
基于Streamlit的BS直聘数据爬取可视化平台(爬虫)
本项目是一个基于Streamlit和Selenium的BOSS直聘职位数据爬虫系统,提供了友好的Web界面,支持自定义搜索条件、扫码登录、数据爬取和导出等功能。本项目通过Streamlit和Selenium技术栈,实现了一个功能完整的职位数据采集系统。友好的Web操作界面完善的反爬虫机制稳定的数据采集功能便捷的数据导出功能通过这个项目,我们不仅实现了数据采集的自动化,还提供了良好的用户体验,使得非
·
一、项目介绍
本项目是一个基于Streamlit和Selenium的BOSS直聘职位数据爬虫系统,提供了友好的Web界面,支持自定义搜索条件、扫码登录、数据爬取和导出等功能。
1.1 功能特点
- 支持多城市职位搜索
- 自定义工作经验和公司规模筛选
- 扫码登录认证
- 自动化数据采集
- 数据导出为CSV格式
- 实时数据预览
1.2 技术栈
- Python 3.x
- Streamlit:Web界面框架
- Selenium:自动化测试工具
- BeautifulSoup4:HTML解析
- Pandas:数据处理
- ChromeDriver:浏览器驱动
二、项目结构
boss_spyder_streamlit/
├── README.md # 项目说明文档
├── requirements.txt # 项目依赖
├── app.py # Streamlit应用主程序
├── spider.py # 爬虫核心实现
├── config.py # 配置文件(城市代码等)
├── data/ # 数据存储目录
└── chromedriver/ # ChromeDriver目录
└── chromedriver # 浏览器驱动
三、核心代码实现
3.1 爬虫实现 (spider.py)
- 浏览器初始化
def init_driver():
try:
service = Service('./chromedriver/chromedriver')
options = webdriver.ChromeOptions()
# 基本设置
options.add_argument('--start-maximized')
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_argument('--disable-dev-shm-usage')
options.add_argument('--no-sandbox')
# 反爬设置
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(service=service, options=options)
# 禁用webdriver标记
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument', {
'source': '''
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
'''
})
return driver
except Exception as e:
raise Exception(f"浏览器初始化失败: {str(e)}")
- 登录处理
def wait_for_login(driver, timeout=300):
try:
driver.get("https://www.zhipin.com/web/user/?ka=header-login")
WebDriverWait(driver, timeout).until(
EC.presence_of_element_located((By.CLASS_NAME, "user-nav"))
)
return True
except TimeoutException:
raise Exception("登录等待超时,请在5分钟内完成扫码登录")
- 数据采集
def get_jobs(driver, keyword, city_code, exp=None, scale=None, limit=10):
try:
base_url = f"https://www.zhipin.com/web/geek/job?city={city_code}&query={keyword}"
driver.get(base_url)
# 应用筛选条件
apply_filters(driver, exp, scale)
job_list = []
jobs_processed = 0
while jobs_processed < limit:
# 解析职位信息
soup = BeautifulSoup(driver.page_source, 'html.parser')
jobs_on_page = soup.select('.job-card-wrapper')
for job in jobs_on_page:
if jobs_processed >= limit:
break
# 提取职位信息
name = safe_get_element_text(job, '.job-name')
area = safe_get_element_text(job, '.job-area')
salary = safe_get_element_text(job, '.salary')
company = safe_get_element_text(job, '.company-name')
# 获取详细信息
url = "https://www.zhipin.com" + job.select_one('a')['href']
description = get_job_description(driver, url)
job_list.append([name, area, salary, company, ...])
jobs_processed += 1
# 翻页处理
if jobs_processed < limit:
next_button = driver.find_element(By.CLASS_NAME, 'next')
if 'disabled' not in next_button.get_attribute('class'):
next_button.click()
time.sleep(random.uniform(2, 3))
# 保存数据
filename = f'data/{keyword}_{city_code}_{datetime.now().strftime("%Y%m%d_%H%M%S")}.csv'
df = pd.DataFrame(job_list, columns=[...])
