
量化金融学习笔记(一):Python处理股票数据与相关性探索
本文通过Python Tushare库获取工业富联和潍柴重机股票数据,进行相关性分析与可视化。主要步骤包括:数据获取与预处理、合并数据表、计算收益率和相关系数。结果显示两只股票日收益率的相关系数为0.4,呈现中等正相关。通过绘制价格走势对比图、收益率散点图、60日滚动相关系数图等,直观展示了两只股票的联动关系。此外,还分析了成交量与价格的关系,为投资组合构建提供数据支持。该分析过程展示了Pytho
本文主要从Tushare获取两只不同股票的数据进行相关性分析与数据可视化
刚开始学Python和数据分析的时候,总想找个实际的例子来练手,光看理论和代码感觉有点摸不着头脑,后来发现,股票数据是个特别好的切入点,既有意思,又能马上看到结果。
这次便尝试用Python来看看两只股票——工业富联和潍柴重机;这也是我在二级市场反复做T的两只股票,我一直在好奇,它们的股价走势到底有没有关系,是齐涨齐跌,还是各走各的?如果搭建一个投资组合,这俩是否能作为风险对冲?不能光凭感觉猜,得用数据说话。
整个过程就像一次小探险:
- 找数据:学会了怎么用Tushare这个工具包把股票的历史行情数据下载下来。
- 整理数据:用Pandas把乱七八糟的数据整理得干干净净,方便计算。
- 计算:算出了它们每天的涨跌幅,以及最重要的一个数字——相关系数,它精确地告诉我这两只股票联动的程度。
- 画图:用Matplotlib画出了好几张图,价格走势、散点图什么的,结论一目了然
一、安装数据包
import pandas as pd
import pkg_resources
import subprocess
import sys
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])
# 使用示例:如果你需要安装tushare库
try:
import tushare as ts
except ImportError:
install('tushare')
import tushare as ts【import 语句】
- 是什么:就像咱们要做木工,需要从工具箱里拿出锯子、锤子、尺子。
import就是告诉Python:“我要使用pandas这个工具箱,为了方便,我给它起个外号叫pd。” - 用法:
pandas用于数据处理,pkg_resources用于检查已安装的包,subprocess和sys用于运行系统命令(比如安装包)。不导入就无法使用它们的功能。
【install函数】
- 是什么:是在Python环境中执行一条系统命令。
sys.executable是当前Python解释器的路径,整条命令等价于在命令行/终端中输入pip install tushare。 - 为什么:用代码代替手动操作,实现环境的自动化配置,让程序更具可移植性和易用性。
代码意思是:定义一个install (package)的函数,subprocess类似于运行系统命令,给内部打check_call 的检查电话,联系sys.executable解释器,要求一“-m”模块化的形式,让pip部门执行安装install的命令,安装的package就是工具包,它可以是我想安装的Tushare,也可以是其他的包。
【try-except 语句】
- 是什么:try-except是一段“防错”代码。它的逻辑是:“尝试(try) 做某件事,如果发生了特定的错误(except),那就执行另一段代码来补救。”
- 为什么:因为刚开始tushare一直安装不成功,于是我将尝试用这个代码来处理异常,如果没找到,打印出(
ImportError),自动安装它,然后再导入。
二、Tushare认证与初始化 - 拿到“数据仓库的钥匙”
#输入token
token = '你的token' # 这里你的token是假的,非常好!永远不要泄露真实的token。
ts.set_token(token) # 把钥匙交给门卫(Tushare库)
pro = ts.pro_api() # 门卫给你一个功能完整的入口(pro接口对象)Tushare是我之前学财务大数据挖到的宝藏网站,也是目前很多高校同学在用的免费开源金融数据库,Tushare的数据有很多种类型,大家可以注册账号后进入个人中心,这部分就有个人的token信息。
【Token(令牌)】
- 是什么:个人身份凭证,相当于进入数据大楼的“门禁卡”或“钥匙”。Tushare通过它来识别用户身份、统计数据调用量并进行权限管理。
【ts.set_token(token)】
- 在tushare这个数据大楼的前台进行令牌登记。
【pro = ts.pro_api()】
- 是什么:创建一个API接口对象
pro。pro是Tushare Pro提供的统一入口对象,所有数据获取函数(如pro.daily())都是这个对象的方法。类似大楼前台给你一个门禁卡,你可以用这个卡调动Tushare数据大楼存储在任何一个地方的数据。
三、获取与预处理单只股票数据 - 采集“原材料”并“初步加工”
