个变量
v = tf.Variable([[1.0, 2.0], [3.0, 4.0]])
print(f"Is Variable: {tf.is_tensor(v)}") # Variable也是一种Tensor
# 可以使用 .assign() 方法就地修改值
v.assign(v + 10)
print(v)
自动求导(tf.GradientTape):反向传播的魔术师 tf.GradientTape是TensorFlow 2.x实现自动求导的核心工具。它的工作原理可以用一个生动的比喻来理解:
磁带录音机比喻: 当您创建一个
tf.GradientTape的上下文环境时,就好比按下了一台老式磁带录音机的“录制”按钮。在此环境中发生的所有涉及tf.Variable或被监视的tf.Tensor的运算,都会被这台“录音机”记录在一条虚拟的“磁带”上。当您完成了前向传播的计算(比如算出了损失),就可以调用磁带的
.gradient()方法。这好比按下了“倒带”并“播放”,TensorFlow会沿着记录的路径反向追溯,并利用链式法则自动计算出您指定的目标(如损失)关于所有被记录的变量的梯度。
# 演示计算 y = x² 在 x=3 时的梯度
x = tf.Variable(3.0)
with tf.GradientTape() as tape:
y = x ** 2
# 计算梯度 dy/dx
grad = tape.gradient(y, x)
print(grad) # 输出 tf.Tensor(6.0, shape=(), dtype=float32)
5.1.3 Keras实战:三步完成模型搭建
掌握了Keras,构建一个神经网络就像搭积木一样简单,通常遵循“定义-编译-训练”三部曲。
序贯模型(Sequential API):快速搭建线性堆叠 Sequential模型是最简单、最常用的模型类型,适用于绝大多数层与层之间呈线性顺序堆叠的网络。
代码实战:构建一个简单的MLP用于分类
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# 1. 定义模型:像搭积木一样添加层
model = keras.Sequential([
# 输入层:将28x28的图片展平为784维的向量
layers.Flatten(input_shape=(28, 28)),
# 第一个隐藏层:128个神经元,使用ReLU激活函数
layers.Dense(128, activation='relu'),
# 第二个隐藏层:64个神经元,使用ReLU激活函数
layers.Dense(64, activation='relu'),
# 输出层:10个神经元(对应10个类别),使用Softmax输出概率
layers.Dense(10, activation='softmax')
])
# 打印模型结构
model.summary()
# 2. 编译模型:配置优化器、损失函数和评估指标
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
# 假设我们有准备好的训练数据 (x_train, y_train) 和测试数据 (x_test, y_test)
# (x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# x_train, x_test = x_train / 255.0, x_test / 255.0 # 归一化
# 3. 训练模型:将数据“喂”给模型
# history = model.fit(x_train, y_train, epochs=5, batch_size=32, validation_split=0.2)
# 评估模型
# test_loss, test_acc = model.evaluate(x_test, y_test)
# print(f'\nTest accuracy: {test_acc}')
函数式API(Functional API):构建复杂的非线性网络 当模型结构变得复杂,例如需要处理多输入、多输出,或者网络中存在共享层、残差连接等非线性拓扑结构时,Sequential模型便无能为力。这时,更灵活的函数式API就派上了用场。它将网络层视为可以调用的函数,允许您构建任意的有向无环图。
代码实战:构建一个简单的多输入模型 假设我们有一个模型,同时接收一个主输入和一个辅助输入。
# 定义输入层
main_input = keras.Input(shape=(100,), name='main_input')
aux_input = keras.Input(shape=(10,), name='aux_input')
# 主流程
x = layers.Dense(64, activation='relu')(main_input)
x = layers.Dense(32, activation='relu')(x)
# 辅助输入与主流程合并
merged = layers.concatenate([x, aux_input])
# 定义输出层
main_output = layers.Dense(1, name='main_output')(merged)
aux_output = layers.Dense(1, name='aux_output')(x) # 辅助输出
# 使用输入和输出张量列表来实例化模型
complex_model = keras.Model(inputs=[main_input, aux_input],
outputs=[main_output, aux_output])
complex_model.summary()
5.2 PyTorch:Facebook的动态图与研究者首选
如果说TensorFlow是严谨的工程师,那么PyTorch就是一位灵动的艺术家。它以其优雅和对Python语言的深度融合,成为了学术界和快速原型开发领域的宠儿。
5.2.1 框架的哲学与气质
-
Pythonic的设计 PyTorch的设计哲学是“尽可能地像Python”。它的API和用法非常符合Python程序员的直觉。在PyTorch中,您可以像调试普通Python代码一样,使用
print()或任何调试工具来检查任意中间变量,这得益于其动态图的本质。 -
动态图的灵活性 PyTorch从诞生之初就采用动态计算图(Define-by-Run)。计算图是在代码运行时,随着运算的发生而动态建立的。这意味着您可以使用Python所有原生的控制流语句(如
if-else、for循环)来自由地改变网络的行为。这种灵活性对于处理变长输入的自然语言处理(NLP)任务,或进行复杂的算法研究至关重要。
5.2.2 PyTorch核心概念:三大支柱
-
张量(
torch.Tensor):数据与梯度的载体torch.Tensor是PyTorch的核心数据结构,与NumPy的ndarray极为相似,并且两者可以高效、无缝地共享底层内存进行转换(在CPU上),避免了数据拷贝的开销。 -
自动求导(
torch.autograd):动态图的引擎autograd是PyTorch的自动求导引擎。它的工作方式与GradientTape类似,但集成得更加无缝:requires_grad属性:当您创建一个张量时,可以设置requires_grad=True。这会告诉PyTorch,需要追踪所有发生在该张量上的操作。.backward()方法:在一个标量(通常是计算出的loss)上调用.backward()方法,PyTorch会自动计算所有requires_grad=True的张量相对于该标量的梯度。.grad属性:计算出的梯度会累积到对应张量的.grad属性中。
-
神经网络模块(
torch.nn):模型组件的蓝图torch.nn是PyTorch中用于构建神经网络的核心模块。nn.Module:所有神经网络层(如nn.Linear,nn.Conv2d)和模型容器的基类。构建自定义模型时,您需要创建一个继承自nn.Module的类。在__init__方法中定义好所有需要的层,然后在forward方法中,明确地定义数据是如何从输入流向输出的(即前向传播的逻辑)。
5.2.3 PyTorch实战:标准的五步训练流程
PyTorch不像Keras那样提供一个高度封装的.fit()方法。它鼓励(或者说,要求)用户自己编写训练循环。这虽然代码量稍多,但赋予了用户对训练过程每一个细节的完全控制力。
代码实战:从零构建MLP训练流程
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
# 1. 准备数据 (假设我们有Numpy数组 x_train_np, y_train_np)
# x_train_tensor = torch.from_numpy(x_train_np).float()
# y_train_tensor = torch.from_numpy(y_train_np).long()
# train_dataset = TensorDataset(x_train_tensor, y_train_tensor)
# train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True)
# 2. 定义模型:创建一个继承自 nn.Module 的类
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.flatten = nn.Flatten()
self.layers = nn.Sequential(
nn.Linear(28*28, 128),
nn.ReLU(),
nn.Linear(128, 64),
nn.ReLU(),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.flatten(x)
logits = self.layers(x)
return logits
device = "cuda" if torch.cuda.is_available() else "cpu"
model = MLP().to(device)
print(model)
# 3. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # CrossEntropyLoss内部已包含Softmax
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 4. 编写训练循环
num_epochs = 5
# for epoch in range(num_epochs):
# model.train() # 设置为训练模式
# for inputs, labels in train_loader:
# inputs, labels = inputs.to(device), labels.to(device)
#
# # a. 清空梯度
# optimizer.zero_grad()
#
# # b. 前向传播
# outputs = model(inputs)
#
# # c. 计算损失
# loss = criterion(outputs, labels)
#
# # d. 反向传播
# loss.backward()
#
# # e. 更新权重
# optimizer.step()
#
# print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item():.4f}')
# 5. 编写评估逻辑
# model.eval() # 设置为评估模式
# with torch.no_grad(): # 在此上下文中,不计算梯度,节省内存和计算
# correct = 0
# total = 0
# for inputs, labels in test_loader:
# inputs, labels = inputs.to(device), labels.to(device)
# outputs = model(inputs)
# _, predicted = torch.max(outputs.data, 1)
# total += labels.size(0)
# correct += (predicted == labels).sum().item()
# print(f'Accuracy on test set: {100 * correct / total} %')
5.3 环境搭建:打造自己的“炼丹炉”
工欲善其事,必先利其器。一个稳定、隔离、可复现的开发环境,是高效进行深度学习研究与实践的基石。
5.3.1 包与环境管理:Conda的艺术
为何需要环境管理 在软件开发中,我们经常会遇到“依赖地狱”:项目A需要库X的1.0版本,而项目B需要库X的2.0版本。如果在全局环境中安装,这两个项目将无法同时工作。虚拟环境就是解决这个问题的良方。它为每个项目创建一个独立的、隔离的Python环境,您可以在其中安装任意版本的库,而不会影响到其他项目。
Conda核心命令 Conda是目前最流行、最强大的Python环境和包管理器之一。
- 创建新环境:
conda create --name my_dl_env python=3.9 - 激活环境:
conda activate my_dl_env - 安装包:
conda install numpy pandas matplotlib或pip install tensorflow - 查看已安装的包:
conda list - 退出环境:
conda deactivate
5.3.2 交互式编程环境:Jupyter Notebook/Lab
-
Jupyter的优势 Jupyter Notebook/Lab是一个基于Web的交互式计算环境。它允许您创建和共享包含实时代码、公式、可视化和叙述性文本的文档。这种“文学式编程”的风格,使其成为数据科学探索、快速原型验证和教学演示的理想工具。
-
安装与启动 在激活了您的Conda环境后,通过以下命令安装:
conda install -c conda-forge jupyterlab然后,在您的项目文件夹下,通过命令行启动:jupyter lab
5.3.3 GPU加速配置指南:为模型插上翅膀
CPU vs. GPU CPU(中央处理器)和GPU(图形处理器)的设计目标不同。
- CPU:像一位博学的教授,拥有少数几个强大而复杂的计算核心,擅长处理逻辑复杂、需要按顺序执行的任务。
- GPU:像一个小学生军团,拥有成百上千个简单但高效的计算核心。它不擅长复杂逻辑,但极其擅长执行大规模、可并行的简单计算任务。 神经网络中的核心运算——大规模的矩阵乘法和加法——正是GPU的用武之地。使用GPU进行训练,通常能比使用CPU带来数十倍甚至上百倍的速度提升。
NVIDIA驱动与CUDA 要使用GPU进行深度学习,需要一块NVIDIA显卡,并正确安装两样东西:
- NVIDIA驱动:确保显卡驱动程序更新到最新版本,可以从NVIDIA官网下载。
- CUDA Toolkit:CUDA是NVIDIA推出的并行计算平台和编程模型。深度学习框架通过CUDA来调用GPU的计算能力。需要根据所使用的TensorFlow或PyTorch版本的要求,从NVIDIA官网下载并安装对应版本的CUDA Toolkit。
验证安装 安装完框架后,可以用以下代码片段来验证GPU是否被成功识别:
- TensorFlow:
import tensorflow as tf print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU'))) - PyTorch:
import torch print(f"Is CUDA available: {torch.cuda.is_available()}") if torch.cuda.is_available(): print(f"Device name: {torch.cuda.get_device_name(0)}")
小结
在本章中,我们完成了从理论到实践的关键一跃。我们深入探索了当今最主流的两大深度学习框架——TensorFlow与PyTorch。我们不仅学习了它们高级API的便捷用法,更理解了其背后关于张量、自动求导和模型封装的核心设计哲学。通过并排比较Keras的“三部曲”和PyTorch的“五步法”,读者应能体会到两种框架在易用性与灵活性之间的不同取舍。
最后,我们详细介绍了如何使用Conda、Jupyter和NVIDIA工具链,来搭建一个专业、高效的深度学习开发环境。这套“炼丹炉”将是您未来探索更广阔深度学习世界的坚实基础。
手握神兵,炉火已旺。现在,您已经具备了将任何神经网络模型付诸实践的能力。从下一章开始,我们将运用这些工具,去探索深度学习领域中那些更专门、更强大的模型架构。
第六章:深度学习的“炼丹术” —— 训练与优化
从“能跑”到“跑得好”的艺术
在上一章中,我们已经掌握了使用现代框架构建神经网络并使其运行起来的“神兵利器”。然而,让模型“能跑”仅仅是万里长征的第一步。一个未经精心调校的神经网络,往往表现平平,甚至无法收敛。从“能跑”到“跑得好”,这中间的鸿沟,需要一门精深的技艺来跨越——我们称之为深度学习的“炼丹术”。
将模型训练比作一场古代方士的炼丹,并非故弄玄虚。因为这个过程充满了科学的严谨与艺术的直觉。我们需要面对两大核心挑战:
- 优化(Optimization):我们的损失函数,是一个坐落在亿万维度参数空间中的、极其崎岖复杂的“山脉”。如何找到一条最高效、最稳健的路径,从随机的起点出发,顺利抵达山脉的最低谷(全局最优解或一个足够好的局部最优解)?这便是优化的艺术。
- 泛化(Generalization):即便我们在训练这座“山脉”上找到了最低点,又如何保证我们找到的不是一个只适用于这座山的“投机取巧”的捷径,而是一条能够适用于世界上所有类似山脉的“普适法则”?换言之,如何让模型在未曾见过的“测试数据”上依然表现出色?这便是泛化的智慧。
本章的使命,就是为读者系统地传授应对这两大挑战的一系列关键技术与策略。我们将一同探索各种先进的优化器,它们如同性能各异的“交通工具”,帮助我们在损失函数的复杂地形中高效穿行。我们将学习多种正则化技术,它们是防止模型“走火入魔”、陷入“过拟合”的强大“戒律”。我们还会揭示批归一化、超参数调优和权重初始化等一系列“秘法”,它们能极大地加速训练进程,并提升模型的最终性能。
掌握了这些“炼丹术”,读者将不再是一个只会按部就班的“学徒”,而将成长为一位能够洞悉训练动态、诊断模型问题、并对症下药的“炼丹大师”。现在,让我们从选择下山的交通工具开始,踏上这段充满挑战与智慧的旅程。
6.1 优化器详解:寻找最优解的“交通工具”
优化器是深度学习训练过程的心脏。它的职责,是根据反向传播计算出的梯度信息,来指导模型参数如何更新,以期最小化损失函数。选择不同的优化器,就如同在探索损失函数这片广袤而崎岖的“山脉”时,选择了不同的交通工具。
6.1.1 梯度下降的挑战:在崎岖山路中前行
损失函数的“地形” 我们需要在脑海中建立一幅画面:一个深度神经网络的损失函数,其“地形”远比我们想象的要复杂。它不是一个平滑的碗,而是一个坐落在极高维度空间中的、崎岖无比的山脉。这片山脉中,遍布着狭长而陡峭的峡谷,梯度在峡谷两侧方向剧烈变化,但在峡谷延伸方向上却很平缓;还存在着鞍点(Saddle Points),它在某个维度上是最小值,但在另一维度上却是最大值,梯度在此处为零,极易困住优化器;此外,还有无数的局部最小值(Local Minima)。
朴素梯度下降(SGD)的困境 我们最基础的优化算法——随机梯度下降(SGD),其策略非常朴素:只看脚下,哪边最陡就往哪边走一步。这种策略在复杂地形中会遇到诸多麻烦:
- 振荡:在狭长的峡谷中,SGD会在峡谷两侧的峭壁间来回振荡,导致收敛速度极慢。
- 被困:在鞍点或平缓的局部最小值区域,梯度变得非常小甚至为零,SGD会认为已经到达了谷底,从而过早地停止更新。
为了克服这些困境,一系列更智能、更强大的优化器被提了出来。
6.1.2 动量(Momentum):冲过鞍点的“惯性”
物理类比 Momentum优化器的灵感,源于一个简单的物理类比。想象一个有质量的铁球从山上滚下,它的运动轨迹不仅取决于当前位置的坡度(梯度),更受到其自身**惯性(动量)**的影响。即使它滚到一个平坦的区域(梯度为零),由于惯性的存在,它依然会继续前行,从而有可能冲过鞍点或浅的局部最小值。
工作原理 Momentum在SGD的基础上,引入了一个“动量”项 v,它是过去所有梯度的一个指数加权移动平均。参数的更新方向,不再仅仅是当前的梯度 g,而是动量 v: v = β * v + (1-β) * g (更新动量,β通常取0.9) w = w - learning_rate * v (用动量来更新权重)
这种机制带来了两个好处:
- 加速收敛:在梯度方向基本一致的区域(如峡谷的延伸方向),动量会持续累积,使得更新步伐越来越大,从而加速前进。
- 抑制振荡:在梯度方向来回变化的区域(如峡谷的两侧),动量项中的正负梯度会相互抵消,从而抑制了振荡,使优化路径更平滑。
6.1.3 自适应学习率:为每个参数定制“步长”
另一大类优化思想,是让学习率能够自适应(Adaptive)。其核心洞见是:对于模型中不同的参数,我们或许应该使用不同的学习率。
Adagrad (Adaptive Gradient Algorithm) 核心思想:Adagrad认为,那些在训练中更新不频繁的参数(通常对应稀疏特征,其梯度累积较小),可能蕴含着重要的信息,我们应该给它们一个较大的学习率以鼓励其更新;而那些更新频繁的参数(梯度累积较大),则应该给它们一个较小的学习率以求稳定。它通过累积每个参数梯度的平方和来实现这一点。
优点与缺点:Adagrad在处理稀疏数据(如NLP中的词嵌入)时表现出色。但它有一个致命缺陷:由于分母中的梯度平方和是单调递增的,学习率会随着训练的进行而持续、不可逆地下降,最终可能变得过小,导致训练在还未充分收敛时就提前停止了。
RMSprop (Root Mean Square Propagation) 对Adagrad的改进:RMSprop是Geoff Hinton提出的一种对Adagrad的改进算法,旨在解决其学习率过早衰减的问题。它不再是简单地累积所有历史梯度,而是使用梯度的指数加权移动平均。这样,只有近期梯度的信息会被重点考虑,使得学习率可以根据最近的梯度情况动态调整,而不会单调递减。
6.1.4 Adam (Adaptive Moment Estimation):动量与自适应的集大成者
巅峰之作 Adam优化器,是目前深度学习领域最流行、最成功的优化器之一。它的名字已经揭示了其本质:自适应矩估计。Adam巧妙地将我们前面讨论的两大主流思想——Momentum的惯性思想和RMSprop的自适应学习率思想——完美地结合在了一起。
它同时维护了两个指数加权移动平均:
- 一阶矩估计(梯度的平均值):这部分与Momentum非常相似,负责控制更新的方向和惯性。
- 二阶矩估计(梯度平方的平均值):这部分与RMSprop非常相似,负责控制每个参数自适应的学习率。
为何成为“默认选项” 通过这种双重机制,Adam几乎在所有类型的深度学习任务和模型架构中,都表现出了极其出色和稳健的性能。它通常能够快速收敛,并且对超参数的选择(如学习率)相对不那么敏感。因此,在不确定使用哪种优化器时,Adam通常是那个最安全、最高效的默认选项。
6.2 正则化:防止模型“走火入魔”的“戒律”
如果我们只专注于优化,可能会训练出一个在训练集上得分近乎完美的模型。但这往往是一种“假象”,是模型“走火入魔”的开始。这个魔,就是过拟合(Overfitting)。正则化,就是我们为模型设定的一系列“戒律”,防止它误入歧途。
6.2.1 过拟合(Overfitting):智慧的“诅咒”
现象与本质 过拟合的典型现象是:模型在训练集(Training Set)上表现极佳(损失很低,精度很高),但在从未见过的测试集(Test Set)或验证集(Validation Set)上却表现糟糕。 其本质是,一个过于强大的模型(参数过多),在有限的训练数据上,不仅学到了数据中普适的、潜在的规律,更学到了数据中独有的噪声和偶然的巧合。它完美地“记忆”了训练样本,却失去了**泛化(Generalize)**到新样本的能力。
奥卡姆剃刀原则 所有正则化技术,其背后的哲学思想都可以追溯到著名的奥卡姆剃刀原则:“如无必要,勿增实体”(Entities should not be multiplied without necessity)。在机器学习中,这意味着:如果有多个模型都能很好地解释数据,我们应该选择那个最简单的模型。因为简单的模型更可能抓住问题的本质,而非表面的噪声。正则化,就是通过各种手段对模型的复杂度施加“惩罚”或“限制”,引导它去寻找那个更简单的解。
6.2.2 L1/L2正则化:为参数戴上“紧箍咒”
L1和L2正则化是最古老、最经典的正则化方法。它们通过在原始的损失函数上,增加一个关于模型权重的“惩罚项”来实现。
L2正则化(权重衰减) 原理:在损失函数后,加上一个与所有权重参数平方和成正比的惩罚项:Loss_new = Loss_original + λ * Σ(w²) 。其中 λ 是正则化强度的超参数。 效果:这个惩罚项会促使优化器在减小原始损失的同时,也尽量减小权重的大小。它倾向于让模型的权重值变得更小、更分散,使得模型的决策边界更平滑,从而降低了对训练数据中个别噪声点的敏感度。在很多框架中,它也被称为权重衰减(Weight Decay)。
L1正则化 原理:在损失函数后,加上一个与所有权重参数绝对值之和成正比的惩罚项:Loss_new = Loss_original + λ * Σ|w|。 效果:L1正则化有一个非常独特的特性。由于绝对值函数在原点处的尖点,它会强烈地驱使那些对模型贡献不大的参数权重,精确地变为零。这相当于自动地进行了一次特征选择,剔除了无效特征,使得最终的模型变得稀疏(Sparse)。
6.2.3 Dropout:随机“失忆”的智慧
Dropout是深度学习时代提出的一种极其强大且简单有效的正则化技术。
工作原理 在训练过程中,对于神经网络的某一层,Dropout会以一个预设的概率 p(例如 p=0.5),随机地将其中的一部分神经元的输出暂时置为零。这意味着,在每一次前向传播中,网络都好像被“阉割”成了一个不同的、更小的“子网络”。而在测试过程中,则会使用完整的、未经丢弃的网络。
效果与隐喻 Dropout的强大效果,可以从两个角度来理解:
- 打破协同适应:它强制一个神经元不能过度依赖于其他某几个特定的神经元。因为它“身边”的任何一个“同事”,都随时可能“罢工”。这迫使网络去学习更加鲁棒、更加独立的特征表示。
- 集成学习的近似:从宏观上看,每一次迭代使用一个不同的子网络进行训练,整个Dropout的训练过程,就好像在同时训练成千上万个共享权重的、不同结构的网络。而在测试时使用完整的网络,则近似于将这些海量的子网络进行**模型集成(Ensemble)**来做预测。这是一种极其廉价而高效的Bagging集成近似,能显著提升模型的泛化能力。
6.2.4 早停(Early Stopping):见好就收的“禅定”
原理 早停是一种充满实践智慧的正则化策略。它的做法是:在训练模型的同时,我们并不只关心模型在训练集上的损失,而是持续地监控它在一个独立的验证集上的性能(例如,验证集上的损失或准确率)。 通常,训练初期的几个epoch,训练集和验证集的损失都会下降。但到某个时间点之后,训练集的损失仍在继续下降,而验证集的损失却开始停止下降,甚至不降反升。这个“拐点”,正是模型开始过拟合的信号。早停策略,就是在探测到这个拐点后,立即停止训练,并将模型恢复到在验证集上性能最好的那个状态。
实践智慧 早停的美妙之处在于其简单和高效。它不需要修改损失函数,也不需要引入额外的超参数(除了耐心等待的epoch数)。它直击问题的核心,在模型即将“走火入魔”的那一刻,果断地让它“收功禅定”,从而以最小的代价获得了极佳的正则化效果。
6.3 批归一化(Batch Normalization):重塑“地形”的“风水术”
批归一化(BN)是深度学习训练技术中的一项里程碑式的发明。它不仅能极大地加速模型的收敛速度,还兼具一定的正则化效果。它就像一位高明的“风水大师”,通过调整网络内部的数据“风水”,让训练过程变得异常顺畅。
6.3.1 内部协变量偏移(Internal Covariate Shift)
问题描述 想象一下深度网络的训练过程。当第一层的参数通过梯度下降进行更新后,它输出的数据的分布(均值、方差等)就发生了改变。对于第二层来说,它上一轮刚学会如何处理旧的输入分布,下一轮就要面对一个新的、陌生的输入分布。这种网络内部,层与层之间输入分布不断变化的现象,就被称为内部协变量偏移。 这迫使网络的每一层都需要不断地去适应其上游层输入分布的变化,就像在流沙上盖楼一样,极大地拖慢了整体的训练效率。
6.3.2 BN的工作原理
强制“水土”稳定 BN的解决方案简单而粗暴:在每一层的线性变换之后、激活函数之前,它强行将输入的数据(在一个mini-batch的范围内)进行一次标准化处理,使其均值恢复为0,方差恢复为1。 这样一来,无论上游层的参数如何变化,流到下游层的数据,其分布都被稳定在了这个标准状态,极大地稳定了“地基”。
可学习的“微调” 但新的问题来了:强行将数据都扭曲成标准正态分布,会不会破坏掉网络好不容易学到的有用特征呢?比如,某个特征的分布范围本身就蕴含着重要信息。 为了解决这个问题,BN引入了两个可以像权重一样通过学习来更新的参数:缩放因子 γ (gamma) 和 平移因子 β (beta)。在标准化之后,BN会用这两个参数对数据再进行一次线性的缩放和平移:y = γ * x_normalized + β。 这给了网络一个“反悔”的机会。在最坏的情况下,网络可以通过学习让 γ 等于原始数据的标准差,β 等于原始数据的均值,从而完全抵消掉标准化操作,恢复出原始的特征分布。这确保了BN在带来好处的同时,不会削弱模型的表达能力。
6.3.3 BN带来的好处
加速收敛:这是BN最主要的好处。由于内部数据分布被稳定,优化过程变得更加平滑,使得我们可以放心地使用更高的学习率,从而极大地加速模型的收敛。
缓解梯度消失:通过将数据拉回到激活函数(如Sigmoid)的线性区(中心区),BN有效地缓解了梯度饱和和梯度消失的问题。
自带正则化效果:由于BN是基于每个mini-batch的均值和方差进行计算的,而每个batch的数据都略有不同,这相当于为网络的每一层都引入了轻微的随机噪声。这种噪声,起到了类似Dropout的正则化效果,有助于提升模型的泛化能力。
6.4 超参数调优:寻找最佳“丹方”的艺术
如果说前面介绍的技术是“炼丹”中的具体“手法”,那么超参数调优,就是寻找最佳“丹方”的艺术。
6.4.1 超参数 vs. 参数
参数(Parameters):是模型在训练过程中,通过优化算法自动学习得到的值。例如,神经网络中的权重 w 和偏置 b。
超参数(Hyperparameters):是我们在训练开始之前,需要手动设定的配置。例如,学习率的大小、网络的层数、每个隐藏层的神经元数量、Dropout的丢弃率、正则化强度 λ 等。这些超参数共同决定了模型的架构和训练的方式,是模型的“基因”和“培养方案”。
6.4.2 经典的调优策略
网格搜索(Grid Search) 这是一种最暴力、最直接的地毯式搜索方法。需要为每一个所关心的超参数,设定一个候选值的列表。网格搜索会穷尽这些列表值的所有可能组合,为每一种组合都训练一个模型,并最终选出在验证集上表现最好的那个组合。 它的优点是完备,只要候选列表足够好,理论上能找到最优解。缺点是其计算成本随着超参数数量的增加呈指数级增长,在深度学习中几乎不可行。
随机搜索(Random Search) 随机搜索的做法是,不再尝试所有组合,而是在为每个超参数设定的一个范围内,随机地采样指定次数的组合来进行实验。 实践和理论都证明,随机搜索通常比网格搜索更高效。因为对于大多数模型来说,真正对性能有决定性影响的,往往只是少数几个“关键”超参数。随机搜索更有可能在这些关键超参数上探索到更优的值,而不会把大量的计算资源浪费在那些不重要的超参数的精细划分上。
6.4.3 更智能的调优:贝叶斯优化
学习如何搜索 网格搜索和随机搜索都是“盲目”的,每一次实验都是独立的,不会从过去的失败或成功中学到任何东西。贝叶斯优化则是一种更智能的策略。 它的核心思想是:根据所有已经完成的实验结果(即“(超参数组合,模型性能)”这个数据点),建立一个关于“哪个超参数组合可能会带来更好性能”的概率模型(代理模型)。然后,它利用这个模型,去智能地、有选择地挑选下一个最有希望(或者说,不确定性最大且潜力最高)的候选点进行尝试。 通过这种“边学边猜”的方式,贝叶斯优化通常能用比随机搜索少得多的实验次数,找到一个更好或相当的解,是目前进行复杂模型超参数调优的主流高级方法。
6.5 权重初始化:赢在“起跑线”
在“炼丹”的最后,我们回到起点。丹炉点火的那一刻,炉内物质的初始状态,往往对最终成丹的品质有决定性影响。权重初始化,就是这门“赢在起跑线”的学问。
6.5.1 初始化为何重要
打破对称性 一个绝对不能犯的错误,是将所有权重都初始化为0。如果这样做,那么在同一层的所有神经元,它们的输入、输出、以及接收到的梯度将永远是完全相同的。它们会像被捆绑在一起一样,学习到完全相同的特征。这被称为对称性问题,它会使得深度网络的多层结构完全失去意义。
梯度消失/爆炸 不恰当的随机初始化,也可能带来灾难。如果权重初始值过小,信号在前向传播中会逐层衰减,导致输出接近于0;梯度在反向传播中也会逐层消失,使网络难以训练。反之,如果权重初始值过大,则可能导致信号和梯度在前向和反向传播中被逐层指数级地放大,造成梯度爆炸,使训练过程发散。
6.5.2 现代初始化策略
现代的权重初始化策略,其核心目标都是为了让信号能够在网络中更稳定地流动,即保持每一层输出的方差大致稳定。
Xavier/Glorot初始化 核心思想:Xavier初始化推导出的一个关键结论是,为了保持前向传播和反向传播中信号方差的稳定,权重的初始化方差应该与该层的输入节点数 n_in 和输出节点数 n_out都有关。它通常从一个均值为0,方差为 2 / (n_in + n_out) 的均匀分布或正态分布中进行采样。 适用场景:这种初始化方法,在其推导中假设了激活函数是线性的,因此它在那些关于原点对称的激活函数(如Sigmoid和Tanh)上表现得非常好。
He初始化 对Xavier的修正:当激活函数换成现代网络中最常用的ReLU时,情况发生了变化。ReLU会将所有负的输入都置为零,这相当于直接“砍掉”了一半的信号。He初始化敏锐地考虑到了这一点,它在推导中修正了方差的计算,最终得到的采样方差为 2 / n_in。 适用场景:由于它专为ReLU及其变体(如Leaky ReLU)设计,He初始化是所有使用ReLU激活函数的现代深度神经网络的标准权重初始化方法。
小结
至此,我们已经完整地学习了深度学习“炼丹术”中的五大核心秘笈。从选择合适的优化器来高效导航,到运用正则化技术为模型设定戒律以防过拟合;从利用批归一化来稳定内部环境以加速收敛,到探索超参数调优的艺术来寻找最佳丹方;最后,我们还掌握了通过权重初始化来赢得一个良好开局的智慧。
这些技术,并非相互独立,而是相辅相成,共同构成了一个成功的深度学习实践者所必须具备的知识体系。它们将理论与工程、科学与艺术完美地结合在一起。
掌握了这些“炼-丹-术”,读者便拥有了将一个平庸模型,打磨成一个高性能模型的关键能力。现在,我们的“内功”与“招式”均已大成,是时候去挑战深度学习领域中那些更专门、更强大的“神功”了。在接下来的章节中,我们将进入计算机视觉和自然语言处理这两个最激动人心的应用领域。
