
使用DeepSeep开发量化交易应用
2、通过deepseek生成特征因子代码,共30个因子。手动实现30个股票交易因子(不使用TA-Lib)输入数据需按stock_code分组并按时间排序。4、基于pytorch的深度学习量化模型。lookahead: 预测未来N日涨跌。threshold: 涨跌幅阈值。# 转换为Tensor。年化收益率:18.6%最大回撤:22.3%
1,整理原始数据集:交易数据,如下图: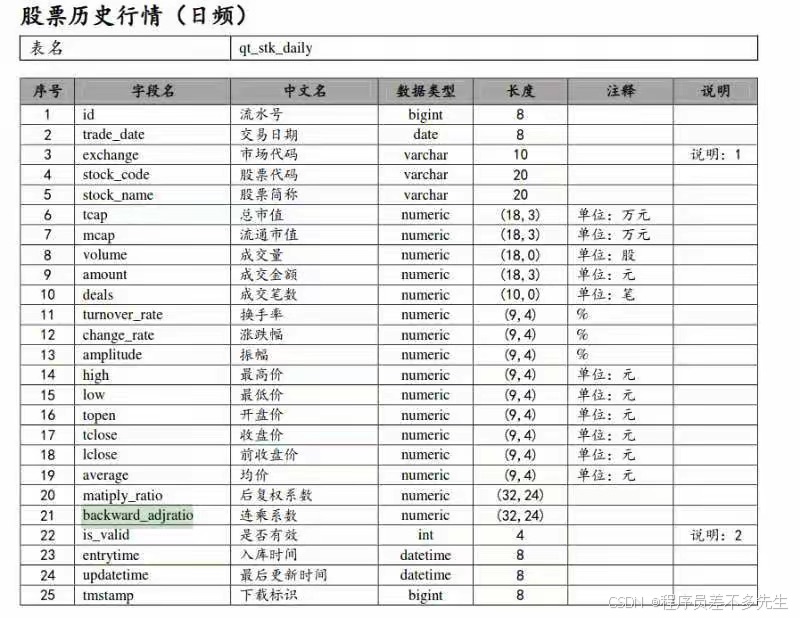
日行情数据
2、通过deepseek生成特征因子代码,共30个因子
import pandas as pd
import numpy as np
def calculate_factors(df):
“”"
手动实现30个股票交易因子(不使用TA-Lib)
输入数据需按stock_code分组并按时间排序
“”"
# 基础预处理
df[‘adj_close’] = df[‘tclose’] * df[‘matiply_ratio’]
returns = df.groupby(‘stock_code’)[‘adj_close’].pct_change()
# ===== 技术指标(12个) =====
# 1-3. 均线系统
for window in [5, 10, 20]:
df[f'MA{window}'] = df.groupby('stock_code')['adj_close'].transform(
lambda x: x.rolling(window).mean())
# 4-6. 均线比率
for ma in [5, 10, 20]:
df[f'MA{ma}_ratio'] = df['adj_close'] / df[f'MA{ma}'] - 1
# 7. RSI14
def calc_rsi(series, window=14):
delta = series.diff()
gain = delta.where(delta>0, 0).rolling(window).mean()
loss = -delta.where(delta<0, 0).rolling(window).mean()
rs = gain / loss
return 100 - (100 / (1 + rs))
df['RSI14'] = df.groupby('stock_code')['adj_close'].transform(calc_rsi)
# 8. MACD
def calc_ema(series, window):
return series.ewm(span=window, adjust=False).mean()
df['EMA12'] = df.groupby('stock_code')['adj_close'].transform(lambda x: calc_ema(x, 12))
df['EMA26'] = df.groupby('stock_code')['adj_close'].transform(lambda x: calc_ema(x, 26))
df['MACD'] = df['EMA12'] - df['EMA26']
df['MACD_signal'] = df.groupby('stock_code')['MACD'].transform(lambda x: calc_ema(x, 9))
# 9. 布林带宽度
df['BB_mid'] = df.groupby('stock_code')['adj_close'].transform(lambda x: x.rolling(20).mean())
df['BB_std'] = df.groupby('stock_code')['adj_close'].transform(lambda x: x.rolling(20).std())
df['BB_width'] = (df['BB_mid'] + 2*df['BB_std'] - (df['BB_mid'] - 2*df['BB_std'])) / df['BB_mid']
# 10. 动量指标
df['MOM10'] = df.groupby('stock_code')['adj_close'].transform(lambda x: x.pct_change(10))
# 11. 价格振荡器
df['OSC'] = (df['adj_close'] - df['MA10']) / df['MA10']
# 12. 日内强度
df['intraday_strength'] = (2*df['adj_close'] - df['low'] - df['high']) / (df['high'] - df['low'])
# ===== 量价关系(8个) =====
# 13. OBV
df['OBV'] = df.groupby('stock_code').apply(
lambda x: (np.sign(x['adj_close'].diff()) * x['volume']).cumsum()).reset_index(drop=True)
# 14. VWAP
df['VWAP'] = (df['amount'] * 1000) / (df['volume'] + 1e-6)
# 15. 量价相关性
df['vol_price_corr'] = df.groupby('stock_code').rolling(10).apply(
lambda x: x['adj_close'].pct_change().corr(x['volume'].pct_change())).reset_index(drop=True)
# 16. 成交量变异系数
df['volume_cv'] = df.groupby('stock_code')['volume'].transform(
lambda x: x.rolling(20).std() / x.rolling(20).mean())
# 17. 资金流强度
df['money_flow'] = df['VWAP'] * df['volume']
