
量化交易 实战第四课 双均线策略
·
概述
均线最早由美国投资专家 Joseph E.Granville (格兰威尔) 于 20 世纪中期提出. 现在仍然广泛为人们使用, 成为判断买卖信号的一大重要指标. 从统计角度来说, 均线就是历史价格的平均值, 可以代表过去 N 日股价的平均走势.
在之前的文章里, 我们简单了解了一下金叉和死叉的概念. 这次我带大家来实现一下双均线策略.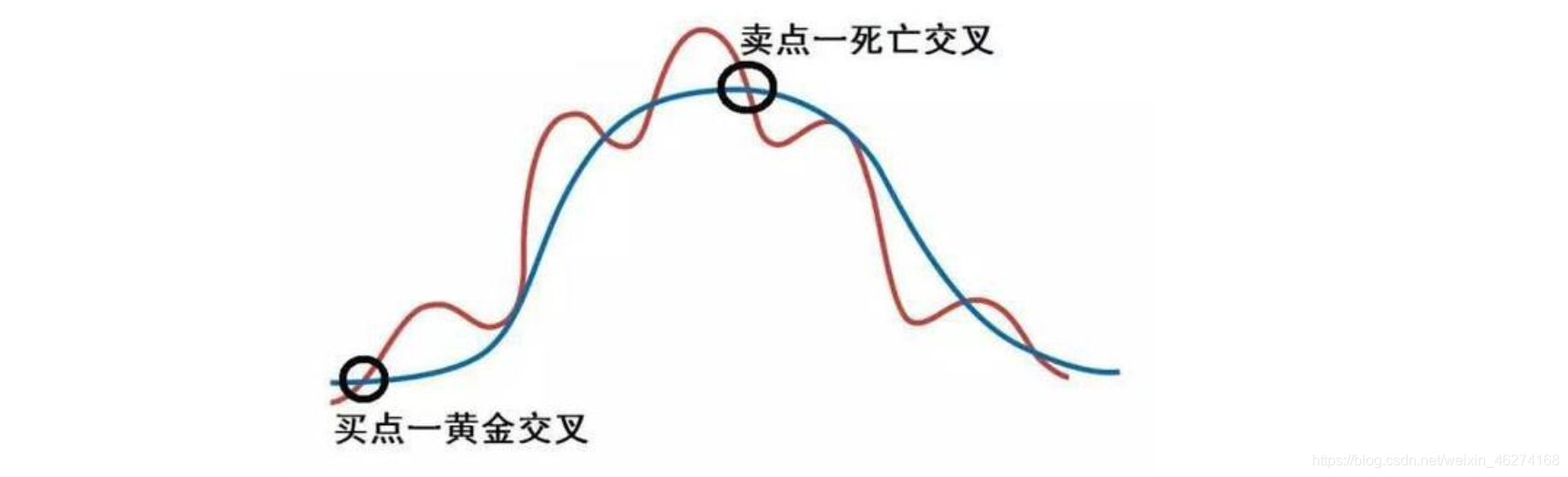
导包
均线最早由美国投资专家Joseph E.Granville(格兰威尔)于20世纪中期提出,现在仍然广泛为人们使用,成为判断买卖信号的一大重要指标。从统计角度来说,均线就是历史价格的平均值,可以代表过去N日股价的平均走势。
获取股票数据
需求
- 这里我们以洋河股份为例
- 获取数据区间 2018-06-01 到 2021-01-04
- 分析区间 2019-01-01 到 2021-01-01
- 绘制走势情况
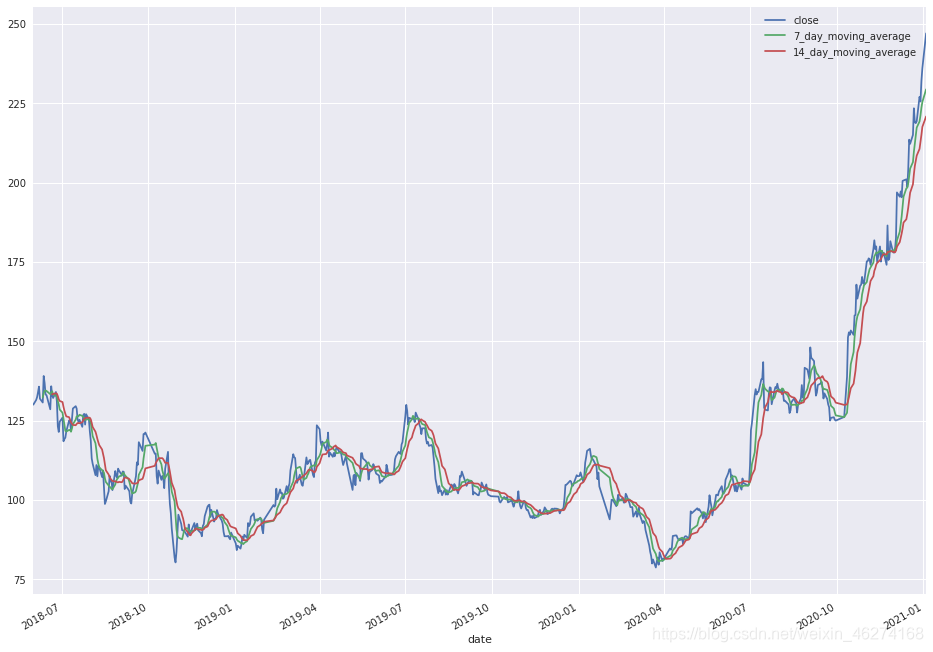
我们在获取数据的时候多获取 6 个月的原因是避免计算平均线的时候少一段, 如图: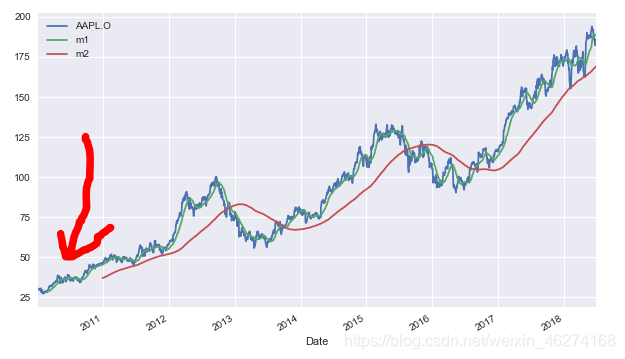
我们可以看出 m2 (红线) 缺失了一部分, 这是因为我们在计算 时间窗口 (rolling) 的时候会产生 NaN 值, 如图: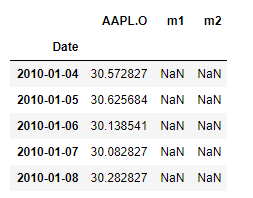
代码
# 定义获取数据时间段
start_date = "2018-06-01" # 开始日期
end_date = "2021-01-04" # 结束日期
# 获取洋河股份数据
data = get_price("002304.XSHE", start_date=start_date, end_date=end_date, fields="close")
data = pd.DataFrame(data, index=data.index)
# 调试输出
print(data.head())
# 绘制走势图
data.plot(figsize=(16, 10))
输出结果:
close
date
2018-06-01 130.0143
2018-06-04 131.4746
2018-06-05 132.3862
2018-06-06 133.9395
2018-06-07 135.6882
计算均线
需求
- 去除缺失值
- 计算短期与长期均线
- 标记短期与长期均线位置关系
注: 由于洋河股份的数据并不存在缺失值, 所以无需去除. 一般在实际情况中会有 NaN 值.