第三部分:进阶篇 —— 掌握核心网络架构
第七章:卷积神经网络(CNN) —— 洞悉图像的奥秘
超越像素 —— 让机器“看”懂世界
欢迎来到深度学习最令人激动、也最符合我们人类直觉的领域——计算机视觉。我们的世界,是一个由图像和视频构成的视觉信息的海洋。让机器能够像我们一样“看”懂这个世界,是人工智能长久以来的梦想。在深度学习浪潮兴起之前,这个梦想遥不可及。而卷积神经网络(CNN)的出现,则如同一道划破长夜的闪电,彻底改变了这一切。
在前面的章节中,我们已经熟悉了多层感知机(MLP)。如果我们试图用MLP来处理一张图像,会遇到两个难以逾越的障碍。首先,我们需要将二维的图像矩阵展平(Flatten)成一个长长的一维向量。这个粗暴的操作,会彻底丢失图像宝贵的空间结构信息——一个像素与其上下左右邻居的关系,对于理解图像至关重要。其次,即使是一张很小的彩色图片,展平后的向量维度也极其巨大,这意味着MLP的输入层和第一隐藏层之间将产生天文数字般的参数量,这不仅让模型极易过拟合,也使其在计算上难以承受。
CNN,正是为解决这些问题而生的、一种专为处理像图像这类网格状数据而精心设计的神经网络架构。它的设计中,蕴含着深刻的仿生学智慧,其核心思想源于对生物视觉皮层工作方式的模仿。它不再将图像视为一个无序的像素集合,而是通过一种巧妙的方式,逐层地、有结构地从中提取信息——从最底层的边缘、角点,到中间层的眼睛、鼻子等部件,再到最高层的物体乃至场景。
在本章的探索中,我们将首先深入CNN赖以成功的三大基石思想:局部连接、权值共享与池化。随后,我们将像解剖学家一样,逐一剖析构成CNN的核心组件。接着,我们将穿越时空,回顾从LeNet-5到ResNet的经典CNN架构波澜壮阔的演进史诗,见证一代代AI先驱们如何将网络推向新的深度与高度。最后,我们将学会如何站在巨人的肩膀上,利用迁移学习来解决我们自己的问题,并一窥CNN在图像分类、目标检测、图像分割等更广阔世界中的强大应用。
准备好开启机器的“慧眼”了吗?让我们一同进入CNN的奇妙世界。
7.1 CNN的核心思想:源于视觉的智慧
CNN之所以能在计算机视觉领域取得如此巨大的成功,并非偶然。它的设计哲学,与我们生物视觉系统处理信息的方式惊人地相似。这三大核心思想——局部连接、权值共享和池化——共同构成了CNN高效而强大的基础。
7.1.1 局部连接(Local Connectivity):专注“一隅”
生物视觉的启发 让我们先思考一下我们自己的眼睛是如何工作的。诺贝尔奖得主Hubel和Wiesel的研究发现,猫的视觉皮层中,每个神经元都只对视野中的一个非常小的局部区域有反应。这个区域,被称为神经元的感受野(Receptive Field)。我们看世界,并不是一眼就感知到所有像素,而是由无数个这样的神经元,各自负责自己的一小片“责任田”,然后大脑再将这些局部信息整合起来,形成完整的视觉感知。
CNN的实现 CNN完美地借鉴了这一机制。在一个卷积层中,其神经元(或者说,输出特征图上的一个单元)不再与前一层的所有神经元相连接(这正是MLP的做法),而仅仅连接到输入图像(或前一层特征图)的一个很小的局部区域。 这个设计背后,蕴含着一个非常符合直觉的假设:物体的局部特征,是由其局部像素决定的。例如,要判断一个地方是否存在一个“角点”,我们只需要观察这个点周围一小圈像素的模式即可,而无需关心图像远处的内容。 局部连接这一思想,使得CNN的连接数和参数数量,相较于全连接的MLP,得到了指数级的减少,这是CNN能够处理高分辨率图像的第一个关键。
7.1.2 权值共享(Weight Sharing):一把“标尺”量天下
局部连接解决了参数过多的问题,但如果每个局部区域都需要一套独立的权重去学习,参数量依然庞大。权值共享,是CNN的第二个、也是更具革命性的思想。
图像的平移不变性 让我们再思考一个视觉常识:一个特定的模式,比如一只鸟的眼睛,无论它出现在图像的左上角,还是右下角,它作为“眼睛”的这个本质特征是不会改变的。我们大脑中的“眼睛探测器”,不会因为目标位置的改变而需要重新学习。这种特性,我们称之为平移不变性(Translation Invariance)。
卷积核(Kernel/Filter) 为了在神经网络中实现这一点,CNN引入了卷积核(Kernel),也常被称为滤波器(Filter)。一个卷积核,本质上就是一个小型的权重矩阵(例如3x3或5x5),它被设计用来检测一种特定的局部特征(如一个特定的边缘、一种特定的颜色组合或一个角点)。 权值共享的核心在于,这个卷积核会像一个滑动窗口一样,系统性地扫描整张输入图像。在每一个位置,它都与图像的对应局部区域进行计算(点积运算),并将结果记录在输出特征图的相应位置。重要的是,在整个滑动的过程中,这个卷积核的权重是固定不变的。
巨大的效率提升 权值共享的意义是巨大的。它意味着,我们只需要学习一个“眼睛探测器”(即一个卷积核),就可以用它来检测出图像中所有位置的眼睛。我们不再需要为图像的每一个像素位置,都单独去学习一个“眼睛探测器”。 通过这种方式,一个卷积层需要学习的参数数量,仅仅是其包含的卷积核的权重数量,这与输入图像的尺寸完全无关。这使得CNN在参数效率上达到了极致,也是其能够从有限数据中学到泛化能力极强的特征的根本原因。
7.1.3 池化(Pooling):去粗取精,降维减参
在通过卷积层提取到一系列特征之后(例如,我们得到了一张图,上面标记了所有“眼睛”特征被激活的位置),CNN通常会进行一次池化操作。
目的与思想 池化的核心思想是降低特征图的空间分辨率,即进行下采样(Downsampling)。这基于一个洞见:当我们检测到一个特征后,其精确到像素级别的位置,往往不如它与其他特征的相对位置关系来得重要。例如,知道一只眼睛的左边有一个鼻子,比知道这只眼睛在图像的(105, 210)像素位置要有用得多。 池化操作,就是在一个局部邻域内(例如一个2x2的窗口),用一个单一的值来概括这个区域的特征信息,从而实现信息的浓缩和降维。
效果 池化层通常不包含任何需要学习的参数,但它带来了三大好处:
- 降低计算量:它显著减小了特征图的尺寸(例如,一个
2x2的池化会将特征图的宽高各减半,尺寸变为原来的1/4),从而大幅降低了后续网络层的参数数量和计算负担。 - 增加感受野:这是一个非常重要的间接效果。由于池化层缩小了特征图,使得后续的卷积层虽然其卷积核尺寸不变,但其每一个单元所能“看到”的**原始输入图像的区域(即感受野)**却变大了。这使得网络能够学习到更大尺度、更抽象的特征。
- 提供平移不变性:池化操作使得模型对于特征在图像中的微小位移,具有了一定的容忍度。例如,即使目标在
2x2的窗口内移动了一个像素,只要它仍然是这个窗口内的最强响应,最大池化的输出结果就不会改变。这增强了模型的鲁棒性。
这三大思想——局部连接、权值共享、池化——如三根擎天之柱,共同支撑起了CNN这座宏伟的大厦。它们使得CNN能够以一种极其高效、且符合视觉规律的方式,从原始像素中逐层提取出越来越抽象、越来越有意义的特征表示。
7.2 核心组件详解:构建CNN的“乐高积木”
理解了CNN的核心思想后,我们就可以来详细审视构成一个典型CNN模型的“乐高积木”了——卷积层、池化层和全连接层。
7.2.1 卷积层(Convolutional Layer):特征提取的引擎
卷积层是CNN的心脏和灵魂,它负责执行最主要的特征提取工作。
关键元素 一次卷积操作,涉及以下几个关键元素:
- 输入特征图(Input Feature Map):它可以是原始的图像(例如,一个
224x224x3的彩色图像,3代表RGB三个颜色通道),也可以是前一个卷积层输出的特征图。 - 卷积核(Kernel / Filter):一个小的权重矩阵。需要注意的是,卷积核的深度必须与输入特征图的深度相匹配。例如,如果要在一个
224x224x3的图像上做卷积,那么卷积核的尺寸就必须是kxk_x3(如3x3x3)。它会同时在三个通道上进行计算,并将结果相加,得到一个单一的输出值。 - 输出特征图(Output Feature Map):也称为激活图(Activation Map)。它是卷积核在输入特征图上滑动并计算后生成的结果。输出特征图上的每一个像素值,都代表了卷积核所对应的那个特定特征,在输入图像该位置的激活强度。
超参数详解 在定义一个卷积层时,我们需要设定几个关键的超参数,它们共同决定了该层的行为:
- 滤波器数量(Number of Filters):这是最重要的超参数之一。它决定了一个卷积层要学习多少种不同类型的特征。如果我们设定滤波器数量为64,那么这个卷积层就会拥有64个独立的卷积核,每个核都去学习一种不同的模式。最终,该层会输出一个深度为64的特征图。
- 滤波器尺寸(Filter Size):即卷积核的宽度和高度,通常选择较小的尺寸,如
3x3或5x5。小的滤波器尺寸意味着更少的参数和更精细的特征。 - 步长(Stride):指卷积核在输入特征图上每次滑动的像素距离。步长为1表示逐像素滑动,步长为2则表示每次跳过一个像素。较大的步长会产生更小的输出特征图,有类似池化的降采样效果。
- 填充(Padding):如果在卷积操作前,不先在输入特征图的边缘进行填充,那么输出特征图的尺寸将会比输入小。填充通常是在输入的边缘周围补上一圈或几圈的0。最常用的
padding='same'设置,可以确保在步长为1的情况下,输出特征图的空间尺寸与输入特征图完全相同,这在构建深层网络时非常方便。
7.2.2 池化层(Pooling Layer):信息的高度浓缩
池化层通常紧跟在卷积层之后,用于对提取出的特征进行降维和概括。
最大池化(Max Pooling) 工作原理:这是最常用、最有效的池化方式。它将特征图划分为若干个不重叠的矩形区域(池化窗口,如2x2),然后,在每个区域内,只取最大值作为唯一的输出。 直观理解:最大池化传递了一个非常明确的信息:“我只关心这个区域内是否存在我想要的那个特征,以及这个特征的最强响应是什么”。它对特征的位置不敏感,只对特征的有无和强度敏感,这是一种非常有效的非线性下采样。
平均池化(Average Pooling) 工作原理:与最大池化类似,但它计算的是池化窗口内所有像素值的平均值作为输出。 直观理解:平均池化保留了每个区域特征的“整体背景信息”,其输出更为平滑。在历史上它曾被使用,但在现代CNN中,除了在网络末端用于全局平均池化(Global Average Pooling)之外,在中间层,其效果通常不如最大池化。
7.2.3 全连接层(Fully Connected Layer):特征的“翻译官”
在经过了多轮“卷积-激活-池化”的特征提取之后,我们得到了一组高度抽象、但空间维度较小的特征图。现在,我们需要根据这些特征来做出最终的决策。这个任务,就交给了位于CNN架构末端的全连接层。
角色与位置 全连接层通常是CNN的最后几个层。在它之前,最后一层卷积或池化层输出的立体特征图(例如,一个7x7x512的特征图)会被**展平(Flatten)**成一个长长的一维向量(7*7*512 = 25088维)。
工作原理与功能 这个一维向量,随后会被送入一个或多个我们早已熟悉的全连接层(即MLP)。 全连接层的作用,就像一个“翻译官”。它接收前面所有卷积层辛辛苦苦提取出的、高度抽象的、分布式的特征表示(例如,“有毛茸茸的耳朵”、“有胡须”、“有猫一样的眼睛”等特征的激活值),然后对这些高级特征进行加权组合与非线性变换,最终将它们“翻译”成我们任务所需要的最终输出。 例如,在一个1000类的图像分类任务中,最后一个全连接层的输出维度就是1000,并通过Softmax激活函数,将其转换为对这1000个类别的预测概率。
通过这三种核心组件的有机组合与堆叠,CNN构建起了一个从局部到全局、从具体到抽象的、强大的分层特征学习体系。
7.3 经典CNN架构演进:一部浓缩的视觉AI史
从第一个能够实际应用的CNN,到如今动辄上百层的庞然大物,这条演进之路充满了智慧的闪光与思想的碰撞。理解这些经典架构,就是理解CNN发展的脉络与精髓。
7.3.1 LeNet-5 (1998):开山鼻祖
历史地位 在深度学习还未成为潮流的20世纪90年代,Yann LeCun教授便设计出了LeNet-5,并成功地将其应用于美国邮政系统的手写数字识别任务中。它被公认为第一个被成功大规模商业应用的卷积神经网络,是当之无愧的开山鼻祖。
核心贡献 LeNet-5的架构虽然在今天看来非常小巧,但它却奠定了现代CNN的基本蓝图。它首次完整地展示了“输入 -> 卷积 -> 池化 -> 卷积 -> 池化 -> 全连接 -> 全连接 -> 输出”这一经典范式。它使用的激活函数是Sigmoid和Tanh,池化方式是平均池化。LeNet-5的成功,证明了这种分层特征提取的架构是行之有效的。
7.3.2 AlexNet (2012):王者归来
历史地位 在LeNet之后,由于计算能力的限制和SVM等传统方法的强势,神经网络经历了一段漫长的“寒冬”。直到2012年,Alex Krizhevsky、Ilya Sutskever和Geoff Hinton带着AlexNet,在当年的ImageNet大规模视觉识别挑战赛(ILSVRC)中,以碾压性的优势(Top-5错误率15.3%,远低于第二名的26.2%)一举夺冠。这一事件,如同一声惊雷,宣告了深度学习时代的王者归来,引爆了至今仍在持续的人工智能革命。
核心贡献 AlexNet的成功并非偶然,它建立在LeNet的基础上,并引入了几个关键的、具有划时代意义的创新:
- 更深更宽的网络:它拥有5个卷积层和3个全连接层,比LeNet-5大得多,能够学习更复杂的特征。
- ReLU激活函数:它首次在大型CNN中用ReLU替换了传统的Sigmoid/Tanh。ReLU的非饱和性极大地缓解了梯度消失问题,使得训练深层网络成为可能,收敛速度也快得多。
- Dropout:在最后的全连接层中使用了Dropout技术,有效地抑制了由于模型参数过多而导致的过拟合问题。
- GPU训练:这是其成功的关键秘诀。作者创造性地使用了两块NVIDIA GTX 580 GPU进行并行训练,极大地提升了计算效率,使得训练如此庞大的网络成为现实。
7.3.3 VGGNet (2014):极致的简约与深度
设计哲学 AlexNet之后,牛津大学的视觉几何组(Visual Geometry Group, VGG)提出了VGGNet。它的核心设计哲学是:大道至简。VGGNet摒弃了花哨的结构,旨在探索一个纯粹的问题——网络深度对性能究竟有多大影响?为此,它将整个网络都用一种极其规整、统一的组件来搭建。
核心贡献 VGGNet最核心的贡献,是证明了使用多个堆叠的、非常小的(3x3)卷积核,其效果优于使用一个大的卷积核。例如,两个3x3的卷积层堆叠,其感受野等效于一个5x5的卷积层,但参数量更少,且能引入更多的非线性变换,表达能力更强。VGGNet凭借其极致简约、规整的“积木块”式结构,将网络深度推向了16-19层,取得了优异的性能。由于其结构简单清晰,VGGNet至今仍是许多研究和应用中非常受欢迎的基线模型。
7.3.4 GoogLeNet (Inception) (2014):宽度的探索
设计哲学 与VGGNet同年,Google团队提出了GoogLeNet,并赢得了2014年的ImageNet挑战赛。它提出了一个不同的问题:在网络不断变深的同时,我们能否让网络也变得更“宽”,并且更高效?GoogLeNet的核心,是其精巧设计的Inception模块。
核心贡献 Inception模块的思想是,对于一个输入特征图,我们很难预知用多大尺寸的卷积核去处理才是最优的。那么,何不将不同尺寸的操作并行地执行一遍,然后让网络自己去学习如何组合它们? 一个Inception模块会并行地对输入使用1x1卷积、3x3卷积、5x5卷积以及3x3最大池化,然后将所有这些操作的输出特征图在深度这个维度上**拼接(Concatenate)**起来。这种“网络中的网络”(Network-in-Network)结构,极大地提升了网络的宽度和对不同尺度特征的适应能力。同时,它还巧妙地使用1x1的卷积核来进行降维,极大地减少了计算量。
7.3.5 ResNet (Residual Network) (2015):跨越深度的天堑
面临的问题 随着网络越来越深,人们发现了一个令人困惑的现象:网络退化(Degradation)。按理说,一个更深的模型,其解空间包含了那个更浅的模型,性能至少不应该更差。但实验表明,当网络堆叠到一定深度后(例如56层),其训练误差和测试误差反而会比一个较浅的网络(例如20层)更高。这说明,让一个深度网络去学习一个恒等映射(即什么都不做,直接输出输入)都是非常困难的。
核心贡献 2015年,何恺明等几位华人研究员提出的残差网络(ResNet),天才般地解决了这个问题。其核心是引入了残差连接(Residual Connection),也常被称为快捷连接(Shortcut Connection)。 这个连接允许输入信号 x 可以“抄近道”,直接跳过一个或多个卷积层,在这些层的输出 F(x) 之后,直接与之相加,得到最终的输出 H(x) = F(x) + x。 这个简单的改动,彻底改变了网络的学习目标。网络不再需要去拟合一个期望的完整映射 H(x),而仅仅需要去学习输入与输出之间的残差(Residual)F(x)。如果某个层对于当前任务是冗余的,网络只需要将这一层的权重 F(x) 学成0即可,此时 H(x) = x,一个恒等映射被轻松实现。
历史地位 ResNet的出现,如同一座桥梁,跨越了阻碍网络走向更深的天堑。它使得训练数百层甚至上千层的超深神经网络成为可能,极大地提升了模型的性能,并再次刷新了ImageNet的记录。残差连接的思想,成为了后续几乎所有先进CNN架构的标配。
7.4 迁移学习与微调:站在巨人的肩膀上
我们刚刚回顾的这些经典架构,尤其是ResNet等,它们的强大性能背后,是在ImageNet这样拥有上百万张图片、上千个类别的数据集上,使用海量GPU资源训练数周的结果。这对于绝大多数个人和中小型组织来说,是完全无法复现的。那么,我们是否就无法享受到这些强大模型的红利了呢?答案是:我们可以,通过迁移学习。
7.4.1 迁移学习的核心思想
迁移学习的基石是一个重要的洞见:知识是可以迁移的。一个在ImageNet上预训练好的CNN模型,它在靠近输入的浅层网络中,学到的是非常通用的视觉特征,比如边缘、角点、纹理、颜色块等。这些基础特征,对于解决几乎所有的计算机视觉任务都是有用的,无论是识别猫狗,还是诊断医疗影像。
7.4.2 迁移学习实践策略
我们可以“借用”这些在大规模数据集上预训练好的模型(Pre-trained Model),将其作为我们自己任务的一个强大的、现成的特征提取器。具体操作上,通常有两种策略:
-
作为固定的特征提取器 这是最简单的方法。我们加载一个预训练模型(如ResNet-50),然后“冻结”其所有卷积层(即在训练中保持它们的权重不变)。我们只移除其原始的分类头(即最后的全连接层),换上我们自己为新任务设计的、新的、未训练的分类头。在训练时,我们只更新这个新分类头的参数。这种方法非常适合当我们的新任务数据集很小的时候。
-
微调(Fine-tuning) 这是一种更强大、也更常用的策略。我们同样加载预训练模型并替换分类头。但这一次,我们不完全冻结卷积层。我们用一个非常小的学习率,解冻并继续训练预训练模型的部分或全部卷积层(通常是更靠近输出的、更抽象的高层特征层)。 这样做,可以让那些预训练好的、通用的特征,根据我们新任务的数据分布,进行一些细微的调整,使其更能“专精”于我们的特定任务。微调通常能带来比固定特征提取器更好的性能,尤其是在我们的新任务数据量不是特别小的情况下。
迁移学习,让我们得以站在巨人的肩膀上,用有限的数据和计算资源,快速地构建出性能优异的视觉模型。
7.5 CNN的应用:从分类到更广阔的世界
虽然我们本章的讨论大多围绕图像分类展开,但这仅仅是CNN能力的冰山一角。掌握了分层特征提取这一核心能力后,CNN被广泛地应用于各种更复杂的视觉任务中。
7.5.1 图像分类(Image Classification)
这是CNN最基础、最核心的应用,即回答“这张图片里有什么?”的问题。它是所有其他视觉任务的基础。
7.5.2 目标检测(Object Detection)
目标检测的任务更进一步,它需要回答“图片里的物体分别是什么?它们在哪里?”。它不仅要识别出图像中所有物体的类别,还要用一个紧密的**边界框(Bounding Box)**来标出每个物体的位置。
- 经典方法:
- 两阶段方法:以 Faster R-CNN 为代表。它首先通过一个“区域提议网络”(RPN)来生成上千个可能包含物体的“候选区域”,然后,再对这些候选区域逐一进行分类和边界框的精确回归。这类方法通常精度更高。
- 单阶段方法:以 YOLO (You Only Look Once) 系列为代表。它摒弃了候选区域的步骤,将目标检测视为一个单一的回归问题,直接在整个图像上,一次性地预测出所有物体的类别和边界框坐标。这类方法通常速度极快,非常适合需要实时处理的应用场景。
7.5.3 图像分割(Image Segmentation)
图像分割是计算机视觉中最为精细的任务,它追求对图像的像素级别的理解。
- 主要类型:
- 语义分割(Semantic Segmentation):它的目标是,将图像中的每一个像素都分配到一个类别。例如,将图中所有的“牛”都标记为蓝色,所有的“草地”都标记为绿色,所有的“天空”都标记为青色。它关心的是类别,不区分同类中的个体。
- 实例分割(Instance Segmentation):这是最具挑战性的任务。它在语义分割的基础上,还需要区分出同类别的不同个体。例如,将第一头牛标为蓝色,将旁边的第二头牛标为绿色。它需要同时完成目标检测和语义分割两项工作。
小结
在本章中,我们一同踏上了一段洞悉图像奥秘的精彩旅程。我们从赋予CNN独特“视觉智慧”的三大基石思想——局部连接、权值共享与池化——出发,深入理解了其高效特征提取的本质。我们详细解构了构成CNN的核心组件,并见证了从LeNet-5到ResNet的波澜壮阔的架构演进史诗,领略了深度、宽度与连接的艺术。
更重要的是,我们学会了如何通过迁移学习与微调,站在巨人的肩膀上,将这些强大的预训练模型应用于我们自己的任务。最后,我们还将视野拓展到了目标检测和图像分割等更广阔的应用领域,一窥CNN改变世界的巨大潜力。
掌握了CNN,读者便拥有了开启计算机视觉世界大门的钥匙。在下一章,我们将转向另一个同样迷人的领域——自然语言处理,去探索另一种强大的神经网络架构,看它如何理解人类语言的序列之美。
第八章:循环神经网络(RNN) —— 理解序列的智慧
当神经网络拥有“记忆”
在前一章,我们探索了卷积神经网络(CNN)如何通过其独特的空间感知能力,洞悉了静态图像的奥秘。然而,我们所处的世界,更多的是以一种动态的、流动的形式存在的——语言的展开、音乐的流淌、时间的推移。这些序列数据的核心魅力,在于其内在的时间(或顺序)依赖性:一个词的意义,往往取决于它前面出现过的词语;今天的股价,与过去数天的市场表现息息相关。
我们之前学习的MLP和CNN,本质上都是前馈神经网络(Feed-forward Neural Networks)。它们是“失忆”的。对于一个输入序列,它们在处理第三个元素时,已经完全忘记了第一个和第二个元素是什么。这种结构,使它们无法捕捉序列中至关重要的上下文信息。
为了让神经网络拥有“记忆”,循环神经网络(Recurrent Neural Network, RNN)应运而生。RNN的设计中,蕴含着一种优雅而强大的思想:它引入了一个循环(Recurrent)的连接,允许信息在网络处理序列的不同时间步之间,得以持续存在(Persist)。这个循环,就像是为网络植入了一颗“记忆核心”,使其能够将过去的信息,如涓涓细流般,不断汇入对当前输入的理解之中。
在本章的旅程中,我们将首先解构RNN最基础的循环机制,并直面其与生俱来的“阿喀琉斯之踵”——长期依赖问题。随后,我们将深入探索其两个强大的现代变体——长短期记忆网络(LSTM)和门控循环单元(GRU),看它们是如何通过精巧绝伦的“门控”设计,实现了对遥远记忆的有效捕捉。最后,我们将学习如何通过双向和堆叠的方式,构建出更强大的序列模型,并最终将它们应用于自然语言处理和时间序列预测等真实世界的任务中。
现在,让我们一同开启这段旅程,去探索神经网络是如何学会理解时间,并拥有那份理解序列的独特智慧的。
8.1 RNN的结构与挑战:优雅的循环与脆弱的记忆
8.1.1 循环的核心:隐藏状态(Hidden State)
-
结构剖析 乍一看,一个RNN单元的结构图与我们熟悉的普通神经网络层似乎很相似。但其中有一个至关重要的区别:一个指向其自身的循环箭头。这个看似简单的循环,正是RNN所有魔力的来源。它表明,该层的输出,不仅会传递给下一层,还会作为下一次计算的输入,再次回到自身。
-
隐藏状态
h_t这个在时间中循环传递的信息,被称为隐藏状态(Hidden State),我们通常用h_t来表示在时间步t的隐藏状态。我们可以将h_t形象地比作是RNN在处理完序列中第t个元素后,所形成的**“瞬时记忆”**。在每一个时间步
t,RNN单元会接收两个输入:- 当前序列的输入
x_t(例如,句子中的第t个词的词向量)。 - 上一个时间步的隐藏状态
h_{t-1}(即网络在处理完第t-1个元素后留下的“记忆”)。
RNN单元内部的操作非常简单,它将这两个输入进行线性变换,然后通过一个非线性激活函数(通常是Tanh),来生成新的隐藏状态
h_t:h_t = tanh(W_hh * h_{t-1} + W_xh * x_t + b_h)其中,W_hh是作用于上一个隐藏状态的权重矩阵,W_xh是作用于当前输入的权重矩阵,b_h是偏置项。同时,RNN也可以根据新的隐藏状态h_t生成当前时间步的输出y_t:y_t = W_hy * h_t + b_y最关键的一点是,在处理整个序列的过程中,权重矩阵
W_hh,W_xh,W_hy和偏置b_h,b_y是共享的,这与CNN中的权值共享思想异曲同工,极大地减少了模型的参数量。 - 当前序列的输入
-
按时间展开(Unfolding in Time) 为了更清晰地理解信息是如何在RNN中流动的,也为了能够在计算机上进行实际的梯度计算,我们通常会将RNN的循环结构,沿着时间序列的长度展开成一个没有循环的、线性的网络。
想象一下,我们有一个长度为3的序列
(x_1, x_2, x_3)。展开后的RNN看起来就像一个三层的神经网络:- 在时间步1,RNN接收初始隐藏状态
h_0(通常是零向量)和输入x_1,计算出h_1。 - 在时间步2,RNN接收
h_1和输入x_2,计算出h_2。 - 在时间步3,RNN接收
h_2和输入x_3,计算出h_3。
这个展开后的网络清晰地揭示了RNN的本质:它是一个参数共享的、非常深的前馈神经网络,其深度等于序列的长度。信息(隐藏状态)就像一条传送带,将过去的信息一步步地传递到未来。
- 在时间步1,RNN接收初始隐藏状态
8.1.2 RNN的“阿喀琉斯之踵”:长期依赖问题
RNN的循环结构赋予了它记忆的能力,但这种记忆却是脆弱和短暂的。
-
短期记忆的困境 让我们来看一个长句子:“The clouds are in the sky.”(云在天空中)。要预测最后一个词是“sky”,我们只需要看它前面紧邻的几个词即可,RNN可以很好地处理这种短期依赖。 但再看另一个句子:“I grew up in France... therefore, I speak fluent French.”(我在法国长大……因此,我能说流利的法语)。要预测最后的“French”,网络必须能够回忆起句子开头提到的“France”这个关键信息。当这两个词语在序列中相距很远时,简单的RNN就很难将这个早期的关键信息,有效地传递到需要它的遥远未来。这就是著名的长期依赖问题(Long-Term Dependencies Problem)。
-
梯度消失(Vanishing Gradients) 这个问题的根源,在于梯度在反向传播过程中的衰减。我们已经知道,展开后的RNN是一个非常深的网络。当我们计算损失函数关于早期时间步参数的梯度时,这个梯度需要从后往前,穿过许多个时间步的RNN单元。 根据链式法则,这个梯度会包含一长串的连乘项,其中最关键的是多个
W_hh矩阵和Tanh激活函数导数的连乘。由于Tanh函数的导数值域在(0, 1]之间,远小于1,这一长串的连乘会导致梯度值以指数级的速度衰减。当梯度传播到早期的几个时间步时,它几乎已经衰减为零。 梯度消失意味着,模型几乎无法从长距离的依赖关系中学习到任何东西。网络会变得“目光短浅”,只能学习到短期模式。 -
梯度爆炸(Exploding Gradients) 与梯度消失相对,虽然在实践中不那么常见,但如果权重矩阵
W_hh的某些值较大,梯度在反向传播的连乘过程中,也可能指数级地增长,最终变成一个巨大的数值,导致模型的权重更新过大,训练过程变得不稳定甚至发散。 幸运的是,梯度爆炸问题相对容易被发现和处理。一个简单而有效的解决方案是梯度裁剪(Gradient Clipping):在每次权重更新前,检查梯度的范数。如果范数超过了一个预设的阈值,就按比例缩小梯度,使其范数回到阈值之内。
梯度消失,是标准RNN难以逾越的鸿沟,也是限制其在实际应用中发挥作用的最大障碍。为了克服这一挑战,研究者们设计出了更复杂的、带有精巧“门控”机制的循环单元。
8.2 长短期记忆网络(LSTM):记忆“门”的设计哲学
长短期记忆网络(LSTM)是Hochreiter和Schmidhuber在1997年提出的一种特殊的RNN,它被精心设计用来解决长期依赖问题。至今,它及其变体依然是序列建模任务中最主流、最强大的工具。
8.2.1 核心思想:引入“细胞状态”作为记忆主干
-
细胞状态(Cell State)
C_tLSTM的革命性创新,是在RNN的隐藏状态h_t之外,额外引入了一个细胞状态(Cell State)C_t。我们可以将这个细胞状态C_t想象成一条贯穿整个时间链的记忆“高速公路”。 信息在这条高速公路上可以非常顺畅地、几乎不经改变地向前流动。它只在少数几个地方,受到一些被称为**“门(Gates)”**的结构进行精细的、可控的调节。这种设计,使得梯度在反向传播时,也能够沿着这条“高速公路”顺畅地回传,从而从根本上解决了梯度消失的问题。 -
“门”的隐喻 LSTM中的“门”,是一种让信息选择性通过的结构。我们可以将其比作是信息流管道上的**“阀门”或“开关”。在技术上,一个门就是一个Sigmoid激活函数层**,后面通常跟着一个按元素相乘的操作。 Sigmoid层的输出在0到1之间,这个值就代表了阀门的“开合程度”:
- 输出为0,表示“阀门关闭”,不允许任何信息通过。
- 输出为1,表示“阀门完全打开”,允许所有信息通过。
- 输出在0和1之间,表示“阀门半开”,允许一部分信息按比例通过。 LSTM正是通过这些可学习的门,来智能地决定何时读取、写入和遗忘信息。
8.2.2 三大门控机制:精巧的记忆管理者
一个标准的LSTM单元,由三扇这样的门来共同管理和保护细胞状态。
-
遗忘门(Forget Gate) 作用:这扇门是LSTM的“记忆清理工”。它的职责是审视上一个时间步的隐藏状态
h_{t-1}和当前输入x_t,然后决定应该从上一个细胞状态C_{t-1}中丢弃或遗忘哪些旧的信息。 例如,当开始处理一个新的句子时,遗忘门可能会决定忘记上一个句子的主语信息。f_t = σ(W_f * [h_{t-1}, x_t] + b_f)这里的f_t就是一个介于0和1之间的向量,它将与C_{t-1}按元素相乘,决定旧记忆的保留程度。 -
输入门(Input Gate) 作用:这扇门是“新知识记录员”。它的职责是决定哪些新的信息将被吸纳,并存放到当前的细胞状态
C_t中。 这个过程分为两步:- 首先,一个Sigmoid层(即输入门)决定我们需要更新哪些值。
i_t = σ(W_i * [h_{t-1}, x_t] + b_i) - 然后,一个Tanh层创建一个候选的新信息向量
C̃_t,包含了所有可能被添加的新知识。C̃_t = tanh(W_C * [h_{t-1}, x_t] + b_C)最后,将这两部分结合起来,得到最终要添加的新记忆:i_t * C̃_t。
- 首先,一个Sigmoid层(即输入门)决定我们需要更新哪些值。
-
更新细胞状态 现在,我们可以将旧的细胞状态
C_{t-1}和新的候选记忆结合起来,得到当前的细胞状态C_t了:C_t = f_t * C_{t-1} + i_t * C̃_t这个公式非常优美:我们首先用遗忘门f_t乘以旧状态C_{t-1},丢弃掉决定要忘记的部分;然后,加上由输入门i_t筛选过的新信息C̃_t。 -
输出门(Output Gate) 作用:这扇门是“记忆表达者”。细胞状态
C_t中存储了丰富的长期和短期记忆,但我们并不一定需要将所有这些记忆都作为当前时间步的输出。输出门的职责,就是决定细胞状态中的哪些部分,将被提炼并用作当前时间步的隐藏状态h_t(h_t既是给下一层的输出,也是给下一个时间步的循环输入)。 这个过程同样分为两步:- 首先,一个Sigmoid层(即输出门)决定细胞状态的哪些部分可以被输出。
o_t = σ(W_o * [h_{t-1}, x_t] + b_o) - 然后,我们将更新后的细胞状态
C_t通过一个Tanh层(将其值压缩到-1到1之间),再与输出门的输出o_t相乘,得到最终的隐藏状态h_t。h_t = o_t * tanh(C_t)
- 首先,一个Sigmoid层(即输出门)决定细胞状态的哪些部分可以被输出。
通过这套遗忘、输入、输出的精巧门控机制,LSTM单元得以像一个高效的记忆管理者一样,智能地维护着那条记忆的“高速公路”,从而成功地捕捉到了序列数据中遥远的依赖关系。
8.3 门控循环单元(GRU):LSTM的优雅简化
门控循环单元(Gated Recurrent Unit, GRU)由Cho等人在2014年提出,可以看作是LSTM的一个戏剧性的、但非常流行的变体。它在保持LSTM强大性能的同时,对内部结构进行了简化,使得模型参数更少,计算效率更高。
8.3.1 结构上的改变
GRU对LSTM的核心架构做了两个主要的改变:
-
融合细胞状态与隐藏状态 GRU最大胆的改动,是取消了独立的细胞状态
C_t。它将LSTM中的细胞状态和隐藏状态的功能,合并到了一个单一的隐藏状态h_t之中。这条曾经的记忆“高速公路”被并入了常规车道,但通过更精巧的交通规则(门控)来避免拥堵。 -
两扇门 相应地,GRU将LSTM的三扇门(遗忘门、输入门、输出门)简化为了两扇门:更新门(Update Gate)和重置门(Reset Gate)。
8.3.2 GRU的工作机制
-
更新门
z_t这扇门的作用,非常类似于LSTM中遗忘门和输入门的结合体。它决定了在多大程度上,新的隐藏状态h_t应该直接继承上一个时间步的隐藏状态h_{t-1},以及在多大程度上,它应该接收新计算出的候选隐藏状态h̃_t。z_t = σ(W_z * [h_{t-1}, x_t])h_t = (1 - z_t) * h_{t-1} + z_t * h̃_t当z_t的值接近0时,h_t几乎完全由旧状态h_{t-1}构成,信息被直接保留;当z_t接近1时,h_t则主要由新的候选状态h̃_t构成。 -
重置门
r_t这扇门的作用,是控制在计算新的候选隐藏状态h̃_t时,应该在多大程度上忽略掉过去的隐藏状态h_{t-1}。r_t = σ(W_r * [h_{t-1}, x_t])h̃_t = tanh(W_h * [r_t * h_{t-1}, x_t])当重置门r_t的值接近0时,r_t * h_{t-1}这一项就趋近于零,这意味着在计算新的候选记忆时,将完全忽略掉过去的记忆,只依赖于当前的输入x_t。这使得GRU能够有效地抛弃与未来无关的旧信息。
