
不一样的获取数据方式——爬虫学习(3)
不一样的获取数据方式——爬虫学习(1)
不一样的获取数据方式——爬虫学习(2)
之前在学习爬虫的时候,有些网站发送请求会被拒绝,所以需要把程序伪装成浏览器,除了在请求头加上user-agent之外常见的还有cookie,防盗链,代理等操作
1 处理cookie
1.1 知识点
在爬虫的时候,有些网站需要先登录才能查看内容,而浏览器记录登录就是通过cookie实现的。所以在遇到需要登录的情况时就要先登录一下得到cookie然后带着cookie去发送请求才能获得想要的数据。
为了实现以上连续的操作,就可以使用session进行请求,session翻译成中文就是会话的意思,会话就是你说一句我回一句所有的聊天记录都能看到,可以理解成它的作用是发送一连串的请求,在这个过程中的cookie不会丢失。session的用法和request发送请求一样,使用get()、post()方法即可
1.2 例子
演示一个爬取17k小说网个人书架中的信息
- 由于要爬取的内容是个人书架的信息,所以必须要先进行登录后才能查看到,所以使用session先发送登录请求记录下cookie。需要注意的是登录的时候需要用户名和密码,这个是通过参数传递进去的,而参数名是什么就可以通过开发调试工具中的Network找到对应的请求参看。如果发送的方式是post则参数用data表示,如果是get方式则参数用params表示
- 得到cookie之后就可以按照正常爬取网页信息的方式进行爬取
import requests
url = "https://passport.17k.com/ck/user/login" # 登录的地址
session = requests.session() # 创建一个session对象
data = { # 登录的参数
'loginName': '测试爬虫的小明', # 用户名
'password': 'xiaoming123!' # 密码
}
resp = session.post(url, data=data) # 发送登录请求获得cookie
# 找到想要爬取的地址再用session发送请求
resp = session.get("https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919")