我们以工业富联为例,潍柴重机的逻辑完全一样。
gyfl = pro.daily(ts_code='601138.SH', start_date='20240924', end_date='20250924')调用Tushare的日线行情接口。
参数:
ts_code: 股票代码,注意后缀.SH(上海交易所)和.SZ(深圳交易所)必须正确。start_date/end_date: 起止日期,格式为'YYYYMMDD'。- 返回:一个Pandas的DataFrame,可以把它直观地理解为一张Excel表格,有行有列。
print(len(gyfl)) # 查看获取到了多少行数据
print(gyfl.head(10))
gyfl['trade_date'] = pd.to_datetime(gyfl['trade_date']) # 将日期字符串转为日期格式
gyfl.set_index('trade_date', inplace=True) # 将‘trade_date’列设置为索引
gyfl.sort_index(inplace=True) # 按索引(日期)排序
gyfl_1 = gyfl[['close', 'pct_chg', 'vol', 'amount']] # 选择需要的列- 用len函数查看一共获取了多少列数据,打印出来正好是244个交易日。
- print(gyfl.head(10))打印出表格的前10行看看具体的数据情况,跑出来的前十行数据如下:
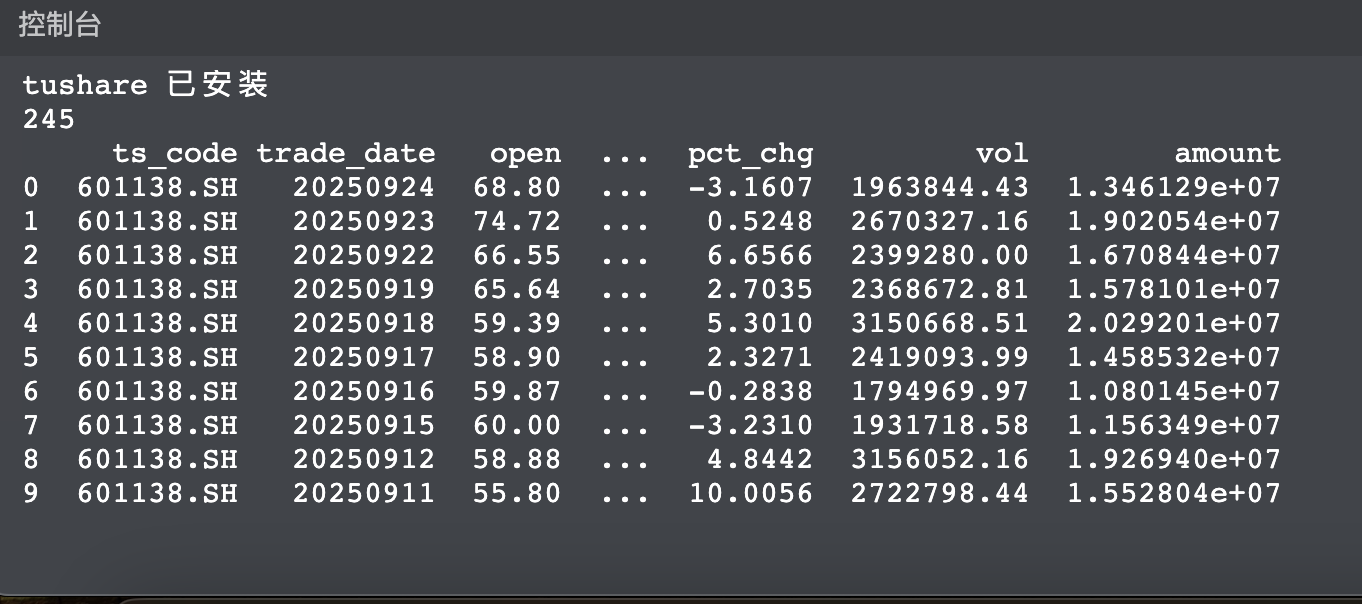
可以发现:各列分别是股票代码、交易时间、开盘价,...,涨跌幅,交易量、总额等信息。
观察发现,trade_date 的格式是倒序,且非日期格式,基于此,下一步我们要将改列转换为为日期格式
gyfl ['trade_date']=pd.to_datetime(gyfl['trade_date'])
因为后面要和潍坊重机进行比较,会用到merge函数,两个不同的股票,需要锚定一个索引,日期便是最好的选择:
gyfl.set_index("trade_date",inplace=True) 通过set_index函数把日期设置为索引值,inplace=True指的是在原有的datafame上进行修改。
设置成索引值后,进一步对日期进行处理,使其排序从前往后。
gyfl.sort_index(inplace=True)
以上,表格已经处理成按照交易日期(日期格式)从前往后的排序,接下来就是把众多的数据列筛选留下需要的列(收盘价,涨跌幅,交易量,总额):
gyfl_1 = gyfl[['close', 'pct_chg', 'vol', 'amount']] # 选择需要的列
写完后大家可以价格print(gyfl_1.head(3))打印出前三行看看
潍坊重机写法如上,不再重复。
四、数据合并与收益率计算 - 分析的“核心引擎”
我们现在有两个独立的DataFrame:gyfl_1(工业富联)和 wfzj_1(潍柴重机)。它们就像是两张分开的Excel表。
- 要分析它们的相关性,就必须把它们的数据按日期对齐,放在一起比较。合并就是为了创建一张总表,每一行都是同一个交易日的两只股票的数据。
#合并表格
merged_data = gyfl_1.merge(wfzj_1, left_index=True, right_index=True, how='outer', suffixes=('_gyfl', '_wfzj'))1.merge函数参数详解:
这是一个非常强大且常用的函数,我们来拆解它的每个参数:
gyfl_1.merge(wfzj_1, ...): 这表示以gyfl_1为“左表”,将wfzj_1“右表”合并到它上面。left_index=True, right_index=True: 这是合并的“依据”。它告诉Pandas:“请使用左表的索引(gyfl_1的日期)和右表的索引(wfzj_1的日期)作为键来进行匹配。” 因为我们在前面已经把日期设置为了索引,所以这里用索引合并非常方便。how='outer': 这是合并的方式,决定了哪些日期应该出现在最终表里。'inner'(内连接):只保留两个表都有的日期。如果某天一只股票停牌,那天数据就会被丢弃。'outer'(外连接):保留两个表出现的所有日期。如果某天一只股票停牌,那天的数据就是NaN(空值)。 在股票分析中,这是更常用的方式,因为它保留了完整的时间序列,我们可以后续处理停牌造成的空值。
suffixes=('_gyfl', '_wfzj'): 因为两个表都有close,change等同名的列,合并后无法区分。这个参数自动为左表的同名列添加_gyfl后缀,为右表的同名列添加_wfzj后缀。这是避免列名冲突的标准做法。
2.处理缺失值
# 对缺失值进行向前填充(对于停牌的情况)
merged_data.fillna(method='ffill', inplace=True)为什么会有缺失值(NaN)?