8.3.3 LSTM vs. GRU:如何选择?
这是一个在实践中经常被问到的问题。
- 性能:大量的实验表明,在绝大多数任务上,精心调参的LSTM和GRU的性能都非常相似,没有一个模型被证明在所有情况下都绝对优于另一个。
- 效率:由于GRU的内部结构更简单,门更少,因此它的参数数量也更少。这意味着GRU的计算效率通常更高,训练速度更快,在数据集较小的情况下,也可能因为参数少而具有更好的泛化能力。
- 实践建议:
- 如果刚开始一个新项目,LSTM是一个非常稳健和强大的起点,因为它的三门结构提供了更精细的控制,表达能力在理论上可能更强。
- 如果非常关心计算效率,或者希望模型更轻量级,GRU是一个绝佳的替代方案。
- 最好的方法,往往是根据具体任务的验证集性能,来实验性地决定哪一个更适合。
8.4 扩展RNN:构建更强大的序列模型
掌握了LSTM和GRU这样的强大循环单元后,我们还可以通过改变网络的连接方式,来进一步提升模型的表达能力。
8.4.1 双向RNN(Bidirectional RNN)
-
单向的局限 我们目前讨论的所有RNN,都是单向的。它们在处理一个序列时,只能从左到右,按部就班地进行。这意味着,在时间步
t做决策时,模型只能利用过去(t-1及之前)的信息。 但在许多任务中,尤其是自然语言处理中,理解一个词的准确含义,往往需要同时考虑其左侧和右侧的上下文。例如,在句子“He banked the plane to the left.”中,要理解“banked”(倾斜)的含义,右侧的“plane”(飞机)一词至关重要。 -
工作原理 双向RNN(BRNN)正是为了解决这个问题而设计的。它的结构非常直观:它由两个独立的RNN(可以是Simple RNN, LSTM或GRU)组成,并排运行。
- 一个正向RNN,按正常顺序(从
t=1到t=T)处理输入序列,生成一系列正向的隐藏状态(h⃗_1, h⃗_2, ..., h⃗_T)。 - 一个反向RNN,按相反顺序(从
t=T到t=1)处理输入序列,生成一系列反向的隐藏状态(h⃖_1, h⃖_2, ..., h⃖_T)。 在任何一个时间步t,该时间步的最终隐藏状态表示,就是将正向隐藏状态h⃗_t和反向隐藏状态h⃖_t进行拼接(Concatenate):h_t = [h⃗_t ; h⃖_t]。
- 一个正向RNN,按正常顺序(从
-
优势 通过这种方式,
h_t中就同时包含了来自过去和未来的上下文信息,极大地增强了模型在每个时间步上的特征表示能力。双向结构对于NLP中的许多任务,如命名实体识别、情感分析、问答系统等,几乎是标配。其唯一的缺点是,需要完整的输入序列才能开始计算,因此不适用于需要实时预测的在线任务。
8.4.2 深度(堆叠)RNN(Deep/Stacked RNN)
-
增加“深度” 正如我们通过堆叠卷积层来构建深度CNN,以学习到从低级到高级的空间特征一样,我们也可以堆叠多个RNN层来构建深度RNN。
-
工作原理 其工作原理非常简单:
- 第一层RNN(最底层)接收原始的输入序列
(x_1, x_2, ..., x_T),并输出一个隐藏状态序列(h¹_1, h¹_2, ..., h¹_T)。 - 第二层RNN将第一层输出的隐藏状态序列
(h¹_1, h¹_2, ..., h¹_T)作为自己的输入序列,并计算出第二层的隐藏状态序列(h²_1, h²_2, ..., h²_T)。 - 这个过程可以一直重复下去。
- 第一层RNN(最底层)接收原始的输入序列
-
优势 堆叠RNN允许模型在不同的层次上学习特征。底层的RNN可能学习到一些局部的、低级的序列模式,而更高层的RNN则可以在此基础上,学习到更长期的、更抽象的时间依赖关系。在实践中,一个2到4层的深度RNN,通常能比单层RNN带来显著的性能提升。
8.5 RNN的应用:从语言到时间
掌握了LSTM、GRU以及双向和深度扩展之后,我们就拥有了一套强大的工具集,可以用来解决各种与序列相关的现实问题。
8.5.1 自然语言处理(NLP)
RNN是现代自然语言处理的基石技术之一。
-
词嵌入(Word Embedding) 计算机无法直接理解“猫”、“狗”这样的词语。在将文本喂给RNN之前,我们必须先将这些离散的、符号化的词语,转换为密集的、低维的、连续的浮点数向量。这个向量,就是词嵌入或词向量。 词嵌入不仅仅是一个技术步骤,它本身就蕴含着语义信息。通过在大量文本上进行训练(例如使用Word2Vec或GloVe算法),语义上相近的词语,其词向量在向量空间中的位置也会相互靠近。
-
文本分类与情感分析 这是RNN最直接的应用之一。任务是判断一整段文本属于哪个预设的类别(如体育、财经、科技新闻),或者其表达的情感是正面的、负面的还是中性的。 典型的做法是:将文本中的词语依次输入一个RNN(通常是LSTM或GRU)。当整个序列处理完毕后,我们可以利用最后一个时间步的隐藏状态
h_T,因为它在理论上已经编码了整个句子的信息。或者,我们也可以将所有时间步的隐藏状态进行池化(如最大池化或平均池化),来获得一个更鲁棒的句子表示。最后,将这个句子表示向量送入一个标准的全连接分类器,即可得到最终的分类结果。 -
序列到序列(Seq2Seq)任务 RNN在更复杂的NLP任务中也大放异彩,这些任务的输入和输出都是变长的序列。例如:
- 机器翻译:输入一种语言的句子,输出另一种语言的句子。
- 文本摘要:输入一篇长文章,输出一个简短的摘要。
- 对话系统:输入用户的问话,输出机器人的回答。 这些任务通常使用一种被称为**“编码器-解码器”(Encoder-Decoder)**的RNN架构,其中一个RNN(编码器)负责将输入序列压缩成一个固定大小的上下文向量,另一个RNN(解码器)则根据这个上下文向量,生成输出序列。
8.5.2 时间序列预测
除了语言,任何以时间为轴的数据,都是RNN的用武之地。
-
任务定义 时间序列预测的任务是,利用过去一段时间的历史观测数据,来预测未来一个或多个时间点的值。应用场景极其广泛,包括:
- 金融:预测股票价格、汇率走势。
- 气象:预测未来几小时或几天的气温、降雨量。
- 工业:预测网站流量、电力消耗、产品销量。
-
模型构建 构建一个基于RNN的时间序列预测模型,通常遵循以下步骤:
- 数据准备:将一维的时间序列数据,转换成监督学习所需的
(输入序列, 输出目标)样本对。例如,使用过去30天的数据作为输入序列,来预测第31天的值。 - 模型搭建:搭建一个以LSTM或GRU为核心的RNN模型。模型的输入是历史数据序列。
- 预测输出:模型的输出层,通常是一个或多个全连接层,用于将RNN的最终隐藏状态,回归到我们想要预测的具体数值上。
- 数据准备:将一维的时间序列数据,转换成监督学习所需的
小结
在本章中,我们深入探索了循环神经网络(RNN)那理解序列的独特智慧。我们从RNN最基础的循环结构和隐藏状态出发,直面了其在处理长序列时遇到的梯度消失/爆炸这一核心挑战。
为了克服这一“阿喀琉斯之踵”,我们详细解构了长短期记忆网络(LSTM)那精巧绝伦的三大门控机制,以及其优雅的简化版——门控循环单元(GRU)。我们看到,正是这些“门”的设计,使得信息得以在时间的“高速公路”上选择性地流动,从而实现了对长期依赖的有效捕捉。
接着,我们学习了如何通过双向和深度(堆叠)的连接方式,来构建更强大的序列模型,使其能够同时感知过去与未来,并学习到更深层次的抽象特征。最后,我们将这些强大的工具应用于两大核心领域:自然语言处理(如文本分类)和时间序列预测,将理论知识转化为了解决实际问题的能力。
掌握了RNN,读者便拥有了与时间对话、理解序列之美的钥匙。然而,序列建模的探索并未止步于此。在下一章,我们将见证一场新的革命——注意力机制与Transformer的崛起,看它们是如何颠覆RNN的循环范式,将序列处理的性能与效率推向一个全新的高峰。
第九章:注意力机制与Transformer —— 现代NLP的基石
挣脱“循环”的枷锁
在上一章中,我们深入探索了循环神经网络(RNN)及其强大的变体LSTM和GRU。它们通过精妙的循环结构和门控机制,赋予了神经网络宝贵的“记忆”能力,在序列建模领域取得了巨大的成功。然而,这种成功的背后,也隐藏着其与生俱来的“枷锁”。
首先,RNN顺序处理的本质,使其天生难以并行计算。要计算第 t 个时间步的状态,必须先等待第 t-1 个时间步计算完成。在GPU大行其道的今天,这种串行依赖极大地限制了模型在长序列上的训练效率。其次,无论是简单RNN还是复杂的LSTM,它们在处理完一个长序列后,都试图将其全部信息压缩成一个固定大小的上下文向量。这就像要求一位翻译在听完一整段长篇演讲后,仅凭脑中的一个最终印象就开始翻译,不可避免地会造成信息瓶颈,尤其是对于那些遥远的、细节的信息。
为了打破这一瓶颈,注意力机制(Attention Mechanism)的曙光初现。它最初是作为对RNN信息瓶颈的一种补充疗法而提出的,其核心思想是:在生成输出的每一步,不再只依赖于那个固化的最终印象,而是允许模型“回头看”,并动态地、有选择地聚焦于输入序列中与当前任务最相关的部分。
然而,一场更彻底的革命正在酝酿。2017年,一篇名为《Attention Is All You Need》的论文横空出世,它提出了一个石破天惊的观点:我们或许根本不需要RNN的循环结构。我们可以完全抛弃“循环”,仅依靠注意力机制,来构建一个性能更强、并行能力更好、能够完美捕捉长距离依赖的序列模型。这个模型,就是伟大的Transformer。
Transformer的诞生,彻底重塑了自然语言处理(NLP)的版图。在本章中,我们将深入这场革命的核心。我们将从注意力机制的本质思想出发,详细解构Transformer这座由自注意力、多头注意力和位置编码等核心部件构成的宏伟建筑。随后,我们将见证由它催生的预训练语言模型(如BERT、GPT)是如何开启了NLP的全新范式,并最终一窥其强大的影响力,是如何跨越模态的界限,在计算机视觉领域掀起新一轮的浪潮。
现在,让我们一同挣脱“循环”的枷锁,进入这个由“注意力”主宰的、更高效、更强大的新世界。
9.1 注意力机制:从关注“全部”到聚焦“重点”
在深入Transformer的宏伟架构之前,我们必须首先理解其最核心的灵魂——注意力(Attention)机制。它并非一个具体的模型,而是一种通用的、强大的思想。这种思想的引入,是深度学习从处理静态数据,到真正理解复杂、动态上下文关系的一次关键跃迁。
9.1.1 核心思想:源于人类的认知直觉
人类视觉注意力的比喻 要理解注意力机制,最好的起点是反观我们自身。想象一下,当您看到下面这张复杂的图片时,您的大脑是如何处理它的?

您并不会在同一瞬间,以同等的精力去处理图片中的每一个像素。相反,您的视觉系统会进行一次快速的、无意识的扫描,然后您的注意力会迅速聚焦于某些您认为重要的区域。如果您想过马路,您的注意力会集中在来往的车辆和交通信号灯上;如果您想找一家咖啡店,您的注意力则会锁定在各种店铺的招牌上。
这种有选择性地聚焦于关键信息,而忽略次要信息的能力,就是人类认知系统高效工作的核心秘诀。我们的大脑资源是有限的,注意力机制帮助我们将这些宝贵的资源,动态地分配到最需要的地方。
突破信息瓶瓶颈 现在,让我们回到上一章讨论的RNN及其在处理长序列时的困境。一个经典的基于RNN的“编码器-解码器”模型在进行机器翻译时,编码器(Encoder)会读取整个源语言句子(例如,一个20个词的德语句子),并将其所有信息强行压缩成一个固定大小的上下文向量(Context Vector)。然后,解码器(Decoder)必须仅凭这个浓缩后的向量,去生成目标语言的句子(例如,一个22个词的英语句子)。
这就像要求一位同声传译员,必须在听完一整段长达一分钟的演讲后,才能开始翻译,并且在翻译过程中,不允许他再查阅任何笔记。这显然是反直觉且低效的。无论这个上下文向量的维度有多大,它都不可避免地会成为一个信息瓶颈,尤其对于长句子而言,早期的、细节的信息很容易在反复的压缩中被“遗忘”。
注意力机制,正是为了打破这个瓶颈而设计的。
它的核心思想,就是模仿人类的认知行为,赋予解码器一种“回头看”的能力。在生成目标句子的每一个词时,解码器不再只依赖于那个单一的、固化的上下文向量。相反,它会得到一个动态的、为当前步骤量身定制的上下文向量。这个动态向量,是通过对源语言句子中所有词的表示进行一次加权求和而得到的。
而这个“权”,就是注意力权重(Attention Weights)。它代表了在生成当前目标词时,应该对源语言中的哪个词,投入多大的“注意力”。例如,在翻译德语句子 "Ich bin ein Student" 为英语时,当解码器准备生成 "student" 这个词时,注意力机制会使得源语句子中的 "Student" 这个词获得极高的注意力权重,而其他词的权重则相对较低。
通过这种方式,模型不再需要将所有信息都硬塞进一个狭小的瓶颈里。它拥有了直接访问所有输入信息源的能力,并学会了如何根据当前的需求,去动态地、有选择地聚焦于重点。
9.1.2 Query, Key, Value:注意力的三要素
为了将这种直觉转化为具体的数学模型,研究者们提出了一个非常优美且通用的计算框架。这个框架将注意力机制的计算过程,类比为一次数据库的查询(Query)操作。这个类比非常深刻,是理解所有注意力变体的关键。
在这个框架中,有三个核心的角色:Query (Q), Key (K), 和 Value (V)。
Query (Q):查询 Query 代表了我们当前的需求、意图或问题。它是驱动整个注意力过程的“主动方”。在不同的场景下,Query可以是我们想要解答的问题,是我们正在处理的某个特定对象,或者是我们下一步行动的意图。
- 在经典的Encoder-Decoder模型中:当解码器准备生成第
i个目标词时,其上一个时间步的隐藏状态h_{i-1}就扮演了Query的角色。这个h_{i-1}蕴含了“我已经生成了这些词,现在我需要什么信息来生成下一个词?”这样的查询意图。
Key (K):键 Key 代表了信息库中,每一条可供查询的记录所拥有的**“标签”或“索引”。它的主要作用,是与Query进行匹配和比较**,以衡量它所代表的那条信息,与当前查询需求的相关性或相似度。
- 在经典的Encoder-Decoder模型中:编码器在处理完整个源语言句子后,所产生的每一个时间步的隐藏状态
(h_1, h_2, ..., h_n),就扮演了Key的角色。每一个h_j都是一个“键”,代表了源句中第j个词及其上下文的信息标签。
Value (V):值 Value 代表了信息库中,每一条记录所包含的真正的信息内容。它是我们最终想要提取和利用的东西。通常情况下,Key和Value是成对出现的,Key是信息的索引,Value是信息本身。在很多模型中,为了简化,Key和Value可以是同一个东西。
- 在经典的Encoder-Decoder模型中:Value通常就等于Key,即编码器的每一个时间步的隐藏状态
(h_1, h_2, ..., h_n)。当我们通过Query和Key的匹配,确定了应该对源句中第j个词投入高度关注时,我们真正想要提取的,就是这个词的表示h_j本身。
计算三部曲 有了Q, K, V这三个要素,注意力的计算过程就可以清晰地分为三步:
-
第一步:计算相似度(Similarity Calculation) 这一步的核心,是用当前的Query,去和信息库中所有的Key进行逐一的匹配,计算出一个注意力分数(Attention Score)。这个分数衡量了Query和每个Key的相似或相关程度。计算相似度的方法有很多,最常见的有:
- 点积(Dot-Product):
score(Q, K_i) = Q^T * K_i。这是最简单、最高效的方法,也是Transformer采用的核心方法。 - 加性注意力(Additive Attention):
score(Q, K_i) = v^T * tanh(W_q*Q + W_k*K_i)。它通过一个带激活函数的前馈网络来计算分数,理论上表达能力更强,但计算更复杂。
- 点积(Dot-Product):
-
第二步:归一化分数(Score Normalization) 我们得到了一系列的注意力分数,但这些分数的大小不一,难以直接用作权重。因此,我们需要使用Softmax函数,将这些原始的分数,转换成一组和为1、非负的注意力权重(Attention Weights)
α_i。α_i = softmax(score_i) = exp(score_i) / Σ_j(exp(score_j))经过Softmax处理后,每一个α_i都代表了在当前Query下,第i个Value所应占的“注意力百分比”。所有权重加起来等于1,就像是我们总共100%的注意力,被分配到了不同的信息源上。 -
第三步:加权求和(Weighted Sum) 最后一步,就是用上一步得到的注意力权重
α_i,去对所有的Value进行加权求和,得到最终的输出。这个输出,通常被称为上下文向量(Context Vector)或注意力输出(Attention Output)。Context = Σ_i(α_i * V_i)这个最终的Context向量,是一个高度浓缩的、为当前Query量身定制的信息精华。它不再是源序列所有信息的简单平均或粗暴压缩,而是根据当前需求,从所有Value中智能地、有侧重地提取出的信息的动态融合。
通过这优美的三部曲,注意力机制挣脱了信息瓶颈的束 chiffres,为深度学习模型赋予了聚焦于重点的强大能力。它不仅是后续Transformer架构的基石,其思想本身也已经渗透到计算机视觉、推荐系统等众多领域,成为现代AI工具箱中不可或缺的一件法宝。
9.2 Transformer架构详解:注意力就是一切
2017年,Google的研究者们发表了一篇名为《Attention Is All You Need》的论文,这篇论文的标题本身,就是一句石破天惊的宣言。它所提出的Transformer模型,彻底颠覆了序列处理的传统范式,宣告了一个新时代的来临。
9.2.1 告别RNN:拥抱并行化的哲学革命
核心变革:从“时间链”到“关系网” RNN的哲学,是时间的线性叙事。它像一位史官,沿着时间轴一格一格地前进,将过去的信息不断累积、提炼,形成对当下的理解。这种模式的本质,是一条时间依赖的链条。
Transformer的哲学,则是空间的关系网络。它彻底斩断了时间的锁链,将整个序列视为一个同时存在的集合。它认为,序列中元素的意义,并非仅仅由其“前身”决定,而是由其与集合中所有其他元素之间复杂、多维的关系所共同定义。它不再问“接下来会发生什么?”,而是问“在这个整体中,每个元素与其他所有元素是如何相互关联、相互定义的?”
并行优势:计算效率的解放 这场哲学革命,直接带来了计算效率上的巨大解放。由于Transformer摒弃了RNN的循环依赖,对于一个输入序列,模型内部的计算(尤其是核心的自注意力计算)可以在所有位置上同时展开。这意味着,无论序列有多长,理论上我们都可以在一个计算步骤内,完成所有元素之间关系的建模。这种内在的并行性,完美地契合了现代GPU(图形处理器)大规模并行计算的架构,使得训练更大、更深的模型,处理更长的序列成为可能,极大地缩短了实验周期,加速了整个领域的迭代。
9.2.2 自注意力机制(Self-Attention):序列内部的深度“凝视”
自注意力,是Transformer这座神殿的中央支柱,是其所有力量的源泉。它是注意力机制的一种特殊形式,也是其最强大的应用。
“自己对自己”的注意力:概念的升华 在经典的注意力机制中,Query来自一个地方(如解码器),而Key和Value来自另一个地方(如编码器)。在自注意力中,这种区分消失了。Query, Key, 和 Value 这三个角色,都来源于同一个输入序列本身。
这意味着什么?这意味着序列中的每一个元素,都会轮流扮演**“查询者(Query)”的角色,去审视和探寻序列中包括自身在内的所有其他元素(它们同时扮演着Key和Value)**。
让我们用一个句子来具体化这个过程:The animal didn't cross the street because it was too tired.
当模型处理到 it 这个词时,自注意力机制会让 it 生成一个Query,然后这个Query会去和句子中所有词(The, animal, didn't, ..., tired, .)的Key进行匹配。通过计算,it 的Query可能会发现,与 animal 的Key相似度最高,与 street 的Key相似度较低。于是,在最终生成 it 的新表示时,模型会分配给 animal 的Value一个极高的注意力权重,而给 street 的Value一个很低的权重。
作用:构建动态的、上下文感知的词表示 通过这种“内部凝视”,自注意力机制为序列中的每一个词,都构建了一个高度动态、深度上下文感知的表示。一个词的向量表示,不再是一个在词典中固定的、静态的值(如Word2Vec),而是根据它在当前句子中与其他所有词的具体关系,被动态地“重新塑造”了。它完美地解决了语言中的**一词多义(Polysemy)和指代消解(Coreference Resolution)**等核心难题。
缩放点积注意力(Scaled Dot-Product Attention):优雅的实现 Transformer中使用的,是一种被称为缩放点积注意力的具体实现。其计算过程与我们9.1节描述的三部曲完全一致,但增加了一个看似微小却至关重要的细节——缩放(Scaling)。
计算公式:Attention(Q, K, V) = softmax( (Q * K^T) / √d_k ) * V
这里的 d_k 是Key向量(也是Query向量)的维度。为什么要进行这个缩放呢? 研究者发现,当向量维度 d_k 较大时,Q * K^T 的点积结果的方差也会随之增大,这意味着点积的结果可能会变得非常大或非常小。如果将这些悬殊的数值直接输入Softmax函数,会导致Softmax的梯度变得极其微小(即进入了梯度饱和区),这会严重阻碍模型的学习。 通过除以 √d_k 这个缩放因子,可以将点积结果的方差稳定在1左右,无论维度 d_k 如何变化,都能保证Softmax函数工作在一个更健康、梯度更稳定的区域。这是一个典型的、展现了深度学习研究中理论洞察与工程实践相结合之美的例子。
9.2.3 多头注意力(Multi-Head Attention):从不同“认知通道”审视关系
如果说自注意力机制让模型学会了“凝视”,那么多头注意力则赋予了模型一双“复眼”,使其能够从多个不同的角度,同时进行凝视。
单一注意力的局限:认知的“偏见” 只用一套Q, K, V矩阵进行自注意力计算,就好比我们只用一种标准或一个“认知通道”去理解词与词之间的关系。例如,它可能学会了关注句法上的主谓关系,但却忽略了语义上的同义关系。这种单一的视角,限制了模型捕捉信息丰富性的能力。
工作原理:分而治之,融会贯通 **多头注意力(Multi-Head Attention)**的解决方案,是一种优雅的“分而治之”策略。假设我们设定了 h 个“头”(例如,在Transformer Base模型中,h=8)。
- 投影(Projection):首先,它为每一个头,都准备了一组独立的、可学习的线性变换矩阵(权重矩阵)。它将原始的、高维的Q, K, V输入,分别通过这些矩阵,投影到
h个不同的、低维的表示子空间中。也就是说,我们得到了h组低维的(Q_i, K_i, V_i),其中i从1到h。 - 并行注意力计算(Parallel Attention):然后,在这
h个子空间中,并行地、独立地进行h次缩放点积注意力计算。每一个头,都将输出一个它自己“视角”下的注意力结果。 - 拼接与融合(Concatenation & Final Projection):最后,将这
h个头输出的结果向量拼接(Concatenate)起来,形成一个大的向量。再将这个大向量通过最后一个可学习的线性变换矩阵,将其融合并投影回模型所期望的原始输出维度。
优势:丰富的特征表示 多头机制的威力在于,它允许模型在不同的表示子空间中,同时学习和关注不同类型的关系。例如,在处理句子 The animal didn't cross the street because it was too tired. 时:
- 一个头可能学会了关注指代关系,将
it和animal强烈地关联起来。 - 另一个头可能学会了关注因果关系,将
tired和didn't cross关联起来。 - 还有一个头可能只是关注一些位置上的近邻关系。 通过这种方式,多头注意力极大地丰富了模型捕捉和整合信息的能力,使得最终的输出表示,是多个不同“专家”视角下的信息融合,从而更加全面和强大。
9.2.4 位置编码(Positional Encoding):在无序的世界中找回“顺序感”
这是理解Transformer的最后一个关键,也是一个反直觉的、天才般的设计。
并行化带来的“失忆症” 我们之前盛赞Transformer的并行计算能力,但这种能力也带来了一个致命的副作用:模型本身无法感知到序列的顺序。由于所有词都是同时被处理的,对于一个纯粹的自注意力网络来说,“猫 追 老鼠”和“老鼠 追 猫”这两个输入是完全等价的,因为它只看到了词的集合,而丢失了它们的排列顺序。这对于理解语言来说是不可接受的。
解决方案:为词语注入“位置信号” Transformer的解决方案,不是在模型结构中去处理顺序,而是在输入端,直接为每个词的嵌入向量,注入(加上)一个代表其位置信息的位置编码(Positional Encoding)向量。 这个位置编码向量,并不是一个需要学习的参数,而是根据词在序列中的绝对位置 pos,通过一组固定的、精心设计的正弦(sin)和余弦(cos)函数来生成的。 PE(pos, 2i) = sin(pos / 10000^(2i/d_model)) PE(pos, 2i+1) = cos(pos / 10000^(2i/d_model)) 其中,pos是词的位置索引(0, 1, 2, ...),i是编码向量的维度索引,d_model是模型的总维度。
设计的巧妙之处:相对位置的编码 为什么选择如此复杂的三角函数,而不是简单地给每个位置分配一个数字(如0.1, 0.2, ...)呢?这正是其设计的精妙所在:
- 唯一性:它为每个位置都生成了一个独一无二的编码。
- 相对位置信息:更重要的是,对于任意固定的偏移量
k,PE(pos+k)都可以表示为PE(pos)的一个线性函数。这意味着,词与词之间的相对位置关系,被编码在了这些向量的线性关系之中。模型不需要去记忆每个词的绝对位置,而是可以很容易地通过比较它们的编码向量,来学习到它们之间的相对距离和顺序。 - 泛化能力:这种基于函数生成的方式,使得模型理论上可以处理比训练中遇到的更长的序列。
通过将词嵌入和位置编码相加,Transformer成功地在不破坏并行计算的前提下,将序列的顺序信息无缝地融入到了模型的输入之中。
9.2.5 整体架构:编码器-解码器的精密协作
现在,我们可以将所有这些部件组装起来,一窥Transformer完整的编码器-解码器(Encoder-Decoder)架构。
编码器(The Encoder) 编码器的任务是读取并理解整个输入序列。它由N个(原论文中N=6)完全相同的编码器层(Encoder Layer)堆叠而成。 每一个编码器层,都由两个核心的子模块组成:
- 一个多头自注意力模块(Multi-Head Self-Attention)。
- 一个简单的、位置全连接的前馈神经网络(Position-wise Feed-Forward Network)。这个前馈网络由两个线性层和一个ReLU激活函数组成,它被独立地应用于每一个位置的输出上。 在每个子模块的后面,都跟随着一个**残差连接(Residual Connection)和层归一化(Layer Normalization)**操作。这与ResNet中的思想一致,极大地帮助了深层网络的训练稳定性和信息流动。
解码器(The Decoder) 解码器的任务是根据编码器对源序列的理解,来生成目标序列。它同样由N个(N=6)完全相同的解码器层(Decoder Layer)堆叠而成。 每一个解码器层,比编码器层要复杂一些,它由三个核心的子模块组成:
- 一个带掩码的多头自注意力模块(Masked Multi-Head Self-Attention)。这里的“掩码”至关重要。在训练解码器时,为了模拟真实的生成过程,我们必须防止模型在预测第
i个词时,“偷看”到第i个词之后的答案。掩码的作用,就是在自注意力计算中,将所有未来位置的注意力分数设置为负无穷,这样在Softmax之后,它们的权重就变成了0。 - 一个编码器-解码器注意力模块(Encoder-Decoder Attention)。这是连接编码器和解码器的桥梁。在这个模块中,Query来自于解码器自身(前一个自注意力模块的输出),而Key和Value则来自于编码器最终的输出。这完美地实现了我们最初描述的注意力机制:解码器根据自己当前的状态,去“查询”源序列的表示,并从中提取所需的信息。
- 一个位置全连接的前馈神经网络,与编码器中的结构相同。 同样,解码器的每个子模块后面,也都跟随着残差连接和层归一化。
通过这种精密的、由多层自注意力和前馈网络构成的结构,Transformer不仅彻底摆脱了循环的束缚,更是在序列建模的能力和效率上,达到了前所未有的新高度,为后续的AI革命奠定了坚不可摧的基石。
9.3 BERT、GPT及其他:预训练语言模型的新范式
Transformer的诞生,为自然语言处理(NLP)领域提供了一件前所未有的“神器”。然而,如何将这件神器的威力发挥到极致,还需要一场方法论上的革命。这场革命,就是**“预训练-微调”(Pre-training and Fine-tuning)**新范式的崛起,而BERT和GPT,正是这场革命中最耀眼的两面旗帜。
9.3.1 范式的转变:从“为任务从零开始”到“站在巨人的知识上”
传统范式的困境:数据饥渴与知识割裂 在预训练模型出现之前,NLP任务的主流做法是“为任务从零开始(Training from Scratch)”。即便是使用了强大的Transformer架构,针对一个具体的任务(如情感分析),我们依然需要:
- 收集大量与该任务相关的、有标签的训练数据。
- 随机初始化一个模型。
- 用这些标注数据,从头开始训练模型的全部参数。
这种范式存在两个致命的缺陷:
- 数据饥渴:深度学习模型通常需要海量的标注数据才能表现良好。但对于许多NLP任务而言,获取高质量的标注数据成本高昂且耗时。
- 知识割裂:每个任务都从零开始训练,意味着模型学到的知识是孤立的、无法迁移的。为情感分析训练的模型,对语法、常识、世界知识一无所知;为命名实体识别训练的模型,也无法理解句子的情感。我们每次都在重复地教模型一些最基础的语言知识,效率极其低下。
新范式的曙光:借鉴计算机视觉的成功经验 这场范式革命的灵感,很大程度上借鉴了计算机视觉(CV)领域的成功经验。在CV领域,研究者们早已发现在ImageNet这样的大规模数据集上预训练好的模型(如ResNet),其学到的卷积层能够捕捉到通用的视觉特征(如边缘、纹理、形状)。当面对一个新的、数据量较小的下游任务(如猫狗分类)时,研究者无需从零训练,只需在预训练好的模型基础上进行微调(Fine-tuning),用少量任务相关数据调整一下高层参数,就能取得非常好的效果。
NLP的新范式:两阶段学习 NLP的研究者们将这一思想引入了语言领域,形成了“预训练-微调”的两阶段新范式:
- 预训练(Pre-training)阶段:这是新范式的核心。我们利用互联网上唾手可得的、海量的、无标签的文本数据(如维基百科、新闻、书籍等),来训练一个巨大的Transformer模型。关键在于,我们为这个阶段设计了巧妙的自监督学习(Self-supervised Learning)任务。模型不需要人工标签,而是从文本自身中创造学习信号(例如,通过预测被遮盖的词)。通过这个过程,模型被迫去学习语言内在的、通用的规律,包括语法结构、语义信息、上下文关系,乃至海量的世界知识和常识。这个预训练好的模型,就像一个已经读过“万卷书”的、知识渊博的“通才”。
- 微调(Fine-tuning)阶段:当我们需要解决一个具体的下游任务时(如文本分类、问答系统),我们不再从零开始。我们直接加载这个预训练好的“通才”模型,并在其顶部添加一个简单的、任务相关的输出层。然后,我们用少量的、有标签的任务数据,对模型的参数进行“微调”,使其适应特定任务的需求。这个过程,就像是让一位博学的通才,针对一个专业领域进行短暂的岗前培训,他能很快上手并成为专家。
这一范式的转变,彻底解决了传统方法的两大困境。它极大地降低了对下游任务标注数据的依赖,并使得模型之间能够共享和迁移从海量数据中学到的通用语言知识,标志着NLP进入了一个全新的工业化时代。
9.3.2 BERT:深邃的“完形填空”大师
**BERT(Bidirectional Encoder Representations from Transformers)**由Google在2018年发布,它的出现,像一场风暴席卷了整个NLP领域,在几乎所有的NLP基准测试中都刷新了记录。BERT成功的秘诀,在于其对“深度双向”理解的极致追求。
核心架构:只取Transformer的“理解者” BERT的架构非常纯粹:它只使用了Transformer的编码器(Encoder)部分。它是一个天生的“理解者”而非“生成者”。它的目标,就是为输入的任意文本,生成一个深度融合了上下文信息的、高质量的向量表示。
预训练任务:迫使模型理解双向语境 BERT之所以强大,关键在于其两个独创的预训练任务:
-
掩码语言模型(Masked Language Model, MLM):这是BERT的灵魂。传统的语言模型(如GPT的前身)都是单向的,只能根据左侧的文本预测下一个词。这种单向性限制了模型对语境的理解。BERT则开创性地使用了“完形填空”的方式。在预训练时,它随机地将输入句子中15%的词元(Token)用一个特殊的
[MASK]标记替换掉,然后,模型的任务就是仅根据未被遮盖的上下文,去预测这些被遮盖住的原始词元。 例如,输入My dog is [MASK] and hairy.,模型需要预测出[MASK]的位置是cute。为了做出正确的预测,模型必须同时关注左侧的My dog is和右侧的and hairy。这种机制,迫使BERT必须学习到真正的、深度的双向语境表示。这与人类做阅读理解题的方式何其相似。 -
下一句预测(Next Sentence Prediction, NSP):为了让模型理解句子与句子之间的逻辑关系(这对于问答、对话等任务至关重要),BERT还设计了NSP任务。在预训练时,模型会接收一对句子(A, B),并需要判断句子B是否是句子A在原始文本中的下一句。50%的情况下B是真实的下一句,另外50%则是从语料库中随机选择的一个句子。这个任务,让BERT学会了捕捉篇章级别的连贯性。
通过这两个任务的联合训练,BERT成为了一个对语言有着深刻双向理解能力的模型。在微调阶段,我们可以根据不同的任务,对BERT的输出进行不同的利用。例如,对于句子分类任务,我们可以取其第一个特殊标记 [CLS] 的最终输出向量,送入一个分类器;对于序列标注任务,我们可以利用每个词元的最终输出向量。
9.3.3 GPT:雄辩的“文字接龙”天才
与BERT同年,由OpenAI发布的**GPT(Generative Pre-trained Transformer)**则走了另一条截然不同的技术路线,并最终开启了通往AIGC(人工智能生成内容)的康庄大道。
核心架构:只取Transformer的“创造者” 与BERT相反,GPT系列的架构只使用了Transformer的解码器(Decoder)部分。它是一个天生的“生成者”或“创造者”。它的核心能力,在于根据给定的上文,去预测和生成最有可能的下一个词。
预训练任务:经典的自回归语言模型 GPT的预训练任务非常经典和直接,它就是一个标准的自回归语言模型(Autoregressive Language Model)。其目标永远是:根据所有已经出现的、左侧的文本,来预测下一个词元。 例如,给定上文 The cat sat on the,模型需要预测出下一个词是 mat 的概率最高。 由于GPT采用了Transformer的解码器结构,其内部的“带掩码的自注意力”机制,天然地保证了在预测第 i 个词时,模型只能看到第 i-1 个词及其之前的内容,而无法“偷看”未来的信息。这种严格的单向性(Uni-directional),使得GPT天生就非常擅长于执行文本生成任务,从写故事、写代码到回答问题,本质上都是在做“文字接龙”。