print(resp.json())
以上是一种看起来比较舒服的方式,不用session也是可以实现同样的效果,只不过需要在请求头中手动加上cookie,查看cookie的方法就是先用浏览器进行登录,然后在开发调试工具中查看请求的请求头部分都会存在一个cookie,直接复制到代码里就好了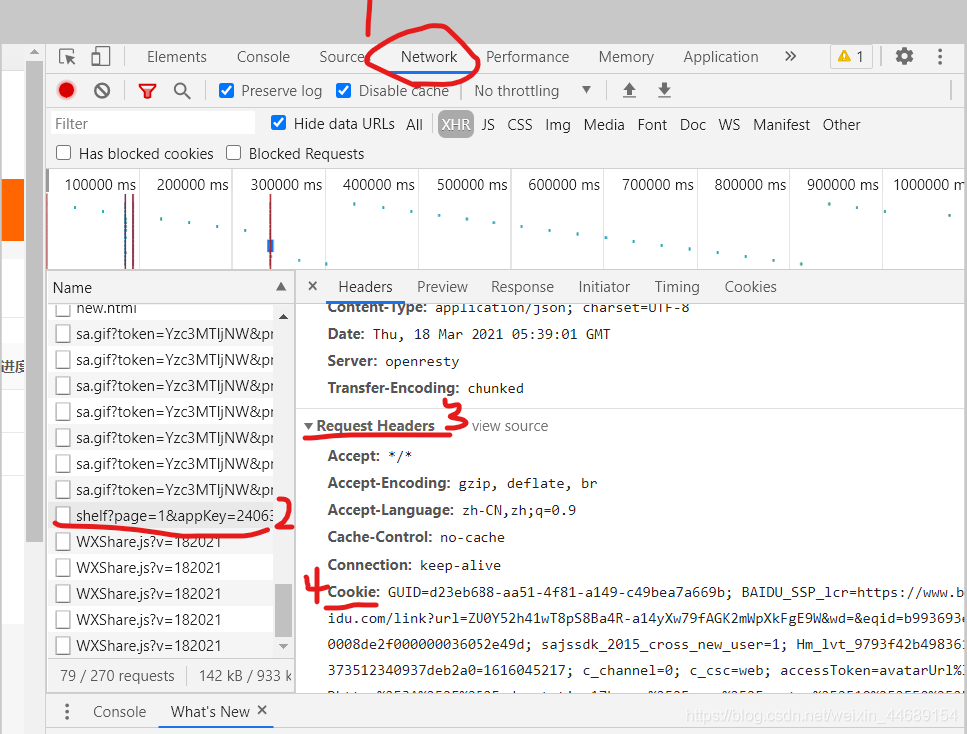
url = "https://user.17k.com/ck/author/shelf?page=1&appKey=2406394919" # 想要爬取数据的地址
headers = { # 直接在请求头加上cookie
"Cookie": 'GUID=d23eb688-aa51-4f81-a149-c49bea7a669b; BAIDU_SSP_lcr=https://www.baidu.com/link?url=ZU0Y52h41wT8pS8Ba4R-a14yXw79fAGK2mWpXkFgE9W&wd=&eqid=b993693e0008de2f000000036052e49d; sajssdk_2015_cross_new_user=1; Hm_lvt_9793f42b498361373512340937deb2a0=1616045217; c_channel=0; c_csc=web; accessToken=avatarUrl=https%3A%2F%2Fcdn.static.17k.com%2Fuser%2Favatar%2F10%2F50%2F85%2F76348550.jpg-88x88%3Fv%3D1616045356000&id=76348550&nickname=%E6%B5%8B%E8%AF%95%E7%88%AC%E8%99%AB%E7%9A%84%E5%B0%8F%E6%98%8E&e=1631597793&s=b64e37bcfd48da03; sensorsdata2015jssdkcross={"distinct_id":"76348550","$device_id":"17843cd157