
Python网络爬虫实战:高效爬取网页图片技巧
网络爬虫(Web Crawler)是指按照一定规则,自动抓取互联网数据的程序。其发展历程从早期的简单信息采集,逐步演进为如今支持大数据分析、搜索引擎、舆情监控等复杂任务的核心技术之一。Python凭借其语法简洁、生态丰富等优势,成为爬虫开发的主流语言,广泛应用于数据挖掘、人工智能、金融分析等多个领域。同时,理解网页结构(如HTML、DOM树)是进行爬虫开发的前提,这为后续的数据提取与处理打下基础。

简介:Python网络爬虫广泛应用于数据采集与信息提取,本文重点讲解如何使用Python爬取网页中的图片资源。通过requests发起请求,BeautifulSoup解析HTML,结合正则表达式提取图片链接,并利用urllib和os模块实现图片下载与本地存储。教程包含完整代码示例与实战流程,适合初学者掌握图片爬虫核心技术,同时提醒开发者遵守Robots协议,合理合法进行数据抓取。 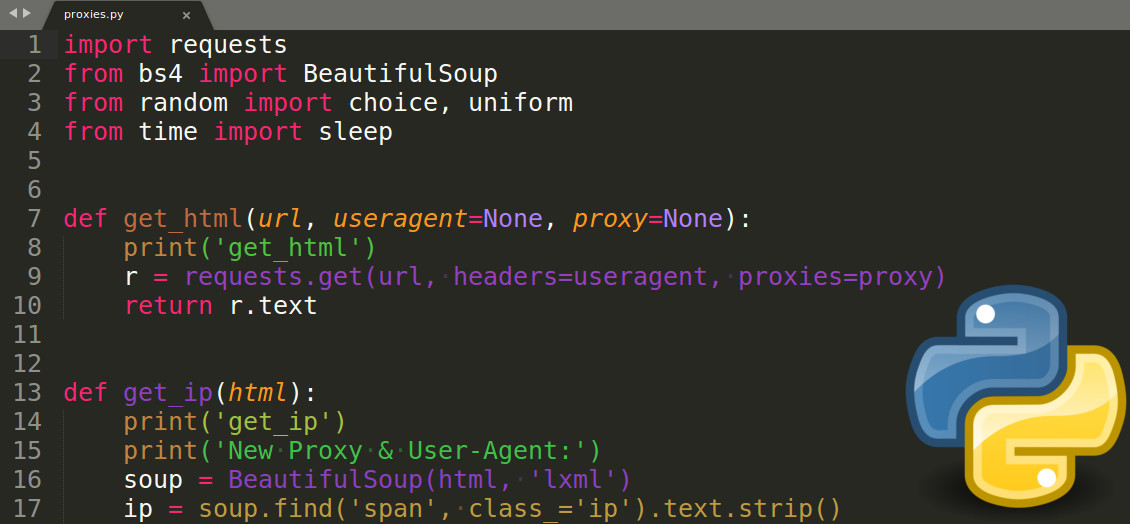
1. Python网络爬虫概述与基础认知
网络爬虫(Web Crawler)是指按照一定规则,自动抓取互联网数据的程序。其发展历程从早期的简单信息采集,逐步演进为如今支持大数据分析、搜索引擎、舆情监控等复杂任务的核心技术之一。Python凭借其语法简洁、生态丰富等优势,成为爬虫开发的主流语言,广泛应用于数据挖掘、人工智能、金融分析等多个领域。同时,理解网页结构(如HTML、DOM树)是进行爬虫开发的前提,这为后续的数据提取与处理打下基础。本章将引导读者由浅入深地掌握爬虫的基本原理与实践准备。
2. HTTP请求与响应基础
在现代网络爬虫开发中,HTTP协议作为客户端与服务器之间通信的核心机制,扮演着至关重要的角色。理解HTTP请求与响应的基本原理,不仅有助于构建稳定、高效的爬虫程序,还能帮助开发者更好地应对网络通信中可能出现的各种问题。本章将深入探讨HTTP协议的核心机制,介绍如何使用Python的 requests 库发起网络请求,并处理响应内容与异常情况。
2.1 网络通信的基本流程
网络通信的本质是客户端与服务器之间的数据交换。在爬虫系统中,客户端通常是我们的程序,而服务器则负责响应请求并返回网页内容。为了理解这一过程,我们需要从HTTP协议的基础概念入手。
2.1.1 HTTP协议的核心概念
HTTP(HyperText Transfer Protocol)是一种应用层协议,用于从Web服务器传输超文本到本地浏览器。它基于请求-响应模型,具有以下核心特点:
- 无状态性(Stateless) :每次请求之间互不关联。
- 明文传输 :默认不加密,易受监听。
- 客户端-服务器模型 :客户端发送请求,服务器响应请求。
- 支持多种请求方法 :如GET、POST、PUT、DELETE等。
HTTP请求的基本结构包括:
请求行(Method, URL, HTTP版本)
请求头(Headers)
空行(分隔头和体)
请求体(Body,可选)
HTTP响应结构包括:
状态行(HTTP版本,状态码,状态描述)
响应头(Headers)
空行
响应体(Body)
例如,一个典型的HTTP响应可能如下:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
<!DOCTYPE html>
<html>
<head><title>示例页面</title></head>
<body><h1>Hello World!</h1></body>
</html>
HTTP状态码分类
| 类别 | 状态码范围 | 描述 |
|---|---|---|
| 1xx | 100-199 | 信息响应,表示接收请求正在处理 |
| 2xx | 200-299 | 成功响应 |
| 3xx | 300-399 | 重定向 |
| 4xx | 400-499 | 客户端错误 |
| 5xx | 500-599 | 服务器错误 |
示例:GET请求的交互流程图(Mermaid)
sequenceDiagram
participant Client
participant Server
Client->>Server: 发起GET请求
Server-->>Client: 返回HTTP响应
Client->>Client: 解析响应内容
2.1.2 请求与响应的工作机制
HTTP通信的基本流程如下:
- 建立连接 :客户端通过TCP/IP协议与服务器建立连接。
- 发送请求 :客户端发送包含方法、路径、协议版本等信息的HTTP请求。
- 处理请求 :服务器解析请求并执行相应的操作(如查询数据库、返回静态文件等)。
- 返回响应 :服务器将结果封装成HTTP响应返回给客户端。
- 断开连接 :根据请求头中的
Connection字段决定是否保持连接。
以一个GET请求为例,客户端向服务器请求某个网页资源,服务器将该资源封装在响应体中返回。而POST请求则通常用于提交表单数据,请求体中携带了客户端发送的数据。
2.2 requests库的安装与使用