BERT vs. GPT:哲学的分歧
- BERT是“双向编码器”,像一个阅读理解大师。它的强项在于理解,为输入的文本生成高质量的、富含上下文的表示,特别适合于**自然语言理解(NLU)**任务,如分类、实体识别、情感分析等。
- GPT是“单向解码器”,像一个写作天才。它的强项在于生成,根据给定的提示(Prompt)创造出连贯、流畅的文本,是**自然语言生成(NLG)**任务的王者。
9.3.4 模型的演进与“涌现”:从微调到提示,从量变到质变
BERT和GPT的出现,只是这场革命的序章。随后的几年,整个领域进入了一场以“规模定律(Scaling Laws)”为主导的军备竞赛。研究者发现,模型的性能,与其参数规模、数据量、计算量之间,存在着可预测的幂律关系。模型越大,似乎就越“聪明”。
模型即服务(Model as a Service)与提示(Prompting) 随着模型(特别是GPT系列,如GPT-3, GPT-4)的参数规模从数亿膨胀到数千亿甚至万亿,微调整个模型的成本变得极其高昂,甚至不再必要。一种全新的、更轻便的交互范式——提示(Prompting)应运而生。 用户发现,对于这些超大规模的语言模型(Large Language Models, LLMs),我们不再需要用成千上万的标注数据去微调它。我们只需要在输入端,用自然语言给出清晰的指令(Instruction)或上下文示例(In-context Learning),模型就能直接理解我们的意图,并完成相应的任务。 例如,要进行情感分析,我们不再需要一个情感分类数据集,只需向模型提问: "请判断以下评论的情感是正面的还是负面的:'这部电影真是太棒了!'" 模型就能直接回答:“正面的”。这种“模型即服务”的范式,极大地降低了AI的应用门槛。
能力的涌现(Emergent Abilities):当量变引发质变 更令人震惊的现象是**“涌现”**。研究者发现,当语言模型的规模跨越某个巨大的阈值之后,会突然表现出在小规模模型上完全不存在的、令人惊叹的新能力。这些能力似乎不是被直接“教会”的,而是从海量数据和巨大规模中“自发地”涌现出来的。 典型的涌现能力包括:
- 思维链(Chain-of-Thought, CoT)推理:模型不再只是给出答案,而是能像人类一样,通过一步步的逻辑推导来解决复杂问题。
- 高级代码生成:能够理解复杂的编程需求,并生成高质量、可运行的代码。
- 世界知识的运用:能够回答需要深入、多领域知识才能解答的问题。
“涌现”现象是当前AI领域最前沿、也最神秘的研究方向之一。它表明,我们可能正在从“训练模型解决特定任务”的时代,迈向一个“与通用人工智能雏形进行交互”的新时代。BERT和GPT,正是开启这扇大门的两把钥匙。
9.4 Transformer在计算机视觉中的应用:新一轮的统一
在BERT和GPT引领的浪潮席卷NLP之后,一个自然而然的问题浮现在了研究者们的脑海中:Transformer那强大的、通用的序列建模能力,能否被迁移到计算机视觉领域?这个问题在当时看来,既诱人又充满挑战。因为CV领域早已被卷积神经网络(CNN)“统治”了近十年。CNN的成功,很大程度上源于其精巧的归纳偏置(Inductive Bias),这使其在学习视觉任务时,拥有了天然的“先发优势”。
CNN的归纳偏置:为视觉而生的“专家”
- 局部性(Locality):CNN通过小的卷积核,假设了图像中的信息是局部相关的。一个像素的意义,主要由其周围的像素决定。
- 平移不变性(Translation Invariance):一个在图像左上角被识别为“猫”的模式,在右下角同样能被识别出来,因为卷积核在整个图像上是共享的。 这些偏置与我们对物理世界的直观认知高度一致,使得CNN能够以极高的数据效率(Data Efficiency)学习到强大的视觉表示。它就像一个天生的视觉专家,自带一套理解世界的方法论。
而Transformer,则是一个“无偏见”的、更加通用的学习器。它不对输入的元素做任何空间上的假设,只是一视同仁地学习它们之间的关联。让这样一个“通才”去处理图像,无异于一场豪赌。
9.4.1 Vision Transformer (ViT):当图像被视为“单词”序列
2020年,Google的研究者们发表了论文《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》,正式推出了Vision Transformer (ViT)。这篇论文的设计,充满了大道至简的智慧与勇气。它没有试图将卷积与Transformer进行复杂的融合,而是做出了一个极其大胆的宣言:我们可以完全抛弃卷积,将图像直接视为一个“单词”序列,然后用一个标准的Transformer来处理它。
核心思想:从像素网格到“图像词”序列 ViT的工作流程,优雅地将图像数据“翻译”成了Transformer能够理解的语言:
-
第一步:图像分块(Image Patching) 这是ViT最核心的、也是唯一的“图像特定”预处理步骤。它将一张输入的图像(例如
224x224像素),分割成一系列固定大小的、不重叠的小方块(Patches)。例如,如果每个Patch的大小是16x16像素,那么一张224x224的图像就会被分割成(224/16) * (224/16) = 14 * 14 = 196个Patches。 这个简单的操作,在概念上具有革命性的意义:它将一个连续的、二维的像素网格,离散化成了一个一维的**“图像词(Image Words)”序列**。 -
第二步:块嵌入(Patch Embedding) 与NLP中将单词映射为词向量类似,ViT将每一个Patch展平(Flatten)成一个一维向量(例如,
16x16x3->768),然后通过一个可学习的线性投影层(Linear Projection),将其嵌入到一个固定维度的向量空间中(例如,D=768)。这一步之后,我们就得到了一个由196个向量组成的序列,这在形式上与NLP中的词嵌入序列已经完全一样了。 -
第三步:融入位置与分类信息
- 位置编码(Positional Encoding):与NLP中的Transformer一样,为了让模型感知到Patch之间的空间顺序关系,ViT为每一个Patch嵌入向量,都加上了一个可学习的(或固定的三角函数)位置编码。
- 分类令牌([CLS] Token):借鉴BERT的设计,ViT在Patch序列的最前面,额外拼接上了一个可学习的分类令牌(Classification Token)。这个令牌不代表任何一个具体的Patch,它的作用,是在经过Transformer编码器之后,其对应的最终输出向量,将被用作整个图像的全局聚合表示,直接送入最终的分类器。
-
第四步:标准的Transformer编码器 接下来的步骤,就与我们熟悉的BERT完全一致了。这个包含了分类令牌和带位置编码的Patch序列,被直接输入一个标准的Transformer编码器中。编码器内部的多头自注意力机制,会去计算每一个Patch与所有其他Patches之间的关联强度,并据此动态地更新每个Patch的表示。
-
第五步:分类 当序列通过整个编码器后,我们只取出分类令牌所对应的最终输出向量,将其送入一个简单的多层感知机(MLP Head),进行最终的图像分类。
ViT的“反直觉”之处 ViT的自注意力机制,意味着图像左上角的一个Patch,可以直接与右下角的一个Patch进行信息交互,完全忽略了它们之间的空间距离。这彻底打破了CNN基于“局部性”的假设。ViT认为,图像中元素的关联,不应受限于空间的邻近性,一个物体的不同部分(如猫的头和尾巴)即使相距很远,也可能存在着强烈的语义关联。
9.4.2 影响与未来:一场关于“偏见”与“规模”的深刻对话
ViT的实验结果,震惊了整个AI社区,并引发了一场关于CV领域未来走向的深刻讨论。
性能:规模定律的再次胜利 实验结果揭示了一个关键的现象:
这个结果雄辩地证明了:Transformer架构中缺失的“归纳偏置”,是可以通过“规模(Scale)”来弥补的。 只要给模型看足够多的数据,它就能够自己从数据中学习到那些原本需要我们通过结构设计来“硬编码”的视觉规律。这再次验证了“规模定律”的普适性。
- 当在中小型数据集(如ImageNet-1k,约120万张图)上从零开始训练时,ViT的性能不如同等规模的CNN模型(如ResNet)。这印证了CNN归纳偏置在数据效率上的优势。在数据有限的情况下,ViT这个“通才”很难从零学到有效的视觉知识。
- 然而,当在超大规模的、私有的数据集(如Google内部的JFT-300M,约3亿张图)上进行预训练,然后再在下游任务上进行微调时,ViT的性能达到甚至超越了当时最顶尖的CNN模型。
架构的统一:通往多模态智能的基石 ViT的成功,其意义远不止于在图像分类上取得SOTA(State-of-the-Art)的性能。它最重要的贡献,在于展示了Transformer作为一种通用计算架构的巨大潜力。 在此之前,我们处理不同模态的数据,需要设计不同的“专家”模型:用CNN处理图像,用RNN/Transformer处理文本,用其他模型处理语音。ViT的出现,则预示着一种架构大一统的可能性:我们或许可以用同一种核心架构(Transformer),来统一处理文本、图像、语音、视频、表格等几乎所有类型的数据。 这种统一,为真正的**多模态人工智能(Multimodal AI)**奠定了坚实的基础。我们可以想象,未来的模型,其输入不再是单一的文本或图像,而是一个由“文本词元”、“图像词元”、“语音词元”混合组成的序列。模型内部的自注意力机制,将能够无差别地学习这些不同模态“词元”之间的跨模态关联。例如,它能理解图像中的一只狗,与文本中“毛茸茸的朋友”之间的指代关系。这正是通往更接近人类智能的、更通用的人工智能的必由之路。
后续发展:CNN与Transformer的融合与超越 ViT的出现并非终点,而是开启了一场CV架构的“文艺复兴”。后续的研究,沿着两条主线展开:
- 改进ViT:研究者们发现,纯粹的ViT在处理密集预测任务(如分割、检测)时存在困难,因为它的特征图分辨率单一。因此,出现了如Swin Transformer等模型,它们通过引入层级化结构(Hierarchical Structure)和窗口化注意力(Windowed Attention),将CNN中多尺度特征图的优点与Transformer的长距离依赖建模能力巧妙地结合起来,在各种视觉任务上取得了全面的领先。
- 革新CNN:ViT的成功,也反过来激发了对CNN架构的重新思考。研究者们开始借鉴Transformer的设计思想(如大卷积核、类似Inverted Bottleneck的结构)来现代化CNN,诞生了如ConvNeXt等模型,证明了纯粹的卷积网络在经过精心设计后,依然能与Transformer分庭抗礼。
这场由ViT掀起的浪潮,至今仍在奔涌。它不仅为计算机视觉带来了新的SOTA模型,更重要的是,它打破了我们对“如何看世界”的固有思维,推动了整个AI领域向着更通用、更统一、更强大的多模态未来,迈出了决定性的一步。
小结
在本章中,我们踏上了一场从“循环”到“注意”,再到“统一”的革命性旅程。我们首先深入剖析了注意力机制这一源于人类认知直觉的深刻思想,理解了其如何通过Query-Key-Value框架,打破了RNN的信息瓶颈。
接着,我们详细解构了现代AI的基石——Transformer架构。我们见证了它如何通过自注意力和多头注意力机制,彻底摆脱了序列化处理的束缚,实现了高效的并行计算;并通过巧妙的位置编码,找回了丢失的顺序感。
随后,我们探讨了由Transformer催生的**“预训练-微调”新范式。我们对比了BERT这位深邃的“双向理解大师”和GPT这位雄辩的“单向生成天才”,并目睹了在“规模定律”的驱动下,大语言模型如何从需要“微调”的专家,演化为只需“提示”的通才,并展现出惊人的“涌现”能力**。
最后,我们将目光投向了视觉领域,见证了Vision Transformer (ViT)如何勇敢地将图像“翻译”为序列,挑战了CNN长达十年的统治地位。ViT的成功,不仅证明了规模可以弥补归纳偏置的不足,更重要的是,它为用一种统一的架构处理多模态数据铺平了道路,预示着一个更通用、更强大的人工智能时代的到来。
掌握了Transformer,读者便掌握了通往现代AI几乎所有前沿领域的钥匙。在接下来的章节中,我们将探索更多由这些基础模型衍生出的、令人兴奋的应用领域。
第十章:生成式模型 —— 创造与想象
从“理解”到“创造”的飞跃
在本书前面的章节中,我们投入了大量的精力,去教会机器如何“理解”这个世界。我们训练模型去识别图像中的物体、理解文本中的情感、预测时间序列的走向。这些任务的核心,是让模型学会分辨与判断。这类模型,我们称之为判别式模型(Discriminative Models)。我们可以将一个优秀的判别式模型,比作一位学识渊博的**“艺术评论家”。他能清晰地告诉您,一幅画是属于梵高的后印象派,还是属于莫奈的印象派。他学习的是不同类别之间的决策边界**。
然而,人工智能的梦想不止于此。除了理解和分辨,我们更渴望赋予机器一种更深层次的能力——创造与想象。我们希望模型不仅仅是“评论家”,更能成为“艺术学徒”,甚至“艺术家”。我们希望它在看尽了梵高的所有画作之后,能够领悟其风格的精髓,然后画出一幅全新的、世界上从未存在过的、但又充满了旋转星空和炽热向日葵风格的画作**。这种学习数据内在规律并创造新数据的模型,就是生成式模型(Generative Models)。
生成式模型的终极目标,是学习真实数据背后那个难以捉摸的、高维的概率分布,并能从中进行采样(Sampling),从而实现“无中生有”的魔力。这扇门一旦打开,人工智能便不再仅仅是分析工具,而是演化为了可以与我们共同创作的、强大的创造力伙伴。
在本章中,我们将一同探索三条通往“创造”的伟大路径,它们代表了三种不同的哲学思想与技术实现:
- 生成对抗网络(GAN):一场由“伪造者”与“鉴赏家”上演的、永无休止的进化博弈。
- 变分自编码器(VAE):一次充满概率美学、试图为纷繁世相构建一个优雅“潜在基因库”的尝试。
- 扩散模型(Diffusion Models):一门如同时光倒流般,从一片混沌噪声中,逐步“雕刻”出高清杰作的逆向艺术。
准备好进入这个由数据、概率和算法构成的、充满无限可能的新世界了吗?让我们一同开启这趟旅程,见证机器如何开始“做梦”。
10.1 生成对抗网络(GAN):一场永恒的进化博弈
2014年,当伊恩·古德费洛(Ian Goodfellow)和他的同事们提出生成对抗网络(GAN)时,或许连他们自己也未曾预料到,这个源于一个巧妙思想实验的模型,将会在未来数年内,成为生成式AI领域最耀眼的明星,并催生出无数令人惊叹的“深度伪造”杰作。GAN的魅力,不在于其复杂的数学,而在于其背后那简单、深刻、且充满戏剧性的博弈思想。
10.1.1 核心思想:源于博弈论的“二人零和游戏”
-
伪造者与鉴赏家的比喻 要理解GAN,我们必须先在脑海中上演一出精彩的对手戏。这场戏有两个主角:
- 生成器(Generator, G):一位技艺精湛的**“艺术伪造者”**。他从未见过真正的传世名画,但他拥有一本“灵感之书”(一个随机噪声源)。他的毕生追求,就是利用这些灵感,凭空创造出能够以假乱真的赝品画作。
- 判别器(Discriminator, D):一位眼光毒辣的**“艺术鉴赏家”**。他的工作,就是鉴定送到他面前的画作。他既能接触到博物馆里的真品,也会看到伪造者送来的赝品。他的目标,是尽可能精准地分辨出哪些是“真迹”,哪些是“赝品”。
-
对抗训练(Adversarial Training):在博弈中共同进化 GAN的训练过程,就是这两位主角之间一场永无休止的、相互驱动的“二人零和游戏”。
- 第一回合:鉴赏家学习。在游戏初期,伪造者技艺拙劣,其作品(如一堆杂乱的像素)漏洞百出。我们固定住伪造者的水平,然后让鉴赏家同时观看真品和这些粗劣的赝品。鉴赏家会很快学会分辨二者的区别,例如,“真品都有清晰的轮廓,而赝品没有”。
- 第二回合:伪造者进化。现在,我们固定住这位刚刚变得更“聪明”的鉴赏家。伪造者开始调整自己的技法,他的目标只有一个:“欺骗”这位鉴赏家。他会根据鉴赏家给出的“反馈”(梯度信息),去生成那些最有可能被鉴赏家误判为“真”的作品。例如,他会学着去创造带有清晰轮廓的图像。
- 螺旋上升:这个过程周而复始。鉴赏家在见识了更逼真的赝品后,被迫提升自己的鉴定标准,去发现更细微的破绽;而伪造者在面对更挑剔的鉴赏家时,也被迫磨练自己的技艺,创造出更完美的赝品。
在这个共同进化、螺旋上升的过程中,双方的能力都得到了极大的提升。最终,理想的结局是,伪造者的技艺达到了出神入化的地步,他创造出的赝品与真品别无二致,以至于最顶级的鉴赏家也只有50%的概率能猜对(相当于随机猜测)。此时,我们说系统达到了纳什均衡(Nash Equilibrium)。而这个技艺高超的伪造者——生成器G,就成了我们梦寐以求的、强大的生成模型。
10.1.2 模型架构与训练过程
现在,让我们将这个比喻翻译成神经网络的语言。
-
生成器(Generator)
- 输入:一个从简单概率分布(如100维的标准高斯分布)中随机采样的潜在向量(Latent Vector)
z。这个向量z,就是伪造者的“灵感种子”。每一个不同的z,都将对应一个不同的生成结果。 - 结构:生成器的网络结构,通常是一个**“放大”的过程。它与我们熟悉的CNN分类器正好相反。它采用转置卷积(Transposed Convolution,常被不准确地称为反卷积)或上采样(Upsampling)**操作,将输入的低维
z向量,一层层地放大尺寸、丰富细节,最终生成一个与真实数据维度相同的人造数据(例如,一张64x64x3的彩色图像)。
- 输入:一个从简单概率分布(如100维的标准高斯分布)中随机采样的潜在向量(Latent Vector)
-
判别器(Discriminator)
- 输入:一笔数据,它有50%的概率是来自真实数据集的真样本
x,有50%的概率是来自生成器的假样本G(z)。 - 结构:判别器通常就是一个标准的卷积神经网络(CNN)分类器。它接收一张图像,通过一系列卷积、池化层提取特征。
- 输出:与普通多分类器不同,判别器的输出层只有一个神经元,并使用Sigmoid激活函数。它输出一个介于0和1之间的标量(概率值),代表模型判断输入数据为**“真”**的概率。输出1代表“绝对是真”,输出0代表“绝对是假”。
- 输入:一笔数据,它有50%的概率是来自真实数据集的真样本
-
价值函数(Value Function)与优化目标 GAN的对抗过程,可以通过一个统一的**最小最大化(Minimax)**目标函数来描述:
min_G max_D V(D, G) = E_{x~p_data(x)}[log D(x)] + E_{z~p_z(z)}[log(1 - D(G(z)))]让我们来拆解这个看似复杂的公式:
- 训练判别器D(
max_D V(D, G)):当训练判别器时,我们希望最大化这个价值函数。- 对于真实样本
x,D(x)应该趋近于1,log D(x)趋近于0。 - 对于生成样本
G(z),D(G(z))应该趋近于0,log(1 - D(G(z)))趋近于0。 - 因此,最大化
V(D, G),就是在训练判别器将真实样本判断为1,将生成样本判断为0。这正是“鉴赏家”的职责。
- 对于真实样本
- 训练生成器G(
min_G V(D, G)):当训练生成器时,我们希望最小化这个价值函数。生成器无法影响第一项log D(x),它只能影响第二项。它希望自己生成的样本G(z),被判别器D判断为“真”,即D(G(z))趋近于1。当D(G(z))趋近于1时,log(1 - D(G(z)))会趋近于负无穷,从而最小化了V(D, G)。- 实践中的技巧:在实践中,最小化
log(1 - D(G(z)))在早期梯度较小,训练困难。因此,通常会将其替换为一个等价的、但梯度表现更好的目标:最大化log D(G(z))。这在直觉上更容易理解:生成器的目标,就是最大化其生成样本被判别器判断为“真”的对数概率。
- 实践中的技巧:在实践中,最小化
- 训练判别器D(
10.1.3 挑战与演进
GAN的训练过程如同一场精密的舞蹈,稍有不慎就会失衡。其训练的不稳定性是出了名的,主要体现在以下几个方面:
-
模式崩溃(Mode Collapse) 这是GAN最常见的失败模式之一。想象一下,如果伪造者偶然发现,他画的某一种“猫”(比如一只特定的布偶猫)能够稳定地骗过当前的鉴赏家。出于“偷懒”,他可能会停止探索其他画法,开始反复地、只生成这一种布偶猫。结果就是,生成器虽然能产生高质量的图像,但生成结果极其缺乏多样性。它只学会了真实数据分布中的一个或少数几个“模式(Mode)”。
-
梯度消失/爆炸 对抗训练的平衡非常脆弱。
- 如果判别器过于强大,它能轻易地分辨真假,给出的概率总是接近1或0。这会导致
log(1 - D(G(z)))的梯度变得非常小,生成器接收不到有效的学习信号,如同一个学徒面对一位从不指点、只会说“不对”的严师,完全无法进步。 - 反之,如果判别器过于弱小,无法提供有区分度的反馈,生成器也会迷失方向。
- 如果判别器过于强大,它能轻易地分辨真假,给出的概率总是接近1或0。这会导致
为了解决这些问题,研究者们提出了大量的GAN变体,其中一些是具有里程碑意义的:
-
DCGAN (Deep Convolutional GAN) DCGAN是第一个将深度卷积网络成功且稳定地应用于GAN的模型。它并非提出了全新的理论,而是为GAN的训练提供了一套极其宝贵的网络结构设计和超参数设置的“最佳实践”,例如:用转置卷积替代上采样、在生成器和判别器中都使用批归一化(Batch Normalization)、移除全连接层、在生成器中使用ReLU激活函数而在判别器中使用LeakyReLU等。这些准则,极大地提升了GAN的训练稳定性和生成质量,是GAN从理论走向实用的关键一步。
-
WGAN (Wasserstein GAN) WGAN从理论层面,为解决GAN的训练不稳定性提供了深刻的洞见。它指出,原始GAN所优化的目标,等价于最小化真实分布与生成分布之间的JS散度。而当两个分布没有重叠时,JS散度是一个常数,这会导致梯度消失。 WGAN提出,转而使用Wasserstein距离(又称“推土机距离”)来度量两个分布的差异。Wasserstein距离即使在分布不重叠时,也能提供有意义的、平滑的梯度。为了实现这一点,WGAN对判别器(在WGAN中被称为“评论家(Critic)”)的结构进行了修改(如移除最后的Sigmoid层),并引入了权重裁剪(Weight Clipping)或梯度惩罚(Gradient Penalty)等技巧,来满足理论所需的“利普希茨连续性”条件。WGAN的出现,极大地缓解了模式崩溃问题,并使得训练过程与生成质量之间的关联性更强。
-
Conditional GAN (cGAN) 原始的GAN是一种无条件的(Unconditional)生成模型,我们无法控制它具体生成什么内容。条件生成对抗网络(cGAN)则通过引入条件信息
y(例如,图像的类别标签、一段文本描述),实现了可控生成。 其实现方式非常直观:将条件信息y,同时输入给生成器和判别器。- 生成器接收噪声
z和条件y,学习生成符合y描述的样本G(z|y)。 - 判别器接收样本(真或假)和条件
y,学习判断该样本是否既“真实”又“与条件y相符”。 cGAN的出现,使得GAN的应用场景被极大地拓宽了。我们可以指定模型“请生成一只虎斑猫的图像”,或者在后续更复杂的模型中,根据一段详细的文字描述来生成图像。
- 生成器接收噪声
10.2 变分自编码器(VAE):概率生成的美学
与GAN那充满戏剧性的诞生故事不同,VAE植根于更深厚的概率图模型和变分推断的土壤。它不追求生成最锐利、最以假乱真的图像,而是致力于构建一个平滑、连续、且富有意义的潜在空间(Latent Space)。我们可以将这个潜在空间,想象成一个物种的“基因库”。库中的每一个点,都对应一个“个体”;而点与点之间的平滑过渡,则对应着物种的平滑演化。VAE的目标,就是为我们所观察到的纷繁复杂的数据(如人脸图像),构建出这样一个优雅的“潜在基因库”。
10.2.1 核心思想:从“完美复刻”到“神似即可”
要理解VAE的精髓,我们必须先回顾它的前身——标准自编码器(Autoencoder, AE)。
-
回顾自编码器(Autoencoder, AE) 一个标准的自编码器,由两部分组成:
- 编码器(Encoder):它像一个“压缩程序”,接收一个高维的输入数据
x(如一张图片),并将其压缩成一个低维的潜在编码(Latent Code)z。 - 解码器(Decoder):它像一个“解压程序”,接收潜在编码
z,并尝试将其重构出与原始输入x一模一样的x'。 AE的训练目标,就是最小化重构误差(即x与x'之间的差距)。它是一个强大的非线性降维工具。然而,AE的潜在空间z,是不连续、不规则的。如果在它的潜在空间中随机取一个点,然后用解码器进行解码,通常只会得到一堆毫无意义的乱码。这是因为AE只学会了如何对训练数据中的特定点进行编码和解码,而对这些点之间的“空白区域”一无所知。因此,标准AE无法用于生成新样本。
- 编码器(Encoder):它像一个“压缩程序”,接收一个高维的输入数据
-
VAE的概率化改造:为潜在空间注入灵魂 VAE的革命性创举,就是对编码过程进行了概率化的改造。它不再认为一个输入
x应该对应一个确定的、唯一的潜在编码点z。相反,它认为一个输入x应该对应潜在空间中的一个概率分布。 具体来说,VAE的编码器不再直接输出一个向量z,而是输出两个向量:这个概率分布的均值向量μ和对数方差向量log(σ²)。这两个向量,共同定义了一个高斯分布N(μ, σ²)。然后,我们从这个专属于x的分布中,随机采样一个点z,再送入解码器进行重构。 -
潜在空间的正则化:构建“创世地图” 仅仅进行概率化改造还不够。VAE最关键的一步,是通过一个巧妙设计的损失函数,对编码器施加了一个强大的约束:它要求所有输入
x所编码出的这些概率分布N(μ, σ²),都必须尽可能地靠近标准正态分布N(0, 1)(一个以原点为中心、各个维度相互独立的高斯分布)。 这个约束,就像一股强大的引力,将潜在空间中原本离散、混乱的各个“岛屿”(不同数据点的编码分布),拉扯、规整成一片连续、平滑、且结构良好的“大陆”。这片大陆的中心是原点,并且大部分区域都被数据所覆盖,没有无法解码的“无人区”。 如此一来,我们便得到了一张完美的“创世地图”。任何从这张地图的中心区域(即标准正态分布)随机采样出的一个点z,通过解码器,都能生成一个看起来“合理”的、全新的样本。生成能力,由此诞生。
10.2.2 模型架构与损失函数
-
编码器(Encoder) 其结构与标准AE的编码器类似(如一系列卷积层),但它的最终输出是两个独立的向量:均值向量
μ和对数方差向量log(σ²)。输出对数方差而不是直接输出方差σ²,是为了保证方差值为正,并增加训练的数值稳定性。 -
采样(Sampling)与重参数化技巧 接下来,我们需要从编码器定义的分布
N(μ, σ²)中采样一个z。然而,“采样”这个操作本身是随机的,不可微分的,这意味着梯度无法从解码器回传到编码器。这是一个致命的问题。 VAE使用了一个被称为**重参数化技巧(Reparameterization Trick)**的天才方法来解决它。我们不直接从N(μ, σ²)中采样,而是换一种等价的方式:- 首先,从一个固定的、与模型参数无关的标准正态分布
N(0, 1)中采样一个随机噪声ε。 - 然后,通过
z = μ + σ * ε(其中σ = exp(0.5 * log(σ²)))来计算z。 通过这种方式,随机性被转移到了ε这个外部输入上,而z与模型参数μ和σ之间的计算路径是完全确定的、可微分的。梯度得以顺利地反向传播。
- 首先,从一个固定的、与模型参数无关的标准正态分布
-
解码器(Decoder) 其结构与GAN的生成器类似(如一系列转置卷积层),它接收一个从潜在空间采样出的向量
z,并尽力将其重构为原始的输入图像x。 -
双重损失函数:在“复刻”与“泛化”间寻求平衡 VAE的损失函数,完美地体现了其设计哲学。它由两个部分相加而成:
- 重构损失(Reconstruction Loss):这部分与标准AE的目标一致,即衡量解码器重构出的图像
x'与原始图像x之间的差距。对于图像,通常使用均方误差(MSE)或二元交叉熵(Binary Cross-Entropy)。这一项损失,驱动模型去学习有意义的编码,保证“复刻”得足够像。 - KL散度损失(KL Divergence Loss):这是VAE的灵魂。它使用KL散度来衡量编码器输出的分布
N(μ, σ²)与我们期望的标准正态分布N(0, 1)之间的“距离”。这一项损失,扮演着一个正则化项的角色,它惩罚那些偏离标准正态分布太远的编码分布,迫使潜在空间变得规整、连续,保证了模型的“泛化”与生成能力。
- 重构损失(Reconstruction Loss):这部分与标准AE的目标一致,即衡量解码器重构出的图像
VAE的训练过程,就是在“尽可能地完美重构(降低重构损失)”和“尽可能地让潜在空间规整(降低KL散度损失)”这两个目标之间,寻找一个最佳的平衡点。
10.2.3 VAE vs. GAN:两种哲学的对比
VAE和GAN是生成模型领域最经典的两条路线,它们的对比,能让我们更深刻地理解各自的特点:
- 生成质量:GAN由于其对抗性训练机制,会无情地惩罚任何模糊、不真实的结果,因此通常能生成更清晰、更锐利、细节更丰富的图像。而VAE的目标是最大化数据的对数似然下界,这使其倾向于生成更“安全”、更“平均”的结果,图像往往更平滑,但有时会显得有些模糊。
- 训练稳定性:VAE的训练过程是非常稳定的,因为它本质上只是在优化一个固定的、定义明确的损失函数。而GAN的训练是寻找纳什均衡的过程,充满了动态博弈,极易出现模式崩溃等不稳定的问题。
- 潜在空间的质量:这是VAE最大的优势。它显式地学习了一个结构化、平滑且有意义的潜在空间。我们可以在这个空间中进行插值操作(例如,将一张笑脸的编码和一张不笑的人脸编码进行线性插值,可以得到一系列表情逐渐变化的平滑过渡图像),或者探索不同维度对生成结果的影响(如控制发色、年龄等)。而GAN的潜在空间通常是“纠缠”的,其结构不明确,不易进行有意义的操纵。
总而言之,如果追求极致的生成逼真度,GAN可能是更好的选择;而如果您更看重训练的稳定、可控性,以及一个富有解释性的潜在空间,VAE则展现出其独特的概率之美。
10.3 扩散模型(Diffusion Models):从噪声中雕刻杰作
读者朋友们。我们已经探索了GAN的对抗世界和VAE的概率空间。现在,我们将要进入一片近年来异军突起、并迅速席卷整个生成领域的全新大陆。这里的创造法则既不同于博弈,也不同于编码,它源于一种更物理、更直观的过程——有序地破坏,再逆向地重构。这,就是扩散模型(Diffusion Models)的艺术。
在2020年之后,一类被称为扩散模型(Denoising Diffusion Probabilistic Models, DDPMs)的生成模型,以其无与伦比的生成质量和稳定的训练过程,迅速从学术界的宠儿,成为了驱动DALL-E 2、Midjourney、Stable Diffusion等顶级文生图应用的幕 灵感来源:非平衡热力学 扩散模型的灵感,源于物理学中的非平衡热力学。想象一滴墨水滴入一杯清水中,墨水分子会自发地、随机地向四周扩散,直到最终均匀地分布在整杯水中,系统达到最大熵的无序状态。扩散模型做的,就是模仿这个过程,然后再学习如何将这个过程“倒带*。
-
前向过程(Forward Process / Diffusion Process):走向混沌 这是扩散模型中一个固定的、无需学习的、纯粹的数学过程。
- 我们从一张真实的、清晰的图像
x_0开始。 - 我们定义一个很长的时间步长
T(例如,T=1000)。 - 在每一个时间步
t(从1到T),我们都向上一时刻的图像x_{t-1}中,添加少量、可控的高斯噪声,得到x_t。这个过程由一个固定的方差调度表β_t来控制,保证了每一步添加的噪声量是预先定义好的。 - 这个过程重复
T次之后,原始的、信息丰富的图像x_0,会逐渐变得模糊,最终在t=T时,完全变成一张纯粹的、无意义的、与原始图像无关的标准高斯噪声图像x_T。
这个前向过程的美妙之处在于,由于每一步添加的都是高斯噪声,我们可以推导出一个封闭解(Closed-form Solution):对于任意一个时间步
t,我们都可以直接通过x_0和t,一步计算出x_t的样子,而无需从头模拟t次。这为后续高效的训练奠定了基础。 - 我们从一张真实的、清晰的图像
-
反向过程(Reverse Process / Denoising Process):重塑秩序 这才是模型真正需要学习的核心部分,混沌的噪声中,恢复出一张清晰、逼真、且从未见过的图像
x_0。 -
学习的目标:预测噪声,而非图像 直接让模型从带噪图像
x_t预测出更干净的x_{t-1}是困难的。一个更巧妙、也更有效的学习目标是:在反向过程的每一个时间步t,让模型去预测出在当前这张带噪图像x_t中,所包含的噪声ε是什么。 这个任务相对更简单、更明确。只要模型能够精准地预测出我们当初在前向过程中添加的噪声ε,我们就可以轻易地从x_t中“减去”这个噪声的影响,从而得到一个对x_{t-1}的良好估计。这个过程,就像一位技艺高超的雕塑家,他不是在凭空创造,而是在一块混沌的石料(带噪图像)中,精准地“凿去”那些多余的部分(噪声),从而让内藏的杰作(干净图像)显现出来。
10.3.2 训练与生成
-
模型架构:U-Net的回归 在扩散模型中,用于预测噪声的神经网络,最经典、最主流的架构是U-Net。U-Net最初是为医学图像分割设计的,其特点是拥有一个对称的“编码器-解码器”结构,并且在编码器的下采样路径和解码器的上采样路径之间,存在着跳跃连接(Skip Connections)。这种结构,使得模型既能捕捉到图像的全局上下文信息,又能保留精细的局部细节,非常适合于进行像素级别的噪声预测。在现代扩散模型中,U-Net的内部通常还会融入自注意力模块,以增强其对长距离依赖的建模能力。
-
训练过程 扩散模型的训练过程非常稳定且高效:
- 从训练集中随机抽取一张真实图像
x_0。 - 随机选择一个时间步
t(在1到T之间)。 - 从标准高斯分布中采样一个噪声
ε。 - 利用前向过程的封闭解,直接计算出在
t时刻的带噪图像x_t。 - 将
x_t和时间步t(t通常会被编码成一个向量)一起输入到U-Net模型中。 - 模型的损失函数,就是U-Net预测出的噪声
ε_θ(x_t, t)与我们真实添加的噪声ε之间的均方误差(MSE)。 我们只需要优化这个简单的MSE损失即可,整个过程没有对抗,没有复杂的KL散度,非常稳定。
- 从训练集中随机抽取一张真实图像
-
生成(采样)过程 当模型训练好后,生成新图像的过程就是一个**迭代式的“去噪”**过程:
- 首先,从标准高斯分布中随机采样一张与目标尺寸相同的纯噪声图像,作为
x_T。 - 然后,进行一个从
t=T到t=1的循环:- 在每一个时间步
t,将当前的图像x_t和时间步t输入到训练好的U-Net模型中,得到一个对噪声的预测ε_θ(x_t, t)。 - 使用这个预测出的噪声,结合反向过程的数学公式,计算出上一个时刻的、更干净的图像
x_{t-1}。
- 在每一个时间步
- 循环结束后,
x_0就是我们最终生成的清晰图像。
- 首先,从标准高斯分布中随机采样一张与目标尺寸相同的纯噪声图像,作为
这个过程,就像看着一位隐形的雕塑家,在一块充满雪花点的屏幕上,一笔一笔地擦除噪声,最终让一幅精美的画作浮现出来,充满了仪式感和艺术感。
10.3.3 扩散模型的崛起
-
无与伦比的生成质量与多样性 扩散模型最令人称道的,就是其卓越的生成质量和多样性。在多个基准测试中,它生成的图像在保真度(Fidelity)和多样性(Diversity)上,都全面超越了最顶尖的GAN模型。它很好地避免了GAN的模式崩溃问题,能够生成覆盖整个数据分布的、丰富多彩的样本。
-
稳定的训练与强大的可控性 如前所述,扩散模型的训练过程非常稳定。更重要的是,它非常容易与条件信息相结合,实现强大的可控生成。通过将额外的条件(如类别标签,或更强大的CLIP模型编码出的文本特征)一同输入U-Net,模型就能学会在去噪的过程中,始终朝着符合条件描述的方向进行“雕刻”。这正是Stable Diffusion等文生图模型能够根据用户输入的任意文本,生成高质量图像的底层核心技术。这种引导(Guidance)技术,使得扩散模型的可控性达到了前所未有的高度。