代码
# 查看是否有缺失值
print("缺失值个数;", data["close"].isna().sum()) # 缺失值个数为0, 无需去除空值
print(data.head())
# 定义短期平均和长期时间窗口
SMA_1 = 7
SMA_2 = 14
# 计算均线
data['7_day_moving_average'] = data["close"].rolling(SMA_1).mean() # 7 天均线
data['14_day_moving_average'] = data["close"].rolling(SMA_2).mean() # 14 天平均
# 调试输出
print(data.tail())
print(data.index)
# 画图
data.plot(figsize=(16, 12))
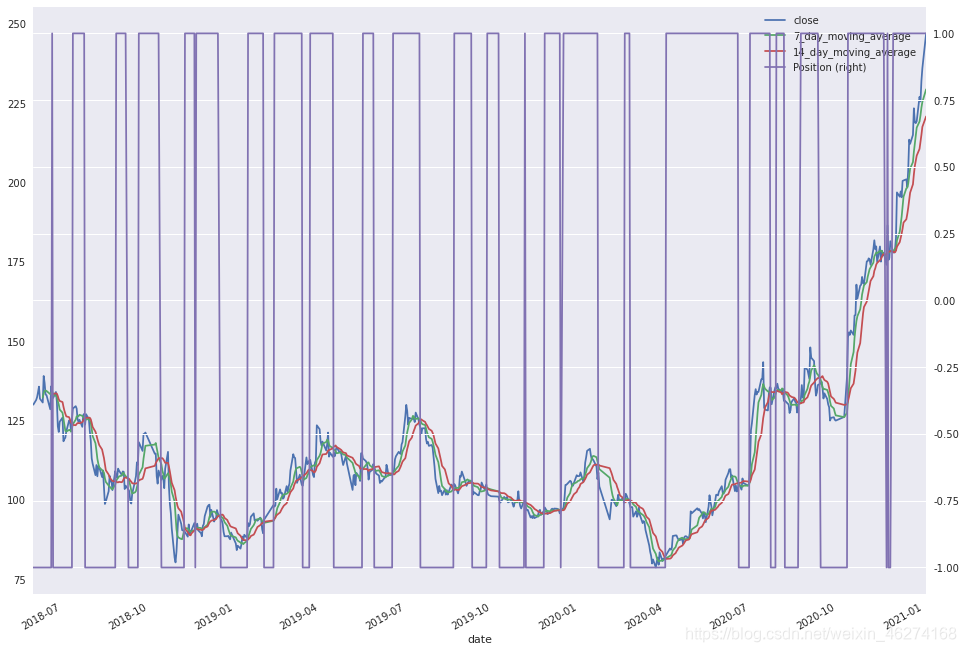
# 标记黄金交叉和死亡交叉位置
data["Position"] = np.where(data["7_day_moving_average"] > data["14_day_moving_average"], 1, -1)
# 调试输出
print(data.head())
# 画图
data.plot(secondary_y='Position',figsize=(16, 12))
输出结果:
缺失值个数; 0
close
date
2018-06-01 130.0143
2018-06-04 131.4746
2018-06-05 132.3862
2018-06-06 133.9395
2018-06-07 135.6882
close 7_day_moving_average 14_day_moving_average
date
2020-12-28 227.00 219.222857 210.590000
2020-12-29 225.54 221.131429 212.747857
2020-12-30 232.00 223.560000 214.997857
2020-12-31 235.99 225.361429 217.522857
2021-01-04 246.98 229.358571 220.807143
DatetimeIndex(['2018-06-01', '2018-06-04', '2018-06-05', '2018-06-06',
'2018-06-07', '2018-06-08', '2018-06-11', '2018-06-12',
'2018-06-13', '2018-06-14',
...