- 正是因为我们在合并时使用了
how='outer'。如果“工业富联”某天交易了而“潍柴重机”停牌(或反之),那么停牌股票的那一行数据就是NaN。
2. 为什么要处理?
- 后续计算收益率等操作无法在NaN上进行,会导致错误。
ffill是 “forward fill”(向前填充) 的缩写。- 金融逻辑:它用停牌前最后一个交易日的有效数据来填充停牌期间的数据。
这是一种行业惯例。假设股票停牌,其价格和成交量理论上就“冻结”在停牌前的状态,直到复牌。这比直接删除数据(dropna())更能保持时间序列的连续性,避免计算收益率时产生巨大的跳跃。
3.计算收益率
# 计算两只股票的每日收益率
merged_data['return_gyfl'] = merged_data['close_gyfl'].pct_change()
merged_data['return_wfzj'] = merged_data['close_wfzj'].pct_change()
# 删除包含NaN的行(第一行)
returns_data = merged_data[['return_gyfl', 'return_wfzj']].dropna()收益率解决了这些问题:
- 标准化:它将涨幅标准化为百分比,使得不同价格的股票之间可以公平比较。
- 平稳性:收益率序列更接近平稳序列,其统计性质(如均值、方差)相对稳定,更适合进行统计分析(如计算相关性)。
- 可加性:多期的总收益率可以由单期收益率计算得出,符合投资逻辑。
.pct_change() 是如何计算的?
它的计算公式非常简单,但极其重要:
今日收益率 = (今日收盘价 - 昨日收盘价) / 昨日收盘价 换句话说,它就是计算今日价格相对于昨日价格的百分比变化。
为什么第一行是NaN?为什么要dropna()?
- 对于数据的第一天(最早的那个交易日),它没有“昨天”的数据,所以无法计算收益率,结果为NaN。
dropna()会删除所有包含NaN的行。在这里,它主要就是删除了这第一行,确保returns_data是一个纯净的、可供计算的收益率数据框。
4.计算相关性
# 计算相关性
correlation = returns_data['return_gyfl'].corr(returns_data['return_wfzj'])
print(f"\n工业富联和潍柴重机日收益率的相关系数: {correlation:.4f}")f-string (f"...")
- 字符串前面的
f是核心标志,它告诉Python:“这是一个格式化字符串,里面会有用花括号{}包起来的变量或表达式,请把它们的值计算出来并填充到这个位置。” - 没有
f的话,{correlation:.4f}会被当成普通文本直接打印出来。
代码里的 {correlation:.4f} 是一个格式化指令,它确保最终打印出来的相关系数是一个简洁、专业、四舍五入到小数点后4位的数字
五、可视化分析
1.环境配置