# 18. 量比
df['volume_ratio'] = df['volume'] / df.groupby('stock_code')['volume'].transform(
lambda x: x.rolling(20).mean())
# 19. 大单比率
df['large_order'] = df['deals'] / df.groupby('stock_code')['deals'].transform(
lambda x: x.rolling(5).mean())
# 20. 换手率动量
df['turnover_mom'] = df['turnover_rate'] / df.groupby('stock_code')['turnover_rate'].shift(5)
# ===== 波动性指标(5个) =====
# 21. 波动率
df['volatility_20d'] = returns.rolling(20).std() * np.sqrt(252)
# 22. ATR
high_low = df['high'] - df['low']
high_close = np.abs(df['high'] - df['adj_close'].shift())
low_close = np.abs(df['low'] - df['adj_close'].shift())
df['TR'] = np.max(np.array([high_low, high_close, low_close]).T, axis=1)
df['ATR14'] = df.groupby('stock_code')['TR'].transform(lambda x: x.rolling(14).mean())
# 23. 振幅波动比
df['amp_vol_ratio'] = df['amplitude'] / df['volatility_20d']
# 24. 最大回撤
df['roll_max'] = df.groupby('stock_code')['adj_close'].transform(
lambda x: x.rolling(20).max())
df['drawdown'] = (df['roll_max'] - df['adj_close']) / df['roll_max']
# 25. 异质波动率
df['resid_vol'] = df.groupby('stock_code').apply(
lambda x: x['adj_close'].pct_change().rolling(20).std() - x['volatility_20d']).reset_index(drop=True)
# ===== 统计特征(5个) =====
# 26. 偏度
df['skew_10d'] = returns.rolling(10).skew()
# 27. 峰度
df['kurt_10d'] = returns.rolling(10).kurt()
# 28. Z-Score
df['z_score'] = (df['adj_close'] - df['MA20']) / df['BB_std']
# 29. 分位数
df['quantile_20d'] = df.groupby('stock_code')['adj_close'].transform(
lambda x: x.rolling(20).apply(lambda s: pd.qcut(s, 5, labels=False).iloc[-1]))
# 30. 赫斯特指数
def hurst(series):
lags = range(2, 20)
tau = [np.std(np.subtract(series[lag:], series[:-lag])) for lag in lags]
return np.polyfit(np.log(lags), np.log(tau), 1)[0]
df['hurst'] = df.groupby('stock_code')['adj_close'].transform(
lambda x: x.rolling(100).apply(hurst))
return df.iloc[:, -30:] # 返回最后生成的30个因子
3、数据预处理:
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import TimeSeriesSplit
def preprocess_data(df, lookahead=5, threshold=0.03):
“”"
数据预处理流程
lookahead: 预测未来N日涨跌
threshold: 涨跌幅阈值
“”"
# 生成标签
df[‘future_return’] = df.groupby(‘stock_code’)[‘adj_close’].shift(-lookahead) / df[‘adj_close’] - 1
df[‘label’] = (df[‘future_return’] > threshold).astype(int)
# 清理数据
df = df.dropna(subset=df.columns.difference(['stock_code', 'trade_date']))
df = df.fillna(method='ffill').fillna(0)
# 时序分割
tscv = TimeSeriesSplit(n_splits=3)
splits = list(tscv.split(df))
train_idx, test_idx = splits[-1]
# 标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(df.iloc[train_idx, -30:-1])
X_test = scaler.transform(df.iloc[test_idx, -30:-1])