Python中用于发送HTTP请求的常用库之一是 requests 。它封装了底层的socket通信,提供了简洁易用的API接口,极大地简化了HTTP请求的编写过程。
2.2.1 发起GET与POST请求
安装 requests 库
在命令行中运行以下命令安装:
pip install requests
发起GET请求
GET请求通常用于获取数据,请求参数会附加在URL之后:
import requests
response = requests.get('https://example.com')
print(response.text)
逐行解读:
import requests:导入requests库。requests.get('https://example.com'):向指定URL发起GET请求。response.text:获取响应内容为字符串。
发起POST请求
POST请求用于向服务器提交数据,通常会携带请求体:
import requests
data = {'username': 'test', 'password': '123456'}
response = requests.post('https://example.com/login', data=data)
print(response.status_code)
逐行解读:
data = {...}:定义POST请求的数据。requests.post(url, data=data):发送POST请求并携带表单数据。response.status_code:获取响应状态码。
代码逻辑分析
- GET请求适用于获取资源,参数以查询字符串形式附加在URL中。
- POST请求用于提交数据,数据通常放在请求体中。
response对象包含了状态码、响应头、响应体等信息,便于后续处理。
2.2.2 设置请求头与参数传递
在实际爬虫开发中,许多网站会检查请求头来判断是否为真实浏览器访问。为了模拟浏览器行为,我们可以通过设置 headers 来伪装User-Agent。
设置请求头示例
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0 Safari/537.36',
'Accept-Language': 'en-US,en;q=0.9',
}
response = requests.get('https://example.com', headers=headers)
print(response.request.headers)
逐行解读:
headers:定义请求头,模拟浏览器访问。requests.get(url, headers=headers):发送请求并携带自定义请求头。response.request.headers:查看实际发送的请求头。
参数传递方式
GET请求的参数可以通过 params 参数传递:
params = {'q': 'python', 'page': 1}
response = requests.get('https://example.com/search', params=params)
print(response.url)
输出示例:
https://example.com/search?q=python&page=1
POST请求则使用 data 或 json 参数传递数据:
json_data = {'key': 'value'}
response = requests.post('https://example.com/api', json=json_data)
2.3 响应内容的处理与异常捕获
在爬虫开发过程中,网络请求可能会因为各种原因失败,如服务器无响应、超时、权限问题等。因此,合理地处理响应内容与捕获异常是非常关键的。
2.3.1 判断请求状态码与响应内容
HTTP响应状态码可以反映请求是否成功。我们可以使用 response.status_code 来判断:
import requests
response = requests.get('https://example.com')
if response.status_code == 200:
print("请求成功")
print(response.text)
else:
print(f"请求失败,状态码:{response.status_code}")
响应内容类型处理
response.text:获取文本格式内容(如HTML)。response.content:获取二进制格式内容(如图片)。response.json():解析JSON响应。
示例:获取并解析JSON数据
response = requests.get('https://api.example.com/data')
data = response.json()
print(data['key'])
2.3.2 超时设置与异常处理机制
在网络通信中,长时间等待响应可能会导致程序阻塞。为了避免这种情况,我们可以设置超时时间,并使用 try-except 结构捕获常见异常。
设置超时时间
try:
response = requests.get('https://example.com', timeout=5) # 最多等待5秒