c67d-0e4381d62cb056-5771133-1327104-17843cd157da3e","props":{"$latest_traffic_source_type":"自然搜索流量","$latest_referrer":"https://www.baidu.com/link","$latest_referrer_host":"www.baidu.com","$latest_search_keyword":"未取到值"},"first_id":"d23eb688-aa51-4f81-a149-c49bea7a669b"}; Hm_lpvt_9793f42b498361373512340937deb2a0=1616045941'
}
resp = requests.get(url, headers=headers) # 直接用request发送请求
print(resp.json())
2 防盗链
防盗链简单说就是我发送了一个请求,然后服务器会进行溯源,查看我是在哪个页面发送了这个请求,通过检查我发送的这个请求上一级是哪个页面就可以判断是否是真实用浏览器访问的。这就是一种反爬的机制,如果遇到这种情况的话就可以在请求头里加上Referer的信息就好了(和user-agent的做法一样),从开发调试工具对应的请求中的请求头就能找到这个信息,直接复制下来就好了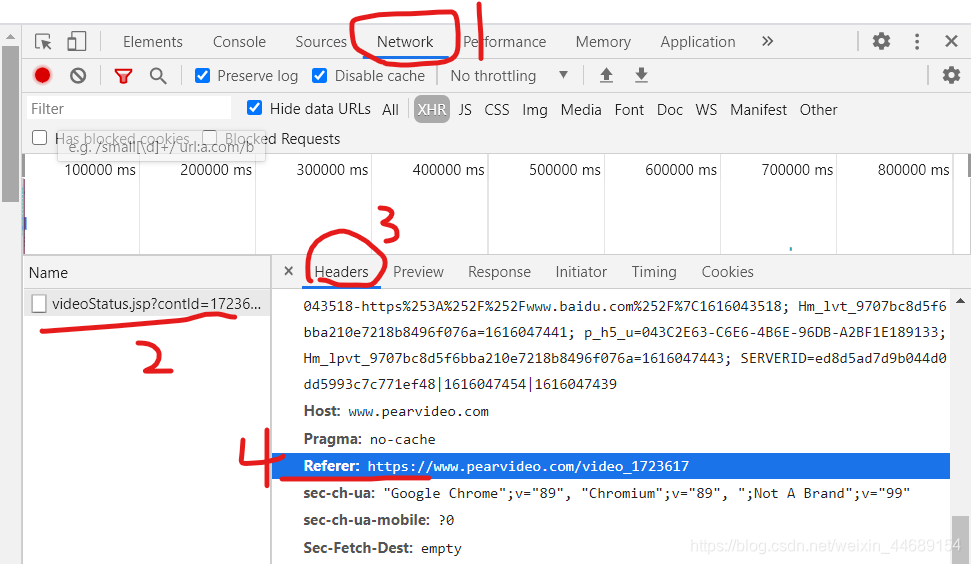
3 代理
当需要频繁大量的向同一个地址发送请求时,如果还是按照之前的正常做法来弄的话非常容易就会被服务器检测到异常的访问从而导致ip被封锁,便再也无法访问了。所以需要用到代理,原理就是通过第三方的机器去发送请求,相当于是在你和服务器之间多加了一个中介。所以如果需要大批量的发送请求,就可以同时使用多个代理交替着发送请求从而减小了同一个ip访问的频率。
使用方法和写一个请求头类似,在请求的参数中用proxies表示,具体的内容由 http://或https:// 加上IP和端口构成,至于选http还是https这个要看想要请求的那个地址是什么,保持一致就可以了
import requests
proxies = {
