
【Python爬虫】从天气后报网站上爬取近十年来各省会城市的空气质量数据
本文介绍了一个基于Python的空气质量数据爬虫程序,通过天气后报网站获取2015-2025年全国31个主要城市的空气质量数据。程序使用requests和BeautifulSoup库实现网页请求与解析,爬取内容包括AQI指数、空气质量等级、PM2.5、PM10等多项指标,并将数据存储为CSV文件。该爬虫具有自动跳过未来月份、设置随机延迟防封禁等特性,可扩展用于环境监测、城市空气质量分析等场景。代码
·
数据来源网站
天气后报:历史天气查询|天气记录|天气预报|气温查询|过去天气_天气后报
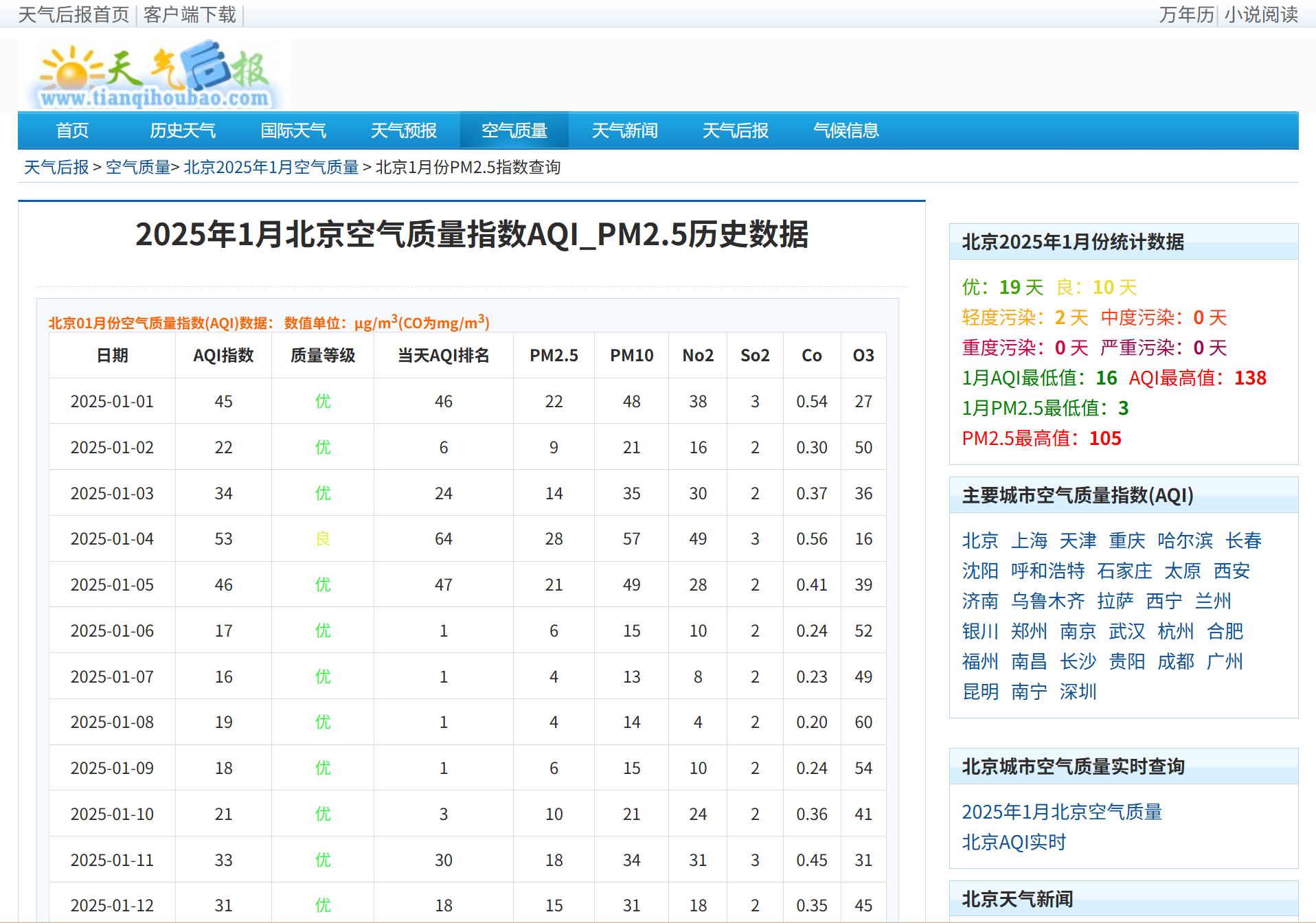
完整代码
import csv
import random
import time
from datetime import datetime
import requests
from bs4 import BeautifulSoup
class AqiSpider:
def __init__(self, cityname, realname):
self.cityname = cityname
self.realname = realname
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
self.f = open(f'air_quality.csv', 'a', encoding='utf-8', newline='')
self.writer = csv.DictWriter(self.f,
fieldnames=['city', 'date', 'AQI', 'quality_level', 'AQI_rank', 'PM2.5', 'PM10',
'NO2', 'S02', 'CO', 'O3'])
# self.writer.writeheader()
def send_request(self, year, month):
"""
发送请求
"""
print(self.realname)
url = f"https://www.tianqihoubao.com/aqi/{self.cityname}-"+str(year)+str("%02d"%month)+".html"
response = requests.get(url, headers=self.headers, timeout=60)
time.sleep(random.uniform(1, 3)) # 休眠一段时间,防止频繁请求
# print(response.text)
# print(f"响应状态码:{response.status_code}")
self.parse_response(response.text) # 解析网页
def parse_response(self, response):
"""
解析网页
"""
soup = BeautifulSoup(response, 'lxml')
tr = soup.find_all('tr')
for j in tr[1:]:
td = j.find_all('td')
city = self.realname # 城市
Date = td[0].get_text().strip() # 日期
AQI = td[1].get_text().strip() # AQI
Quality_Level = td[2].get_text().strip() # 空气质量等级
AQI_rank = td[3].get_text().strip() # AQI排名
PM25 = td[4].get_text().strip()