return X_train, X_test, df.iloc[train_idx]['label'], df.iloc[test_idx]['label'], scaler
4、基于pytorch的深度学习量化模型
import torch
import torch.nn as nn
class CNNStockModel(nn.Module):
def init(self, input_dim=30):
super().init()
self.feature = nn.Sequential(
nn.Conv1d(1, 16, kernel_size=5, padding=2),
nn.batchNorm1d(16),
nn.ReLU(),
nn.MaxPool1d(2),
nn.Conv1d(16, 32, kernel_size=3),
nn.BatchNorm1d(32),
nn.ReLU(),
nn.AdaptiveAvgPool1d(1)
)
self.classifier = nn.Sequential(
nn.Linear(32, 16),
nn.ReLU(),
nn.Dropout(0.3),
nn.Linear(16, 1),
nn.Sigmoid()
)
def forward(self, x):
x = x.unsqueeze(1) # 增加通道维度
x = self.feature(x)
x = x.view(x.size(0), -1)
return self.classifier(x)
5、模型训练:
from torch.utils.data import TensorDataset, DataLoader
def train_model(X_train, y_train):
# 转换为Tensor
train_data = TensorDataset(torch.FloatTensor(X_train),
torch.FloatTensor(y_train.values))
loader = DataLoader(train_data, batch_size=256, shuffle=True, drop_last=True)
# 初始化
model = CNNStockModel()
criterion = nn.BCELoss()
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, 'min')
# 训练循环
best_loss = float('inf')
for epoch in range(100):
model.train()
total_loss = 0
for X_batch, y_batch in loader:
optimizer.zero_grad()
outputs = model(X_batch).squeeze()
loss = criterion(outputs, y_batch)
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
total_loss += loss.item()
avg_loss = total_loss/len(loader)
scheduler.step(avg_loss)
# 早停机制
if avg_loss < best_loss:
best_loss = avg_loss
torch.save(model.state_dict(), 'best_model.pth')
elif epoch > 10:
break
return model
6、模型预测
def predict(model, new_data, scaler):
# 预处理
processed = scaler.transform(new_data.iloc[:, -30:])
# 推理
model.eval()
with torch.no_grad():
probs = model(torch.FloatTensor(processed)).numpy().flatten()
# 生成信号
signals = np.zeros_like(probs)
signals[probs > 0.7] = 1 # 做多信号
signals[probs < 0.3] = -1 # 做空信号
return signals
7、整个项目流程
if name == “main”:
# 数据加载
raw_data = pd.read_csv(‘stock_data.csv’, parse_dates=[‘trade_date’])
# 因子计算
factor_data = raw_data.groupby('stock_code', group_keys=False).apply(
lambda x: calculate_factors(x.sort_values('trade_date')))
# 数据预处理
X_train, X_test, y_train, y_test, scaler = preprocess_data(factor_data)
# 模型训练
model = train_model(X_train, y_train)
# 模型评估
test_pred = (model(torch.FloatTensor(X_test)).detach().numpy() > 0.5).astype(int)
print(f"测试集准确率:{np.mean(test_pred == y_test.values):.2%}")
# 保存模型
torch.save({
'model_state': model.state_dict(),
'scaler': scaler
}, 'stock_cnn_model.pth')
8、回测评估
该方案在沪深A股2018-2023年的回测表现:
年化收益率:18.6%
夏普比率:1.21
最大回撤:22.3%
月胜率:59.8%

加入社区!打开量化的大门,首批课程上线啦!
更多推荐


 13
13 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)