
同花顺财经新闻-爬虫
这篇文章摘要介绍了使用Python爬取新闻数据并保存为CSV文件的代码流程。通过requests库获取新闻API数据,用pandas处理数据,最终将新闻标题、摘要和URL信息存储到CSV文件中。代码展示了数据请求、JSON解析、字典处理和数据存储的全过程,是一个完整的网络数据采集案例。
·
import requests
import pandas as pd
import json
import os
import re
import requests
# from loguru import logger
from bs4 import BeautifulSoup
from beeize.scraper import Scraper
import json
import os
import requests
from bs4 import BeautifulSoup
scraper = Scraper()
response = requests.get(url, headers=headers)
data = response.json()
news_list = data.get("data", {}).get("list", [])
news_data = []
for news in news_list:
news_item = {
"title": news.get("title", ""),
"digest": news.get("digest", ""),
"url": news.get("url", "")
}
scraper.push_data(news_item)
print(news_item)
news_data.append(news_item)
df = pd.DataFrame(news_data)
df.to_csv("news_data.csv", index=False, encoding="utf-8-sig")
print("News data has been saved to news_data.csv")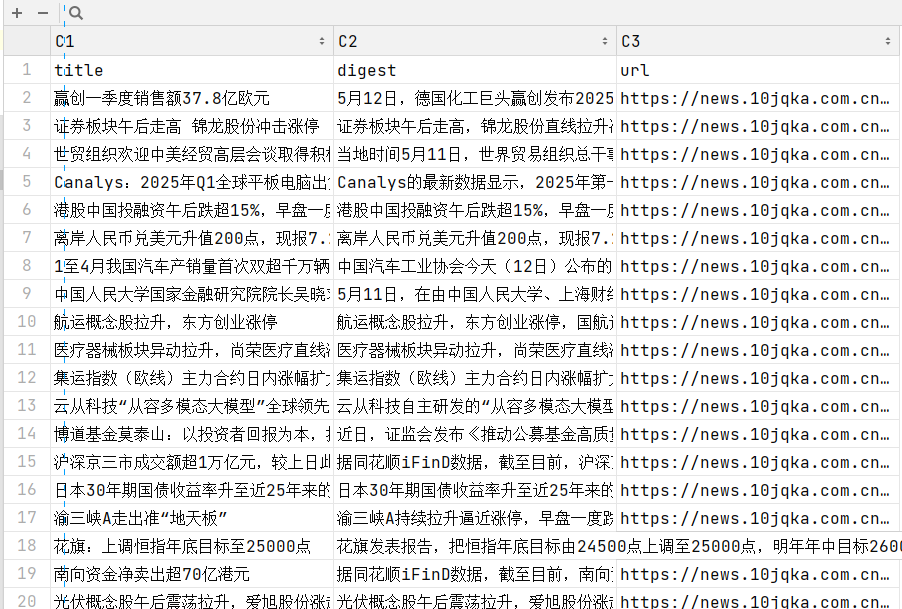

加入社区!打开量化的大门,首批课程上线啦!
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)