-
缺点:慢速的“艺术创作” 扩散模型目前最主要的缺点,就是其采样速度相对较慢。因为生成一张图像,需要完整地执行上百甚至上千次的迭代去噪步骤,每一步都需要一次完整的神经网络前向传播。这与GAN只需一次前向传播就能生成图像形成了鲜明对比。不过,学术界和工业界正在积极研究各种加速采样的方法(如DDIM、减少采样步数、知识蒸馏等),并已经取得了显著的进展。
10.4 应用:当机器开始“做梦”
掌握了GAN、VAE、扩散模型这些强大的生成工具后,我们便开启了一扇通往AIGC(人工智能生成内容)时代的大门。这些模型如同被赋予了“梦境”能力的机器,其应用场景正在以前所未有的速度扩展。
10.4.1 图像生成与编辑
- 无条件生成:这是生成模型最基础的能力。例如,StyleGAN系列可以生成逼真到肉眼无法分辨的、但在现实世界中并不存在的虚拟人脸。这在虚拟形象创建、游戏角色设计、艺术创作等领域具有巨大价值。
- 文本到图像生成(Text-to-Image):这是当前最火热、也最具变革性的应用。用户只需输入一段自然语言描述(例如,“一只穿着宇航服的柯基犬,在月球上骑着一匹马,数字艺术风格”),模型(如Stable Diffusion, Midjourney)就能生成符合这段天马行空描述的、高质量的图像。这极大地降低了视觉内容创作的门槛,为广告、设计、娱乐等行业带来了颠覆性的变革。
- 图像修复(Inpainting)与扩展(Outpainting):利用生成模型对图像上下文的深刻理解,我们可以智能地填充图像中被遮挡或损坏的部分(修复),或者在现有图像的画框之外,进行富有想象力的、符合原作风格的扩展(扩展),这在照片修复、影视后期制作等领域非常有用。
10.4.2 风格迁移与变换
- 艺术风格迁移:这是生成模型一个经典且富有魅力的应用。我们可以提取一张内容图片(如一张个人照片)的内容特征,和一张艺术作品(如梵高的《星空》)的风格特征,然后让生成模型将两者结合,创造出一张既保留了照片内容、又充满了《星空》笔触和色彩风格的全新艺术品。
- 域适应(Domain Adaptation):生成模型可以在不同的数据“域”之间建立桥梁。例如,将一个领域的数据(如夏天的风景照),在保持其核心内容不变的前提下,转换成另一个领域(如冬天的风景照);或者将游戏引擎渲染出的虚拟城市场景,转换成逼真的、照片级的现实场景,这对于自动驾驶等领域的数据集扩充至关重要。
10.4.3 数据增强与半监督学习
- 数据增强(Data Augmentation):在许多现实场景中,获取大量的标注数据是昂贵的。我们可以利用生成模型,在现有的少量训练数据基础上,创造出大量新的、逼真的、且带有正确标签的训练样本。这些生成出的“假”数据,可以与真实数据混合在一起,用于训练下游的判别式模型(如分类器),从而有效提升其性能和鲁棒性。
- 异常检测:生成模型对于学习正常数据的分布非常在行。我们可以训练一个只见过“正常”样本(如健康的细胞图像、正常的工业零件)的生成模型(如VAE或GAN)。当一个“异常”样本(如癌细胞、有缺陷的零件)输入时,模型将无法很好地对其进行重构或判别,从而产生巨大的重构误差或异常的判别分数。通过这种方式,我们可以有效地识别出罕见的异常事件。
小结
在本章中,我们踏上了一段从“理解”到“创造”的奇妙旅程。我们探索了生成式模型的三大主流范式:
- 我们见证了生成对抗网络(GAN)中,“伪造者”与“鉴赏家”之间永恒的、相互驱动的进化博弈,它以其卓越的生成逼真度,开启了深度伪造的时代。
- 我们领略了变分自编码器(VAE)那充满概率美学的优雅,它致力于构建一个平滑、连续的潜在空间,为数据的可控生成与编辑提供了坚实的理论基础。
- 我们惊叹于扩散模型(Diffusion Models)那如同逆转时间般的艺术,它通过从纯粹噪声中逐步去噪、雕刻杰作的方式,将生成内容的质量和可控性推向了前所未有的新高度。
最后,我们巡礼了这些强大的生成工具在图像生成、风格迁移、数据增强等领域的广泛应用,亲身感受了当机器开始“做梦”时,所释放出的巨大创造力。掌握了生成式模型,读者不仅掌握了当前AI领域最前沿的技术,更获得了一把开启未来内容创作新纪元的钥匙。在本书的最后,我们将展望这一切技术融合后,人工智能更广阔的未来。
第四部分:实战篇 —— 从理论到价值的转化
第十一章:项目实战:计算机视觉
- 11.1 图像分类:构建一个垃圾分类系统。
- 11.2 目标检测:实现一个实时人脸或车辆检测器。
- 11.3 图像风格迁移:将照片变成梵高风格的油画。
从“看懂”到“看见”的飞跃
亲爱的读者,在过去的篇章里,我们一同跋山涉水,穿越了深度学习的理论丛林。我们曾在第七章,借助卷积神经网络(CNN)的“慧眼”,让机器学会了识别图像中的“名相”——这是猫,那是狗。我们也在第十章,通过生成模型的“神笔”,让机器拥有了无中生有的创造力。我们已经掌握了让机器“看懂”像素数据的基本法门。
然而,真正的智慧,不止于“看懂”,更在于“看见”。
“看懂”,是分辨与识别,是逻辑的判断,是对世界表象的摹写。而“看见”,是洞察与理解,是联系的建立,是对事物本质与内在规律的彻悟。正如禅宗所言,“见山是山,见水是水”是初境;“见山不是山,见水不是水”是过程;最终“见山还是山,见水还是水”,则是彻悟后的回归。我们的学习之旅,亦复如是。
本章,便是我们从“看懂”迈向“看见”的修行道场。我们将走出理论的静修室,步入真实世界的烟火人间。项目实战,它并非代码的简单堆砌,而是连接抽象模型与鲜活现实的桥梁。在这里,冰冷的算法将拥有温度,去解决环保的难题;在这里,严谨的数学将邂逅艺术,去挥洒梵高的激情。
这不仅是技术的应用,更是一场深刻的“知行合一”。每一次数据清洗,都是在磨砺我们的耐心与细致;每一次模型调试,都是在考验我们的洞察与变通;每一次成功运行,都是对我们所学知识最真切的回响。在这里,理论是罗盘,实践是航船,而我们,是驶向价值彼岸的航海家。
准备好了吗?让我们扬帆起航,开启这场以智慧之眼洞见万物的实战之旅。我们将亲手构建三个项目,它们分别代表了计算机视觉领域三个核心且迷人的方向:图像分类、目标检测与风格迁移。让我们在创造中学习,在实践中升华。
11.1 图像分类:构建一个垃圾分类系统 —— 为世界注入一份“净”
图像分类,可以说是计算机视觉领域的“Hello, World!”。它是我们学习CNN时最先接触的任务,也是无数更复杂视觉任务(如目标检测)的基石。但简单,绝不意味着不重要。恰恰相反,将最基础的技术应用于最迫切的现实问题,正是技术价值的最好体现。
11.1.1 项目缘起与价值:当AI遇见环保
-
背景 “绿水青山就是金山银山”。环境保护,已成为我们这个时代最宏大的叙事之一。而垃圾分类,是这个宏大叙事中与我们每个人息息相关的一环。它看似简单,实则挑战重重:分类标准繁多、民众认知不足、人工分拣成本高昂且效率低下。 此时,我们不禁会想:能否让机器代替人眼,去完成这项重复而又重要的工作?能否在垃圾投放口、分拣流水线上,安装一双不知疲倦、准确无误的“眼睛”?这便是我们这个项目的初心——当AI的智慧,遇见环保的迫切,我们有机会为这个世界注入一份真正的“洁净”与“效率”。
-
目标 我们的目标清晰而具体:构建一个基于深度学习的图像分类模型,该模型能够接收一张垃圾图片,并自动判断其所属类别(例如:厨余垃圾、可回收物、有害垃圾、其他垃圾)。我们将走过一个AI项目的完整生命周期,从数据准备到模型部署,体验一次完整的“价值创造”之旅。
11.1.2 数据之道:从收集到准备
在深度学习的宇宙中,数据是引燃一切的“星尘”。没有数据,再强大的模型也只是一个空壳。因此,我们的第一步,也是至关重要的一步,便是数据的获取与处理。
-
数据集的获取 对于初学者而言,最便捷的方式是使用公开数据集。TrashNet是一个广受欢迎的垃圾分类数据集,它包含了玻璃、纸张、纸板、塑料、金属和一般垃圾等类别。此外,网络上还有许多由研究者和爱好者贡献的、规模更大、类别更丰富的垃圾图像数据集。 当然,更具挑战性也更有趣的方式,是自建数据集。您可以利用Python的网络爬虫库(如
Scrapy或BeautifulSoup)从搜索引擎或图库网站上抓取特定类别的垃圾图片。这个过程本身,就是一次宝贵的工程实践。 -
数据探索与可视化(EDA) 拿到数据后,切忌直接投入训练。我们应先像一位侦探一样,仔细勘察这份数据。
- 我们有多少数据? 每个类别各有多少张图片?是否存在严重的类别不均衡问题(例如,某个类别的图片数量远少于其他类别)?类别不均衡会使模型偏向于学习样本量大的类别,导致对小样本类别的识别能力差。
- 数据质量如何? 图片是否清晰?是否存在大量标注错误或无关的图片? 通过编写简单的脚本,统计各类别数量并绘制成柱状图,再随机抽取一些样本进行人工查看,是进行数据探索的必要步骤。
-
数据预处理与增强 原始数据如同未经雕琢的璞玉,需要精心打磨才能焕发光彩。
- 图像尺寸归一化:由于数据集中的图片尺寸可能千差万别,而神经网络的输入需要固定的大小(例如224x224像素),因此我们需要将所有图片统一缩放到目标尺寸。
- 数据增强(Data Augmentation):这是应对数据量不足和防止过拟合的强大法宝。我们可以在将图片送入网络训练之前,对它们进行一系列随机的变换,生成“新”的训练样本。这就像让模型从不同的角度、在不同的光照下观察同一个物体,从而学习到更本质、更鲁棒的特征。
- 常用的增强手段包括:
- 随机水平/垂直翻转:一张“正着放”的易拉罐图片和“倒着放”的易- 拉罐图片,都应被识别为可回收物。
- 随机旋转:在一定角度范围内随机旋转图片。
- 随机裁剪与缩放:模拟物体在画面中远近不同的情况。
- 色彩抖动:随机改变图像的亮度、对比度、饱和度,模拟不同光照条件。
- 常用的增强手段包括:
幸运的是,
tf.keras.preprocessing.image.ImageDataGenerator或tf.dataAPI等工具,为我们提供了极其方便的数据加载与实时增强功能。
import tensorflow as tf
# 假设我们的数据已经按类别存放在不同文件夹中
# data_dir/
# ├── cardboard/
# ├── glass/
# └── ...
IMG_SIZE = (224, 224)
BATCH_SIZE = 32
# 使用ImageDataGenerator进行数据加载和增强
train_datagen = tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./255, # 将像素值归一化到[0, 1]
rotation_range=40, # 随机旋转角度范围
width_shift_range=0.2, # 随机水平平移范围
height_shift_range=0.2, # 随机垂直平移范围
shear_range=0.2, # 随机错切变换
zoom_range=0.2, # 随机缩放范围
horizontal_flip=True, # 随机水平翻转
fill_mode='nearest', # 填充新创建像素的方式
validation_split=0.2 # 划分20%的数据作为验证集
)
train_generator = train_datagen.flow_from_directory(
'path/to/your/data_dir',
target_size=IMG_SIZE,
batch_size=BATCH_SIZE,
class_mode='categorical',
subset='training' # 设置为训练集
)
validation_generator = train_datagen.flow_from_directory(
'path/to/your/data_dir',
target_size=IMG_SIZE,
batch_size=BATCH_SIZE,
class_mode='categorical',
subset='validation' # 设置为验证集
)
这段代码不仅优雅地解决了数据加载问题,更在无形中极大地扩充了我们的数据集,为后续训练一个强大的模型奠定了坚实的基础。数据之道,在于敬畏与精微。现在,星尘已备,是时候点燃模型的火焰了。
11.1.3 模型构建:站在巨人的肩膀上
面对一个图像分类任务,我们有两个选择:一是“白手起家”,从零开始设计并训练一个全新的CNN架构;二是“借力打力”,采用迁移学习(Transfer Learning)。
-
为何选择迁移学习 从头训练一个深度CNN模型,是一项巨大的挑战。它不仅需要海量的数据(通常是百万级别),还需要强大的计算资源和漫长的训练时间。这好比要我们自己去推演和证明牛顿三定律,虽然理论上可行,但既不高效,也无必要。
迁移学习则提供了一条充满智慧的捷径。它的核心思想是:一个在超大规模数据集(如ImageNet,包含1400多万张图片,1000多个类别)上预训练好的模型,已经学习到了关于这个世界非常通用和底层的视觉知识——比如边缘、纹理、形状、颜色等。这些知识,对于我们识别垃圾同样是适用的。
因此,我们可以“借用”这个预训练好的模型,将其强大的特征提取能力“迁移”到我们的新任务上。我们站在了巨人的肩膀上,可以用更少的数据、更短的时间,达到比从零训练好得多的效果。这是一种“他山之石,可以攻玉”的智慧。
-
选择预训练模型 Keras为我们提供了丰富的预训练模型库。选择哪一个,通常是在模型大小(参数量)、计算速度和性能之间做权衡。
- ResNet (Residual Network):经典中的经典,通过“残差连接”解决了深度网络的退化问题,性能强大且稳定。
ResNet50是一个非常均衡的选择。 - MobileNet:专为移动和嵌入式设备设计,模型小,速度快,虽然精度略有牺牲,但在资源受限的场景下是首选。
- EfficientNet:通过一种复合缩放方法,系统性地平衡了网络的深度、宽度和分辨率,在性能和效率上都达到了当时的顶尖水平。
EfficientNetB0到B7提供了一系列从轻量到庞大的选择。
对于我们的垃圾分类任务,
MobileNetV2或EfficientNetB0会是一个很好的起点,它们在保持较高精度的同时,对计算资源的要求也相对友好。 - ResNet (Residual Network):经典中的经典,通过“残差连接”解决了深度网络的退化问题,性能强大且稳定。
-
微调(Fine-tuning)策略 拿到预训练模型后,我们通常会去掉它原本用于ImageNet分类的顶层(全连接层),然后接上我们自己为垃圾分类任务设计的新的分类头。
- 加载预训练模型:加载模型,并指定
include_top=False来移除顶层。 - 冻结基础层:将预训练模型的主体部分(我们称之为“基础模型”)的权重设置为不可训练(
base_model.trainable = False)。这是迁移学习的第一步,我们先用它强大的、固定的特征提取能力,来训练我们新建的、随机初始化的分类头。 - 添加自定义分类头:在基础模型之上,添加一个
GlobalAveragePooling2D层(用于将特征图展平),再接上一个或多个Dense层,最后是一个输出层,其神经元数量等于我们的垃圾类别数,激活函数为softmax。 - 编译与初步训练:用较小的学习率编译模型,并进行初步训练。
- 解冻与微调(可选但推荐):当新的分类头训练稳定后,我们可以选择性地解冻基础模型的顶部几层(或者全部层),并用一个极低的学习率继续进行端到端的训练。这个过程,就是微调。它允许预训练好的底层特征,根据我们特定任务的数据进行微小的调整,从而更好地适应新任务,有望进一步提升模型性能。
- 加载预训练模型:加载模型,并指定
# 1. 加载预训练模型作为基础模型
base_model = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3),
include_top=False, # 不包括顶部的分类器
weights='imagenet')
# 2. 冻结基础模型
base_model.trainable = False
# 3. 添加自定义分类头
inputs = tf.keras.Input(shape=(224, 224, 3))
x = base_model(inputs, training=False) # 在推理模式下运行基础模型
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dropout(0.2)(x) # 添加Dropout防止过拟合
outputs = tf.keras.layers.Dense(len(train_generator.class_indices), activation='softmax')(x)
model = tf.keras.Model(inputs, outputs)
model.summary()
11.1.4 训练与评估:炼丹术的实战演练
模型已建,炉火已生,现在进入最关键的“炼丹”环节。
-
编译模型 在训练之前,我们需要为模型配置学习过程。
- 优化器:
Adam依然是我们的首选,它稳健且高效。初始学习率可以设置得稍低,例如0.001。 - 损失函数:对于多分类问题,
categorical_crossentropy是标准的选择(如果标签是整数编码,则使用sparse_categorical_crossentropy)。 - 评估指标:我们最关心的是
accuracy(准确率),但加入其他指标如Precision和Recall能提供更丰富的视角。
- 优化器:
-
配置回调函数(Callbacks) 回调函数是Keras中非常强大的工具,它们像是在炼丹炉旁守护的童子,可以在训练过程中的特定节点执行预设的操作。
ModelCheckpoint:在每个epoch结束后,检查验证集上的性能(如val_accuracy),并只保存迄今为止性能最好的模型权重。这是防止我们心血白费的“保险丝”。EarlyStopping:监控验证集损失val_loss,如果它在连续多个epoch(由patience参数设定)内不再下降,就提前终止训练,防止过拟合,并节约时间。ReduceLROnPlateau:监控某个指标(如val_loss),当它“停滞不前”时,自动降低学习率。这就像在下山遇到平地时,我们放慢脚步,更精细地探索。
-
结果分析 训练完成后,
model.fit()返回的history对象记录了每个epoch的训练和验证指标。将其可视化是分析模型行为的最佳方式。- 解读训练曲线:绘制训练/验证的损失和准确率曲线。理想情况下,两条曲线都应平稳收敛。如果训练损失远低于验证损失,且二者差距随时间拉大,则是明显的过拟合信号。
- 使用混淆矩阵:混淆矩阵(Confusion Matrix)能清晰地展示模型在哪些类别上表现良好,又容易将哪些类别混淆。例如,模型是否经常把“纸板”错认为“纸张”?这为我们指明了模型改进的方向(比如,增加这两类易混淆样本的训练数据)。
- 精确率、召回率、F1分数:除了总体准确率,我们还应计算每个类别的这些指标,以获得更全面的性能评估,尤其是在类别不均衡的情况下。
# 编译模型
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss='categorical_crossentropy',
metrics=['accuracy'])
# 配置回调函数
checkpoint_cb = tf.keras.callbacks.ModelCheckpoint("best_garbage_model.h5", save_best_only=True)
early_stopping_cb = tf.keras.callbacks.EarlyStopping(patience=10, restore_best_weights=True)
# 开始训练
history = model.fit(train_generator,
epochs=50, # 先训练较多轮次,让EarlyStopping决定何时停止
validation_data=validation_generator,
callbacks=[checkpoint_cb, early_stopping_cb])
11.1.5 部署与应用:让模型走出实验室
一个模型真正的价值,在于它能被应用。我们将学习如何将训练好的模型,从一个研究原型,变成一个可以提供服务的简单应用。
-
模型导出与封装 训练完成后,我们将性能最佳的模型保存为Keras的H5格式或TensorFlow的SavedModel格式。SavedModel格式更适合部署,因为它包含了完整的计算图和权重,具有更好的跨平台兼容性。
-
构建简单的Web应用 我们可以使用轻量级的Python Web框架,如Flask或FastAPI,来为我们的模型穿上一层“外衣”,让它能通过HTTP协议与外界交互。
- 基本流程:
- 创建一个Web服务。
- 定义一个API端点(例如
/predict),该端点接受用户通过POST请求上传的图片。 - 在后端,服务接收图片,进行与训练时相同的预处理(缩放尺寸、归一化)。
- 加载我们训练好的模型,对预处理后的图片进行预测。
- 将预测结果(类别名称和置信度)以JSON格式返回给用户。
这样一个简单的Web应用,就让我们的垃圾分类模型“活”了起来。任何有网络连接的设备(如手机、电脑)都可以通过访问这个服务,来使用我们的AI能力。这便是从理论到价值转化的“最后一公里”。
- 基本流程:
11.2 目标检测:实现一个实时人脸或车辆检测器
完成了图像分类,我们让机器学会了回答“这张图里有什么?”。现在,我们要更进一步,让它回答一个更复杂的问题:“这张图里的东西,都在哪里?”。这便是目标检测(Object Detection)。
11.2.1 从分类到检测:不止“是什么”,更要“在哪里”
-
任务定义 目标检测不仅要识别出图像中的物体类别(Classification),还要用一个**边界框(Bounding Box)**精确地标出它的位置(Localization)。一张图中可能包含多个不同类别的物体,模型需要将它们全部找出。
-
核心挑战 相比分类,目标检测的复杂性指数级增长。模型需要同时输出两部分信息:
- 类别概率:这个框里是猫的概率是多少?是狗的概率是多少?
- 边界框坐标:通常用框的中心点坐标(x, y)以及框的宽(w)和高(h)来表示。 模型需要在一个画面中,面对不同尺寸、不同长宽比、相互遮挡、数量不定的目标,进行高效且准确的预测。
11.2.2 主流框架与模型概览
目标检测算法主要分为两大流派:
-
两阶段检测器(Two-stage Detectors) 这类方法的思想是“先提议,后分类”,分两步走。
- 区域提议(Region Proposal):首先,通过一个独立的网络(如RPN, Region Proposal Network)快速地在图像上扫描,找出所有可能包含物体的候选区域。
- 分类与回归:然后,对这些候选区域进行精确的分类和边界框位置的微调。
- 代表:R-CNN家族,如
Fast R-CNN和Faster R-CNN。 - 特点:精度高,但因为是两步操作,速度相对较慢。
-
单阶段检测器(One-stage Detectors) 这类方法追求极致的速度与效率,它们将区域提议和分类/回归两步合二为一。
- 代表:YOLO (You Only Look Once) 和 SSD (Single Shot MultiBox Detector)。
- 思想:它们将图像划分为网格(grid),直接在每个网格上预测可能存在的物体及其边界框和类别。整个过程一气呵成,只“看”一次图像。
- 特点:速度极快,可以达到实时检测的要求,虽然早期版本的精度略低于两阶段检测器,但随着发展(尤其是YOLO系列),其精度已经非常有竞争力。
-
模型选择 在需要进行实时检测的应用场景,如视频监控、自动驾驶辅助、动态交互等,YOLO系列无疑是当今业界的王者和首选。它的设计哲学——快、准、狠——完美契合了这些需求。
11.2.3 实战YOLOv5/v8:快、准、狠的检测利器
我们将直接使用目前最流行、生态最完善的YOLOv8(由Ultralytics公司开发)来进行实战。它将复杂的模型训练和推理过程封装得极其友好。
-
环境配置与安装 安装YOLOv8非常简单,只需一行pip命令:
pip install ultralytics -
使用预训练模型进行推理 YOLOv8提供了在COCO数据集上预训练好的模型,可以识别80个常见类别。我们可以直接调用它来体验其强大的威力。
from ultralytics import YOLO # 加载一个预训练的YOLOv8n模型 (n代表nano,最小最快的版本) model = YOLO('yolov8n.pt') # 从图片进行预测 results = model('path/to/your/image.jpg') # 从视频进行预测,并实时显示结果 # results = model('path/to/your/video.mp4', show=True) # 保存预测结果 # model.predict('path/to/your/image.jpg', save=True)仅仅几行代码,一个强大的目标检测器就开始为您工作了!
-
在自定义数据集上进行训练 YOLO的真正魅力在于,我们可以很方便地用它来训练自己的检测任务(比如,检测安全帽佩戴、识别特定种类的野生动物等)。
- 准备数据集:这是最耗时的一步。您需要大量的图片,并使用标注工具(如LabelImg, CVAT)为每张图片中的每个目标物体画上边界框,并指定其类别。
- 组织数据格式:YOLO需要特定的目录结构和标签文件格式。通常是图片文件和对应的txt标签文件放在一起,txt文件中每一行代表一个物体,格式为
<class_id> <x_center> <y_center> <width> <height>(均为归一化后的值)。 - 创建YAML配置文件:您需要创建一个
.yaml文件,告诉YOLO您的训练数据在哪里、验证数据在哪里、有多少个类别以及类别的名称是什么。 - 开启训练:通过命令行或Python脚本,调用YOLO的训练功能,指定您的模型(可以从预训练模型开始微调)、数据配置文件、训练轮次等参数。
# 通过Python脚本开始训练 from ultralytics import YOLO # 加载一个预训练模型作为起点 model = YOLO('yolov8n.pt') # 训练模型 results = model.train(data='path/to/your/data.yaml', epochs=100, imgsz=640)
11.2.4 性能评估与优化
-
关键指标
- 交并比(Intersection over Union, IoU):这是衡量预测框与真实框重合程度的指标。它是预测框和真实框的交集面积除以它们的并集面积。IoU阈值(如0.5)常被用来判断一个预测是否为“正确”的。
- 平均精度均值(mean Average Precision, mAP):这是目标检测领域最核心的评估指标。它综合了模型在所有类别、不同IoU阈值和不同置信度阈值下的精确率和召回率表现,能够非常全面地衡量模型的性能。
mAP@.5表示在IoU阈值为0.5时的mAP,mAP@.5:.95表示在IoU阈值从0.5到0.95(步长0.05)区间内所有mAP的平均值。
-
结果可视化与分析 YOLO在训练结束后,会自动生成丰富的可视化结果,包括损失曲线、混淆矩阵、以及各个类别的P-R(精确率-召回率)曲线等,保存在
runs/detect/train目录下。仔细分析这些图表,是诊断模型问题、进行优化的关键。
11.2.5 应用场景探讨:从安防到自动驾驶
目标检测技术是当今AI应用最广泛的分支之一。它的身影无处不在:
- 智能安防:人脸识别门禁、异常行为检测、人群密度分析。
- 自动驾驶:实时检测车辆、行人、交通标志,是实现环境感知的核心。
- 零售行业:无人商店的商品识别、货架空缺检测、客流分析。
- 医疗影像:在CT或X光片中自动检测肿瘤、病灶等。
掌握了YOLO,您就拥有了一把打开无数计算机视觉应用大门的钥匙。
11.3 图像风格迁移:将照片变成梵高风格的油画
在完成了两个“实用主义”的项目后,让我们将目光投向一个充满创造性与美感的领域:神经风格迁移(Neural Style Transfer)。这个项目将向我们展示,深度神经网络不仅能识别世界,还能以一种令人惊叹的方式“重新诠释”世界。
11.3.1 项目构想:当神经网络成为“画家”
-
灵感来源 2015年,Gatys等人在一篇论文中首次提出了这个想法,并展示了惊人的效果:他们能将一张普通照片的内容,与梵高的《星夜》、蒙克的《呐喊》等名画的风格融合在一起,生成一幅全新的、兼具二者神韵的艺术作品。
-
核心思想 这个算法的绝妙之处在于,它认为一张图像的内容(Content)和风格(Style)是可以被神经网络分离开来,并进行量化和重组的。
- 内容:指的是图像中物体的宏观结构和排列,即“画了什么”。
- 风格:指的是图像的纹理、笔触、色彩搭配等,即“是怎么画的”。 我们的目标是,生成一张新的图像,它在“内容”上接近我们的内容图,在“风格”上接近我们的风格图。
11.3.2 VGG网络的“神启”:为何它能感知内容与风格?
算法的实现,巧妙地利用了一个在ImageNet上预训练好的VGG网络(通常是VGG16或VGG19)。研究者发现,VGG网络的不同层级,天然地学习到了对内容和风格的不同敏感度。
-
内容表示 网络的深层(靠后)特征图,由于感受野更大,捕捉到的是更全局、更抽象的信息,比如物体的轮廓和组合。因此,我们可以用VGG深层的激活值,来代表一张图像的内容。
-
风格表示 网络的浅层到深层的特征图,都包含了丰富的纹理和模式信息。风格,可以被看作是这些特征在空间上的相关性。如何衡量这种相关性?答案是格拉姆矩阵(Gram Matrix)。
- 格拉姆矩阵:对于一个卷积层的输出特征图,我们计算其不同通道(feature map)之间的内积。这个矩阵捕捉了哪些特征倾向于“同时出现”,从而量化了图像的纹理、笔触和色彩模式,成为了风格的绝佳“指纹”。我们可以利用VGG多个层(从浅到深)的格拉姆矩阵,来共同定义一张图像的风格。
11.3.3 损失函数的设计:内容、风格与正则化的三重奏
我们的目标是生成一张新图像,这张图像需要同时满足三个条件,因此,我们的总损失函数也由三部分构成:
-
内容损失(Content Loss) 计算生成图像在VGG某个深层(如
block5_conv2)的特征图,与内容图像在该层的特征图之间的均方误差。这个损失驱使生成图像在宏观内容上向内容图看齐。 -
风格损失(Style Loss) 计算生成图像在VGG多个层(如
block1_conv1,block2_conv1, ...)的格拉姆矩阵,与风格图像在对应层的格拉姆矩阵之间的均方误差之和。这个损失驱使生成图像学习风格图的纹理和笔触。 -
总变分损失(Total Variation Loss) 这是一个可选的正则化项。它计算生成图像相邻像素之间的差异。最小化这个损失,可以使得生成的图像更加平滑、自然,减少杂乱的噪点。
总损失 = α * 内容损失 + β * 风格损失 + γ * 总变分损失 其中,α, β, γ是超参数,用来权衡三者之间的重要性。
11.3.4 编码实现:一步步创造艺术
这个算法的实现过程与我们之前的项目不同。我们不训练网络,VGG的权重是固定不变的。我们优化的对象,是生成图像本身的像素值。
- 加载预训练的VGG模型,并构建一个新的模型,其输入是图像,输出是我们感兴趣的那些内容层和风格层的激活值。
- 定义内容和风格损失函数,以及总变分损失函数。
- 设置优化循环:
- 将生成图像初始化为一张白噪声图,或者直接从内容图开始。
- 将其定义为一个可训练的变量(
tf.Variable)。 - 在每一次迭代中: a. 计算总损失。 b. 根据总损失,计算生成图像像素值的梯度。 c. 使用一个优化器(如Adam),根据梯度更新生成图像的像素。
- 重复上一步数百上千次,直到生成的图像在视觉上令人满意为止。
这个过程,就像一位画家在画布上反复修改,每一次下笔,都试图让画作更接近内容草稿,同时又更符合风格的韵味。
11.3.5 成果展示与延伸思考
-
展示与探索:您可以尝试各种各样的内容图和风格图组合,比如将您的自拍照与毕加索的立体主义风格结合,将城市风景与日本浮世绘的风格结合,其结果往往充满惊喜。调整内容和风格损失的权重(α/β比值),可以控制生成图像更偏向内容还是更偏向风格。
-
延伸思考:
- 实时风格迁移:我们实现的这个基于优化的方法速度很慢,生成一张图可能需要几分钟。业界后来发展出了基于“生成器网络”的快速风格迁移(Fast Style Transfer),它通过训练一个前馈网络来直接生成风格化的图像,可以做到实时处理,但一个模型只能学习一种风格。
- AI创造力的边界:神经风格迁移引发了一个深刻的哲学问题——这究竟是“模仿”还是“创作”?机器是否拥有了“审美”?它生成的作品,其艺术价值何在?这些问题没有标准答案,但它们促使我们去思考技术与人文、智能与创造力之间复杂而迷人的关系。
小结:行是知之成
本章的旅程即将结束。回首望去,我们不仅仅是编写了三段代码,更是亲历了三次完整的创造之旅。
- 我们从垃圾分类开始,将基础的图像分类技术与迁移学习的智慧相结合,为一个现实的环保问题提供了可行的解决方案。我们学会了数据处理、模型微调、性能评估的全流程思维。
- 接着,我们挑战了目标检测,驾驭了强大的YOLO模型,让机器不仅能“看懂”,更能“定位”。我们体会到了从学术理论到高效工业级框架的巨大飞跃,并窥见了其在安防、自动驾驶等领域的无限潜力。
- 最后,我们沉浸在神经风格迁移的艺术世界里,利用VGG网络对内容和风格的深刻理解,让技术与美学共舞,创造出前所未有的视觉体验。
这三个项目,如三面棱镜,折射出计算机视觉领域不同维度的光彩。它们告诉我们,行是知之成——实践,是知识最终的形态,是理论价值的最终归宿。真正的学习,从来不是发生在安逸的阅读中,而是发生在那些您为了解决一个真实问题而彻夜调试、苦苦思索、最终豁然开朗的瞬间。
以本章为起点,愿您带着这份亲手实践过的自信与体悟,去探索更广阔的应用天地。去发现问题,去定义项目,去收集数据,去创造模型。用您手中的代码和心中的智慧,去洞见万物,去改变世界,哪怕只是改变世界的一个小小角落,那也是您作为一名技术创造者,留给这个时代最美的印记。
第十二章:项目实战:自然语言处理
从像素到语素,开启新的探索
在上一章的旅程中,我们赋予了机器一双“智慧之眼”,让它能够洞察五彩斑斓的视觉世界。我们从像素的海洋中,识别出了物体,定位了它们的存在,甚至模仿了艺术家的笔触。现在,我们将踏入一个同样深邃,甚至更为复杂的领域——自然语言处理(Natural Language Processing, NLP)。我们将引导机器,从“看”世界,转向“听”懂世界、“说”出智慧。
语言,是人类思想的居所,是文明传承的载体。它并非像图像像素那样规整、直白。语言充满了精妙的歧义性(“苹果”可以是一种水果,也可以是一个科技公司)、深刻的上下文依赖性(“我不想去了”的真正含义,取决于之前的对话),以及丰富的文化与情感内涵。这使得NLP成为人工智能领域最具挑战、也最具魅力的分支之一。
本章,我们将化身为语言的工程师与艺术家。我们将通过三个循序渐进的核心项目,亲手实践如何将非结构化的文本,转化为机器可以计算和理解的数学表示——向量。我们将运用在第八章和第九章学到的循环神经网络(RNN)、长短期记忆网络(LSTM)乃至更强大的预训练模型,去完成三项迷人的任务:
- 洞察情感:我们将构建一个情感分析系统,让机器能够读懂电影评论文字背后的喜怒哀乐。
- 跨越障碍:我们将搭建一个简单的机器翻译模型,尝试去打破语言之间的壁垒,构建沟通的桥梁。
- 构建伙伴:我们将实现一个智能问答机器人,赋予它基于知识进行逻辑问答的能力。
这趟旅程,不仅是代码与算法的实践,更是对人类智慧最伟大结晶——语言——的一次深度解码。准备好,让我们一起聆听语言的脉搏,与文字背后的智慧同行。
12.1 文本情感分析:分析电影评论的情感倾向 —— 捕捉文字的温度
语言不仅仅是信息的载体,更是情感的流露。“这部电影太棒了!”和“这部电影真是浪费时间”,这两句话承载的信息截然不同,其核心差异就在于情感的极性。让机器学会分辨这种情感,就是情感分析(Sentiment Analysis)的核心任务。
12.1.1 项目概述:为何情感计算如此重要?