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns
matplotlib.rcParams['font.sans-serif'] = ['Arial Unicode MS'] # 或者其他系统可用的中文字体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决负号显示问题matplotlib是老外做的一个绘图的工具,
seaborn属于matplotlib的皮肤,装上这个能让matplotlib出来的图更美观
中文字体设置:matplotlib 默认不支持中文显示,直接绘图会导致标签显示为方框。通过 rcParams 设置一个系统中存在的中文字体(如 Arial Unicode MS, SimHei, PingFang SC等)来解决。
负号显示:同样,设置 unicode_minus=False 是为了确保负号(‘-’)能正常显示。
2.价格走势对比图
plt.figure(figsize=(14, 7))
plt.plot(merged_data.index, merged_data['close_gyfl'], label='工业富联')
plt.plot(merged_data.index, merged_data['close_wfzj'], label='潍柴重机')
plt.title('工业富联 vs 潍柴重机: 价格走势对比')
plt.xlabel('日期')
plt.ylabel('价格(元)')
plt.legend()
plt.grid(True)
plt.show()- 先设置画布尺寸:
plt.figure(figsize=(14, 7))(宽14英寸,高7英寸)。 - 使用两次
plt.plot()分别绘制两条折线图。merged_data.index通常是日期时间数据,作为X轴;close列是收盘价,作为Y轴。label参数为图例提供标签。 plt.legend()用于显示图例,让我们能分清哪条线对应哪支股票。plt.grid(True)添加网格线,让读数更加方便。
写完跑出来的图片如下:
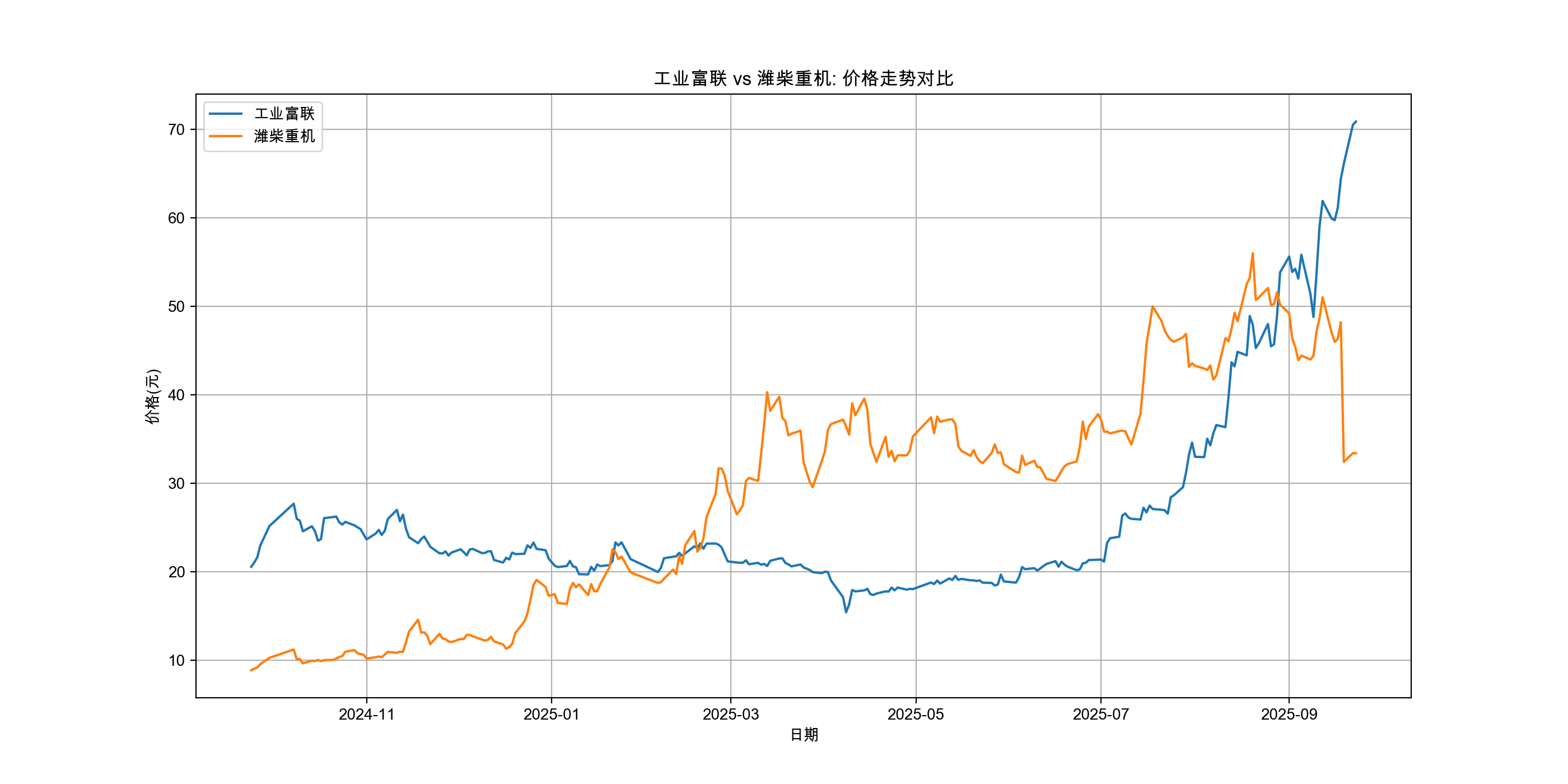
分析目的:趋势分析与相对强弱对比
- 长期趋势:两只股票总体上处于上涨、下跌还是震荡趋势?
- 相对强弱:在一段时间内,哪只股票表现更强?例如,牛市中是工业富联涨得多,还是潍柴重机涨得多?熊市中谁更抗跌?
- 联动性初步观察:它们的涨跌节奏是否大致同步?(为后面的相关性分析做铺垫)
3.收益率散点图
# 2. 绘制收益率散点图
plt.figure(figsize=(10, 6))
plt.scatter(returns_data['return_gyfl'], returns_data['return_wfzj'], alpha=0.5)
plt.xlabel('工业富联日收益率')