response.raise_for_status() # 如果状态码不是2xx,抛出异常
except requests.exceptions.Timeout:
print("请求超时,请重试")
except requests.exceptions.HTTPError as err:
print(f"HTTP错误:{err}")
except requests.exceptions.RequestException as e:
print(f"请求发生异常:{e}")
异常类型说明:
| 异常类型 | 说明 |
|---|---|
| Timeout | 请求超时 |
| ConnectionError | 网络连接错误 |
| HTTPError | HTTP响应状态码非2xx |
| RequestException | 所有请求异常的基类 |
表格:常见异常与处理建议
| 异常类型 | 原因 | 处理建议 |
|---|---|---|
| Timeout | 网络延迟或服务器响应慢 | 设置合理超时时间,重试机制 |
| ConnectionError | 网络不通或服务器宕机 | 检查网络连接,重连机制 |
| HTTPError | 返回非2xx状态码 | 检查URL、参数或权限 |
| JSONDecodeError | 响应内容不是合法JSON | 检查响应格式,增加日志输出 |
本章从HTTP协议的基本原理出发,逐步讲解了请求与响应的通信机制,并通过 requests 库的实际代码示例,展示了如何发起GET与POST请求、设置请求头、处理响应内容以及捕获网络异常。下一章我们将进入HTML解析阶段,探讨如何从网页中提取所需数据。
3. HTML解析与数据提取
3.1 HTML文档结构与标签基础
3.1.1 HTML标签的组成与嵌套结构
HTML(HyperText Markup Language)是一种用于创建网页的标准标记语言。HTML文档由一系列标签(tag)组成,这些标签构成了文档的结构和内容。每个标签通常由一对尖括号包围的标识符构成,如 <p> 、 <div> 、 <a> 等。标签可以分为 开始标签 、 结束标签 和 自闭合标签 三种形式。
HTML标签的嵌套结构决定了网页的层级关系。例如:
<div class="container">
<h1>标题</h1>
<p>这是一个段落。</p>
</div>
在这个例子中, <div> 是一个容器标签,它包含了 <h1> 和 <p> 两个子标签。这种嵌套结构形成了一个树状结构,称为 DOM(Document Object Model)树 。理解HTML标签的组成和嵌套方式,是进行网页数据提取的基础。
HTML文档的基本结构通常包括以下几个核心标签:
<html>:根标签,所有内容都包含在其中。<head>:包含元数据,如页面标题、字符集、样式表链接等。<title>:定义网页的标题,显示在浏览器标签页上。<body>:包含网页的可见内容,如文本、图片、链接等。
以下是一个完整的HTML文档示例:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>示例页面</title>
</head>
<body>
<h1>欢迎来到我的网页</h1>
<p>这是一个示例段落。</p>
</body>
</html>
HTML标签还支持属性(attributes),用于提供额外的信息。例如:
<a href="https://example.com">点击这里</a>
<img src="image.jpg" alt="图片描述">
在上述代码中, href 和 src 是属性,分别表示链接地址和图片路径, alt 则提供了图片的替代文本。
3.1.2 常见网页结构与DOM树解析
网页的结构通常由多个HTML标签嵌套组成,形成了一个树状结构——即DOM树(Document Object Model Tree)。DOM是浏览器将HTML文档解析为对象模型的过程,它允许程序(如JavaScript或爬虫)动态访问和修改网页内容。
常见的网页结构包括:
| 结构名称 | 常用标签 | 用途说明 |
|---|---|---|
| 页面容器 | <div> 、 <section> 、 <article> |
构建页面布局和内容区块 |
| 导航栏 | <nav> 、 <ul> 、 <li> |
页面导航链接的组织与展示 |
| 主体内容区域 | <main> 、 <section> 、 <div> |
网站的核心内容展示区域 |
| 侧边栏 | <aside> 、 <div> |
提供辅助信息或广告等 |
| 页脚 | <footer> 、 <div> |
页面底部信息,如版权、联系方式 |
以下是一个典型的网页结构示例:
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>网页结构示例</title>
</head>
<body>
<header>
<h1>网站标题</h1>
<nav>
<ul>
<li><a href="/">首页</a></li>