-
应用场景 情感计算是人工智能商业应用中最广泛、最成熟的技术之一。它就像一把能探知群体情绪的“脉搏计”,其价值无处不在:
- 商业智能:企业可以自动分析海量的电商评论、社交媒体帖子,快速了解用户对新产品的反馈,洞察品牌口碑。
- 舆情监控:政府或机构可以实时跟踪公众对某一政策或事件的情感倾向,及时做出反应。
- 个性化推荐:推荐系统可以根据您对某些电影的“正面”评价,为您推荐风格类似的好评电影。
- 金融市场:通过分析财经新闻和社交媒体上的市场情绪,辅助进行量化交易决策。
-
任务定义 我们将这个任务简化为一个经典的二元分类问题:给定一段文本(在我们的项目中,是一段IMDb的电影评论),模型需要输出其情感倾向是“正面”(Positive)还是“负面”(Negative)。
12.1.2 文本的“数字化”之旅:从词语到向量
机器不理解文字,只理解数字。因此,在构建模型之前,我们必须将千变万化的文本,转化为规整、可计算的数学形式。这个过程,是所有NLP任务的基石。
-
文本预处理 原始的文本是“粗糙”的,充满了需要我们清洗和整理的“杂质”。
- 文本清洗:首先,我们需要去除那些对情感分析无用的信息,例如HTML标签(
- 分词(Tokenization):将一个完整的句子,切分成一个词语(Token)的列表。例如,
"This is great!"->['this', 'is', 'great']。 - 去除停用词(Stop Words):停用词是指那些非常常见但通常不携带太多实际意义的词,如
'a','the','is','in'等。在某些任务中,去除它们可以减少噪声,但对于情感分析,有时这些词(如'not')也可能很重要,是否去除需要视情况而定。
- 文本清洗:首先,我们需要去除那些对情感分析无用的信息,例如HTML标签(
-
词嵌入(Word Embeddings):超越One-Hot编码的智慧 将词语转换为数字,最简单的方法是One-Hot编码。但它的弊端显而易见:会产生一个极其巨大且稀疏的向量,并且无法体现词与词之间的语义关系(“good”和“great”的向量是完全正交的)。
词嵌入(Word Embeddings)是一种革命性的思想。它不再将词语表示为稀疏的高维向量,而是将其映射(embed)到一个低维(如100维、300维)、稠密的向量空间中。这个映射的神奇之处在于,它能捕捉词语的语义。在训练好的词嵌入空间里:
- 语义相近的词,其向量在空间中的位置也彼此靠近。例如,
king的向量减去man的向量,加上woman的向量,其结果会非常接近queen的向量。 - 它将词语从一个孤立的符号,变成了一个携带丰富语义信息的数学实体。
- 语义相近的词,其向量在空间中的位置也彼此靠近。例如,
-
实战Keras的
Embedding层 在Keras中,实现词嵌入非常简单,我们只需要使用Embedding层。它就像一个大型的查询表(lookup table)。- 首先,我们需要构建一个词汇表(Vocabulary),将数据集中所有出现过的词语,按频率排序,并为每个词语分配一个唯一的整数索引。
- 然后,将每条文本评论,从一个词语序列,转换为一个整数索引序列。
Embedding层接收这个整数序列作为输入。它内部维护着一个权重矩阵,矩阵的每一行,就是一个词语的嵌入向量。当输入一个整数索引i时,它就去查询并输出权重矩阵的第i行。 这个Embedding层的权重矩阵,可以随机初始化,然后在训练分类任务的同时,一并进行学习。这样,模型就能为我们的特定任务,学习到最合适的词嵌入表示。
from tensorflow.keras.layers import Embedding
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
# 假设我们有评论文本列表 a list of sentences
sentences = ["This movie is great", "This movie is bad"]
# 1. 创建Tokenizer,构建词汇表
tokenizer = Tokenizer(num_words=10000, oov_token="<OOV>") # 只考虑最常见的10000个词
tokenizer.fit_on_texts(sentences)
word_index = tokenizer.word_index
# 2. 将文本转换为整数序列
sequences = tokenizer.texts_to_sequences(sentences)
# 3. 填充序列,使所有序列长度一致 (模型需要定长输入)
padded_sequences = pad_sequences(sequences, maxlen=120, padding='post', truncating='post')
# 4. 在模型中使用Embedding层
# vocab_size: 词汇表大小
# embedding_dim: 嵌入向量的维度
# input_length: 输入序列的长度
embedding_layer = Embedding(input_dim=10000, output_dim=16, input_length=120)
12.1.3 构建情感分类模型:从简单到复杂
文本数据经过数字化和嵌入表示后,就变成了一个(batch_size, sequence_length, embedding_dim)形状的张量。现在,我们可以用在前面章节学到的各种网络结构来处理它了。
-
基于循环神经网络(RNN/LSTM)的模型 文本是典型的序列数据,词语的顺序(“不好” vs “不好看”)至关重要。RNN,特别是LSTM和GRU,其内部的循环结构和门控机制,天然地适合处理这种序列依赖关系。
- 工作方式:LSTM会按时间步依次读取词向量序列,在每个时间步,它会更新其内部的隐藏状态,这个隐藏状态会不断累积和提炼前面所有词语的信息。
- 模型结构:一个典型的结构是
Embedding层 ->LSTM层 ->Dense层(用于分类)。为了防止过拟合,可以在LSTM层之后加入Dropout。使用Bidirectional包装器(即双向LSTM)通常能获得更好的性能,因为它能同时从前向和后向捕捉上下文信息。
-
基于一维卷积网络(1D CNN)的模型 虽然CNN常用于图像,但它同样可以高效地处理文本。一维CNN可以被看作是文本的N-gram特征提取器。
- 工作方式:一个大小为
k的一维卷积核,会滑过整个词向量序列,每次“看”k个连续的词。这相当于在捕捉文本中的k-gram(如2-gram, 3-gram)模式。例如,“not good”、“very bad”这样的关键短语,就很容易被CNN捕捉到。 - 模型结构:通常是
Embedding层 -> 多个不同大小的Conv1D层 ->GlobalMaxPooling1D层 ->Dense层。使用不同大小的卷积核,可以同时捕捉不同长度的短语模式。
- 工作方式:一个大小为
-
模型对比与选择
- LSTM擅长捕捉长距离的依赖关系,对语序更敏感。
- 1D CNN计算速度通常比LSTM快,擅长捕捉关键的局部短语模式。
- 在实践中,两者都能在情感分析任务上取得很好的效果。对于初学者,从一个双向LSTM模型开始,是一个非常经典且稳健的选择。
import tensorflow as tf
model = tf.keras.Sequential([
# 1. Embedding层
tf.keras.layers.Embedding(10000, 128, input_length=120),
# 2. 使用双向LSTM捕捉上下文
tf.keras.layers.Bidirectional(tf.keras.layers.LSTM(64)),
# 3. 全连接层进行特征整合
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dropout(0.5),
# 4. 输出层进行二元分类
tf.keras.layers.Dense(1, activation='sigmoid') # Sigmoid用于二元分类
])
model.summary()
12.1.4 训练、评估与实践
-
数据集 我们将使用Keras内置的IMDb数据集,这是一个理想的起点。它包含了来自互联网电影数据库的50,000条电影评论,已经被标记为正面(1)或负面(0)。更方便的是,Keras已经为我们完成了大部分预处理工作,文本被转换成了整数序列,其中每个整数代表词汇表中的一个特定词语。
-
训练过程
- 加载数据:通过
tf.keras.datasets.imdb.load_data()可以一键加载数据。我们可以指定词汇表的大小(例如,只保留最常见的10,000个词)。 - 填充序列:电影评论的长度各不相同,但神经网络的输入需要是规整的张量。因此,我们必须使用
pad_sequences函数,将所有评论序列“填充”或“截断”到相同的长度。这是一个重要的预处理步骤。 - 编译模型:
- 损失函数:对于二元分类问题,
binary_crossentropy是标准的损失函数。 - 优化器:
Adam依然是我们稳健高效的选择。 - 评估指标:我们最关心的是
accuracy(准确率)。
- 损失函数:对于二元分类问题,
- 训练:调用
model.fit()方法,传入训练数据和验证数据。我们可以设置训练的轮次(epochs)和批量大小(batch_size),并利用回调函数(如EarlyStopping)来防止过拟合,自动在最佳点停止训练。
import tensorflow as tf from tensorflow.keras.datasets import imdb from tensorflow.keras.preprocessing.sequence import pad_sequences # 1. 加载数据 VOCAB_SIZE = 10000 (train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=VOCAB_SIZE) # 2. 填充序列 MAX_LENGTH = 256 train_data = pad_sequences(train_data, maxlen=MAX_LENGTH, padding='post', truncating='post') test_data = pad_sequences(test_data, maxlen=MAX_LENGTH, padding='post', truncating='post') # (接续上一节定义的模型) # 3. 编译模型 model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 4. 训练模型 history = model.fit(train_data, train_labels, epochs=10, batch_size=64, validation_data=(test_data, test_labels)) - 加载数据:通过
-
结果分析 训练完成后,我们不能仅仅满足于一个数字,比如“90%的准确率”。真正的理解源于深入的分析。
- 可视化学习曲线:绘制
history对象中的训练损失/准确率和验证损失/准确率曲线。这是诊断过拟合或欠拟合最直观的工具。 - 质性分析(Qualitative Analysis):这是最有趣的部分。我们应该用自己设计的、具有挑战性的评论来“拷问”模型,以探究其能力的边界:
- 带有转折的评论:“这部电影的开头很无聊,但我没想到结局如此精彩!”——模型能否正确捕捉到后半部分的关键情感?
- 带有反讽的评论:“哦,真是‘太棒了’,我生命中又浪费了两个小时。”——这对于只看词语表面意义的模型是极大的挑战,很可能被误判为正面。
- 带有否定词的评论:“我并不觉得这部电影不好。”——模型是否能正确理解双重否定? 通过观察模型在这些例子上的表现,我们可以更深刻地理解它的优势(比如捕捉关键词)和局限性(比如难以理解复杂的语言结构和讽刺)。
- 可视化学习曲线:绘制
-
学以致用 一个训练好的模型,其最终归宿是应用。我们可以将其保存下来,并编写一个简单的预测函数。这个函数接收一段新的、未经处理的英文文本,然后:
- 使用我们训练时用的
Tokenizer对其进行分词和整数编码。 - 使用
pad_sequences进行填充。 - 调用
model.predict()方法得到一个0到1之间的概率值。 - 根据这个概率值(例如,大于0.5则为正面),返回最终的人类可读的预测结果。 至此,我们的情感分析器就从一个实验品,变成了一个可以集成到任何应用中的实用工具。
- 使用我们训练时用的
12.2 机器翻译:构建一个简单的中英翻译模型 —— 跨越语言的巴别塔
情感分析是“理解”语言,而机器翻译则是“生成”语言,其难度和复杂度都提升了一个量级。我们将要挑战的,是人工智能领域最经典的任务之一:构建一个能将中文翻译成英文的模型。
12.2.1 项目构想:编码器-解码器(Encoder-Decoder)架构的智慧
-
任务的本质 机器翻译的核心,是将一个源语言序列(如中文句子)映射到一个目标语言序列(如英文句子)。这两个序列的长度通常不同,且语法结构迥异,无法像情感分析那样直接进行分类。
-
Encoder-Decoder框架 为了解决这个问题,研究者们提出了一个极其优美且强大的框架——编码器-解码器(Encoder-Decoder),也称为**序列到序列(Sequence-to-Sequence, Seq2Seq)**模型。
- 编码器(Encoder):它的任务是“阅读”并“理解”整个源语言句子。它通常是一个RNN(如LSTM或GRU),会逐词读取源语言序列。当读完最后一个词后,编码器会输出一个最终的上下文向量(Context Vector)。这个向量,就像是编码器对整个句子的“思想”或“摘要”,它被期望蕴含了源句子的全部语义信息。
- 解码器(Decoder):它的任务是根据编码器提供的“思想”,生成目标语言句子。它也是一个RNN,但它的工作方式更像一个语言生成器。它接收编码器输出的上下文向量作为其初始状态,然后一个词一个词地生成目标语言序列。在生成每个词时,它都会考虑之前已经生成的词和当前的隐藏状态。
这个框架的智慧在于,它将复杂的翻译任务,解耦成了“理解”和“生成”两个相对独立的阶段,并通过一个固定大小的上下文向量作为桥梁,连接了两种不同的语言。
12.2.2 基于RNN的Seq2Seq模型实现
-
编码器(Encoder) 实现起来非常直接。我们使用一个LSTM网络。输入是一个中文句子的词向量序列。我们不关心这个LSTM在每个时间步的输出,只关心它在读取完整个句子后的最后一个隐藏状态(hidden state)和细胞状态(cell state)。这两个状态向量将被打包,作为上下文向量传递给解码器。
-
解码器(Decoder) 解码器的实现要复杂一些。
- 它也是一个LSTM,其初始状态被设置为编码器传来的上下文向量。
- 它的输入,在每个时间步,是目标语言序列中前一个真实的词。例如,要生成英文句子
"I am a student",在生成"am"时,我们会给解码器输入"I"。这种使用真实目标词语作为下一步输入来引导训练的技巧,被称为教师强制(Teacher Forcing)。它能极大地稳定和加速模型的收敛。 - 解码器LSTM的每个时间步的输出,会经过一个
Dense层(其大小为目标语言词汇表的大小),再通过一个softmax激活函数,来预测下一个词应该是词汇表中的哪一个。
12.2.3 注意力机制的引入:让模型“专注”起来
-
Seq2Seq的瓶颈 基础的Seq2Seq模型存在一个明显的瓶颈:它试图将源句子的所有信息,都压缩到一个固定大小的上下文向量中。对于短句子,这或许可行;但对于长而复杂的句子,这个小小的向量很容易成为信息传递的“瓶颈”,导致信息丢失,翻译质量急剧下降。
-
Attention的原理 注意力机制(Attention Mechanism)的提出,是机器翻译乃至整个深度学习领域的里程碑事件。它的思想非常符合人类的直觉:当我们在进行翻译时,我们并不会看完整个中文句子后,就完全凭记忆去写英文句子。相反,在翻译英文句子的某个部分时,我们的注意力会动态地聚焦在中文源句的相应部分。
Attention机制正是模拟了这一点。它不再依赖单一的上下文向量,而是:
- 保留编码器所有时间步的输出(而不仅仅是最后一个)。
- 在解码器生成每一个目标词时,它都会执行一个额外的计算: a. 将解码器当前的隐藏状态,与编码器所有时间步的输出进行一次“匹配度”计算,得到一个注意力分数(attention scores)。 b. 对这些分数进行
softmax归一化,得到一个注意力权重(attention weights)分布。这个权重分布,就代表了在生成当前这个目标词时,应该对源句子的哪些部分投入多少“注意力”。 c. 用这些权重对编码器的所有输出进行加权求和,得到一个动态的、为当前时间步量身定制的上下文向量。 - 将这个动态的上下文向量,与解码器当前的输入拼接在一起,再送入解码器的核心LSTM单元。
通过Attention机制,解码器在每一步都能“回头看”,并精准地从源句子中提取最相关的信息,从而极大地提升了长句子的翻译质量。它赋予了模型一种“专注”于局部的能力。
12.2.4 数据准备与训练细节
-
数据集 机器翻译需要平行语料库(Parallel Corpus),即成对的、互为翻译的句子。有许多公开的中英平行语料库可供使用,例如Tatoeba项目、UN Parallel Corpus等。
-
文本预处理
- 为源语言(中文)和目标语言(英文)分别构建词汇表和分词器。中文分词通常使用
jieba等库。 - 在每个句子的开头和结尾,添加特殊的起始符(如
<start>)和结束符(<end>)。这为解码器提供了明确的生成起点和终点信号。 - 将所有句子填充到统一的长度。
- 为源语言(中文)和目标语言(英文)分别构建词汇表和分词器。中文分词通常使用
-
训练与推理的区别
- 训练时:我们使用“教师强制”,将真实的、完整的英文目标序列喂给解码器。
- 推理时(翻译一个全新的中文句子):我们没有真实的英文句子。这时,解码器必须**自回归地(autoregressive)**工作:
- 将中文句子输入编码器,得到上下文向量。
- 将
<start>标记作为解码器的第一个输入。 - 解码器预测出第一个词(例如
"I")。 - 将刚刚预测出的
"I",作为解码器下一个时间步的输入。 - 解码器预测出第二个词(例如
"am")。 - ...这个过程不断循环,直到解码器预测出
<end>标记,或者达到预设的最大长度为止。
构建一个高质量的翻译模型是一项复杂的工程,但通过实现一个带Attention的Seq2Seq模型,读者将能深刻理解现代NLP中序列生成任务的核心思想。
12.3 智能问答机器人:基于知识库的问答系统 —— 赋予机器“记忆”与“逻辑”
最后一个项目,我们将构建一个在工业界应用极为广泛的系统——问答机器人(Chatbot)。它能根据用户的问题,从一个给定的知识库中找到并返回最相关的答案。
12.3.1 项目定位:我们要做什么样的机器人?
-
Chatbot的分类
- 闲聊型:目标是进行开放、流畅、有趣的对话,如微软小冰。
- 任务型:旨在帮助用户完成特定任务,如订餐、查询天气。
- 问答型:专注于根据事实知识回答用户的问题。
-
本次目标 我们将构建一个检索式(Retrieval-based)的问答机器人。它不“生成”新的答案,而是从一个预先准备好的知识库(Knowledge Base, KB)(例如,一个包含上百条“问题-答案”对的FAQ文档)中,检索出与用户问题最匹配的那个答案。这在智能客服、企业内部知识查询等场景中非常实用。
12.3.2 核心技术:从海量文本中检索答案
核心问题是:如何衡量用户提出的问题,与知识库中哪个“标准问题”最相似?
-
信息检索的经典方法:TF-IDF
- 思想:TF-IDF(词频-逆文档频率)是一种经典的统计方法。它认为,一个词的重要性,与它在一篇文章中出现的次数(TF)成正比,与它在整个语料库中出现的频率(IDF)成反比。一个词如果在一篇文章中频繁出现,但在其他文章中很少出现,那么它很可能就是这篇文章的关键词。
- 流程:我们可以为用户问题和知识库中的每个问题,都计算一个TF-IDF向量。然后,通过计算用户问题向量与所有知识库问题向量之间的余弦相似度(Cosine Similarity),来找到最相似的那个。
- 局限:TF-IDF完全基于词频,无法理解语义。例如,用户问“电脑开不了机怎么办?”,知识库里是“笔记本无法启动如何处理?”,尽管意思相同,但因为关键词不匹配,TF-IDF可能无法找到正确答案。
-
基于深度学习的语义匹配 为了克服TF-IDF的局限,我们必须进入**语义(Semantic)**层面。
- 句子嵌入(Sentence Embeddings):这正是我们需要的技术。我们可以使用一个强大的预训练语言模型(如BERT),将用户的问题和知识库中的所有标准问题,都编码成一个高维的、稠密的句子嵌入向量。这些向量,捕捉了句子的深层语义信息。
- 向量相似度计算:同样,我们计算用户问题向量与知识库中所有问题向量的余弦相似度。但这一次,由于向量蕴含了语义,即使两个句子的措辞完全不同,只要意思相近,它们的向量在空间中的位置也会非常接近,从而得到很高的相似度分数。
12.3.3 实战:使用预训练BERT模型构建问答系统
从头训练一个BERT模型是不现实的。我们将直接使用开源社区封装好的强大工具。
-
Sentence-Transformers库介绍
sentence-transformers是一个基于PyTorch和Transformers的Python库。它提供了大量在“语义相似度”任务上微调过的预训练模型,可以极其方便地生成高质量的句子嵌入。 -
构建知识库索引 为了提高效率,我们不能在每次用户提问时,都重新计算知识库中所有问题的向量。正确的做法是离线预处理:
- 选择一个合适的预训练模型(例如,
'paraphrase-multilingual-MiniLM-L12-v2',一个支持多语言且性能优异的模型)。 - 将知识库中所有的问题文本,一次性地全部编码成句子嵌入向量。
- 将这些向量(我们称之为知识库索引)连同对应的答案,一起存储起来。
- 选择一个合适的预训练模型(例如,
-
实现问答流程 当一个在线请求到来时,流程如下:
- 接收用户输入的问题。
- 使用相同的预训练模型,将这个问题实时编码成一个向量。
- 使用
sentence_transformers.util.cos_sim等工具,快速计算该问题向量与我们预先存储的知识库索引中所有向量的余弦相似度。 - 找到相似度最高的那个索引,并返回其对应的预设答案。
from sentence_transformers import SentenceTransformer, util # 1. 加载预训练模型 model = SentenceTransformer('paraphrase-multilingual-MiniLM-L12-v2') # 2. 知识库 (QA对) knowledge_base_questions = ["笔记本无法启动如何处理?", "如何连接到公司WiFi?", ...] knowledge_base_answers = ["请检查电源适配器...", "请选择SSID为...", ...] # 3. 离线构建知识库索引 kb_question_embeddings = model.encode(knowledge_base_questions, convert_to_tensor=True) # 4. 在线问答流程 user_question = "我的电脑开不了机怎么办?" user_question_embedding = model.encode(user_question, convert_to_tensor=True) # 5. 计算余弦相似度 cos_scores = util.cos_sim(user_question_embedding, kb_question_embeddings)[0] # 6. 找到最相似的问题索引 top_result_index = cos_scores.argmax() # 7. 返回对应的答案 print(f"最匹配的问题: {knowledge_base_questions[top_result_index]}") print(f"答案: {knowledge_base_answers[top_result_index]}")
12.3.4 系统的优化与展望
- 提升检索效率:当知识库变得非常庞大(例如百万级别)时,逐一计算余弦相似度会变得很慢。这时,我们需要专门的向量相似度搜索引擎,如Facebook开源的FAISS库。它可以构建向量索引,实现毫秒级的海量向量检索。
- 从检索式到生成式:我们实现的检索式问答系统,答案是固定的。而当前更前沿的,是以ChatGPT为代表的生成式(Generative)问答系统。它们基于超大规模的语言模型(LLM),能够根据上下文和背景知识,动态地生成流畅、自然、全新的答案。这代表了问答机器人发展的未来方向,其背后是更强大的Transformer架构和更海量的预训练数据。
小结:语言是思想的居所
在本章的探索中,我们从捕捉文字的“温度”,到跨越语言的“巴别塔”,再到构建能与我们对话的“伙伴”,一步步深入了自然语言处理的核心地带。
- 我们通过情感分析项目,掌握了NLP任务的基本流程:文本预处理、词嵌入表示,以及如何使用RNN/CNN对文本进行分类。
- 在机器翻译项目中,我们深入学习了里程碑式的Encoder-Decoder架构和Attention机制,理解了序列生成任务的精髓。
- 最后,在问答机器人项目中,我们接触了工业界应用广泛的语义检索思想,并利用强大的预训练语言模型(如BERT),构建了一个远比传统关键词匹配更智能的系统。
这三个项目,分别代表了NLP领域的文本分类、序列到序列生成和语义理解与匹配这三大核心方向。它们共同揭示了一个真理:语言是思想的居所。我们所有的努力,都是为了让机器能够更好地进入这个居所,去理解、去提炼、去运用其中蕴含的无穷智慧。
NLP是一个日新月异的领域,新的模型、新的思想层出不穷。但万变不离其宗,本章所实践的核心概念——向量表示、序列建模、注意力机制、语义匹配——将是您未来学习更前沿技术时,心中最坚实的基石。愿您保持这份好奇与热情,继续在这片语言的海洋中乘风破浪,用代码,去构建能与人类进行更深层次交流的、真正意义上的智能体。
第十三章:项目实战:其他领域
跨越边界,赋能万象
在之前的章节中,我们已经教会了机器如何去“看”懂世界(计算机视觉),如何去“听”懂和“说”出思想(自然语言处理)。我们让机器拥有了类似人类的感知与交流能力。然而,深度学习的疆域远不止于此。它的力量,如同一股强大的思潮,正在渗透和重塑着众多看似与CV、NLP截然不同的领域。
本章,我们将踏上一次跨越边界的探索之旅。我们将看到,深度学习的核心思想——无论是从数据中自动提取层次化特征,还是对序列信息进行建模,抑或是对未来的“价值”进行评估——都具有惊人的普适性。我们将聚焦于三个全新的领域,它们分别对应着三种深刻的智慧:
- 预测未来:我们将深入时间的河流,学习如何从历史的涟漪中,预测未来的波澜。
- 理解选择:我们将探索人心的偏好,构建一个比您更懂您的推荐“知己”。
- 学习决策:我们将引导一个智能体,在虚拟世界中通过不断的试错,从零开始习得通关游戏的智慧。
这不仅是一次技术栈的拓展,更是一次思维范式的延伸。它将向我们证明,深度学习并非一系列孤立的算法,而是一种解决问题的强大世界观。准备好,让我们一起见证深度学习如何为这些复杂的领域赋能,并从中汲取更广阔、更深邃的智慧。
13.1 时间序列预测:预测股票价格或天气变化 —— 在时间的河流中,寻找未来的涟漪
时间,是世界上最公平也最神秘的维度。它单向流淌,永不回头。而时间序列数据,正是这条河流上留下的一串串足迹。学会解读这些足迹,并据此预测未来的走向,是人类长久以来的渴望,也是无数科学与商业决策的基石。
13.1.1 项目构想:为何时间如此特殊?