'2020-12-21', '2020-12-22', '2020-12-23', '2020-12-24',
'2020-12-25', '2020-12-28', '2020-12-29', '2020-12-30',
'2020-12-31', '2021-01-04'],
dtype='datetime64[ns]', name='date', length=632, freq=None)
close 7_day_moving_average 14_day_moving_average Position
date
2018-06-01 130.0143 NaN NaN -1
2018-06-04 131.4746 NaN NaN -1
2018-06-05 132.3862 NaN NaN -1
2018-06-06 133.9395 NaN NaN -1
2018-06-07 135.6882 NaN NaN -1
策略实施
需求
- 计算无策略收益
- 计算均线策略收益
代码
# 计算连续增长率
data["Return"] = np.log(data["close"] / data["close"].shift(1))
# 计算策策略增长率
data['Strategy'] = data['Position'].shift(1) * data['Return']
# 去除头部的na值
data = data.iloc[143:] # 统一舍去 6 个月
# 调试输出
print(data.head())
print()
# 计算收益率
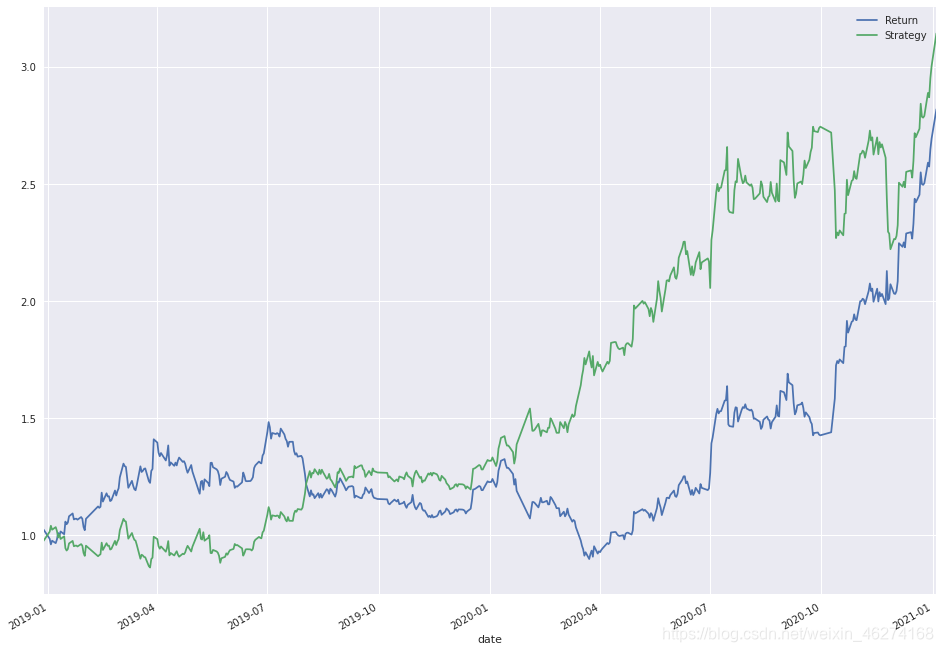
original = np.exp(data['Return'].sum()) # 无策略收益率
strategy = np.exp(data['Strategy'].sum()) # 均线策略收益率
print("无策略回报", original)
print("均线策略回报", strategy)
# 画图
data[["Return","Strategy"]].cumsum().apply(np.exp).plot(figsize=(16, 12))
输出结果:
close 7_day_moving_average 14_day_moving_average Position \