df.to_csv(filename, index=False, encoding='utf-8-sig')
return filename
3.2 Web界面实现 (app.py)
- 页面配置
st.set_page_config(
page_title="BOSS直聘爬虫",
page_icon="💼",
layout="wide",
initial_sidebar_state="expanded"
)
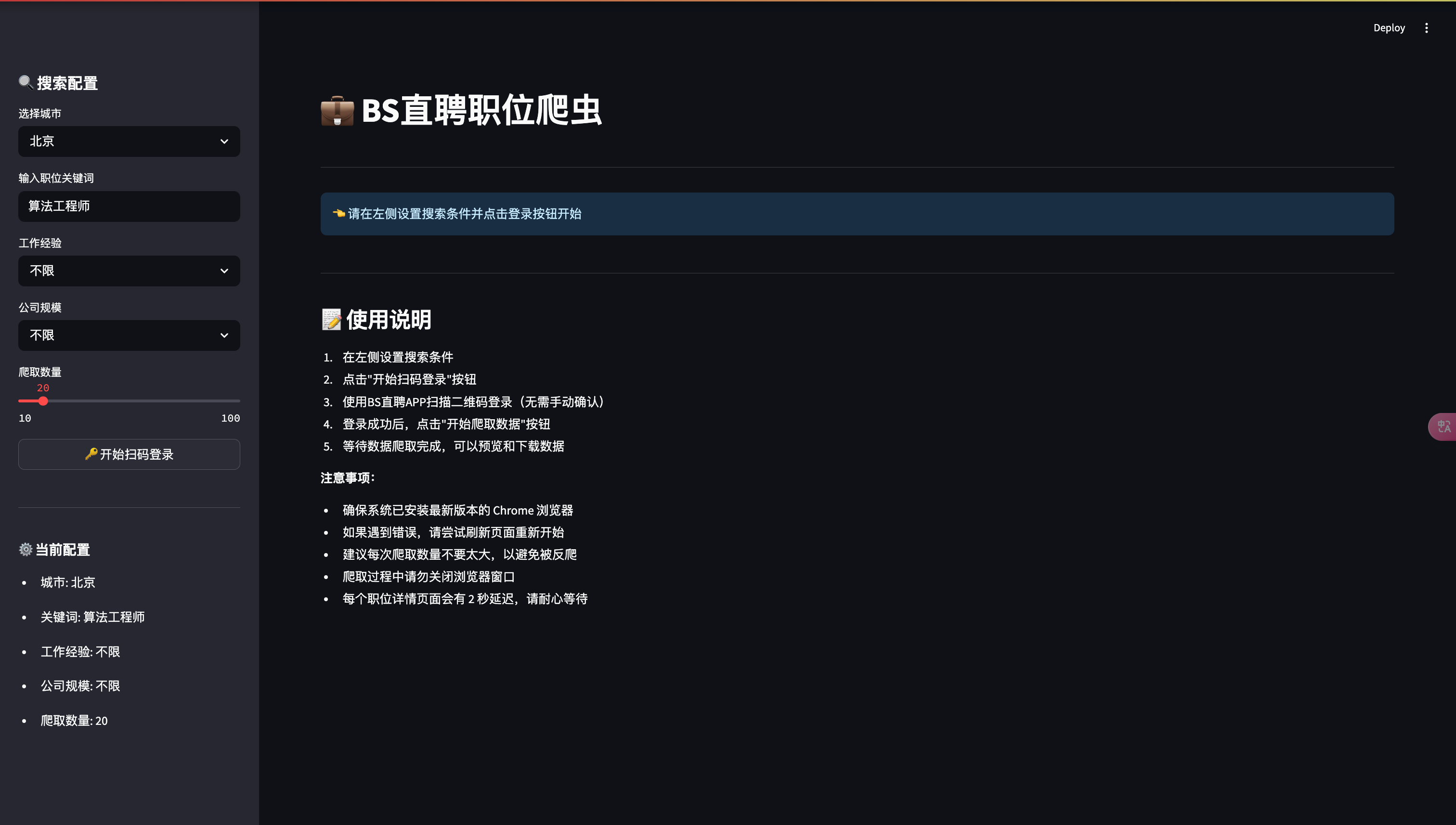
- 搜索配置界面
with st.sidebar:
st.header("🔍 搜索配置")
city = st.selectbox("选择城市", list(zone_dicts.keys()))
keyword = st.text_input("输入职位关键词", value="算法工程师")
exp = st.selectbox("工作经验", exp_list)
scale = st.selectbox("公司规模", scale_list)
limit = st.slider("爬取数量", min_value=10, max_value=100, value=20, step=10)