-
时间序列的定义 时间序列(Time Series)是一组按照时间顺序排列的数据点的集合。它的核心特征,也是它与我们之前处理的独立同分布数据(如图像)最根本的区别,在于数据点之间存在着内在的时间依赖性。简而言之,“过去”会影响“未来”。
-
应用场景 时间序列预测的应用无处不在,深刻地影响着我们的生活和经济活动:
- 金融市场:预测股票价格、汇率、指数的未来走势。
- 气象学:预报未来几小时或几天的气温、降雨量、风速。
- 工业生产:预测服务器的负载、产品的销量、电网的耗电量,以提前进行资源调度。
- 医疗健康:监控病人的心率、血糖等生理指标,预警异常状况。
-
挑战 一条看似简单的时间序列曲线,往往是多种复杂模式的叠加:
- 趋势(Trend):数据随时间呈现出的长期上升或下降的大方向。
- 季节性(Seasonality):数据以固定的周期(如天、周、年)呈现出的规律性波动。
- 噪声(Noise):不规则的、随机的波动。 一个好的预测模型,需要有能力从混杂的信号中,解耦并学习到这些潜在的模式。
13.1.2 数据准备:将时间“窗口化”
深度学习模型,尤其是监督学习模型,需要明确的(输入, 输出)数据对。但原始的时间序列只是一条连续的线,我们如何将其改造为监督学习问题呢?答案是窗口化(Windowing)。
-
数据集 为简化问题,我们先从一个**单变量(Univariate)**时间序列开始,例如某只股票连续200天的每日收盘价。
-
数据预处理 在处理时间序列时,**归一化(Normalization)**尤为重要。将数据缩放到一个较小的区间(如0到1或-1到1),可以帮助神经网络模型(尤其是RNN)更快、更稳定地收敛。常用的方法是
MinMaxScaler。重要的是,我们应该只用训练集的数据来计算缩放的参数(min和max),然后再用这些参数去转换验证集和测试集,以防止未来信息的泄露。 -
创建时间窗口 这是将时间序列问题“翻译”成监督学习语言的关键步骤。我们像一个移动的“窗口”一样,在时间序列上滑动,来生成我们的数据集。
- 窗口大小(Window Size):定义我们用多长的历史数据作为输入。例如,
window_size = 30。 - 预测步长(Horizon):定义我们要预测未来多远的数据。例如,
horizon = 1。 - 滑动过程:
- 取第1天到第30天的数据作为第一个输入
X_1,第31天的数据作为第一个目标y_1。 - 窗口向右滑动一天,取第2天到第31天的数据作为第二个输入
X_2,第32天的数据作为第二个目标y_2。 - ...以此类推,直到数据末尾。
- 取第1天到第30天的数据作为第一个输入
通过这个过程,一条长度为200的时间序列,就被我们转换成了大约170个
(输入序列, 目标值)的数据对,可以被任何监督学习模型使用了。 - 窗口大小(Window Size):定义我们用多长的历史数据作为输入。例如,
import numpy as np
# 假设series是我们的时间序列数据 (numpy array)
def windowed_dataset(series, window_size, batch_size, shuffle_buffer):
dataset = tf.data.Dataset.from_tensor_slices(series)
dataset = dataset.window(window_size + 1, shift=1, drop_remainder=True)
dataset = dataset.flat_map(lambda window: window.batch(window_size + 1))
dataset = dataset.shuffle(shuffle_buffer)
dataset = dataset.map(lambda window: (window[:-1], window[-1]))
dataset = dataset.batch(batch_size).prefetch(1)
return dataset
# 使用示例
# window_size = 30
# train_set = windowed_dataset(train_data, window_size, 32, 1000)
tf.data API提供了高效、灵活的窗口化工具,是处理大规模时间序列数据的首选。
13.1.3 模型的演进:从RNN到专用架构
窗口化后的数据,其输入部分是一个序列,这正是RNN和1D CNN大显身手的舞台。
-
基于LSTM的模型 这是最直观的思路。LSTM被设计用来捕捉序列中的时间依赖关系,因此非常适合处理时间窗口数据。
- 模型结构:一个简单的模型可以是
Input层 ->LSTM层 ->Dense层。如果序列模式复杂,可以堆叠多个LSTM层。由于我们的目标是预测一个数值,所以最后的Dense层只有一个神经元,并且通常不使用激活函数。
- 模型结构:一个简单的模型可以是
-
基于1D CNN的模型 一维卷积网络可以被看作是一种高效的模式检测器。在时间序列中,它可以快速地捕捉到局部的上升/下降模式、小的波峰波谷等。
- 模型结构:
Input层 ->Conv1D层 ->Dense层。Conv1D的卷积核会在时间维度上滑动,提取出关键的局部特征。
- 模型结构:
-
结合CNN与RNN:强强联合 一个更高级、也常常更有效的策略,是将CNN和RNN结合起来。
- 模型结构:
Input->Conv1D->LSTM->Dense。 - 工作原理:
- 首先,使用一个
Conv1D层对输入的长序列进行一次“预处理”。卷积层可以高效地识别出序列中的各种局部模式,并对序列进行平滑和降采样,输出一个更短、但信息更“浓缩”的特征序列。 - 然后,将这个特征序列送入一个
LSTM层。LSTM则在这些被提炼过的特征之上,进一步学习它们之间的长期依赖关系。 这种“先CNN提取局部特征,后RNN整合长期依赖”的混合模型架构,在很多复杂的序列预测任务上都表现出色。
- 首先,使用一个
- 模型结构:
import tensorflow as tf
# 一个CNN+LSTM混合模型的例子
model = tf.keras.models.Sequential([
# 输入形状为 (窗口大小, 特征维度),这里是单变量,所以是1
tf.keras.layers.Input(shape=[None, 1]),
# 1. Conv1D层提取局部模式
tf.keras.layers.Conv1D(filters=64, kernel_size=5, strides=1, padding="causal",
activation="relu"),
# 2. LSTM层学习长期依赖
tf.keras.layers.LSTM(64, return_sequences=True),
tf.keras.layers.LSTM(64),
# 3. Dense层输出预测值
tf.keras.layers.Dense(30, activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1)
])
13.1.4 训练、评估与现实考量
-
评估指标 这是一个回归任务,我们通常使用:
- 均方误差(Mean Squared Error, MSE):对误差的平方进行平均,对大误差的惩罚更重。
- 平均绝对误差(Mean Absolute Error, MAE):对误差的绝对值进行平均,更直观地反映了平均预测误差的大小。
-
“未来”数据的陷阱:绝不能随机打乱! 这是时间序列预测中最重要、也最容易犯错的一点。在划分训练集、验证集和测试集时,我们必须严格按照时间顺序。
- 正确做法:取数据的前70%作为训练集,中间的20%作为验证集,最后的10%作为测试集。
- 错误做法:像处理图像数据一样,将所有窗口化后的数据对随机打乱,再划分训练集和验证集。这会导致模型在训练时“看到”了它本不应该看到的“未来”数据,从而得到一个虚高且毫无意义的评估分数。这被称为数据泄露(Data Leakage)。
-
现实的残酷:为何预测股票价格如此之难? 虽然我们用股票数据作为例子,但必须清醒地认识到,精确预测股票价格几乎是不可能的。
- 有效市场假说:理论认为,股票价格已经反映了所有已知的公开信息。未来的价格波动,主要由无法预测的新信息(如突发新闻、政策变化)驱动。
- 随机游走理论:该理论认为,股票价格的短期变化是随机的,无法根据历史价格进行有效预测。
- 我们模型的真正价值:对于金融市场,我们的模型学习到的,更多是基于历史波动模式的统计规律和可能性,而非确定性的因果关系。它可以作为一个辅助决策的信号(例如,判断市场波动性、识别趋势),但绝不能作为唯一的交易依据。相比之下,预测天气、销量等具有更强物理或社会规律的序列,模型的可靠性会高得多。
掌握了时间序列预测,就如同拥有了一架可以探索时间维度的望远镜。虽然它无法看清未来的每一个细节,但却能为我们揭示通往未来的、可能性最高的路径。
13.2 推荐系统:使用深度学习构建电影或商品推荐引擎
在一个信息爆炸的时代,我们面临的不再是信息匮乏,而是信息过载。无论是面对视频网站上百万的影片,还是电商平台上亿的商品,如何快速找到自己感兴趣的内容,成为一个巨大的挑战。推荐系统,正是这个时代的“信息导航员”。
13.2.1 项目概述:信息过载时代的“导航员”
-
推荐系统的核心价值 推荐系统的使命,是在“用户”和“物品”之间建立一座高效的桥梁。
- 对用户而言:它能发掘用户的潜在兴趣,提升体验,带来“发现”的惊喜。
- 对平台而言:它能增加用户粘性,提升点击率、转化率,是现代互联网商业模式的核心引擎。
-
经典方法回顾:协同过滤 在深度学习流行之前,**协同过滤(Collaborative Filtering)**是推荐系统领域最成功、应用最广泛的思想。它的核心假设是“物以类聚,人以群分”。
- 基于用户的协同过滤(User-based CF):找到与您品味相似的用户(“近邻”),然后将他们喜欢、而您还没看过的物品推荐给您。其逻辑是:“我的朋友喜欢的东西,我可能也喜欢。”
- 基于物品的协同过滤(Item-based CF):找到与您过去喜欢的物品相似的其他物品。其逻辑是:“喜欢《盗梦空间》的人,通常也喜欢《星际穿越》。” 协同过滤思想朴素而有效,但它存在一些问题,如数据稀疏性、难以处理新用户或新物品(冷启动问题)等。
13.2.2 深度学习的切入点:矩阵分解与嵌入思想
深度学习为推荐系统带来了更强大、更灵活的建模工具。其切入点,正是将协同过滤的核心思想——矩阵分解(Matrix Factorization)——用神经网络的语言重新诠释。
-
矩阵分解 我们可以将所有用户的评分数据,想象成一个巨大的、稀疏的“用户-物品”评分矩阵。矩阵分解的目标,是找到两个低维的、稠密的潜在特征(Latent Factor)矩阵:一个用户特征矩阵和一个物品特征矩阵。当这两个矩阵相乘时,能近似地还原出原始的评分矩阵。
- 这个过程,本质上就是在为每一个用户和每一个物品,学习一个嵌入向量(Embedding)。这个向量,代表了该用户或物品在某个抽象的“特征空间”中的位置。例如,一个用户的向量可能编码了他的“科幻偏好度”、“喜剧厌恶度”等;一个电影的向量则编码了它的“科幻成分”、“文艺属性”等。
-
使用深度学习实现矩阵分解 我们可以用一个简单的神经网络来完成这个任务,这种模型通常被称为**神经协同过滤(Neural Collaborative Filtering, NCF)**的一种简化形式。
- 输入:模型的输入是一个
(用户ID, 物品ID)的数据对。 - 嵌入层:
- 创建一个用户嵌入层,将用户ID映射为一个用户嵌入向量。
- 创建一个物品嵌入层,将物品ID映射为一个物品嵌入向量。
- 交互:将得到的用户向量和物品向量,进行点积(Dot Product)操作。这个点积的结果,就被我们视作模型对该用户给该物品的预测评分。
- 训练:将模型的预测评分与真实的评分进行比较(例如,使用均方误差作为损失),通过反向传播来同时学习用户和物品的嵌入向量。
这种方法的优雅之处在于,它将推荐问题,巧妙地转化为了一个标准的监督学习任务,并自然地为每个用户和物品学习到了富有意义的低维表示。
- 输入:模型的输入是一个
13.2.3 构建一个更强大的混合推荐模型
基于ID的协同过滤模型虽然有效,但它忽略了大量有价值的边信息(Side Information)。
-
超越ID 一个用户,除了ID,还有年龄、性别、职业等用户特征。一件物品,除了ID,还有类别、品牌、价格、标签等物品特征。将这些特征融入模型,不仅能提升推荐的准确性,还能极大地缓解**冷启动(Cold Start)**问题——即当一个新用户或新物品出现时,由于没有任何交互历史,传统协同过滤将束手无策,但混合模型依然可以根据其特征进行初步推荐。
-
混合模型(Hybrid Model) 我们可以构建一个更复杂的神经网络来融合这些多源信息。
- 输入:模型的输入变得更加丰富,包括用户ID、物品ID,以及各种用户和物品的元数据特征。
- 特征处理:
- ID类特征:像之前一样,通过各自的
Embedding层转换为嵌入向量。 - 类别特征(如电影类型):同样可以使用
Embedding层。 - 数值特征(如用户年龄):可以进行归一化后直接使用,或分箱后当作类别特征处理。
- ID类特征:像之前一样,通过各自的
- 特征融合:将处理后的所有特征向量**拼接(Concatenate)**在一起,形成一个巨大的、信息丰富的单一向量。
- 深度网络:将这个融合后的向量,送入一个标准的多层感知机(MLP)中。这个MLP的作用,是学习这些不同来源特征之间复杂的、非线性的交互关系。
- 输出:网络的最后一层是一个单一的神经元,输出最终的预测评分。
这种混合模型架构极其灵活,可以方便地融入任意类型的特征,是工业界推荐系统常用的建模范式。
13.2.4 实践与评估
-
数据集 MovieLens是由GroupLens研究小组发布的一系列关于电影评分的数据集,是推荐系统研究最经典的“Hello, World”数据集。它包含了用户对电影的评分、电影的类型标签以及用户的基本信息。
-
评估指标 这是一个回归任务,因此我们可以使用:
- 均方根误差(Root Mean Squared Error, RMSE)
- 平均绝对误差(Mean Absolute Error, MAE) 这两个指标都用于衡量模型预测评分与真实评分之间的差距。
-
从评分预测到Top-N推荐 在真实应用中,我们通常不是要预测用户对某个特定物品的评分,而是要为他生成一个推荐列表(Top-N Recommendation)。
- 实现方法:当一个用户来访时,我们可以用训练好的模型,去计算他对所有(或一个候选子集)他尚未交互过的物品的预测评分。然后,将这些预测评分从高到低排序,选取前N个物品,作为最终的推荐列表呈现给用户。
推荐系统是技术与商业结合最紧密的领域之一。通过这个项目,我们不仅学习了如何用深度学习的“嵌入”思想来理解用户和物品,更窥见了驱动现代互联网个性化体验的核心技术。
13.3 强化学习入门:使用深度Q网络(DQN)玩转简单游戏 —— 在试错中学习智慧
我们本章的最后一个项目,将进入一个思想范式截然不同的领域——强化学习(Reinforcement Learning, RL)。在这里,我们不再为模型提供“正确答案”,而是设定一个“目标”,然后放手让它在与环境的互动中,自己去学习如何达成这个目标。这是一种更接近生物学习本质的、更主动的智慧。
13.3.1 思想的转变:从监督学习到强化学习
-
强化学习的核心范式 想象一个正在学习骑自行车的孩子。您不会告诉他每一毫秒应该以什么角度转动车把、用多大的力气蹬脚踏板。您只会给他一个目标(“别摔倒,往前走”),然后让他自己去尝试。他会摔倒(负奖励),也会成功前进(正奖励)。通过不断的试错,他最终会学会。这就是强化学习。
- 智能体(Agent):学习者和决策者(孩子/我们的算法)。
- 环境(Environment):智能体所处的外部世界(物理世界/游戏世界)。
- 状态(State):对环境在某一时刻的描述(自行车的位置、速度、倾角)。
- 行动(Action):智能体可以采取的操作(转动车把、蹬脚踏板)。
- 奖励(Reward):环境对智能体行动的反馈信号(前进得到正奖励,摔倒得到负奖励)。
- 策略(Policy):智能体的“大脑”,即一个从状态到行动的映射,决定了在特定状态下应该采取什么行动。 RL的目标,就是学习一个最优策略,以最大化长期累积奖励。
-
与监督学习的区别
- 反馈信号:监督学习有明确的、即时的“标签”,而RL只有延迟的、稀疏的“奖励”。您可能做了很多步正确的操作,最后才得到一个奖励。
- 数据来源:监督学习的数据是给定的、静态的,而RL的数据是智能体通过与环境主动交互生成的,是一个动态的过程。
13.3.2 Q-Learning与深度Q网络(DQN)的精髓
-
Q-Learning 这是一种经典的、基于价值(Value-based)的RL算法。它不直接学习策略,而是学习一个动作价值函数Q(s, a)。
- Q(s, a)的含义:它代表了在状态
s下,采取行动a,并且之后都遵循最优策略,所能获得的未来总回报的期望值。 - 决策:一旦我们有了最优的Q函数,策略就变得非常简单:在任何状态
s下,我们只需要选择那个能使Q(s, a)值最大的行动a即可。
- Q(s, a)的含义:它代表了在状态
-
深度Q网络(DQN) 对于简单的环境(如迷宫),我们可以用一个表格(Q-Table)来存储所有
(s, a)对的Q值。但对于复杂环境,比如雅达利(Atari)游戏,其状态是原始的屏幕像素,状态空间几乎是无限的。这时,表格方法失效了。 **DQN(Deep Q-Network)**的革命性贡献在于:使用一个深度神经网络来近似这个Q函数。- 网络输入:环境的状态(例如,游戏画面的几帧图像)。
- 网络输出:该状态下,每一个可能动作的Q值。
13.3.3 DQN的两大“法宝”:经验回放与目标网络
直接用神经网络拟合Q函数会导致训练非常不稳定。2015年,DeepMind提出的DQN引入了两个关键技术,成功地解决了这个问题,开启了深度强化学习的时代。
-
经验回放(Experience Replay) 智能体与环境交互产生的数据是高度时间相关的,直接按顺序学习会导致模型陷入局部最优。
- 做法:智能体将自己经历过的每一步——即
(状态, 动作, 奖励, 下一状态)四元组——都存储到一个固定大小的“记忆池”(Replay Buffer)中。在训练时,我们不再使用刚刚产生的数据,而是从这个记忆池中随机抽取一个小批量(mini-batch)的数据来进行学习。 - 好处:1. 打破了数据相关性,使训练样本更接近独立同分布。2. 提高了数据利用率,一条经验可以被重复学习多次。
- 做法:智能体将自己经历过的每一步——即
-
目标网络(Target Network) 在计算Q学习的目标值时,我们需要用到Q网络自身的预测,这会导致一个“追逐自己尾巴”的问题,使得学习目标不断摇摆,难以收敛。
- 做法:我们创建两个结构完全相同的Q网络。一个是我们正在积极训练的主网络(Main Network),另一个是目标网络(Target Network)。在计算目标Q值时,我们使用固定的目标网络;在更新权重时,我们只更新主网络。每隔一定的步数,我们再将主网络的权重复制给目标网络。
- 好处:这相当于在一段时间内,将学习目标“冻结”住,大大增加了训练的稳定性。
13.3.4 实战:使用DQN玩转CartPole或Atari游戏
-
环境 我们将使用
Gymnasium(由OpenAI Gym发展而来)这个Python库。它为我们提供了大量标准化的RL测试环境,从简单的CartPole(控制小车上的杆子保持平衡)到复杂的Atari游戏,都封装了统一的API接口。 -
编码实现 构建一个DQN智能体,需要实现以下核心组件:
- Q网络:一个简单的全连接网络(对于CartPole)或卷积网络(对于Atari)。
- 记忆池:一个队列或列表,用于存储经验。
- 动作选择策略:通常使用ε-greedy策略。即以
ε的概率随机选择一个动作(鼓励探索),以1-ε的概率选择当前Q值最高的动作(利用已知最优策略)。ε的值会随着训练的进行而逐渐衰减。 - 学习逻辑:从记忆池中采样,计算损失(通常是Huber Loss),并更新主网络。
-
训练循环 整个过程是一个大的循环:
- 初始化环境,获得初始状态。
- 对于每一轮(episode): a. 智能体根据当前状态和ε-greedy策略选择一个动作。 b. 在环境中执行该动作,获得奖励、下一状态和是否结束的信号。 c. 将这个经验存入记忆池。 d. 从记忆池中采样,进行一次网络训练。 e. 周期性地更新目标网络。 f. 直到该轮结束。
-
结果 我们通过绘制每一轮获得的累积奖励曲线,来观察智能体的学习进程。您会看到一条令人振奋的曲线:一开始,智能体像个无头苍蝇,得分很低;但随着训练的进行,奖励曲线会稳步上升,最终达到甚至超过人类水平。这生动地展示了智能体是如何在纯粹的试错中,涌现出真正的“智慧”的。
小结:智慧的形态是多样的
在本章的旅程中,我们三次跨越了学科的边界,将深度学习的火种播撒到了全新的土壤。
- 在时间序列预测中,我们学会了如何尊重和处理时间的特殊属性,利用RNN和CNN的组合,在历史的长河中寻找未来的线索。
- 在推荐系统中,我们运用“嵌入”这一核心思想,将用户和物品映射到同一个语义空间,从而洞察了人心的选择与偏好。
- 在强化学习中,我们彻底颠覆了监督学习的范式,通过构建一个在与环境交互中自我学习的智能体,见证了智慧如何在试错与奖励的驱动下自发涌现。
这三个项目共同向我们揭示了深度学习作为一种通用问题求解范式的强大威力。其核心思想——无论是层次化特征表示、序列信息建模,还是价值函数近似——都如同可以自由组合的“乐高积木”,能够被灵活地应用于解决各种看似毫不相关的复杂问题。
不要将自己局限于计算机视觉或自然语言处理的“舒适区”。真正的创新,往往发生在思想的碰撞与学科的交叉地带。带着在本章学到的全新视角,去观察您身边的世界,去思考还有哪些领域、哪些问题,可以被深度学习的智慧之光所照亮。这将是您从一名优秀的学习者,蜕变为一名杰出的创造者的开始。
第十四章:模型部署与工程化
模型的“出山”之旅
亲爱的读者,至此,我们已经一同走过了深度学习世界的万水千山。我们学会了如何搭建神经网络的“骨架”,如何用数据这味“仙草”进行滋养,如何运用“炼丹术”般的优化技巧,最终训练出性能强大的深度学习模型。在Jupyter Notebook中,当val_accuracy达到一个令人满意的数字时,我们或许会感到心满意足。
然而,这只是故事的开始,绝非结束。
一个在深山中炼成的绝世高手,若想名扬天下、行侠仗E义,终须“出山”,步入江湖。同样,一个在实验室里训练好的模型,若想真正创造价值、赋能百业,也必须开启它的“出山”之旅。这个旅程,便是模型部署与工程化。它关乎如何将我们智慧的结晶,转化为一个稳定、高效、可扩展、可维护的生产力服务,去迎接真实世界中成千上万次调用的考验。
一个成功的AI应用,算法的精妙固然重要,但它仅仅是冰山的一角。水面之下,是庞大而坚实的工程实践在支撑。本章,我们将聚焦于这“水下”的部分,完成从“炼丹”到“济世”的这“最后一公里”。我们将学习:
- 如何为我们日益“臃肿”的模型进行轻量化“瘦身”,让它能飞入寻常百姓家,在手机、在边缘设备上运行。
- 如何将模型部署到专业的服务框架中,让它拥有一个坚固、高性能的“家”。
- 如何将其封装为标准的API服务,为它建立一座与世界万物沟通的“桥梁”。
- 最后,我们将了解MLOps的宏大理念,学习如何系统化地管理AI的整个生命周期,成为一名真正的AI“建筑师”。
这趟旅程,是理论与现实的交汇,是算法与工程的融合。它将考验我们的严谨、细致与远见。准备好,让我们护送亲手创造的模型,完成它从“展品”到“工具”的伟大蜕变。
14.1 模型轻量化:为模型“瘦身”,以适应更广阔的天地
我们追求更深、更复杂的网络,以期获得更高的精度,这本身无可厚非。但这份“智慧”的代价,是模型参数量的爆炸式增长和巨大的计算开销。一个动辄数GB的模型,就像一位身穿重铠的将军,虽威力无穷,却难以在狭窄的街巷中灵活作战。若想让AI的能力遍及手机、智能摄像头、物联网设备等“街头巷尾”,就必须为模型“瘦身”。
14.1.1 为何需要轻量化?性能、成本与场景的考量
模型轻量化的驱动力,源于现实世界中无处不在的“限制”。
- 性能与延迟(Performance & Latency):在自动驾驶、实时语音识别等场景,零点几秒的延迟都可能导致灾难性后果。轻量化能显著加快模型的推理速度,满足严苛的实时性要求。
- 成本与功耗(Cost & Power):在云端,更快的推理速度意味着更少的计算资源占用,直接降低服务成本。在移动端或边缘设备上,更低的计算量意味着更少的能耗和更长的续航时间。
- 部署环境(Deployment Environment):手机、可穿戴设备、工业传感器等边缘设备的计算能力和内存都非常有限。一个庞大的模型根本无法在这些设备上运行。
因此,模型轻量化的目标非常明确:在尽可能保持模型精度的前提下,减小模型体积、降低计算需求、加快推理速度。 这是一门在“性能”与“效率”之间寻求最佳平衡的艺术。
14.1.2 剪枝(Pruning):剪去“冗余”的智慧
如同园丁修剪花木,剪去枯枝败叶,方能让养分集中于主干,使花朵开得更盛。神经网络的剪枝,亦是同理。
-
核心思想 研究发现,深度神经网络中存在大量的参数冗余。许多权重连接的数值非常接近于零,它们对网络的最终输出贡献甚微。剪枝技术的核心,就是识别并安全地移除这些不重要的连接或神经元,从而在不显著影响精度的前提下,得到一个更小、更稀疏的网络。
-
实现方式 最常见的**权重剪枝(Weight Pruning)**流程,如同一场“末位淘汰”的考核:
- 训练一个大模型:首先,正常地训练一个完整的、密集的“教师”模型,使其达到较高的精度。
- 评估权重重要性:为网络中的每一个权重连接打分。最简单直接的方法,就是使用其绝对值的大小作为重要性的衡量标准。绝对值越大的权重,被认为越重要。
- 移除不重要的权重:设定一个剪枝阈值(例如,移除绝对值最小的20%的权重),将这些权重的值强制设为0。此时,我们的权重矩阵就变成了一个稀疏矩阵。
- 微调(Fine-tuning):剪枝操作会暂时性地降低模型精度。因此,我们需要用较低的学习率,在原始数据集上对这个被剪枝的稀疏模型进行几轮额外的训练。这个过程,能让剩余的权重进行微调,以补偿被移除权重所造成的影响,从而恢复大部分失去的精度。 这个“训练-剪枝-微调”的循环可以迭代进行,直到模型大小和精度达到理想的平衡点。
14.1.3 量化(Quantization):从“浮点”到“整数”的精炼
如果说剪枝是在“减少”参数的数量,那么量化则是在“压缩”每一个参数的体积。它是一门将“粗粮细作”的艺术。
-
核心思想 默认情况下,神经网络的权重和激活值都以32位浮点数(FP32)的格式存储。量化技术,就是将这些高精度的浮点数,用一种映射关系,转换为更低精度的数值类型,最常见的是8位定点整数(INT8)。
-
带来的好处 这种看似简单的精度转换,却能带来巨大的收益:
- 模型体积减小:从32位到8位,模型的大小可以直接压缩到原来的1/4。
- 计算速度提升:许多现代CPU和专用AI芯片(如Google的TPU、NVIDIA的Tensor Core)对整数运算的速度,远快于浮点运算。因此,量化后的模型推理速度可以得到2到4倍甚至更高的提升。
- 内存与功耗降低:更小的数据类型意味着更少的内存占用和更低的数据搬运功耗。
-
实现方式 量化主要有两种主流技术路径:
- 训练后量化(Post-Training Quantization, PTQ):这是最简单直接的方式。我们拿一个已经训练好的FP32模型,通过一小部分校准数据来确定浮点数到整数的映射范围,然后直接对模型进行转换。它无需重新训练,操作便捷,但可能会带来一定的精度损失。
- 量化感知训练(Quantization-Aware Training, QAT):为了弥补PTQ可能带来的精度损失,QAT在训练过程中就“模拟”了量化操作。它在模型的前向传播中,模拟量化和反量化的过程,让模型在训练时就提前适应了低精度计算可能带来的噪声和误差。这样训练出来的模型,在转换为真正的INT8模型时,几乎没有精度损失。
14.1.4 知识蒸馏(Knowledge Distillation):让“大”模型教“小”模型
这是一种源于“模仿”和“传承”的智慧。我们不直接去优化一个小模型,而是让一个学识渊博的“老师”,来手把手地教一个天资聪颖的“学生”。
-
核心思想 我们先训练一个性能强大但结构复杂、参数庞大的教师模型(Teacher Model)。然后,我们设计一个结构简单、参数量小的学生模型(Student Model)。知识蒸馏的目标,就是让这个学生模型,去学习和模仿教师模型的“行为”,从而以小巧的身躯,达到或接近教师模型的性能。
-
实现方式 如何“指导”呢?关键在于,学生不仅仅学习客观真理,更要学习老师的“思考过程”。
- 硬标签(Hard Labels):这是我们通常的训练目标,即数据真实的标签(如“猫”、“狗”)。学生模型当然要学习这个。
- 软标签(Soft Labels):这是知识蒸馏的核心。它是指教师模型在softmax层输出的完整的概率分布。这个分布,蕴含了教师模型更丰富的信息。例如,对于一张猫的图片,教师模型可能认为它有90%的可能是猫,但同时有5%的可能是狗,1%的可能是老虎。这个“5%的狗”和“1%的老虎”的信息,就揭示了教师模型认为“猫”与“狗”、“老虎”之间存在某种相似性。
- 联合训练:学生模型的最终损失函数,是其在硬标签上的损失和在软标签上的损失的一个加权和。通过这种方式,学生模型不仅被强制学习正确的答案,更被引导去模仿教师模型对不同类别之间相似性的理解。
知识蒸馏是一种非常有效的模型压缩和迁移学习技术,它为我们提供了一种在不牺牲太多性能的前提下,获得轻量化模型的新思路。
通过剪枝、量化、知识蒸馏这三大“法术”,我们便能将一个庞大而笨重的模型,修炼成一个身轻如燕、快如闪电的高手,为它接下来的“出山”之旅,铺平了道路。
14.2 模型部署:为模型寻找一个“家”
模型部署,就是将我们训练好的模型文件,放置到一个专门的、为生产环境设计的软件系统中运行的过程。这个系统,就是模型的“家”。它需要足够坚固,能够抵御高并发的访问压力;需要足够高效,能够提供低延迟的推理响应;还需要足够灵活,能够方便地管理和更新模型。
14.2.1 跨越框架的鸿沟:ONNX(Open Neural Network Exchange)
在将模型“放入”新家之前,我们首先要解决一个“语言”问题。TensorFlow训练的模型,PyTorch不认识;PyTorch保存的模型,MXNet也无法加载。这种框架间的壁垒,给模型的自由流通和部署带来了巨大的障碍。
-
问题:框架林立,各自为政 不同的深度学习框架,就像说着不同“方言”的部落,它们都有自己独特的模型保存格式。这种不统一,导致一个模型被“锁定”在了创造它的那个框架生态里,难以迁移。
-
ONNX的角色:AI世界的“普通话” 为了解决这个问题,ONNX (Open Neural Network Exchange) 应运而生。它并非一个框架,而是一个开放的、中立的神经网络模型表示格式。它定义了一套标准的算子和文件格式,致力于成为AI模型领域的“普通话”。
- 工作流程:我们可以将任何主流框架(如TensorFlow, PyTorch, Keras, MXNet)训练好的模型,导出(Export)为统一的
.onnx格式。然后,任何支持ONNX标准的推理引擎(Inference Engine),如微软的ONNX Runtime、NVIDIA的TensorRT等,都可以加载这个.onnx文件,并在各种不同的硬件平台(CPU, GPU, 移动端芯片)上进行高性能的推理。 - 核心价值:ONNX将“模型训练”和“模型推理”这两个环节进行了解耦。研究员可以用自己最喜欢的框架进行创新和实验,而工程师则可以专注于用统一的工具栈进行高效、跨平台的部署。
- 工作流程:我们可以将任何主流框架(如TensorFlow, PyTorch, Keras, MXNet)训练好的模型,导出(Export)为统一的
-
实践:导出为ONNX 将模型导出为ONNX通常非常简单。例如,对于一个PyTorch模型:
import torch import torchvision # 假设dummy_model是一个训练好的PyTorch模型 dummy_input = torch.randn(1, 3, 224, 224) # 创建一个符合模型输入的虚拟张量 torch.onnx.export(dummy_model, dummy_input, "model.onnx", # 输出文件名 verbose=False)拥有了
.onnx这个通用格式文件,我们的模型就获得了前所未有的“自由”,可以被部署到更广阔的世界中去。
14.2.2 工业级服务框架:TensorFlow Serving
现在,模型有了“通用语言”,我们需要一个工业级的“家”来承载它。TensorFlow Serving正是Google为其亲儿子TensorFlow量身打造,并久经生产环境考验的高性能服务系统。
-
定位:一个专为生产环境设计的、灵活的、高性能的机器学习模型服务系统。
-
核心特性:
- 高性能:底层由C++编写,专为低延迟、高吞吐量的推理场景优化。
- 模型版本控制:这是其最强大的功能之一。可以为一个模型部署多个版本,并可以无缝地切换、回滚,甚至进行A/B测试,而无需中断服务。
- 易于部署:与Docker等容器化技术完美结合,可以通过几行命令就启动一个稳定、可扩展的预测服务。
- 多模型服务:可以在同一个服务实例中,同时加载和提供多个不同模型的预测服务。
-
工作流程:
- 导出模型:将TensorFlow/Keras模型导出为标准的
SavedModel格式。这是一个包含了模型图结构和权重的目录。 - 启动服务:使用官方提供的Docker镜像,是最简单的方式。只需一条命令,指定模型所在的路径和端口,即可启动服务。
bash
docker run -p 8501:8501 --mount type=bind,source=/path/to/my_model/,target=/models/my_model -e MODEL_NAME=my_model -t tensorflow/serving ``` 3. **发起请求**:服务启动后,会暴露一个RESTful API或gRPC端点。客户端可以通过发送HTTP/gRPC请求,将数据发送到这个端点,并获得预测结果。
- 导出模型:将TensorFlow/Keras模型导出为标准的
14.2.3 另一个选择:TorchServe
对于PyTorch的忠实用户,由PyTorch团队官方维护的TorchServe则是一个更自然的选择。
- 定位:一个专门为PyTorch模型设计的、灵活且易于使用的服务工具。
- 核心特性:
- 与PyTorch生态紧密集成:对PyTorch模型的支持最为原生。
- 模型打包:它要求将模型文件、依赖项以及自定义的预处理/后处理逻辑,一起打包成一个
.mar(Model Archive)文件,这种封装使得部署更加规范和可移植。 - 功能完备:同样支持模型版本管理、性能指标监控、REST/gRPC接口等生产级特性。
选择TF Serving还是TorchServe,主要取决于您的技术栈和团队偏好。两者都是优秀的、经得起考验的生产级部署方案。
14.3 将模型封装为API服务:构建与世界沟通的桥梁
无论是TF Serving还是TorchServe,它们都为我们提供了一个强大的后端服务。现在,我们需要构建一个标准的“接口”,让外部世界能够方便地与这个服务进行交互。这个接口,就是API(Application Programming Interface)。
14.3.1 为何需要API?解耦与标准化
将模型能力封装成API,是现代软件工程的最佳实践。
- 解耦:前端应用(如网页、手机App)的开发者,无需关心您的模型是用什么框架写的、部署在哪里。他们只需要知道API的地址和调用规则,就可以像调用一个普通的函数一样,获得AI的能力。这使得前端和AI后端的开发可以完全分离,独立进行。
- 标准化:HTTP协议是互联网的通用语言。通过RESTful API,我们可以用最标准、最通用的方式提供服务,任何编程语言、任何平台的客户端都可以轻松调用。
我们将使用Python的Web框架,来快速构建这个API“中间层”。
14.3.2 Flask:轻量而强大的Python Web框架
Flask以其简洁、灵活和“微”核心的设计哲学,成为许多Python开发者构建Web服务的首选,尤其适合快速搭建中小型API服务。
- 实践:用Flask创建一个简单的图像分类API。
python
只需短短十几行代码,我们就创建了一个功能完备的预测API。任何客户端只需向from flask import Flask, request, jsonify # 假设我们有一个已经加载好的模型和预处理函数 # from my_model import load_my_model, preprocess_image, predict app = Flask(__name__) model = load_my_model() @app.route("/predict", methods=["POST"]) def predict_endpoint(): if 'file' not in request.files: return "File not provided", 400 file = request.files['file'] image = preprocess_image(file) # 读取并预处理图像 prediction = predict(model, image) # 模型预测 return jsonify(prediction) # 将结果以JSON格式返回 if __name__ == "__main__": app.run(host="0.0.0.0", port=5000)/predict这个地址发送一个包含图片文件的POST请求,就能收到JSON格式的预测结果。
14.3.3 FastAPI:现代、高性能的选择
近年来,一个名为FastAPI的新星冉冉升起,并迅速成为构建高性能API的业界新宠。
- 特点:
- 高性能:其底层基于Starlette和Pydantic,性能可与Node.js、Go等编译型语言构建的服务相媲美。
- 基于类型提示:它大量使用Python 3.6+的类型提示。只需要在函数签名中声明数据类型,FastAPI就能自动完成数据校验、序列化和文档生成。
- 自动生成API文档:这是FastAPI最令人惊艳的特性之一。它能根据代码,自动生成一个交互式的API文档页面(基于Swagger UI和ReDoc)。开发者可以直接在浏览器中测试API,极大提升了协作效率。
对于追求极致性能、规范化开发和自动化文档的生产级项目,FastAPI无疑是比Flask更优越的选择。
14.4 MLOps简介:系统化地管理AI的生命周期
至此,我们已经成功地将单个模型部署上线。但一个真正的AI产品,其生命远未结束。数据在变,业务在变,模型也需要不断地迭代和演进。如何科学、高效地管理这整个复杂的生命周期?MLOps给出了答案。
14.4.1 从DevOps到MLOps:当机器学习遇见工程文化
- MLOps(Machine Learning Operations)是一套旨在实现机器学习应用开发、部署和维护流程自动化与标准化的原则和实践。它是成熟的软件工程文化DevOps在机器学习领域的自然延伸。
- 为何需要MLOps:机器学习系统是一个独特的“三体”。它不仅仅由代码构成,还包含数据和模型这两个核心组件。这三者都有各自的生命周期,都需要被严格管理。更重要的是,模型的性能会随着时间的推移而“衰退”(Concept Drift),需要建立一套持续监控和再训练的机制。MLOps正是为了应对这种复杂性而生。
14.4.2 核心支柱之一:版本控制
可复现性是科学的基石,也是MLOps的核心追求。我们需要对AI系统的三大组件进行全面的版本控制。
- 代码版本控制:使用Git。这是所有现代软件工程的绝对基础,无需多言。
- 数据版本控制:数据是模型的“食粮”,数据的任何变化都可能导致模型行为的改变。我们需要工具来追踪数据的版本。DVC (Data Version Control) 就是为此而生的工具。它能像Git一样,对大型数据集进行版本管理,而无需将庞大的数据文件存入Git仓库。
- 模型版本控制:每次训练,我们都可能得到一个新版本的模型。我们需要一个系统来记录每个模型版本、它是由哪个版本的数据和代码训练出来的、它的性能指标如何、它当前处于什么状态(开发、暂存或生产)。MLflow等工具提供的**模型注册(Model Registry)**功能,正是解决这个问题的利器。
14.4.3 核心支柱之二:CI/CD/CT流水线
MLOps致力于将AI生命周期中的一切都自动化,构建自动化的“流水线(Pipeline)”是其核心实践。
- CI (Continuous Integration, 持续集成):当开发者提交新代码时,自动触发代码的构建和单元测试。
- CD (Continuous Delivery/Deployment, 持续交付/部署):当CI通过后,自动将模型打包、进行集成测试,并将其部署到预生产或生产环境。
- CT (Continuous Training, 持续训练):这是MLOps特有的概念。当检测到有大量新数据标注完成,或者线上模型的性能出现显著下降时,自动触发一个完整的模型再训练、评估和验证的流水线。如果新模型的性能优于旧模型,则自动进入CD流程。
14.4.4 MLOps的愿景:构建可复现、可信赖、可演进的AI系统
MLOps的终极目标,是构建一个自动化的、闭环的AI系统。在这个系统中,从数据准备、模型训练、部署上线,到性能监控、自动再训练,形成一个生生不息的循环。它旨在将AI应用的开发,从一种高度依赖人工和经验的“手工作坊”模式,转变为一种标准化的、自动化的、可信赖的“现代化工业生产”模式。
小结:从工匠到建筑师的蜕变
在本章中,我们完成了从“算法”到“工程”的惊险一跃。我们探讨了模型轻量化的“瘦身之术”,学习了模型部署的“安家之道”,实践了API封装的“沟通之桥”,并最终仰望了MLOps这座系统化管理的“宏伟蓝图”。这四大主题,共同构成了AI工程化的坚实基石。
这段旅程,也要求我们完成一次思维上的深刻转变。如果说前十三章,我们更像一位专注于雕琢技艺的工匠,追求的是算法的精妙与模型的精准;那么本章,我们则开始扮演一位高瞻远瞩的建筑师,追求的是整个系统的稳健、高效、可扩展与可维护。
请将这份工程化的思维,融入未来的每一个AI项目中。因为,只有那些能够穿越实验室的风暴,稳健地运行在真实世界中,并能不断自我演进的模型,才拥有真正持久而强大的生命力。这,便是智慧落地的最终形态。
第五部分:展望篇 —— 探索未来的边界
第十五章:前沿专题与未来趋势
站在巨人的肩膀上,看见未来
亲爱的读者,当您翻开这最后一章时,我们已共同完成了一段非凡的旅程。我们从最基础的神经元出发,亲手构建了感知世界的卷积神经网络、理解序列的循环神经网络,探索了注意力机制的奥秘,并见证了它们在计算机视觉、自然语言处理等领域的强大威力。我们不仅学会了“炼丹”的技艺,更掌握了“济世”的工程之道。可以说,我们已经在深度学习这片坚实的大陆上,建立起了一座属于自己的、视野开阔的知识堡垒。
然而,真正的探索者,从不满足于已知的疆域。
我们脚下的这片大陆,其边界仍在以一种近乎爆炸性的速度,向着未知的远方扩张。新的思想、新的架构、新的挑战,如雨后春笋般不断涌现,共同塑造着人工智能的未来形态。因此,在我们结束这次系统的学习之旅前,有必要登上这座知识堡垒的最高处,将目光投向那片波澜壮阔、正在生成中的新世界。
本章,便是这座专为您搭建的“瞭望塔”。我们将一同眺望五个正在深刻影响AI发展的、激动人心的前沿方向:
- 图神经网络,它让AI的触角得以伸向由“关系”构成的复杂世界。
- 联邦学习,它为破解数据隐私与协作的困局,提供了联邦制的智慧。
- 可解释性AI,它致力于点亮神经网络的“黑箱”,让我们得以信任并审视AI的决策。
- 多模态学习,它正引领AI向着人类的感知方式靠拢,融合万物信息。
- AI伦理,它超越了技术本身,拷问着我们作为创造者的初心与责任。
这五扇窗,分别朝向了数据结构、协作方式、模型透明度、信息融合维度以及技术背后的人文关怀的未来。学习它们,不仅是对现有知识体系的补充与拓展,更是为了激发您对未来的好奇与思考,为您下一段更精彩的探索之旅,预先点亮一盏远航的灯塔。
来吧,让我们一起,站在巨人的肩膀上,去看见那正在发生的未来。
15.1 图神经网络(GNN):当神经网络遇见“关系”
在此之前,我们所处理的数据,无论是图像还是文本,都有一个共同的特点:它们是高度结构化的。一张图像,可以被看作一个规整的像素网格;一段文本,可以被视为一个线性的词语序列。在数学上,我们称这类数据为欧几里得数据。然而,现实世界远比这要复杂和“不规则”。
15.1.1 超越欧几里得:为何需要GNN?
-
传统模型的局限 我们引以为傲的CNN和RNN,在面对许多现实世界的问题时,会显得力不从心。
- CNN被设计用来处理像图像这样的网格结构数据。它的卷积核依赖于固定的、局部的邻居关系(如一个像素周围的8个像素)。
- RNN则被设计用来处理序列数据,其核心是捕捉线性的、有序的依赖关系。 但如果数据本身既不是规整的网格,也不是线性的序列,那该怎么办?