plt.ylabel('潍柴重机日收益率')
plt.title('两只股票日收益率散点图')
plt.axhline(y=0, color='k', linestyle='-', alpha=0.3)
plt.axvline(x=0, color='k', linestyle='-', alpha=0.3)
plt.grid(True)
plt.show()- plt.figure(figsize=(10, 6)): 创建一个新的图形窗口,参数设置图形的尺寸为10英寸宽、6英寸高
- plt.scatter(): 创建散点图函数,returns_data['return_gyfl']: 工业富联的日收益率数据,作为X轴;returns_data['return_wfzj']: 潍柴重机的日收益率数据,作为Y轴,alpha=0.5: 设置点的透明度为50%,当点重叠时,透明度可以让重叠区域显得更深,帮助我们观察点的密度分布
- plt.axhline(): 添加一条水平参考线;y=0: 将水平线放在Y轴的0位置(收益率为0的位置);color='k': 设置线条颜色为黑色('k'是黑色的简写);linestyle='-': 设置线型为实线;alpha=0.3: 设置线条透明度为30%,使其不那么突出这条线帮助我们直观地判断收益率是正还是负
- plt.axvline(): 添加一条垂直参考线,x=0: 将垂直线放在X轴的0位置;其他参数与水平线相同
写完跑出来的图片如下:
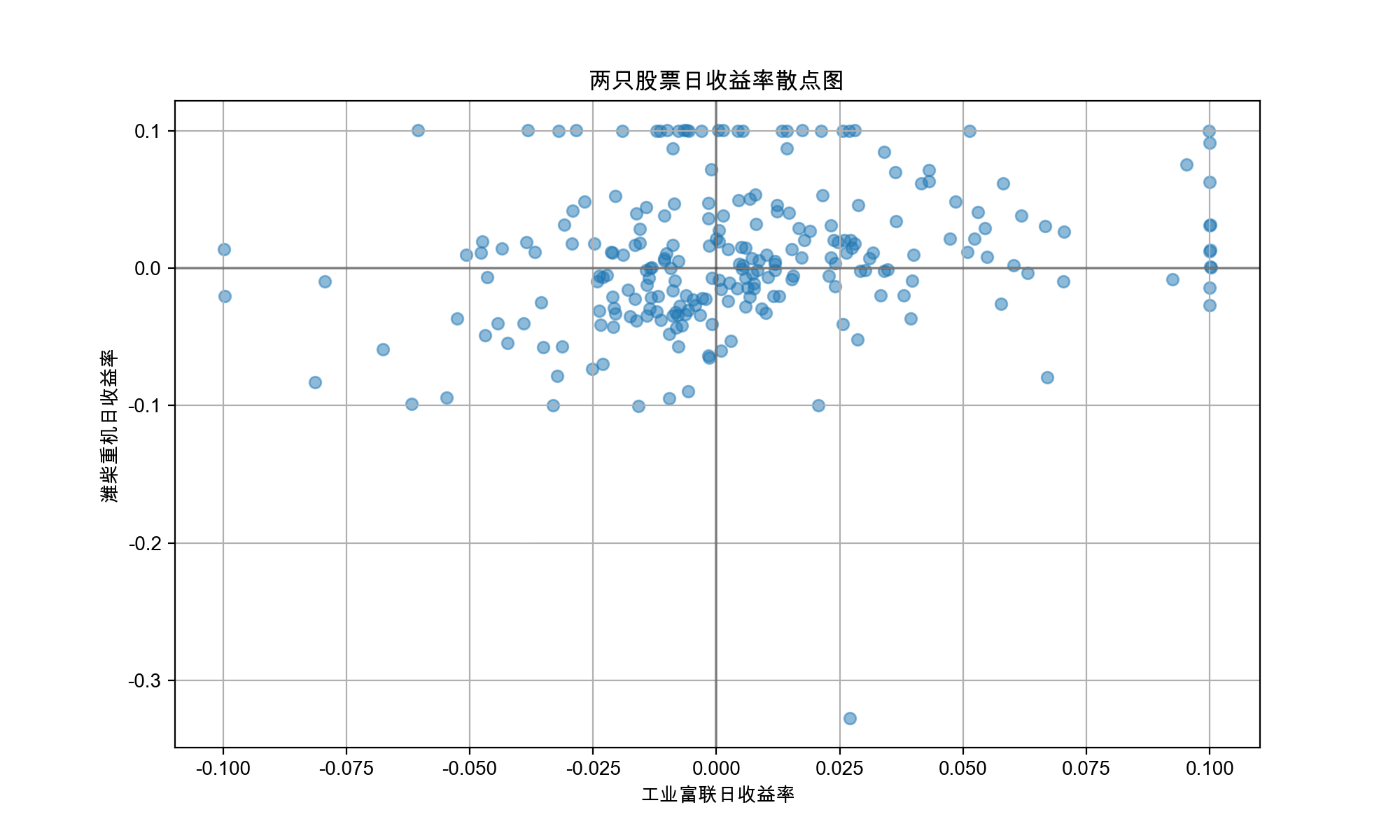
分析目的:静态相关性分析
- 相关性强弱与方向:两只股票的每日收益率是正相关(同涨同跌)、负相关(此涨彼跌)还是无关?
- 分散化效果:如果点分散且接近圆形,说明两者相关性弱,组合投资能有效分散风险。如果点集中呈斜线,说明联动性强,分散风险效果差。
4.收益率分布直方图
fig, axes = plt.subplots(1, 2, figsize=(14, 5))
axes[0].hist(returns_data['return_gyfl'], bins=50, alpha=0.7, color='red')
axes[0].set_xlabel('日收益率')
axes[0].set_ylabel('频率')
axes[0].set_title('工业富联日收益率分布')
axes[1].hist(returns_data['return_wfzj'], bins=50, alpha=0.7, color='blue')
axes[1].set_xlabel('日收益率')
axes[1].set_ylabel('频率')
axes[1].set_title('潍柴重机日收益率分布')
plt.tight_layout()
plt.show()- fig, axes = plt.subplots(1, 2, figsize=(14, 5)): 创建1行2列的子图布局,整体画布尺寸为14x5英寸。