"https": "https://117.88.98.134:8118" # 代理的IP和端口
}
resp = requests.get("https://www.baidu.com", proxies=proxies)
print(resp.text)
4 爬取B站视频
B站视频地址是根据AV号和cid组合拼成一个api的地址,然后在该地址的请求里便存在真正的视频地址
- 查找AV号
打开想要爬取的视频网页,进入开发调试工具的控制台输入aid便可直接返回AV号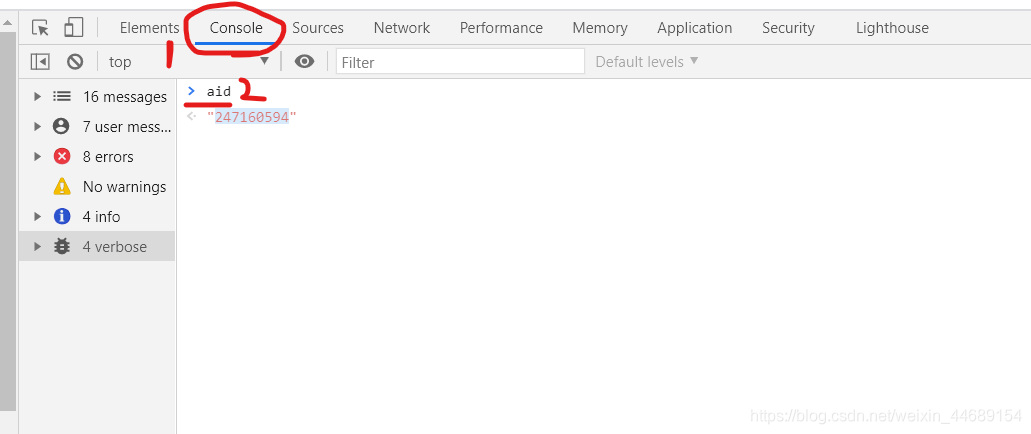
- 查找cid
同样在开发调试工具中选择Network找到pagelist这个请求便可找到cid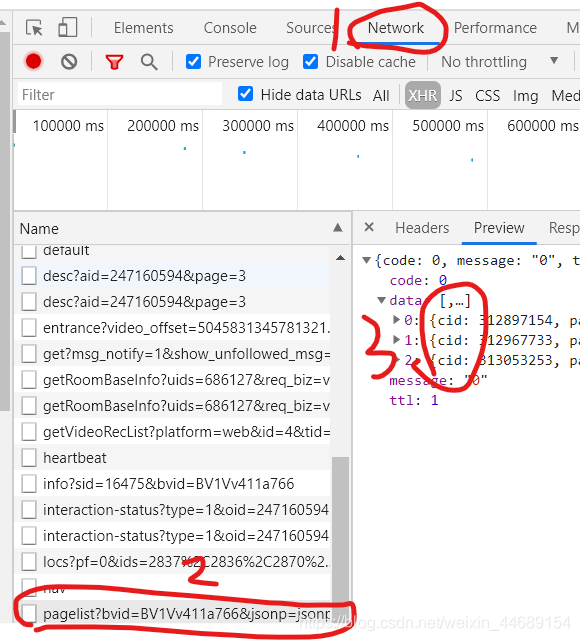
除了以上的两种方法之外,最简单的就是直接右键打开源代码然后按 ctrl+f 打开搜索aid和cid - 拼接api地址
需要拼接的api地址是 https://api.bilibili.com/x/player/playurl?avid=aid值&cid=cid值&qn=80&type=&otype=json
在对应位置填入aid和cid进入这个网址后会出现一堆json格式的数据,直接看会很难看,解决办法就是打开开发调试工具选择Network中的请求便可看到容易看的格式,在里面找到url,发现结尾是.flv,这是一种视频格式从而就可以确定这个url就是视频真正的地址。之后就正常请求这个url然后把请求结果保存到文件中就实现了视频下载,但是可能因为视频比较大下载的会有点慢。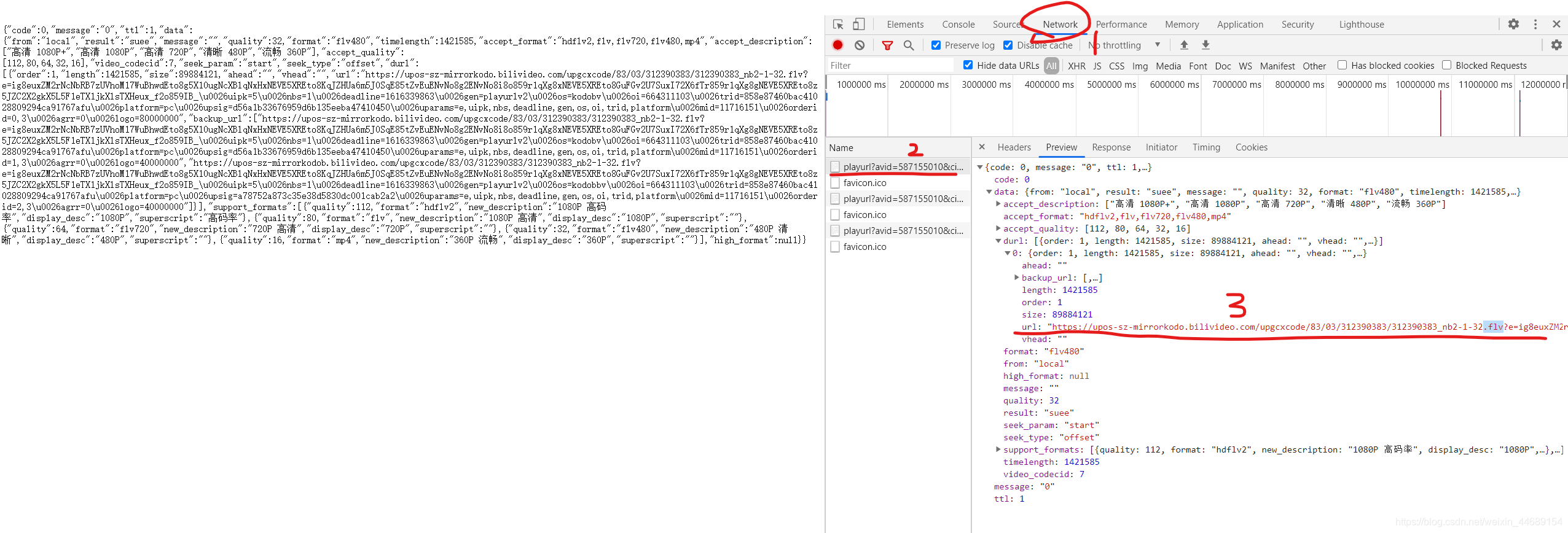
import requests
# 真正的视频地址
url = "https://upos-sz-mirrorkodo.bilivideo.com/upgcxcode/83/03/312390383/312390383_nb2-1-32.flv?e=ig8euxZM2rNcNbRB7zUVhoM17WuBhwdEto8g5X10ugNcXBlqNxHxNEVE5XREto8KqJZHUa6m5J0SqE85tZvEuENvNo8g2ENvNo8i8o