
爬虫库Urllib(urllib.request.Request与urllib.request.urlopen)
Python3中-爬虫库Urllib概述urllib.request1. urllib.request.Request2. urllib.request.urlopen3. urllib.request.urlopen和urllib.request.Request实例演示概述问:Urllib能做什么?答:常用在爬虫开发、API(应用程序编程接口)数据获取、测试;问:Urllib需要安装吗?答:Py
·
Python3中-爬虫库Urllib
概述
- 问:Urllib能做什么?
答:常用在爬虫开发、API(应用程序编程接口)数据获取、测试; - 问:Urllib需要安装吗?
答:Python自带的标准库,直接引用(import)即可; - 问: Urllib、Urllib2和Urllib3区别?
答:①在Python2中分为Urllib和Urllib2,Urllib2可以接收一个Request对象(可设置一个URL的请求头[Headers]),而Urllib只接收一个URL,不能伪装用户代理字符串等。Urllib模块可以提供进行Urlencode的方法,该方法用于GET查询字符串的生成,而Urllib2不具有这样的功能。所以Urllib与Urllib2经常在一起使用。
②在Python 3中,将Urllib和Urllib2合并在一起使用,并且命名为Urllib,可以处理URL的组件集合。
③Urllib3
从网上找到的介绍是这样的:
Urllib3功能非常强大,但是用起来却十分简单:
示例: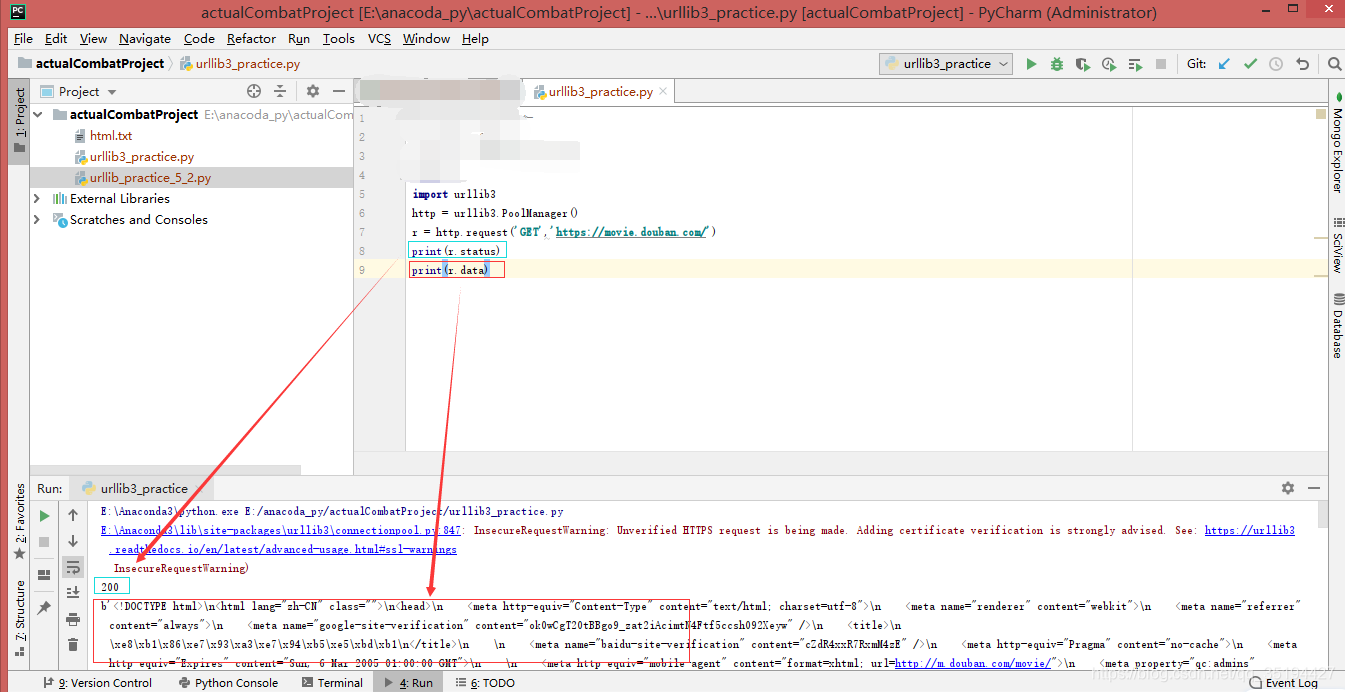
urllib3的安装方法如下:
后续再单独学习研究一下这个urllib3吧,本次我们还是以python3的Urllib库为核心; - Urllib里的模块常使用的模块如下表:
| 模块 | 简述 |
|---|---|
| urllib.request | 用于打开和读取URL |
| urllib.error | 包含提出的例外urllib.request |
| urllib.parse | 用于解析URL |
| urllib.robotparser | 用于解析robots.txt文件 |
urllib.request
1. urllib.request.Request
语法如下:
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
| 参数 | 说明 |
|---|---|
| url | 需要访问的网站的URL地址。url格式必须完整 |
| data | 默认值为None, Urllib判断参数data是否为None从而区分请求方式。若参数data为None,则代表请求方式为GET;反之请求方式为POST,发送POST请求。参数data以字典形式存储数据,并将参数data由字典类型转换成字节类型才能完成POST请求 |
| headers | 设置request请求头信息 |
| origin_req_host | 指定请求方的host名称或者ip地址 |
| unverifiable | 设置网页是否需要验证,默认是False,这个参数一般也不用设置。 |
| method | 设定请求方式,主要是POST和GET方式 |
2. urllib.request.urlopen
语法如下:
urllib.request.urlopen(url, data=None, [timeout,]*, cafile=None, capath=None, cadefault=False,context=None
| 参数 | 说明 |
|---|---|
| url | 需要访问的网站的URL地址。url格式必须完整 |
| data | 默认值为None, Urllib判断参数data是否为None从而区分请求方式。若参数data为None,则代表请求方式为GET;反之请求方式为POST,发送POST请求。参数data以字典形式存储数据,并将参数data由字典类型转换成字节类型才能完成POST请求 |
| timeout | 超时设置,指定阻塞操作(请求时间)的超时(如果未指定,就使用全局默认超时设置) |
| cafile、capath和cadefault | 使用参数指定一组HTTPS请求的可信CA证书。cafile应指向包含一组CA证书的单个文件;capath应指向证书文件的目录;cadefault通常使用默认值即可。 |
| context | 描述各种SSL选项的实例 |
在实际使用中,常用的参数有url、data和timeout。
发送请求后,网站会返回相应的响应内容。urlopen对象提供获取网站响应内容的方法函数:
| 参数 | 说明 |
|---|---|
| read() | 读取整个文件 |
| readline() | 一次读取一行 |
| readlines() | 读取整个文件到一个list中 |
| fileno() | 返回一个整型的文件描述符(file descriptor FD 整型),可用于底层操作系统的 I/O 操作。 |
| close() | 关闭一个已打开的文件 |
| info() | 返回HTTPMessage对象,表示远程服务器返回的头信息。 |
| getcode() | 返回HTTP状态码。 |
| geturl() | 返回请求的URL。 |
3. urllib.request.urlopen和urllib.request.Request实例演示
# 请求的url
url = "https://movie.douban.com/"
# 添加请求头字典
headers = {
'User-Agent': "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.132 Safari/537.36",
'Referer': " https://movie.douban.com/",
'Connection': "keep-alive"}
# 设置request的请求头
req = urllib.request.Request(url, headers=headers)
# 使用urlopen打开req(url,请求头信息)
response = urllib.request.urlopen(req)
# 读取返回内容
html = response.read().decode('utf8')
# 写入文件txt
f = open('html.txt', 'w', encoding='utf8')
f.write(html)
执行结果:
执行后的多出一个文件:
里面内容,是请求返回的数据: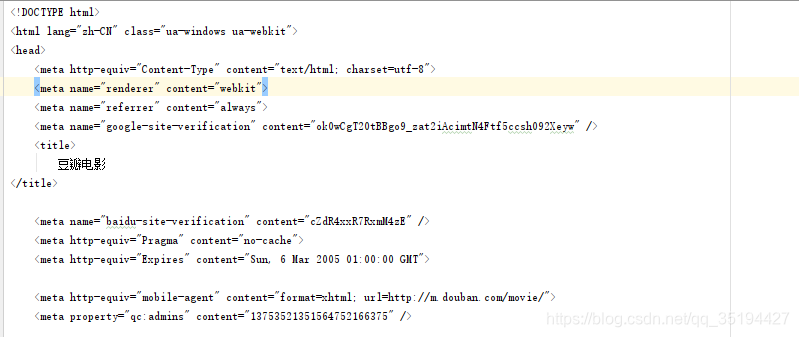

加入社区!打开量化的大门,首批课程上线啦!
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)