- axes[0].hist(...): 在第一个子图绘制工业富联(红色)的收益率分布,分为50个柱子,alpha=0.7,点的透明度70%,颜色红色
- axes[1].hist(...): 在第二个子图绘制潍柴重机(蓝色)的收益率分布。分为50个柱子,alpha=0.7,点的透明度70%,颜色蓝色
- set_xlabel, set_title 等:分别为每个子图设置坐标轴标签和标题。
- plt.tight_layout(): 自动调整子图间距,防止重叠。
写完跑出来的图片如下:
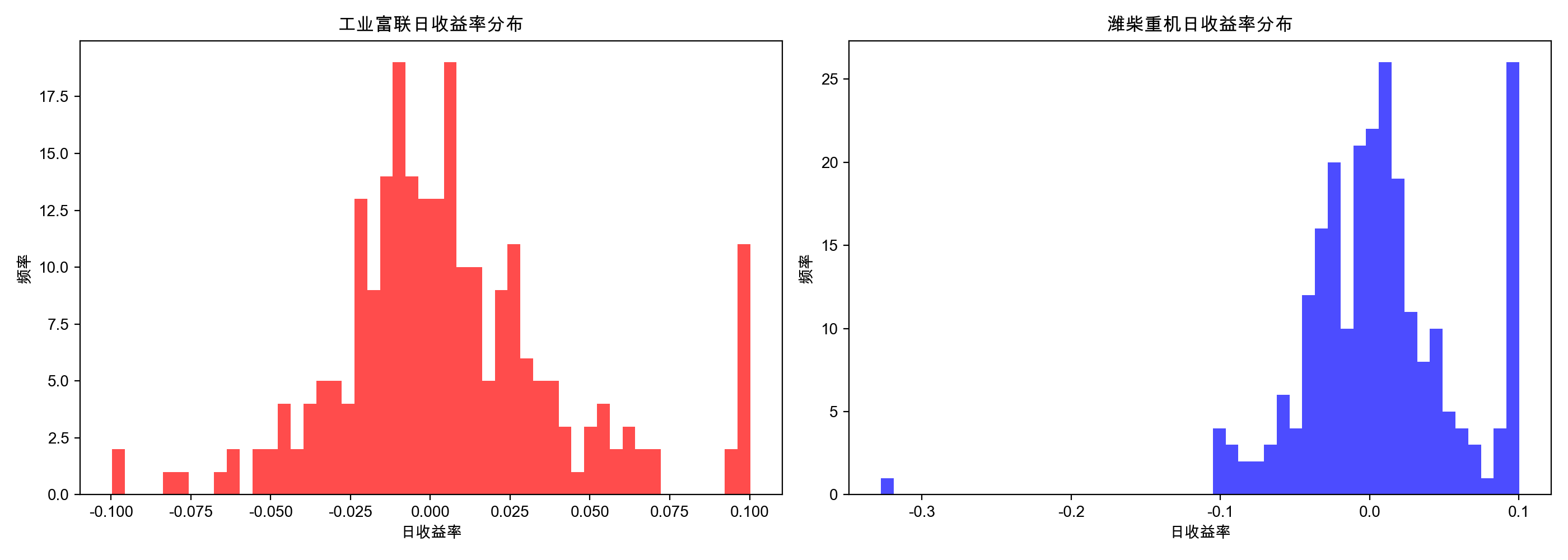
分析目的:风险与波动性分析:
- 收益分布特征:分布是否对称?如果出现“左偏”(左边尾巴长),说明极端下跌的日子比极端上涨的日子多,风险更大。
- 极端值:可以观察到发生巨大涨幅或跌幅的频率,评估“黑天鹅”风险。
5.60日窗口相关性滚动
# 4. 计算滚动相关性(60日窗口)
rolling_corr = returns_data['return_gyfl'].rolling(window=60).corr(returns_data['return_wfzj'])
plt.figure(figsize=(12, 6))
plt.plot(rolling_corr.index, rolling_corr)
plt.title('工业富联与潍柴重机60日滚动相关系数')
plt.xlabel('日期')
plt.ylabel('相关系数')
plt.axhline(y=0, color='k', linestyle='-', alpha=0.3)
plt.grid(True)
plt.show()returns_data['return_gyfl'].rolling(window=60):对"工业富联"的收益率序列创建一个60交易日的滚动窗口;.corr(returns_data['return_wfzj']):在每个滚动窗口内,计算它与"潍柴重机"收益率的相关系数;结果rolling_corr是一个时间序列,显示两者相关性如何随时间变化
- plt.figure(figsize=(12, 6)),创建图形,设置尺寸为12×6英寸
- plt.plot(rolling_corr.index, rolling_corr),绘制滚动相关系数的时间序列折线图;X轴是时间,Y轴是相关系数值(-1到1之间)
- plt.axhline(y=0, color='k', linestyle='-', alpha=0.3);在y=0处添加一条浅灰色水平参考线,线的样式是“-”,透明度是30%
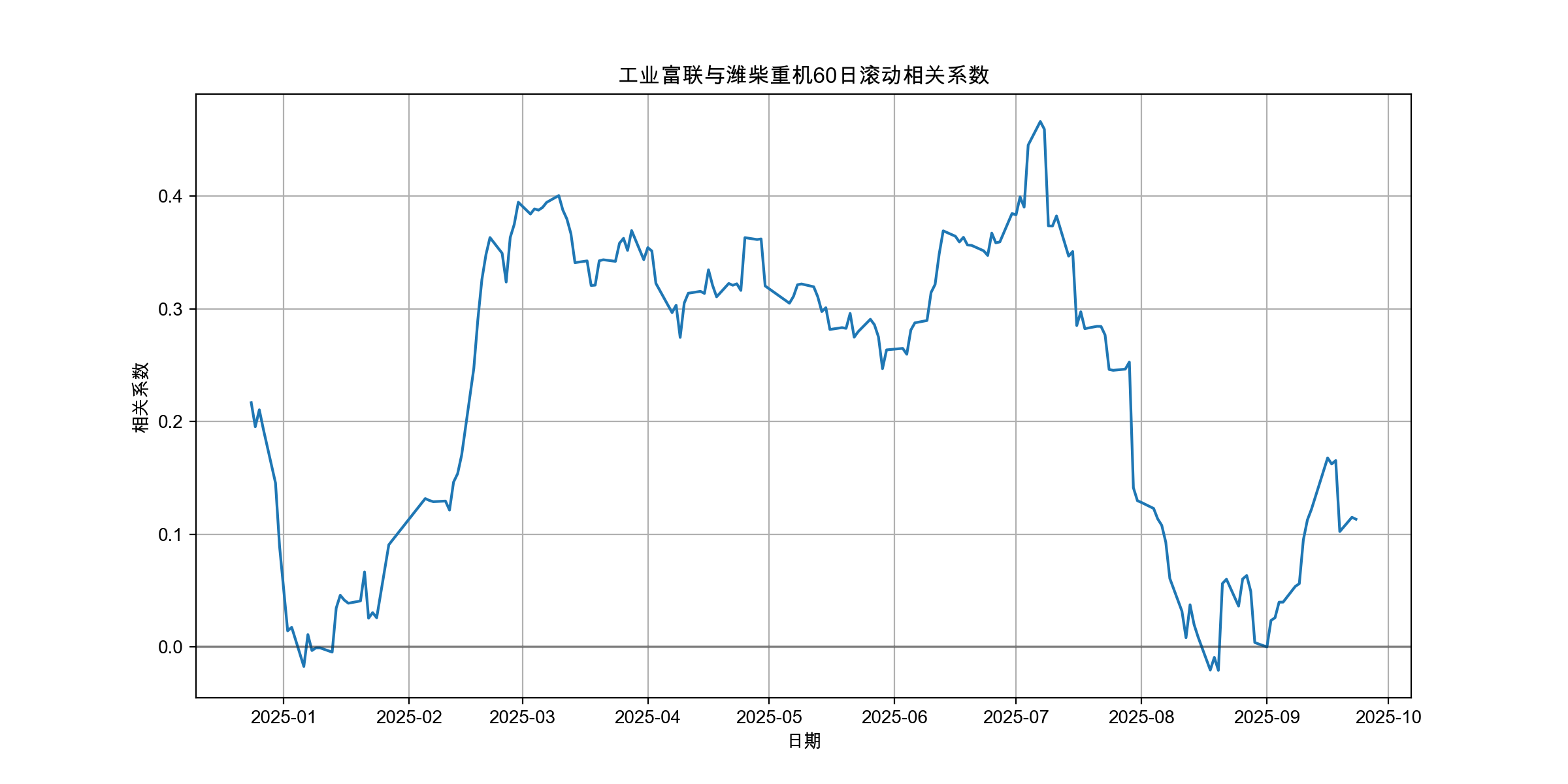
分析目的:动态相关性分析
- 相关性是否稳定:两只股票的关系是一直不变,还是随着时间变化?