date
2018-12-28 89.7022 88.720029 91.567871 -1
2019-01-02 86.2740 88.192400 91.009800 -1
2019-01-03 84.1811 87.568714 90.296150 -1
2019-01-04 85.5732 87.143900 89.493886 -1
2019-01-07 84.6546 86.571629 88.701771 -1
Return Strategy
date
2018-12-28 0.023717 -0.023717
2019-01-02 -0.038967 0.038967
2019-01-03 -0.024558 0.024558
2019-01-04 0.016402 -0.016402
2019-01-07 -0.010793 0.010793
无策略回报 2.819412829709661
均线策略回报 3.1434629265111727
均线天数选择
需求
- 遍历不同短期与长期数值
- 选出最好的结果
- 可视化展示
代码
from itertools import product
# 获取数据
data = get_price("002304.XSHE", start_date=start_date, end_date=end_date, fields="close")
data = pd.DataFrame(data, index=data.index)
# 定义长短期
sma_1 = range(3,31,1)
sma_2 = range(10,61,1)
results = pd.DataFrame()
# 笛卡尔积元组
for SMA1,SMA2 in product(sma_1,sma_2):
data2 = data.copy()
# 计算连续增长
data2['Returns'] = np.log(data2["close"] / data2["close"].shift(1))
data2['SMA1'] = data2['close'].rolling(SMA1).mean()
data2['SMA2'] = data2['close'].rolling(SMA2).mean()
