
[爬虫实战] 爬取json型数据
主要介绍了一般网站的爬取流程,并选用实际案例做具体讲解。
博客配套代码发布于github:智慧职教-json
相关实战案例:[爬虫实战] 爬取text型数据
相关爬虫专栏:JS逆向爬虫实战 爬虫知识点合集 爬虫实战案例
在爬取基础流程里,我们已经初步体验了爬虫的简单做法。这篇文章会进一步,较为详细的介绍大多数网页的爬取技巧与方式。
此篇文章用于大多数Content-type为json型的网站爬取。
以网页智慧职教为例,我们这里试图爬取页面里的标题,发布人与发布学校。
一、分析网站/寻找数据入口
1. 找对应数据入口
在开发者工具的网络板块中刷新网页,在几个数据包中刷新寻找,找到对应我们想要的数据,确定位置后开始爬取。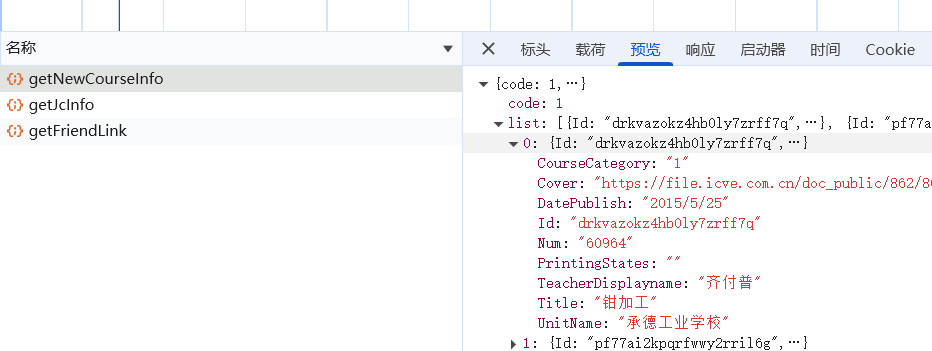
2. 分析网页
根据标头确认数据的请求url与请求方式(post)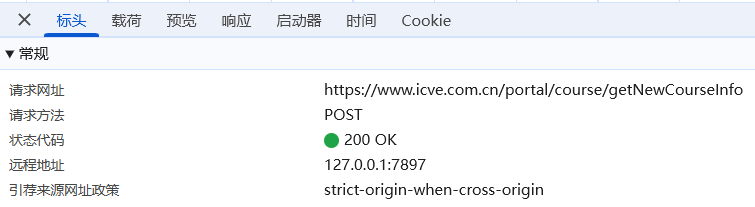
响应头里主要关注这个:
![]()
可以看出返回的数据格式json,需要我们用json格式解析(response.json())↑
如果是下方这种格式,则不用,直接解析就行(response.text)↓
![]()
再分析下面的请求参数:
请求参数:网站会检查其中特定的请求参数,如果检查不到或者错误就不会返回正确数据
注:这里请求参数中最重要的几个,大概率会检查,以后在发起请求时尽量带这几个参数:
User-Agent(身份验证):标识发起请求的客户端(如浏览器、爬虫)的类型版本与平台信息。
非常重要的请求参数,大概率会被检查,尽量携带。
UA反爬也是较为知名的反爬手段,但其反制措施也十分简单,在请求参数中找到它直接copy过来就行。
referer(防盗链): 其是表示是从哪个链接跳转到当前链接的,一旦链接来源不是网页规定,就立即阻止页面返回
cookie:涉及网站的信息记录保存,某些网站可能会检查这里是否携带。
此外,其他请求参数也可能会被检索。如果有请求参数携带了如密文般的参数,那么它也大概率是要被加入检查范围的。
如上,网站总体分析完毕后我们就可以开始写代码了。
二、爬取代码初始化
- 确认页面 -- url = 'https://www.icve.com.cn/portal/course/getNewCourseInfo?page='
- 确认请求头 --
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36',
'referer': 'https://www.icve.com.cn/portal_new/course/course.html'
} (这里的请求参数视情况而加,少了就再填) -
发起请求 -- response = requests.post(url=url,headers=header),再对数据进行 data = response.json()处理,获取json格式的字符串,成功得到我们最终想要的数据。

三、数据清洗
1.单页爬取并整体
这里想获取对应的数据,用的就是简单的py知识了:
上图单项数据我们看起来比较费劲,可以在浏览器中看结构: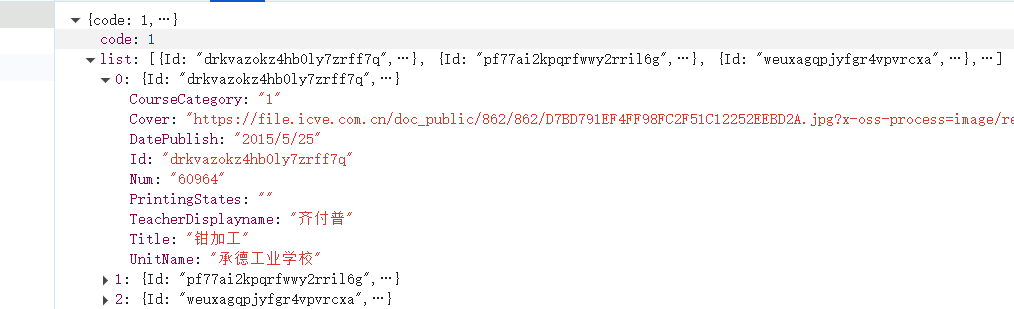
由图很容易看出具体结构,进入下步分析:
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36',
'referer': 'https://www.icve.com.cn/portal_new/course/course.html'
}
k = 1
for i in data['list']:
title = i['Title']
Teacher = i['TeacherDisplayname']
UnitName = i['UnitName']
print(k, title, Teacher, UnitName)
k += 1如上,可得输出答案: 
2. 多页爬取
还是简单的py知识,为其再在外层加个循环即可:
header = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/136.0.0.0 Safari/537.36',
'referer': 'https://www.icve.com.cn/portal_new/course/course.html'
}
# 多页数据爬取(假设爬取五页)
k = 1
for n in range(1,6):
url = f'https://www.icve.com.cn/portal/course/getNewCourseInfo?page={n}'
response = requests.post(url, headers=header)
data = response.json()
# 单页数据爬取
for i in data['list']:
title = i['Title']
Teacher = i['TeacherDisplayname']
UnitName = i['UnitName']
print(k, title, Teacher, UnitName)
k += 1如图:得到最终爬取结果:

四、总结
爬虫爬取公式一般分为如下:
分析网站 | 查看请求数据 - 写爬虫代码 | 成功获取请求 - 清洗数据 | 在获得数据的基础上做进一步处理
这个流程能处理一般网站,但面对其他更复杂的反爬机制时,就需要我们使用更高级的爬虫技巧进行处理。

加入社区!打开量化的大门,首批课程上线啦!
更多推荐
 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)