- 市场阶段的影响:相关性在牛市、熊市或震荡市中是否有显著差异?通常市场大跌时,个股相关性会急剧升高(同跌)。
- 结构性变化点:寻找相关性发生显著、持续性变化的时点,这可能预示着行业逻辑或市场风格的转变
6.分析交易量与价格的关系
# 5. 分析交易量与价格的关系
# 计算交易量的滚动平均值(20日)
merged_data['vol_ma20_gyfl'] = merged_data['vol_gyfl'].rolling(window=20).mean()
merged_data['vol_ma20_wfzj'] = merged_data['vol_wfzj'].rolling(window=20).mean()
# 创建子图
fig, axes = plt.subplots(2, 2, figsize=(15, 10))
# 工业富联价格与成交量
axes[0, 0].plot(merged_data.index, merged_data['close_gyfl'], 'r-', label='价格')
axes[0, 0].set_ylabel('价格(元)', color='r')
axes[0, 0].tick_params(axis='y', labelcolor='r')
axes2_00 = axes[0, 0].twinx()
axes2_00.plot(merged_data.index, merged_data['vol_ma20_gyfl'], 'b-', alpha=0.5, label='成交量(20日均)')
axes2_00.set_ylabel('成交量', color='b')
axes2_00.tick_params(axis='y', labelcolor='b')
axes[0, 0].set_title('工业富联: 价格与成交量关系')
# 潍柴重机价格与成交量
axes[0, 1].plot(merged_data.index, merged_data['close_wfzj'], 'r-', label='价格')
axes[0, 1].set_ylabel('价格(元)', color='r')
axes[0, 1].tick_params(axis='y', labelcolor='r')
axes2_01 = axes[0, 1].twinx()
axes2_01.plot(merged_data.index, merged_data['vol_ma20_wfzj'], 'b-', alpha=0.5, label='成交量(20日均)')
axes2_01.set_ylabel('成交量', color='b')
axes2_01.tick_params(axis='y', labelcolor='b')
axes[0, 1].set_title('潍柴重机: 价格与成交量关系')