# 计算策略值
data2['Position'] = np.where(data2['SMA1'] > data2['SMA2'], 1, -1)
data2['Strategy'] = data2['Position'].shift(1) * data2['Returns']
# 去除头部的na值
data2 = data2.iloc[143:] # 统一舍去前6个月
origional = np.exp(data2['Returns'].sum())
strategy = np.exp(data2['Strategy'].sum())
# 得到结果
results = results.append(pd.DataFrame({'SMA1':SMA1,'SMA2':SMA2,'Returns': origional,'Strategy': strategy,
'Out': strategy - origional},
index=[0]),ignore_index=True)
# 输出结果
print(results.head(15))
# 输出最优结果
SMA1 = 7
SMA2 = 19
row = results["Out"].idxmax() # 最佳值所在行
print(results.iloc[row, :]) # 最佳短期7, 长期19
# 画图
# 计算连续增长
data2['Returns'] = np.log(data2["close"] / data2["close"].shift(1))
data2['SMA1'] = data2['close'].rolling(SMA1).mean()
data2['SMA2'] = data2['close'].rolling(SMA2).mean()
# 计算策略值
data2['Position'] = np.where(data2['SMA1'] > data2['SMA2'], 1, -1)
data2['Strategy'] = data2['Position'].shift(1) * data2['Returns']
# 去除头部的na值
data2 = data2.iloc[143:] # 统一舍去前6个月
origional = np.exp(data2['Returns'].sum())
strategy = np.exp(data2['Strategy'].sum())