PM10 = td[5].get_text().strip()
NO2 = td[6].get_text().strip()
S02 = td[7].get_text().strip()
CO = td[8].get_text().strip()
O3 = td[9].get_text().strip()
print(city, Date, AQI, Quality_Level, AQI_rank, PM25, PM10, NO2, S02, CO, O3)
data_dict = {
'city': self.realname,
'date' :Date,
'AQI': AQI,
'quality_level': Quality_Level,
'AQI_rank': AQI_rank,
'PM2.5': PM25,
'PM10': PM10,
'NO2': NO2,
'S02': S02,
'CO': CO,
'O3': O3
}
# print(Date)
# print(data_dict)
self.save_data(data_dict)
def save_data(self, data_dict):
"""
保存数据
"""
self.writer.writerow(data_dict)
def run(self):
current_year = datetime.now().year
for year in range(2015, 2026):
for month in range(1, 13):
if year == current_year and month > datetime.now().month:
continue # 跳过未来的月份
print(f"正在爬取{year}年{month}月的数据")
self.send_request(year, month)
if __name__ == '__main__':
city_dict = {
'beijing': '北京',
'shanghai': '上海',
'tianjin': '天津',
'chongqing': '重庆',
'shijiazhuang': '石家庄',
'taiyuan': '太原',
'shenyang': '沈阳',
'changchun': '长春',
'haerbin': '哈尔滨',
'nanjing': '南京',
'hangzhou': '杭州',
'hefei': '合肥',
'fuzhou': '福州',
'nanchang': '南昌',
'jinan': '济南',
'zhengzhou': '郑州',
'wuhan': '武汉',
'changsha': '长沙',
'guangzhou': '广州',
'haikou': '海口',
'chengdu': '成都',
'guiyang': '贵阳',
'kunming': '昆明',
'xian': '西安',
'lanzhou': '兰州',
'xining': '西宁',
'huhehaote': '呼和浩特',
'nanning': '南宁',
'lasa': '拉萨',
'yinchuan': '银川',
'wulumuqi': '乌鲁木齐'
}
for k, v in city_dict.items():
AS = AqiSpider(k, v)
AS.run()
参考
1. 代码主要参考B站up主奥特曼计算机毕业设计
视频地址:
2.爬虫思路主要参考下面的文章,讲的很清楚:

加入社区!打开量化的大门,首批课程上线啦!
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)