# 工业富联收益率分布
axes[1, 0].hist(returns_data['return_gyfl'], bins=50, alpha=0.7, color='red')
axes[1, 0].set_xlabel('日收益率')
axes[1, 0].set_ylabel('频率')
axes[1, 0].set_title('工业富联日收益率分布')
# 潍柴重机收益率分布
axes[1, 1].hist(returns_data['return_wfzj'], bins=50, alpha=0.7, color='blue')
axes[1, 1].set_xlabel('日收益率')
axes[1, 1].set_ylabel('频率')
axes[1, 1].set_title('潍柴重机日收益率分布')
plt.tight_layout()
plt.show()merged_data['vol_ma20_gyfl'] = ...:计算20日成交量均线,用于平滑每日波动,更好观察成交量趋势。plt.subplots(2, 2, figsize=(15, 10)):创建2行2列共4个子图的画布。fig: 代表整个大画布。axes: 是一个 2x2的数组,用于访问每一个子图。访问方式如下:axes[0, 0]-> 第1行,第1列(左上角的子图)axes[0, 1]-> 第1行,第2列(右上角的子图)axes[1, 0]-> 第2行,第1列(左下角的子图)axes[1, 1]-> 第2行,第2列(右下角的子图)
左上/右上子图:价量关系分析(核心)
- 使用 双Y轴 技巧:
- 左Y轴(红色):显示股票价格走势
- 右Y轴(蓝色):显示20日成交量均线
- 分析目的:观察价格与成交量的联动效应。通常“价升量增”是健康上涨信号,“价升量缩”可能预示趋势乏力。
左下/右下子图:收益率分布
- 绘制收益率的直方图,展示其波动范围和分布形态。
- 分析目的:评估股票的风险特征。图形越“胖”(分散)说明波动性越大,风险越高。
最终效果:将价格、成交量、收益率分布三个关键分析维度整合在一张图中,便于快速对比两只股票的综合表现。
写完跑出来的图片如下:
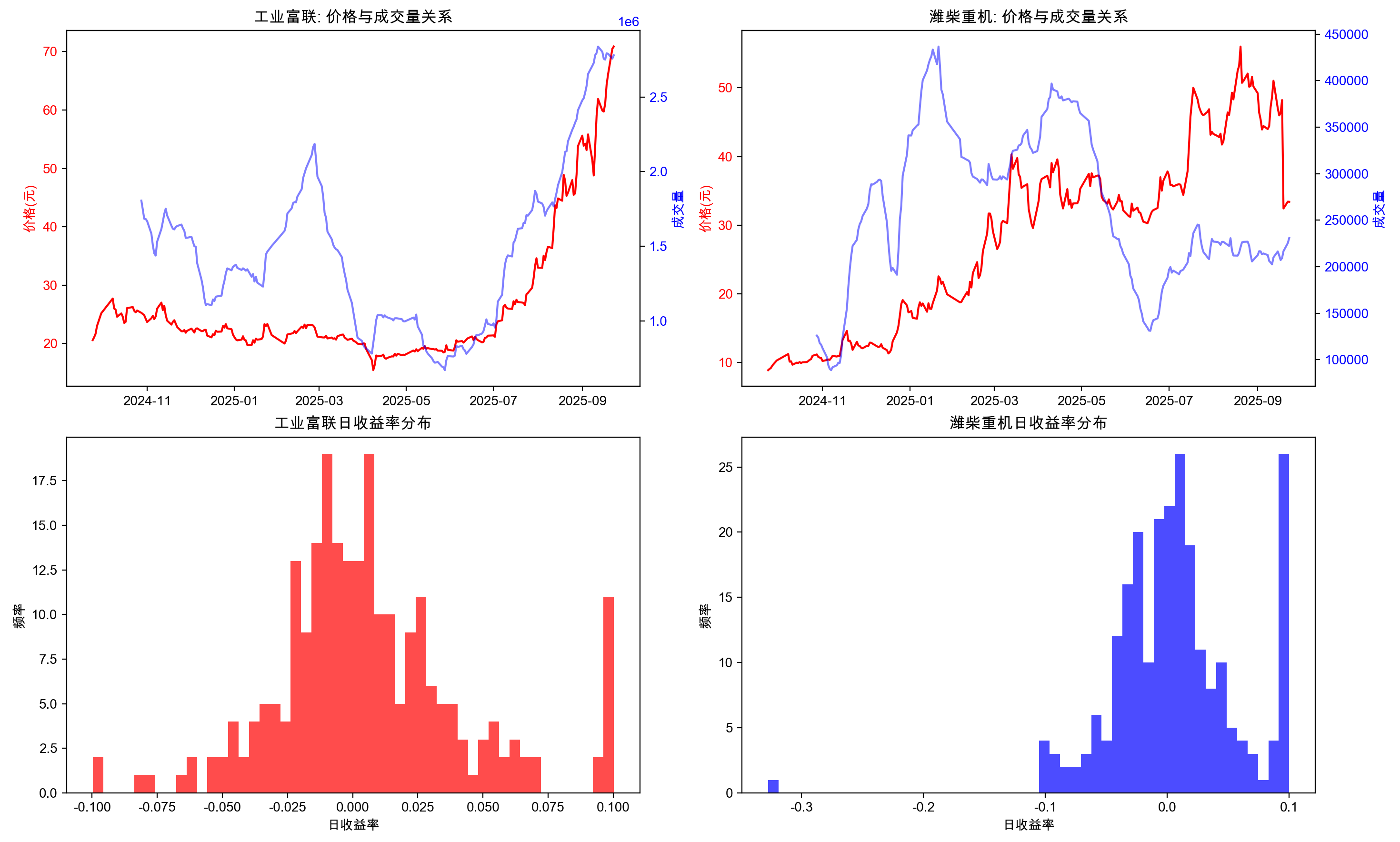
分析目的:技术分析与风险综合评估
上半部分(价量关系):
- 量价配合:健康的上涨通常伴随着成交量的放大(价升量增)。如果价格上涨但成交量萎缩(价升量缩),可能预示上涨动力不足,趋势难以持续。
- 突破确认:价格突破关键位置时,是否有成交量的放大来确认突破的有效性?
- 趋势判断:成交量均线的上升或下降趋势,可以辅助判断资金是在流入还是流出该股票。
下半部分之前收益率直方图已经写了,此处放出来一个是为了多表创建的练习,一个是为了同一界面方便好看,这里不再重复。

加入社区!打开量化的大门,首批课程上线啦!
更多推荐


 12
12 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)