859r1qXg8xNEVE5XREto8GuFGv2U7SuxI72X6fTr859r1qXg8gNEVE5XREto8z5JZC2X2gkX5L5F1eTX1jkXlsTXHeux_f2o859IB_&uipk=5&nbs=1&deadline=1616328773&gen=playurlv2&os=kodobv&oi=664311103&trid=4820d081d1b84f52addc8418c01240bau&platform=pc&upsig=fd04e4f140d858bb31ef23353f05b481&uparams=e,uipk,nbs,deadline,gen,os,oi,trid,platform&mid=11716151&orderid=0,3&agrr=0&logo=80000000"
headers = {
"Referer": "https://www.bilibili.com",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.90 Safari/537.36"
}
response = requests.get(url, headers=headers) # 请求视频内容
with open("{name}.flv".format(name="123"), "wb") as f: # 保存视频字节流保存到本地
for data in response.iter_content(1024):
f.write(data)
这个是最简单也是下载最完整的一个方法,还有另外一个方法是把一个个小片段下载下来然后再拼接成完整的视频。在视频网页打开开发调试工具在Network选项中的playurl请求中就有多个小片段的视频,请求这些地址也是可以下载的。但是还要考虑一个问题,这个下载的格式是.m4s格式的,这是B站缓存视频的一种格式,之后还得想办法转格式。所以并没有上一个方法好用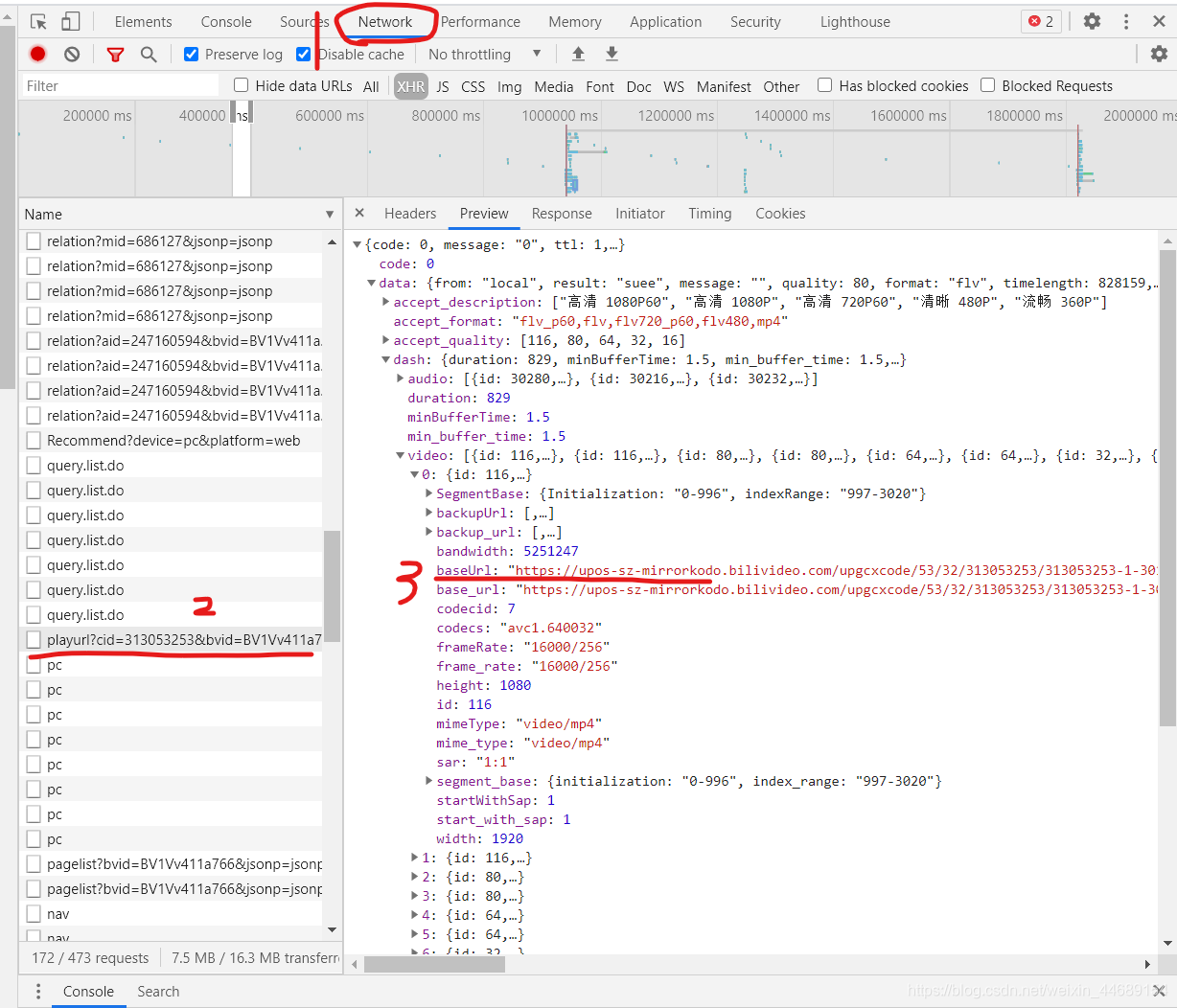

加入社区!打开量化的大门,首批课程上线啦!
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)