-
现实世界的“图”结构 请环顾我们所处的世界,您会发现它本质上是由实体以及实体之间的联系构成的“图”:
- 社交网络:每个人是一个节点(Node),人与人之间的好友关系是一条边(Edge)。
- 分子结构:每个原子是一个节点,化学键是连接它们的边。
- 交通路网:每个路口是一个节点,道路是连接它们的边。
- 知识图谱:每个概念(如“爱因斯坦”、“相对论”)是一个节点,它们之间的关系(如“提出者”)是一条边。 这些由节点和边构成的图(Graph)结构数据,就是典型的非欧几里得数据。它们的邻居关系不固定,节点的连接数可以千差万别。为了让深度学习能够处理这种普遍存在的关系型数据,**图神经网络(Graph Neural Network, GNN)**应运而生。
15.1.2 GNN的核心思想:消息传递
GNN如何在一个不规则的图上进行学习?其核心思想非常符合直觉:一个节点的特性,应该由它周围邻居的特性来共同定义。 正如“近朱者赤,近墨者黑”,要了解一个人,先看看他的朋友。GNN将这个朴素的道理,变成了一套优雅的数学范式——消息传递(Message Passing)。
-
节点如何学习 想象一下,图中的每个节点都拥有一个初始的特征向量(例如,在社交网络中,可以是一个用户的年龄、性别、兴趣标签等)。GNN的目标,是通过学习,将这个初始特征,更新为一个更具信息量、蕴含了其在图中所处结构信息的“高级”特征向量。
-
消息传递范式 这个更新过程是迭代进行的。在每一轮(或每一层)消息传递中,图中的每一个节点都会同步执行以下三步操作:
- 收集(Gather):每个节点像一个“接收器”,从它的所有直接相连的邻居节点那里,收集它们的当前特征向量(这些向量可以被看作是邻居发来的“消息”)。
- 聚合(Aggregate):节点将收集到的所有邻居的“消息”(特征向量),用一种置换不变的方式(即与邻居的顺序无关)聚合起来。最常见的聚合函数是求和、求平均或求最大值。
- 更新(Update):节点将聚合后的邻居信息与节点自身的上一轮旧信息结合起来,然后将这个组合后的结果,喂给一个可学习的神经网络(通常是一个简单的全连接层),计算出该节点在本轮的、全新的特征向量。
-
直观理解 这个过程非常精妙:
- 经过第一轮消息传递,每个节点都融合了其一跳邻居的信息。
- 经过第二轮消息传递,信息会进一步传播,每个节点实际上已经融合了其二跳邻居的信息。 通过堆叠多层GNN(即进行多轮消息传递),每个节点的最终特征向量,就如同一个以它为中心、不断向外扩展的“涟漪”,蕴含了其在图中的局部乃至全局的结构信息。
15.1.3 GNN的应用场景与展望
装备了消息传递能力的GNN,为处理图数据提供了强大的武器,并已在众多领域展现出巨大潜力。
- 节点分类(Node Classification):预测图中某个节点的属性。例如,在社交网络中,根据用户的社交关系,预测其消费兴趣或政治倾向。
- 图分类(Graph Classification):预测整个图的属性。例如,在药物发现中,将分子看作一个图,预测该分子是否具有抗癌活性。
- 链接预测(Link Prediction):预测两个节点之间是否存在连接。例如,在推荐系统中,向用户推荐可能认识的朋友或可能感兴趣的商品。
展望未来,GNN领域的发展方兴未艾。研究者们正在探索如何将其与注意力机制、Transformer等更强大的架构相结合,以处理更复杂的动态图、异构图,并构建能够理解更复杂关系推理的AI系统。GNN正在成为继CNN和RNN之后,深度学习工具箱中又一个不可或缺的核心组件。
15.2 联邦学习(Federated Learning):数据孤岛上的“联邦”智慧
如果说GNN解决了数据结构上的挑战,那么联邦学习则致力于解决数据协作方式上的一个根本性难题:在数据无法集中的情况下,我们如何进行有效的机器学习?
15.2.1 隐私的困境:数据无法集中怎么办?
-
传统模式的瓶颈 我们本书中所有项目的默认前提,都是数据可以被集中到一个地方(如一台服务器或一个数据中心)进行统一的训练。这是传统的、中心化的机器学习模式。
-
隐私与法规的挑战 然而,在现实世界中,这个前提正变得越来越奢侈。
- 数据隐私:用户的个人数据,尤其是医疗记录、金融交易、聊天内容等,是高度敏感的。将其上传到一个中央服务器,存在巨大的隐私泄露风险。
- 法律法规:全球范围内,数据保护法规(如欧盟的GDPR、中国的《个人信息保护法》)日益严格,对数据的跨境流动和集中存储施加了严格的限制。
- 商业壁垒:不同公司之间,出于商业竞争的考虑,也往往不愿意共享自己的核心数据。 这些因素,共同导致了数据被困在各自产生的地方,形成了一座座无法连通的**“数据孤岛”**。
15.2.2 联邦学习的智慧:“模型移动,数据不动”
面对数据孤岛的困局,联邦学习(Federated Learning, FL)提出了一种极具创见的、颠覆性的分布式学习范式。其核心思想简洁而深刻:“数据不动,模型移动”。
既然数据不能被汇集到模型这里,那就让模型“登门拜访”,去到数据所在的地方进行学习。
- 工作流程 一个典型的联邦学习过程,如同一次严谨的“巡回教学”:
- 分发(Dispatch):中央服务器(协调方)将一个初始的、未经训练的全局模型(Global Model),通过网络分发给所有参与协作的客户端(例如,数百万部手机,或数十家医院)。
- 本地训练(Local Training):每一个客户端在接收到模型后,使用自己本地的、从不外传的数据,对模型进行几轮训练。这个训练过程,将本地数据的“知识”,注入到了模型中,形成了一个本地更新后的模型。
- 安全聚合(Secure Aggregation):训练完成后,客户端并不会上传自己的数据,而是只将模型的更新信息(例如,权重的变化量或梯度)进行加密或使用其他隐私保护技术处理后,安全地上传给中央服务器。
- 更新全局模型(Global Update):中央服务器等待并收集来自多个客户端的模型更新。然后,它使用一种聚合算法(最经典的是联邦平均,Federated Averaging),将所有这些更新量进行加权平均,用来更新全局模型。这个聚合后的全局模型,就融合了多个数据孤岛的共同智慧。
- 这个“分发-训练-聚合”的循环会迭代进行多轮,每一轮,全局模型都会吸收更多参与方的知识,最终收敛为一个性能强大的模型,而全程没有任何原始数据离开过本地设备。
15.2.3 应用与挑战
-
应用场景 联邦学习为许多过去因隐私问题而难以开展的AI应用,打开了大门:
- 智能手机:手机输入法可以利用成千上万用户的本地输入习惯来优化预测模型,而无需上传用户的聊天记录。
- 医疗健康:多家医院可以在不共享任何病人病历的前提下,联合训练一个更精准的疾病诊断模型。
- 金融服务:多家银行可以联合训练一个更强大的反欺诈模型,而无需暴露各自的客户交易数据。
-
挑战 联邦学习虽然前景广阔,但仍面临诸多挑战,如:
- 通信开销:在客户端和服务器之间反复传输模型参数,可能会非常耗费带宽。
- 数据异构性:不同客户端的数据分布可能差异巨大(Non-IID问题),这给模型收敛带来了困难。
- 系统异构性:不同客户端的计算能力、网络状况千差万别,如何高效协调是一个难题。
- 更高级的隐私安全:即使不上传数据,恶意攻击者仍有可能从模型的更新量中,反推出部分原始数据的信息(模型反演攻击)。因此,还需要结合差分隐私、同态加密等更强的隐私技术。
联邦学习代表了一种全新的、去中心化的AI协作范式。它试图在“数据价值”与“隐私保护”这两个看似矛盾的目标之间,架起一座精巧的桥梁,引领我们进入一个更安全、更公平的AI协作新时代。
15.3 可解释性AI(XAI):打开神经网络的“黑箱”
深度学习模型,尤其是那些深邃而复杂的网络,常常被人们诟病为一个“黑箱”。我们知道输入是什么,也看到了输出是什么,但对于其内部数以亿计的参数是如何相互作用,最终推导出这个结果的,我们却知之甚少。这种不透明性,在探索性研究中或许可以接受,但在许多高风险的现实场景中,却是一个致命的缺陷。
15.3.1 “黑箱”之问:我们能信任一个无法理解的决策吗?
-
问题的提出 想象以下场景:
- 一个AI系统拒绝了您的贷款申请,但无法给出任何理由。
- 一个医疗AI诊断您患有某种罕见疾病,但医生无法理解其诊断依据。
- 一个自动驾驶汽车在事故中做出了一个致命的转向决策,但调查人员无法复盘其“决策逻辑”。 在这些场景下,一个性能再高但无法解释的“黑箱”决策,是完全不可接受的。
-
为何需要可解释性(Explainable AI, XAI) 我们追求可解释性,其目的远超满足人类的好奇心。
- 信任与调试:理解模型“为何”做出某个判断,是建立信任、发现模型缺陷并进行有效调试的前提。
- 公平与合规:XAI可以帮助我们检测和纠正模型中可能存在的偏见,确保其决策的公平性,并满足监管机构的要求。
- 知识发现:在科学研究中,解释模型有时能帮助我们从数据中发现新的、未知的规律和知识。
- 追责与安全:当AI系统犯错时,清晰的解释是进行责任认定的基础,也是抵御恶意攻击、提升系统鲁棒性的关键。
15.3.2 XAI的主流方法
打开“黑箱”的尝试,主要沿着两条技术路径展开。
-
事后解释(Post-hoc Explanations) 这类方法如同“侦探”,它们在不改变模型本身结构的前提下,对一个已经训练好的“黑箱”模型进行外部探查和分析。
- 特征归因(Feature Attribution):这类方法旨在回答“哪些输入特征对这个预测结果最重要?”
- LIME (Local Interpretable Model-agnostic Explanations):它的思想非常巧妙。它认为,虽然一个复杂的模型在全局上难以理解,但在任何一个具体的预测点附近,我们总可以用一个简单的、可解释的“代理模型”(如线性模型)来近似它的局部行为。通过解释这个简单的代理模型,来理解复杂模型在这一特定点的决策。
- SHAP (SHapley Additive exPlanations):它借鉴了合作博弈论中的“夏普利值”思想,将“预测结果”看作是所有输入特征“合作”产生的总收益。SHAP能够公平地、有理论保证地计算出每个特征对最终预测结果的贡献值。
- 基于梯度的可视化:这类方法在计算机视觉领域尤为常用,旨在回答“模型在做决策时,到底在看图像的哪个部分?”
- 显著图(Saliency Maps):通过计算模型输出相对于输入图像的梯度,可以得到一张“热力图”,图中亮度越高的区域,表示对模型决策影响越大的像素。
- Grad-CAM (Gradient-weighted Class Activation Mapping):它是一种更先进的技术,能够生成更清晰、更聚焦于物体的热力图,直观地展示出CNN做出分类决策时所依赖的关键区域。
- 特征归因(Feature Attribution):这类方法旨在回答“哪些输入特征对这个预测结果最重要?”
-
本质可解释模型(Inherently Interpretable Models) 另一条路径,则是“建筑师”的思路:我们能否直接设计和使用一些本身结构就相对透明、决策过程一目了然的模型?例如,传统的决策树、线性回归模型。在深度学习领域,这意味着有选择地使用那些具有内在可解释性的结构,比如将注意力机制显式地应用并将其权重作为解释依据。然而,这通常需要在“模型性能”与“可解释性”之间做出权衡。
15.3.3 从“解释”到“负责”
XAI的终极目标,并非仅仅是为每一个决策附上一份“说明书”。它是通往构建更公平、更稳健、更值得信赖的AI系统的必经之路。可解释性,是实现负责任的AI(Responsible AI)的技术基石。
15.4 多模态学习:1 + 1 > 2 的融合艺术
人类的感知系统,是一个天生的多模态融合大师。我们听声辨位,察言观色,将图像、声音、语言等多种信息无缝地融合在一起,形成对世界完整而立体的认知。而多模态学习,正是要教会AI这项“1+1>2”的融合艺术。
15.4.1 世界是多模态的
- 人类的感知:当您观看一场电影时,您同时在处理演员的视觉表情、听觉的语调和背景音乐,以及语言的台词内容。这三种模态的信息相互补充、相互印证,共同构成了您完整的情感体验。
- AI的挑战:传统的AI模型通常是单模态的,要么处理图像,要么处理文本。多模态学习(Multimodal Learning)的目标,就是让AI模型能够像人一样,同时处理和理解来自不同模态(Modality)的数据,并理解它们之间的复杂关系。
15.4.2 多模态学习的核心任务与技术
多模态学习的研究,围绕着几个核心问题展开。
- 融合(Fusion):这是多模态学习最核心的技术挑战。即,如何在模型的不同阶段,将来自不同模态的特征表示有效地结合起来。
- 早期融合:在输入层就将不同模态的数据拼接起来。
- 晚期融合:为每个模态单独训练一个模型,在最后决策层再将其结果融合。
- 中期融合(混合融合):这是当前的主流,通过复杂的交互层(如交叉注意力机制)在模型的中间层次进行深度、非线性的信息融合。
- 对齐(Alignment):在不同模态的数据之间,显式地建立起细粒度的联系。例如,在一份烹饪教程视频中,将语音指令“切碎洋葱”,与视频画面中正在切洋葱的那个片段精确地对应起来。
- 跨模态生成(Translation/Generation):这是多模态学习最令人惊艳的应用方向,即从一种模态生成另一种模态的内容。
- 看图说话(Image Captioning):输入一张图片,模型生成一段描述该图片的文字。
- 文本到图像生成(Text-to-Image Generation):这在近年来取得了突破性进展。模型(如DALL-E, Midjourney, Stable Diffusion)可以根据一段天马行空的文字描述,生成一张高质量、富有想象力的图像。
15.4.3 应用与未来
- 应用:
- 多模态情感分析:结合用户的面部表情、语音语调和评论文本,做出更精准的情感判断。
- 自动驾驶:融合摄像头(视觉)、激光雷达(LiDAR,3D点云)、毫米波雷达等多种传感器的数据,做出更安全、更鲁棒的驾驶决策。
- 更强大的智能搜索:实现“以图搜视频”、“用文字描述搜索一段音频”等更自然、更强大的交互方式。
- 未来:构建一个能够理解和生成任意模态信息的、统一的**“世界模型(World Model)”**,是许多顶尖AI实验室的终极目标之一。这样的模型,将能更全面、更深入地理解我们这个复杂多彩的世界。
15.5 AI伦理与社会责任:作为技术创造者的“第一性原理”
我们终于来到了本书的最后一节,也是最重要的一节。它不涉及任何具体的算法或代码,但它关乎我们未来所写的每一行代码的意义和方向。这,就是AI伦理与我们作为技术创造者,肩上所必须承载的社会责任。
15.5.1 技术的中立与人的责任
古希腊神话中,普罗米修斯将火种带到人间,火既能带来温暖与光明,也能燃起焚毁一切的烈焰。AI,正是我们这个时代的“普罗米修斯之火”。它是一项无比强大的赋能技术,但这份力量同样可能被误用,或带来我们始料未及的负面社会后果。
人们常说“技术是中立的”。这句话在某种程度上是对的,但它极易产生误导。因为技术是由人创造、由人设计、由人部署、由人使用的。在整个链条中,人的价值观、意图和选择,无时无刻不在塑造着技术的形态和影响。因此,作为技术的创造者,我们绝不能以“技术中立”为借口,来逃避我们应尽的伦理责任。
15.5.2 必须正视的核心伦理议题
在开发和应用AI技术的过程中,我们必须时刻警惕并审慎思考以下几个核心议题:
- 偏见与公平(Bias and Fairness):AI模型是从数据中学习的。如果我们的训练数据本身就包含了现实世界中存在的社会偏见(如性别歧视、种族偏见),那么模型不仅会忠实地“学会”这些偏见,甚至会将其放大。这会导致AI系统对特定人群做出不公平的、歧视性的决策。如何度量、发现和缓解模型偏见,是确保AI公平性的核心挑战。
- 隐私(Privacy):我们在联邦学习中已经深入探讨了这一点。如何在充分利用数据价值的同时,以最严格的标准保护用户的个人隐私,是所有AI应用必须遵守的底线。
- 透明度与问责制(Transparency and Accountability):当一个AI系统(如自动驾驶汽车)犯下错误并造成损失时,谁应该来负责?是用户、是开发者、是制造商,还是算法本身?要回答这个问题,就需要清晰的问责机制和必要的技术透明度(XAI是其中的一环),以确保决策链条的可追溯性。
- 安全与鲁棒性(Safety and Robustness):研究表明,许多先进的AI模型都非常“脆弱”,它们可能会被精心设计的、人眼难以察觉的微小扰动(即对抗性攻击)轻易地欺骗,做出完全错误的判断。如何构建在恶意攻击和未知环境下依然稳健、可靠的AI系统,是安全领域的重大挑战。
- 对就业与社会结构的影响:AI自动化浪潮对未来工作岗位、技能需求、财富分配乃至整个社会结构的深远影响,是一个无法回避的宏大议题。这需要技术专家、经济学家、社会学家和政策制定者共同进行跨学科的、有远见的审慎思考和积极引导。
15.5.3 我们的誓言:迈向负责任的创新
亲爱的读者,作为即将或已经投身于AI浪潮的新一代技术创造者,我们手中掌握着塑造未来的强大力量。这份力量,赋予我们的不仅是机遇,更是沉甸甸的责任。
我们必须将伦理思考,作为我们技术开发的**“第一性原理”**。它不应该是在项目后期才被想起的“检查项”,而应是贯穿于从问题定义、数据收集、模型设计、到部署应用全过程的、内化于心、外化于行的基本准则。
在追求更高精度、更快速度、更强性能的同时,请让我们时刻心怀对人、对社会、对未来的敬畏与责任。让我们共同致力于构建那些不仅“智能”,而且“智慧”;不仅“强大”,而且“善良”的AI系统。
终章:智慧无垠,探索不息
掩卷沉思,我们共同的旅程至此已近终点。从第一行代码到最后一章的伦理沉思,我们一同走过了一条系统而深入的深度学习之路。我们不仅学习了“是什么”和“怎么做”,更在不断探问“为什么”以及“应该做什么”。
我们掌握了用Python和主流框架构建、训练和部署强大AI模型的全套技能。更重要的是,我们建立起了一套思考问题的框架:面对一个新问题,我们知道如何选择合适的模型架构,如何准备数据,如何诊断和优化训练过程,以及如何以工程化的思维将其转化为现实价值。
然而,知识的海洋浩瀚无垠,本书所能呈现的,终究只是其中的一片风景。它为您提供了一张详尽的地图、一个可靠的指南针和一身远航的本领,但真正的探索,从您合上本书的那一刻,才刚刚开始。
AI的浪潮仍在奔涌向前,新的论文、新的代码、新的思想每天都在诞生。请保持这份在学习旅程中培养起来的好奇心与求知欲,让它成为您未来不断前行的不竭动力。去阅读最新的研究,去复现有趣的项目,去参与开源的社区,去思考那些尚未被解决的难题。
最重要的是,带着您在本书中学到的所有知识、技能与思考,勇敢地去探索、去创造,去解决那些对您、对您所在的社区、乃至对整个世界有意义的问题。
智慧无垠,探索不息。愿您在人工智能的广阔星辰大海中,找到属于自己的、那颗最闪亮的星。
再会,未来的创造者!
附录:行者的“宝库”与“路书”
- A:常用数据集与资源链接。
- B:数学符号表。
- C:常见问题与排错指南。
- D:进一步阅读建议。
整装再出发
亲爱的读者,当您抵达这里,意味着我们共同的深度学习探索之旅已画上一个圆满的句号。然而,任何学习的终点,都应是另一段更广阔征程的起点。为了让您在未来的道路上行得更稳、走得更远,我们为您精心准备了这份附录。
请不要将它看作是知识的余烬,而应视其为一个整装待发的“军械库”与“给养站”。在这里,我们为您备下了实践所需的“粮草”(数据集),查阅概念的“密码本”(数学符号),应对困难的“急救包”(FAQ),以及指向新大陆的“航海图”(阅读建议)。
愿这份“行囊”能伴您左右,在您探索人工智能的星辰大海时,为您提供最坚实的支持与最及时的帮助。现在,让我们一同清点行囊,准备迎接新的挑战。
A:常用数据集与资源链接
“纸上得来终觉浅,绝知此事要躬行。” 深度学习是一门高度依赖实践的学科,而高质量的数据集,正是实践的“粮草”。以下我们整理了一些在学术界和工业界最常用、最经典的公共数据集,以及一系列宝贵的学习资源,希望能为您的探索之旅提供充足的动力。
A.1 经典数据集
计算机视觉(CV)
- MNIST / Fashion-MNIST:手写数字和服装类别的图像数据集。它们是图像分类领域最初的“Hello, World”,非常适合用于快速验证和测试新的模型想法。
- CIFAR-10 / CIFAR-100:包含了10个或100个类别的60000张32x32彩色图像。相比MNIST,它们更具挑战性,是评估小型图像分类模型性能的常用基准。
- ImageNet:一个拥有超过1400万张图像、超过2万个类别的大规模图像数据集。ImageNet挑战赛(ILSVRC)极大地推动了深度学习和计算机视觉的发展,催生了AlexNet、VGG、ResNet等一系列里程碑式的网络架构。
- COCO (Common Objects in Context):一个大规模的、旨在推动目标检测、图像分割和图像描述等更复杂视觉任务的数据集。它的特点是图像场景复杂,单个图像中包含多个物体。
自然语言处理(NLP)
- IMDb Movie Reviews:一个包含了50000条电影评论的文本数据集,被标记为正面或负面。它是学习和实践文本情感分析任务的经典选择。
- SQuAD (Stanford Question Answering Dataset):一个大规模的机器阅读理解数据集。其形式为(文章,问题,答案)三元组,要求模型根据给定的文章,回答相关问题,是衡量问答系统能力的重要基准。
- WMT (Workshop on Machine Translation):机器翻译领域的年度评测,提供了多种语言对之间的大规模高质量平行语料库,是训练和评估机器翻译模型的标准数据集。
- GLUE / SuperGLUE:一系列NLP任务的集合,旨在全面评估一个语言模型在语义理解、推理、情感分析等多种能力上的综合表现。它们如同语言模型领域的“高考”,是衡量模型泛化能力的重要标尺。
其他领域
- MovieLens:由GroupLens研究小组发布的一系列电影评分数据集,包含了不同规模的用户对电影的评分数据。它是推荐系统研究领域最常用、最经典的入门和基准数据集。
- UCI Machine Learning Repository:一个汇集了数百个经典机器学习数据集的宝库。这些数据集覆盖了分类、回归、聚类等多种任务,规模通常较小,非常适合用于学习和实践传统的机器学习算法。
A.2 学习与交流资源
- 在线课程平台:
- Coursera: Andrew Ng教授的《Machine Learning》和《Deep Learning Specialization》是无数人的启蒙课程。
- fast.ai: Jeremy Howard的课程以“代码优先”的实践派风格著称,强调快速上手和解决实际问题。
- 学术论文与预印本:
- arXiv.org: 康奈尔大学运营的预印本服务器,是获取最新AI研究论文的第一站。重点关注
cs.LG(机器学习),cs.CV(计算机视觉),cs.CL(计算语言学)等分类。 - Papers with Code: 一个将学术论文与开源代码实现紧密结合的网站,是复现和学习最新研究成果的绝佳平台。
- arXiv.org: 康奈尔大学运营的预印本服务器,是获取最新AI研究论文的第一站。重点关注
- 顶级学术会议:AI领域的重大突破通常在以下顶级会议上发布:
- 通用机器学习: NeurIPS, ICML, ICLR
- 计算机视觉: CVPR, ICCV, ECCV
- 自然语言处理: ACL, EMNLP, NAACL
- 框架与工具官方文档:官方文档永远是学习一个工具最准确、最可靠的参考。
- TensorFlow: http://www.tensorflow.org
- PyTorch: http://pytorch.org
- Keras: http://keras.io
- Scikit-learn: http://scikit-learn.org
- Hugging Face: http://huggingface.co
- 技术博客与社区:
- Distill.pub: 一个致力于以清晰、交互式的方式阐述机器学习研究的学术期刊。
- The Gradient: 一个发布对AI领域深度思考和评论的独立出版物。
- Reddit: r/MachineLearning, r/deeplearning等板块是获取最新资讯和参与专业讨论的活跃社区。
- Stack Overflow: 解决编程和技术问题时最离不开的问答社区。
B:数学符号表
在阅读学术论文或更深入的理论书籍时,一套标准化的数学符号是不可或缺的交流语言。本表列出了本书及相关领域中最常用的数学符号,以备读者速查。
|
符号 |
含义 |
示例 |
|---|---|---|
|
通用数学 |
||
|
x, y, z |
标量 (小写斜体) |
y = wx + b |
|
x, y, z |
向量 (小写粗体) |
y = Wx + b |
|
X, Y, Z |
矩阵 (大写粗体) |
Z = XW |
|
𝒳, 𝒴, 𝒵 |
张量 (大写花体) |
|
|
Σ |
求和 |
Σᵢ xᵢ |
|
Π |
求积 |
Πᵢ xᵢ |
|
∫ |
积分 |
∫ f(x) dx |
|
∂ |
偏导数 |
∂L/∂w |
|
∇ |
梯度 (Nabla算子) |
∇J(θ) |
|
线性代数 |
||
|
X^T |
矩阵/向量转置 |
|
|
X⁻¹ |
矩阵的逆 |
|
|
x · y |
向量点积 |
|
|
x ⊗ y |
向量外积 |
|
|
X ⊙ Y |
Hadamard积 (元素对应相乘) |
|
|
x |
||
|
概率论与统计 |
||
|
P(A) |
事件A发生的概率 |
|
|
p(x) |
连续变量的概率密度函数 (PDF) |
|
|
E[X] |
随机变量X的期望 |
|
|
Var(X) |
随机变量X的方差 |
|
|
Cov(X, Y) |
随机变量X和Y的协方差 |
|
|
x ~ D |
随机变量x服从分布D |
x ~ N(μ, σ²) |
|
N(μ, σ²) |
均值为μ,方差为σ²的高斯分布 |
|
|
神经网络 |
||
|
wᵢⱼ, bᵢ |
权重和偏置 |
|
|
z⁽ˡ⁾ |
第l层的线性输出 (z-value) |
z⁽ˡ⁾ = w⁽ˡ⁾a⁽ˡ⁻¹⁾ + b⁽ˡ⁾ |
|
a⁽ˡ⁾ |
第l层的激活输出 |
a⁽ˡ⁾ = g(z⁽ˡ⁾) |
|
g(z), σ(z) |
激活函数, Sigmoid函数 |
|
|
L(ŷ, y) |
损失函数 (单个样本) |
|
|
J(θ) |
代价函数 (整个数据集的平均损失) |
|
|
ŷ |
模型的预测值 (y-hat) |
|
|
θ |
模型的参数集合 |
θ = {W, b} |
C:常见问题与排错指南
在深度学习的实践中,遇到各种错误和问题是在所难免的。这里我们整理了一些最常见的“疑难杂症”及其排查思路,希望能成为您旅途中的“急救包”。
C.1 模型训练相关
-
问题:“我的模型不收敛,损失(Loss)一直不下降怎么办?”
- 排查清单:
- 学习率(Learning Rate):这是最常见的“元凶”。学习率过大,会导致优化过程在最优解附近剧烈震荡甚至发散;学习率过小,则会导致收敛极其缓慢或陷入局部最优。可以尝试从一个较小的值(如1e-4)开始,逐渐增大进行实验。
- 数据归一化:确保输入数据已经进行了适当的归一化(如缩放到0-1或标准化为均值为0、方差为1)。这对于加速收敛和避免数值问题至关重要。
- 损失函数与模型输出:检查损失函数是否与模型的输出层激活函数匹配。例如,二元分类通常使用
sigmoid激活和binary_crossentropy损失;多元分类使用softmax激活和categorical_crossentropy损失。 - 模型结构:模型是否过于简单,以至于无法捕捉数据的复杂性(欠拟合)?可以尝试适当增加模型的深度或宽度。
- 数据本身:检查数据标签是否存在错误,或者数据和标签是否正确对应。可以尝试用一个极小的子集(如10个样本)进行训练,看模型能否在这个子集上过拟合,这可以验证整个训练流程是否能正常工作。
- 排查清单:
-
问题:“模型在训练集上表现很好,但在验证集上很差,这是为什么?”
- 解答:这是典型的过拟合(Overfitting)。模型过度地学习了训练数据中的噪声和细节,而失去了对新数据的泛化能力。
- 解决方案:
- 增加数据:获取更多的训练数据是解决过拟合最有效的方法。如果无法获取新数据,可以采用**数据增强(Data Augmentation)**技术来人工扩充数据集。
- 使用正则化:
- L1/L2正则化:在损失函数中加入对模型权重的惩罚项,限制模型的复杂度。
- Dropout:在训练过程中,随机地“丢弃”一部分神经元,迫使网络学习到更鲁棒的特征。
- 早停(Early Stopping):在训练过程中监控验证集的性能,当验证集性能不再提升时,就提前终止训练。
- 简化模型:使用一个更小、更简单的网络结构。
- 迁移学习:使用在一个大型数据集(如ImageNet)上预训练好的模型,在您的小数据集上进行微调。
-
问题:“NaN(Not a Number)出现在我的损失中,这是怎么回事?”
- 解答:这通常是由训练过程中的数值不稳定引起的。
- 排查清单:
- 学习率过大:过大的学习率可能导致梯度更新过猛,使得权重参数变得极大或极小,最终导致数值溢出,产生NaN。这是最常见的原因。
- 数学运算错误:检查代码中是否存在可能导致数值问题的运算,例如对一个负数或零取对数(
log(0)),或者除以一个可能为零的数。 - 梯度裁剪(Gradient Clipping):这是一个有效的应对策略。在优化器更新权重之前,检查梯度的范数,如果超过一个阈值,就将其缩放到一个固定的范围内,防止梯度爆炸。
C.2 环境与数据相关
-
问题:“如何选择使用CPU还是GPU?”
- 解答:深度学习模型的训练,尤其是CNN、RNN等,涉及海量的矩阵乘法和并行计算。GPU(图形处理器)的核心设计正是为了高效地执行这类任务,因此它是进行深度学习训练的首选和“标配”。对于大型模型的训练,CPU几乎是不可行的。在**推理(Inference)**阶段,或者对于一些非常小型的模型和简单的任务,CPU也可以胜任。
-
问题:“张量的形状(Shape)不匹配错误如何解决?”
- 解答:这是在编程实践中会遇到的最高频的错误,没有之一。它意味着数据在流经神经网络模型时,某一层的输出形状,与下一层的期望输入形状不匹配。
- 解决方案:
- 仔细阅读错误信息:错误信息通常会明确指出是哪一层出现了问题,以及期望的形状和实际的形状是什么。
- 善用
print(tensor.shape):在您怀疑的层前后,打印出张量的形状,这是最直接、最有效的调试方法。 - 利用
model.summary():对于Keras等框架,这个函数可以清晰地列出模型每一层的输出形状,帮助您从全局上检查数据流的维度变化。
D:进一步阅读建议
本书为您打下了坚实的基础,但学海无涯。以下书籍推荐,将为您在特定方向的深入探索,或理论高度的进一步提升,提供可靠的指引。
D.1 经典著作
- 《Deep Learning》 (Ian Goodfellow, Yoshua Bengio, Aaron Courville)
- 俗称“花书”,由三位深度学习领域的巨擘合著。这本书以其理论的深度、覆盖的广度和数学的严谨性著称,是任何希望深入理解深度学习背后原理的读者的必读“圣经”。
- 《Pattern Recognition and Machine Learning》 (Christopher Bishop)
- 简称PRML。这本书从贝叶斯的视角,系统地介绍了机器学习的各种模型和方法。虽然它并非专讲深度学习,但其深刻的概率思想和严谨的数学推导,对于培养机器学习的“内功”大有裨益。
D.2 特定领域深入
- 《Speech and Language Processing》 (Dan Jurafsky, James H. Martin)
- 自然语言处理(NLP)领域的权威教科书,俗称“龙书”。它全面而深入地覆盖了从传统统计方法到现代深度学习方法的NLP技术。
- 《Computer Vision: Algorithms and Applications》 (Richard Szeliski)
- 计算机视觉领域的综合性经典著作,内容涵盖了从图像形成、图像处理到三维重建、图像识别等广泛主题。
- 《Reinforcement Learning: An Introduction》 (Richard S. Sutton, Andrew G. Barto)
- 强化学习(RL)领域无可争议的奠基之作和“圣经”。作者是该领域的开创者,书中系统地介绍了RL的核心概念、算法和思想。
D.3 前沿与思想
真正的学习,是持续不断地追踪领域的脉搏。除了上述经典书籍,我们强烈建议您:
- 养成阅读顶级会议论文的习惯:关注NeurIPS, ICML, ICLR, CVPR, ACL等会议的最新录用论文,了解最前沿的研究方向。
- 关注优秀的个人或团队博客:许多顶尖的研究者和工程师(如Andrej Karpathy, Lilian Weng)都会通过博客分享他们的深刻洞见。
- 保持好奇,终身学习:AI是一个日新月异的领域。保持一颗开放、好奇、乐于实践的心,是在这条道路上不断前行的唯一秘诀。
后记
亲爱的读者朋友们:
我们终于走到了这里。
我依然记得,在本书的开篇,我曾将深度学习比作一片浩瀚的星辰大海。那时,我们还站在岸边,对远方的璀璨心怀敬畏与向往。而今,您已然是一位手持星图、能驾驭舟楫的熟练航海家了。
我们一同走过了很长的路。从最基础的数学“心法”与编程“招式”,到亲手搭建起神经网络这座宏伟的“殿堂”;从深入卷积与循环网络的“幽径”,到驾驭注意力机制这匹驰骋在语言疆场的“骏马”;我们不仅在实战中体验了创造的乐趣,更在工程化的磨砺中,学会了如何将智慧的果实,稳妥地送达人间。最后,我们一同站在山巅,眺望了那正在生成中的、更广阔的未来。
我尽我所能,将这门深奥的学问,化作您易于理解的语言;将这趟艰深的旅程,铺成一条次第分明的道路。我试图为您点亮的,不仅是知识的火把,更是探索未知的勇气与独立思考的习惯。
因为,这本书的真正价值,不在于它教会了您什么,而在于它能唤醒您什么。
它唤醒的,是您与生俱来的、对世界运作规律的好奇心;是您面对复杂问题时,将其拆解、分析、并最终解决的逻辑能力;是您将抽象的理论,与鲜活的现实世界相连接的洞察力。最重要的是,它唤醒了您作为一名“创造者”的自觉。
是的,创造者。从您写下第一行import tensorflow开始,您便不再仅仅是知识的消费者,而是一位潜在的、能够用代码塑造未来的创造者。您所掌握的,已不再是一门单纯的技术,而是一种强大的、能够放大智慧、自动化决策、甚至创造出全新事物的“力量”。
这股力量,在您手中,可以是一个小小的宇宙。
您可以用它,去识别一片叶子的脉络,聆听一只鸟儿的歌唱;您可以让它,去读懂浩如烟海的典籍,翻译隔阂彼此的语言;您可以派它,去预测天体的运行,洞察市场的风云;您甚至可以教它,去生成梵高的星空,谱写巴赫的乐章。
然而,任何强大的力量,都伴随着同样深重的责任。
当您未来构建的AI系统,开始影响一个人的工作、一次医疗的诊断、一笔贷款的审批时,请您务必记起我们在最后一章的探讨。请让“公平、透明、隐私、安全、向善”这些词语,成为您代码世界里永不熄灭的灯塔,成为您所有技术决策的“第一性原理”。
请永远保持谦逊。对知识谦逊,因为学海无涯;对自然谦逊,因为智能的奥秘我们仍知之甚少;对生命谦逊,因为我们所创造的一切,终究是为了服务于人类更美好的生活。
这本书,到这里就要结束了。但您的故事,才刚刚开始。
合上书本,世界便是您更广阔的课堂。去阅读、去实践、去交流、去创造、去犯错、去修正……去将您在这里学到的一切,内化为您自己的血肉与骨骼,然后,去解决一个您真正关心的、哪怕再微小不过的问题。
那便是这趟旅程,最美的延续。
感谢您,我亲爱的读者朋友们,愿意花费宝贵的时间,与我们一同走过这段奇妙的旅程。现在,行囊已满,前路已明,去吧,去开启属于您自己的、那充满无限可能的壮丽航程。
我会在时间的这一端,带着微笑,静静地为您祝福。
再会!

加入社区!打开量化的大门,首批课程上线啦!
更多推荐

 24
24 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)