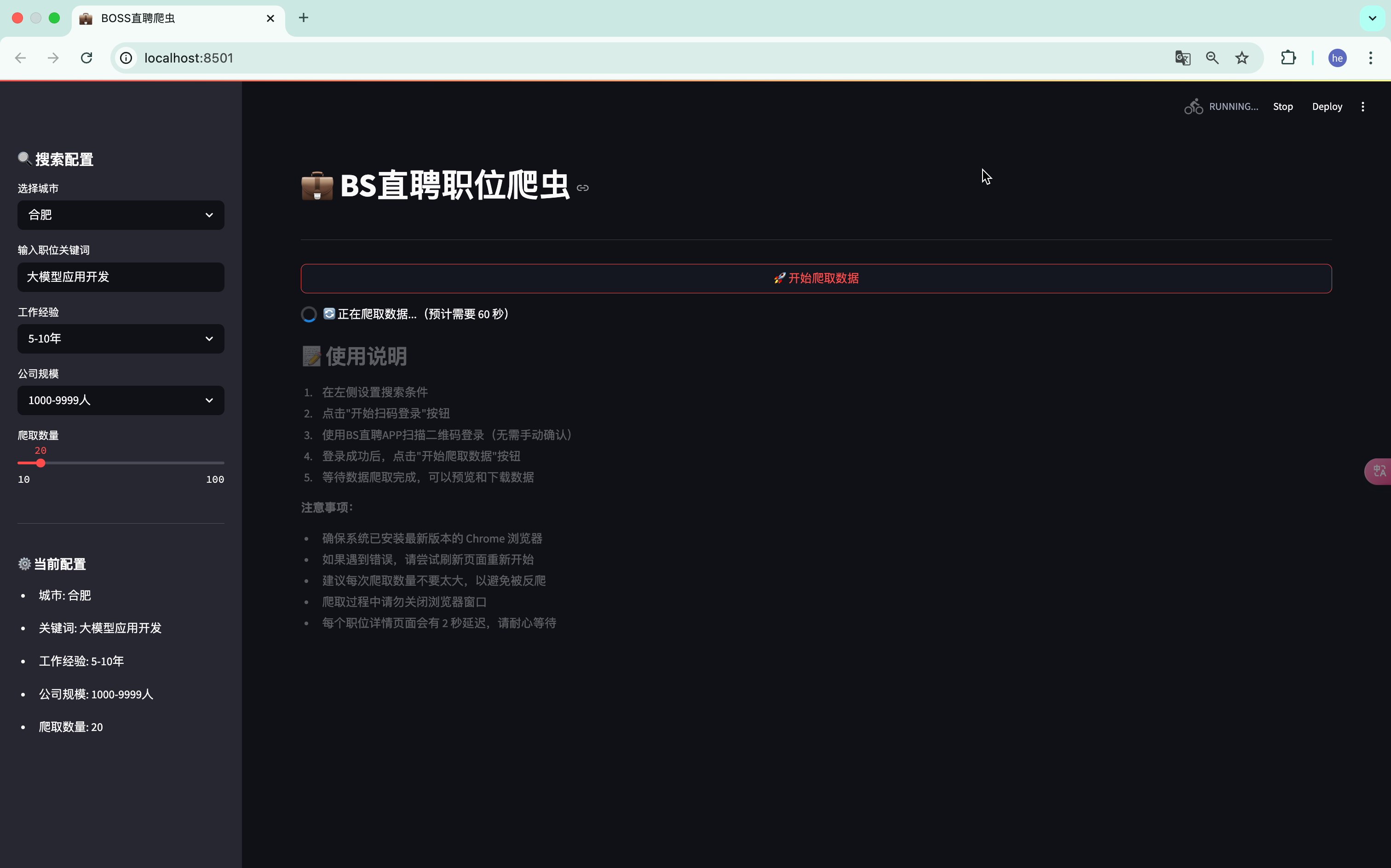
- 数据爬取与展示
if st.button("🚀 开始爬取数据", use_container_width=True):
try:
with st.spinner(f"🔄 正在爬取数据..."):
filename = get_jobs(
driver=st.session_state.driver,
keyword=keyword,
city_code=zone_dicts[city]['code'],
exp=exp,
scale=scale,
limit=limit
)
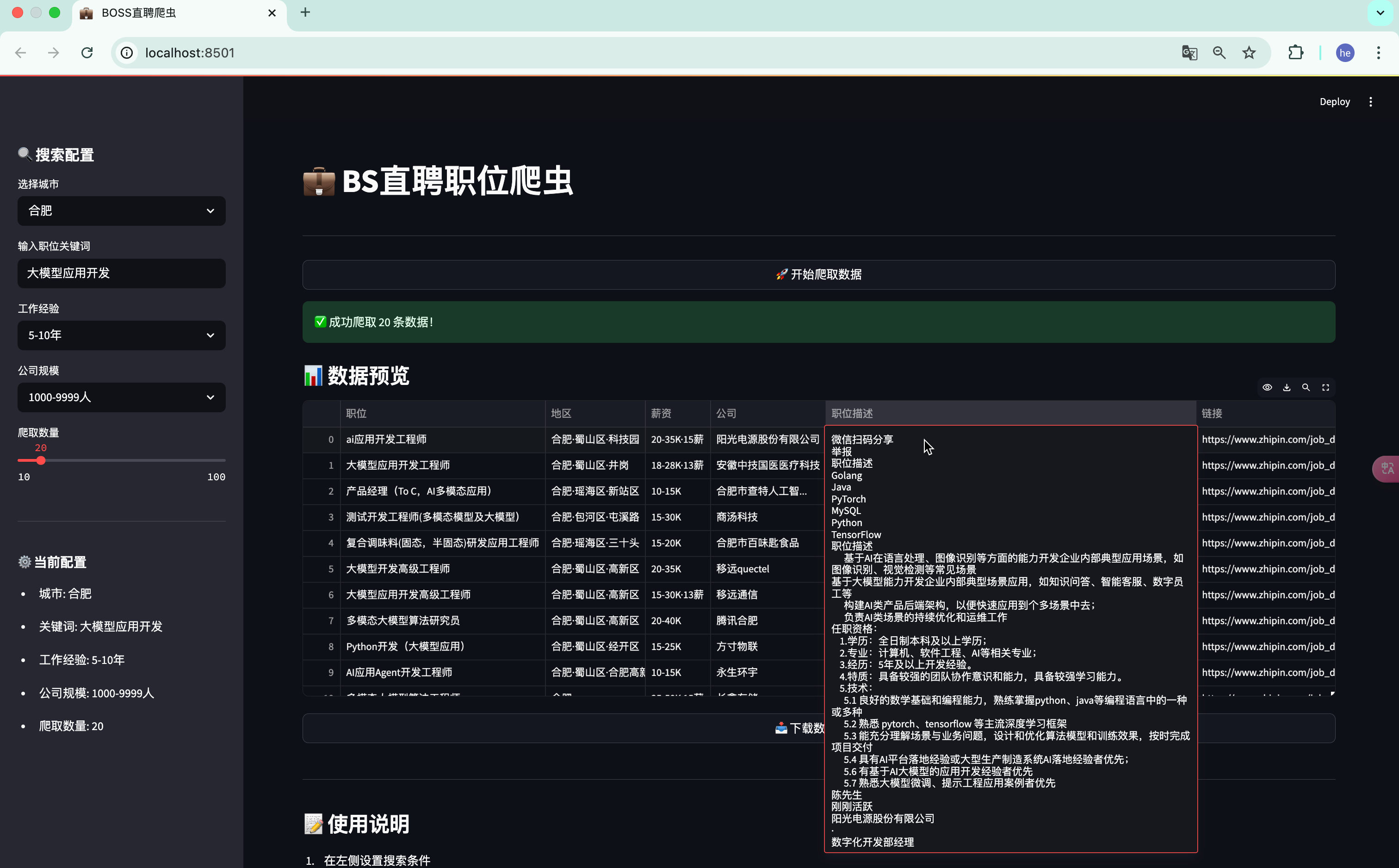
# 读取并显示数据
df = pd.read_csv(filename)
st.success(f"✅ 成功爬取 {len(df)} 条数据!")
# 数据预览
st.markdown("### 📊 数据预览")
st.dataframe(df, use_container_width=True)
# 下载按钮
with open(filename, "rb") as f:
st.download_button(
"📥 下载数据(CSV)",
f,
file_name=filename.split("/")[-1],
mime="text/csv",
use_container_width=True
)
except Exception as e:
st.error(f"❌ 发生错误: {str(e)}")
四、系统功能展示
4.1 搜索配置
- 支持选择全国主要城市
- 自定义职位关键词
- 筛选工作经验要求
- 筛选公司规模
- 设置爬取数据量
4.2 数据采集
- 自动化模拟浏览器操作
- 智能处理登录验证
- 自动翻页采集
- 详情页信息提取
- 数据自动保存
4.3 数据展示
- 实时数据预览
- 表格形式展示
- CSV格式导出
- 操作状态提示
五、项目优化
5.1 反爬虫策略
- 浏览器伪装
- 修改WebDriver特征
- 随机User-Agent
- 禁用自动化标记
- 请求控制
- 随机延时处理
- 分页采集
- 异常重试机制
5.2 性能优化
- 资源管理
- 及时关闭标签页
- 定期清理缓存
- 内存使用优化
- 异常处理
- 完整的异常捕获
- 优雅的错误提示
- 会话状态管理
六、部署说明
6.1 环境准备
- 安装依赖
pip install -r requirements.txt
- ChromeDriver配置
- 下载对应版本的ChromeDriver
- 放置在chromedriver目录下
- 确保执行权限
6.2 启动应用
streamlit run app.py
七、注意事项
- 使用限制
- 遵守网站robots协议
- 控制采集频率
- 合理使用数据
- 运行环境
- 确保Chrome浏览器安装
- 检查网络连接
- 适当的系统权限
八、总结
本项目通过Streamlit和Selenium技术栈,实现了一个功能完整的职位数据采集系统。主要特点包括:
- 友好的Web操作界面
- 完善的反爬虫机制
- 稳定的数据采集功能
- 便捷的数据导出功能
通过这个项目,我们不仅实现了数据采集的自动化,还提供了良好的用户体验,使得非技术用户也能方便地获取职位数据。
完整代码:
参考资料
运行效果
声明
本项目仅供学习交流使用,请勿用于商业用途。使用本项目时请遵守相关法律法规。

加入社区!打开量化的大门,首批课程上线啦!
更多推荐
 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)