# 画图
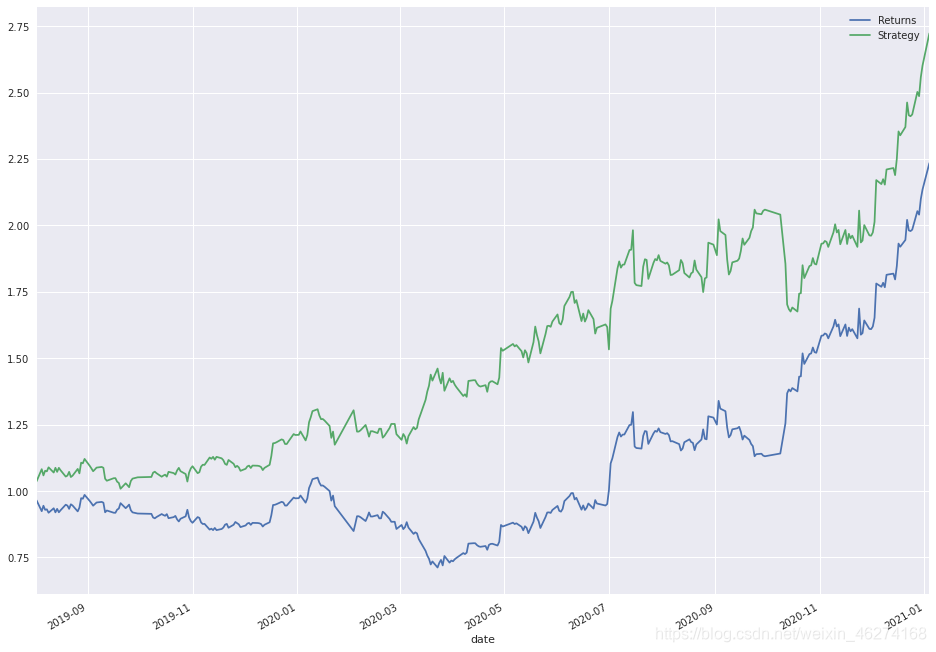
data2[["Returns","Strategy"]].cumsum().apply(np.exp).plot(figsize=(16, 12))
输出结果:
SMA1 SMA2 Returns Strategy Out
0 3 10 2.819413 1.446283 -1.373130
1 3 11 2.819413 2.195871 -0.623542
2 3 12 2.819413 2.037747 -0.781666
3 3 13 2.819413 2.148219 -0.671194
4 3 14 2.819413 1.747857 -1.071556
5 3 15 2.819413 1.555121 -1.264292
6 3 16 2.819413 1.614509 -1.204904
7 3 17 2.819413 1.333349 -1.486063
8 3 18 2.819413 1.631941 -1.187472
9 3 19 2.819413 1.880352 -0.939061
10 3 20 2.819413 1.924894 -0.894519
11 3 21 2.819413 2.298969 -0.520444
12 3 22 2.819413 2.627386 -0.192027
13 3 23 2.819413 2.846099 0.026686
14 3 24 2.819413 3.051959 0.232546
SMA1 7.000000
SMA2 19.000000
Returns 2.819413
Strategy 4.117378
Out 1.297965
Name: 213, dtype: float64
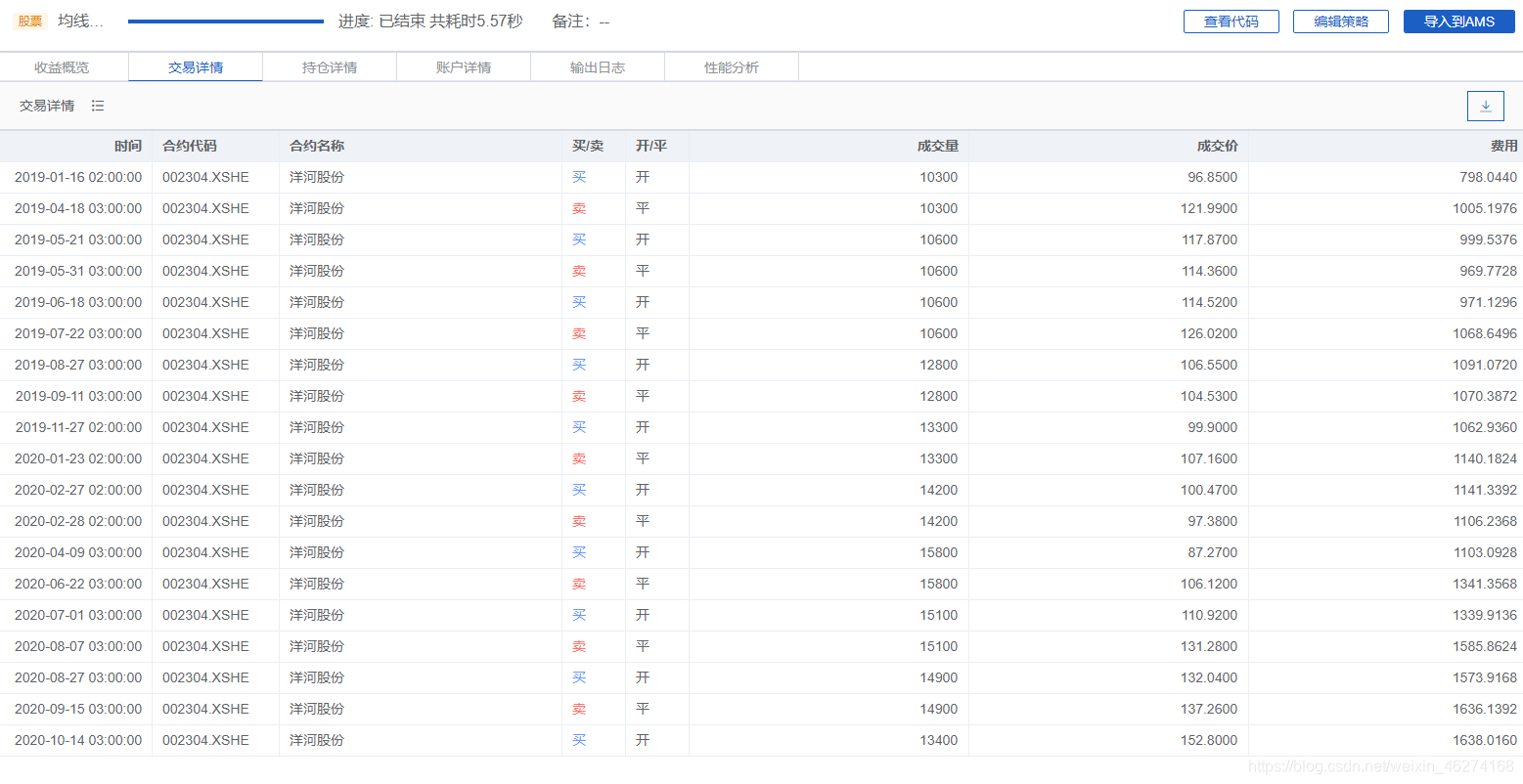
回测结果
代码

回测
81.54% 年化收益率 vs 32.83 基准年化收益率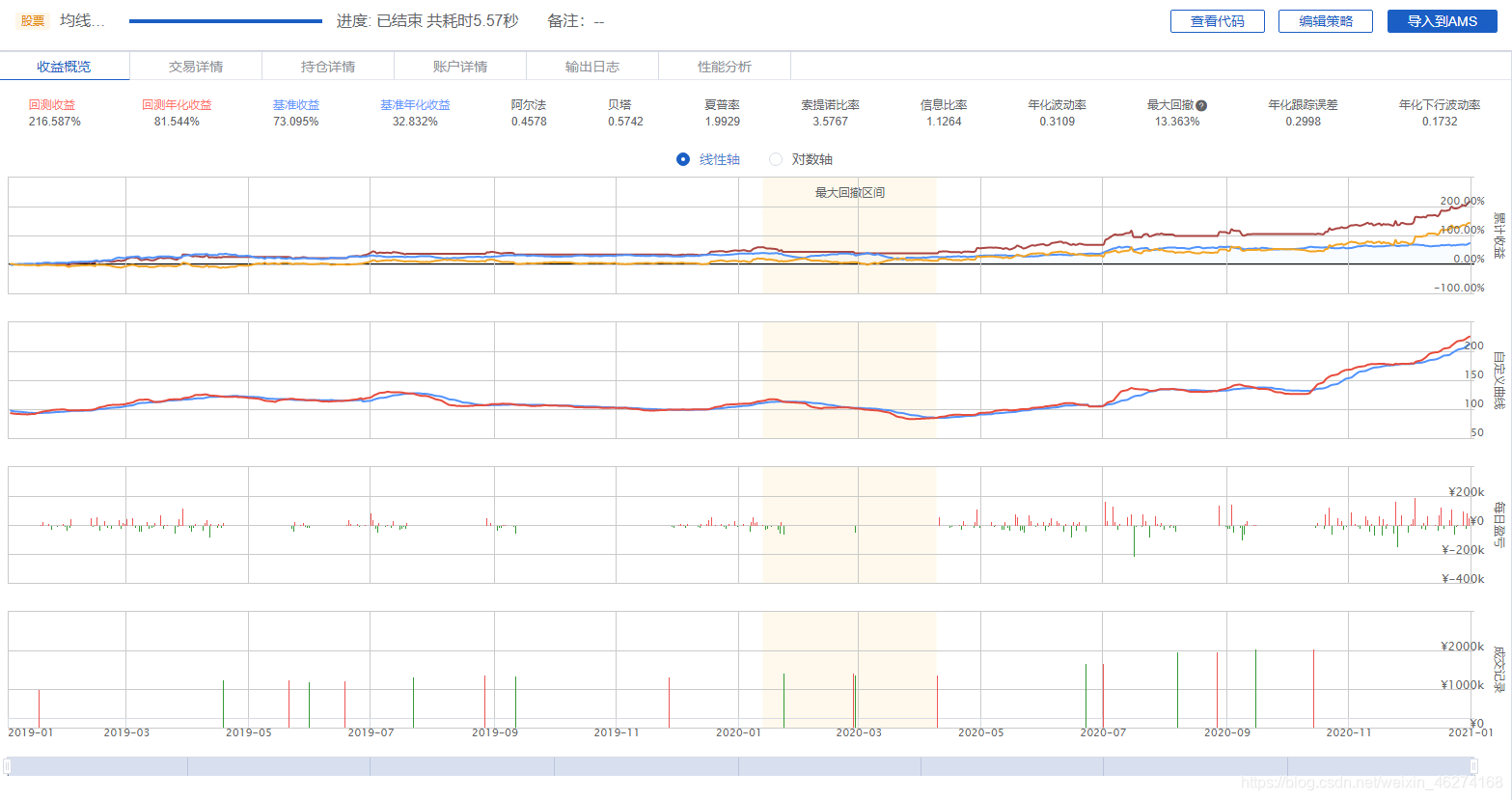

加入社区!打开量化的大门,首批课程上线啦!
更多推荐

 52
52 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)