
Python爬虫——爬取京东商品(价格,评论数)——2020-02-16
打开京东——》搜索ipad第一次打开只加载了30个商品,往下拉才会加载后30个商品,总共60个商品
一、打开京东——》搜索ipad
第一次打开只加载了30个商品,往下拉才会加载后30个商品,总共60个商品

我们f12打开Network检查

得到这样的url:
Request URL:
跟普通的url对比分析
对比参数:
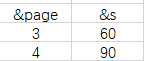
多了几个参数"&scrolling", "&log_id", "&show_items",我们一个一个尝试一遍
最终得到能够访问的url:
从而寻找规律得到:
"https://search.jd.com/Search?keyword=" + keyword + "&enc=utf-8&qrst=1&rt=1&stop=1&vt=1&stock=1&page=" + str(p) + "&s=" + str(1 + (p - 1) * 30) + "&click=0&scrolling=y"得到一整页的商品后,我们的目标是每一个商品的价格和其他,因此我们要得到每一个商品的链接
其中一个url:https://item.jd.com/57521237589.html,"57521237589"就是商品的编号
同样打开f12检查,并复制其XPath方便我们提取这样的链接
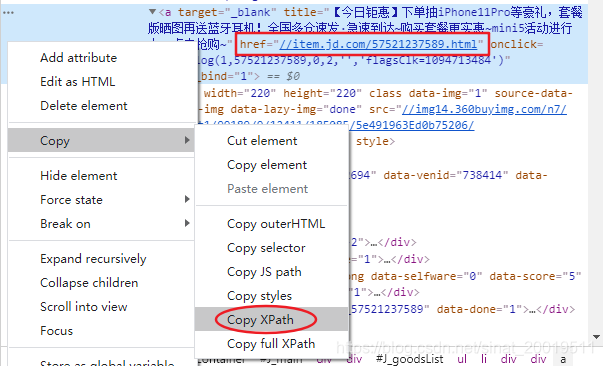
复制得到的XPath://*[@id="J_goodsList"]/ul/li[1]/div/div[1]/a 还需修改一下,把 "li[1]" 的 "[1]" 去掉,不然就只会得到一个商品的链接
html = etree.HTML(response.text)
html.xpath('//*[@id="J_goodsList"]/ul/li/div/div[1]/a/@href'):二、获取商品参数信息(价格,评论数......)
按f12检查, 京东的价格是通过js加载的,直接获取html的<span>是不能的
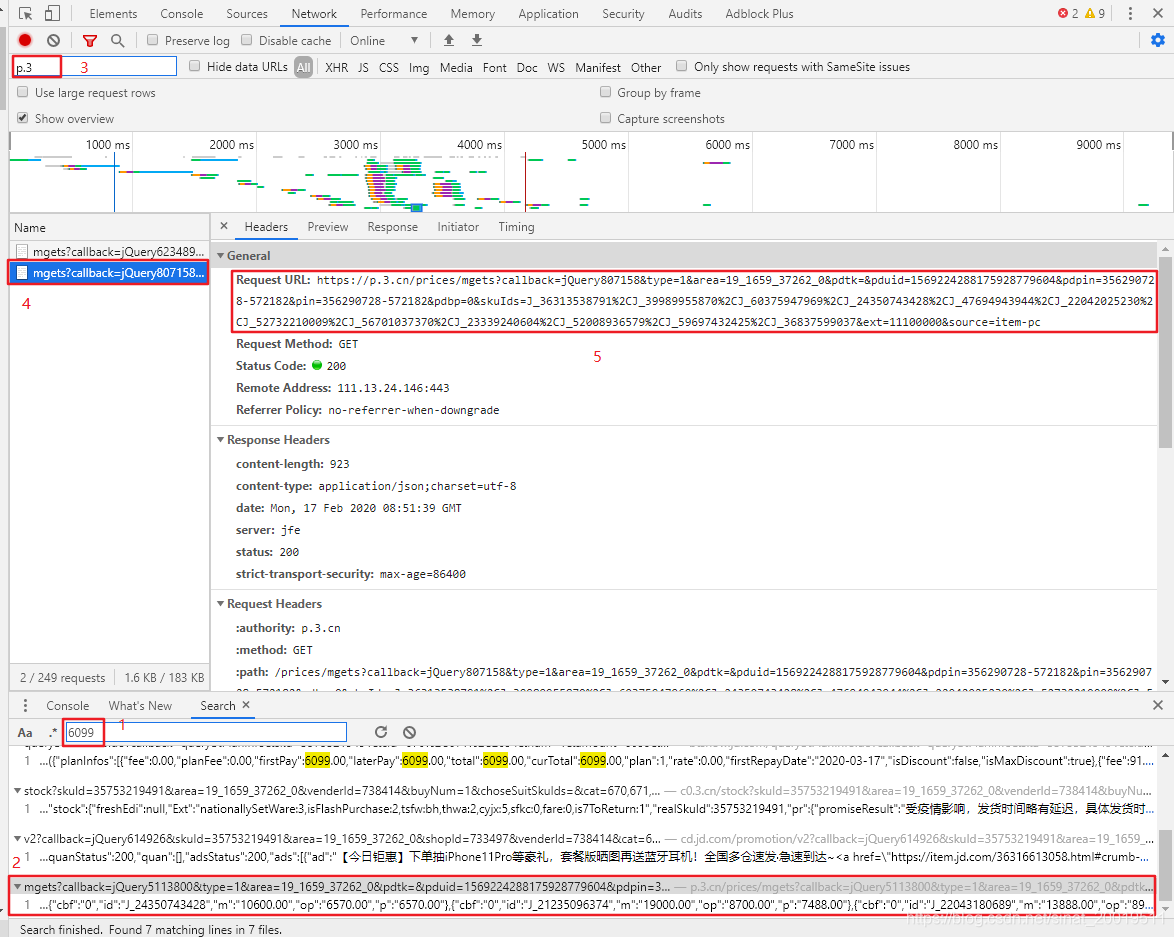
得到价格信息的url:https://p.3.cn/prices/mgets?skuIds=3575321949, "35753219491"是商品编号
返回是一个json文件,我们写出如下代码获取
jsons = json.loads(response.text[0:-1])
price = jsons[0]['p']三、获取商品其他信息并最后写入csv文件
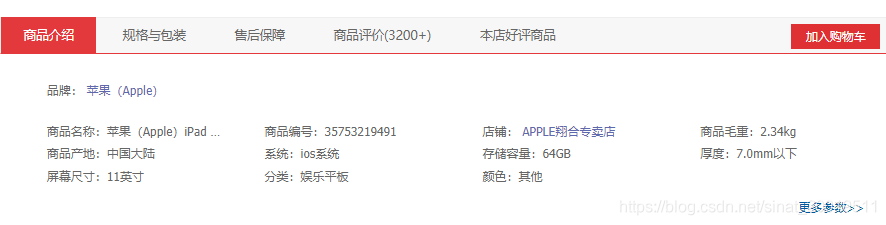
直接在网页源代码html提取就行
写入csv文件
with open("test.csv", "a", newline="") as csvfile:
rows = ("商品名称", "商品价格", "商品链接")
writer = csv.writer(csvfile)
writer.writerow(rows)完整代码参考:
GitHub: https://github.com/Tomy-Enrique/Spider/tree/master/JD_spider
Gitee(码云): https://gitee.com/TomyEnrique/Spider/tree/master/JD_spider

加入社区!打开量化的大门,首批课程上线啦!
更多推荐


 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)