<li><a href="/about">关于我们</a></li>
</ul>
</nav>
</header>
<main>
<section>
<h2>最新资讯</h2>
<p>这里是新闻内容。</p>
</section>
</main>
<aside>
<h3>热门文章</h3>
<ul>
<li><a href="/post1">文章1</a></li>
<li><a href="/post2">文章2</a></li>
</ul>
</aside>
<footer>
<p>© 2025 我的网站. 版权所有.</p>
</footer>
</body>
</html>
该HTML文档的DOM树结构如下图所示:
graph TD
A[html] --> B[head]
A --> C[body]
B --> B1[meta]
B --> B2[title]
C --> C1[header]
C --> C2[main]
C --> C3[aside]
C --> C4[footer]
C1 --> C11[h1]
C1 --> C12[nav]
C12 --> C121[ul]
C121 --> C1211[li]
C1211 --> C12111[a]
C2 --> C21[section]
C21 --> C211[h2]
C21 --> C212[p]
C3 --> C31[h3]
C3 --> C32[ul]
C4 --> C41[p]
DOM树的结构清晰地展示了HTML文档的层级关系,这对爬虫提取数据至关重要。爬虫程序通过解析DOM树,能够定位到特定的节点(如 <h1> 、 <p> 、 <img> 等),从而提取其中的内容。
在Python中,常用的HTML解析库有 BeautifulSoup 和 lxml ,它们可以将HTML文档解析为可操作的对象树,便于提取数据。
3.2 BeautifulSoup解析HTML内容
3.2.1 安装与初始化BeautifulSoup对象
BeautifulSoup 是 Python 中一个非常流行的 HTML 和 XML 解析库,它能够将复杂的 HTML 文档转换为一个树形结构,并提供简单的方法来搜索和提取数据。它非常适合用于网络爬虫的数据解析阶段。
安装 BeautifulSoup
可以通过 pip 安装 BeautifulSoup:
pip install beautifulsoup4
此外,BeautifulSoup 依赖解析器,常用的解析器包括:
html.parser:Python 标准库中的 HTML 解析器。lxml:功能强大且速度快的解析器,需要额外安装:
pip install lxml
html5lib:更宽容的解析器,适合解析不规范的 HTML。
初始化 BeautifulSoup 对象
使用 BeautifulSoup 解析 HTML 的基本步骤如下:
- 获取 HTML 文档内容(例如通过 requests 库获取响应内容)。
- 将 HTML 内容传入 BeautifulSoup 构造函数,并指定解析器。
以下是一个示例:
from bs4 import BeautifulSoup
html_content = '''
<!DOCTYPE html>
<html>
<head><title>测试页面</title></head>
<body>
<h1>欢迎</h1>
<p class="content">这是第一个段落。</p>
<p class="content">这是第二个段落。</p>
</body>
</html>
# 使用 html.parser 解析器
soup = BeautifulSoup(html_content, 'html.parser')
# 输出格式化的HTML
print(soup.prettify())
代码逻辑分析 :
html_content是一个字符串,模拟从网络获取的 HTML 数据。BeautifulSoup(...)接收 HTML 内容和解析器名称,构建解析后的文档对象。prettify()方法用于将 HTML 结构格式化输出,便于阅读。
执行结果:
<!DOCTYPE html>
<html>
<head>
<title>
测试页面
</title>
</head>
<body>
<h1>
欢迎
</h1>
<p class="content">
这是第一个段落。
</p>
<p class="content">
这是第二个段落。
</p>
</body>
</html>
3.2.2 标签查找与内容提取方法
BeautifulSoup 提供了多种方法用于查找和提取 HTML 文档中的标签和内容,最常用的方法包括:
1. 查找单个标签: find()
title_tag = soup.find('title')
print(title_tag.string) # 输出:测试页面
find() 方法返回第一个匹配的标签对象。 .string 属性用于获取标签内的文本内容。
2. 查找多个标签: find_all()
paragraphs = soup.find_all('p')
for p in paragraphs:
print(p.text)
执行结果:
这是第一个段落。
这是第二个段落。
find_all() 返回所有匹配的标签组成的列表,遍历该列表即可提取每个段落的文本内容。
3. 通过标签属性查找
可以通过标签的属性(如 class、id、name 等)进行查找:
content_paragraphs = soup.find_all('p', class_='content')
for p in content_paragraphs:
print(p['class']) # 输出:['content']
print(p.get_text()) # 输出段落文本
class_参数用于匹配 class 属性,因为class是 Python 的关键字。get_text()方法与.text类似,但更安全,避免空值问题。
4. 使用 CSS 选择器查找: select()
CSS 选择器是一种强大的定位方式,支持层级、属性、伪类等复杂选择。
# 选择所有具有 class="content" 的 <p> 标签
selected_p = soup.select('p.content')
for p in selected_p:
print(p.text)
CSS 选择器语法示例:
| 选择器写法 | 含义说明 |
|---|---|
tag |
所有指定标签(如 div ) |
.class |
所有具有指定 class 的标签 |
#id |
具有指定 id 的标签 |
tag.class |
指定标签且具有指定 class |
tag1 tag2 |
tag1 下的所有 tag2 子元素 |
tag1>tag2 |
tag1 下的直接子元素 tag2 |
示例:提取网页中的所有链接
links = soup.select('a')
for link in links:
print(link.get('href')) # 获取 href 属性
print(link.text) # 获取链接文本
BeautifulSoup 的灵活性和易用性使其成为 Python 网络爬虫中不可或缺的工具。在实际开发中,常常结合 requests 库获取 HTML,再使用 BeautifulSoup 解析并提取所需数据。
3.3 图片URL的提取实践
3.3.1 查找img标签与src属性提取
在爬虫开发中,图片URL的提取是一个常见需求。通常,图片是通过 <img> 标签嵌入到HTML文档中的,其 src 属性指向图片的实际地址。
示例HTML片段:
<div class="gallery">
<img src="https://example.com/image1.jpg" alt="图片1">
<img src="/static/image2.png" alt="图片2">
<img src="image3.gif" alt="图片3">
</div>
我们的目标是提取所有 <img> 标签的 src 属性值。
使用 BeautifulSoup 提取 src 属性:
from bs4 import BeautifulSoup
html_content = '''
<div class="gallery">
<img src="https://example.com/image1.jpg" alt="图片1">
<img src="/static/image2.png" alt="图片2">
<img src="image3.gif" alt="图片3">
</div>
soup = BeautifulSoup(html_content, 'html.parser')
# 查找所有 img 标签
img_tags = soup.find_all('img')
# 提取 src 属性
for img in img_tags:
src = img.get('src') # 使用 get() 避免 KeyError
print(src)
执行结果 :
https://example.com/image1.jpg
/static/image2.png
image3.gif
代码逻辑分析 :
find_all('img'):查找所有<img>标签。img.get('src'):获取每个<img>标签的src属性值。使用.get()方法可以避免当属性不存在时抛出异常。- 输出的URL包括 绝对路径 、 相对路径 和 本地路径 三种形式,后续可能需要进行统一处理(如补全域名)。
表格:图片URL的常见类型与处理建议
| URL类型 | 示例 | 特点说明 | 建议处理方式 |
|---|---|---|---|
| 绝对路径 | https://example.com/image.jpg |
完整的网络地址,可直接下载 | 直接使用 |
| 相对路径 | /static/image.jpg |
基于当前域名的相对路径 | 补全为完整URL |
| 本地路径 | images/image.jpg |
相对于网页当前路径的本地文件 | 拼接基础URL |
3.3.2 结合CSS选择器进行高效筛选
CSS选择器是 BeautifulSoup 中非常强大的工具,它允许我们根据HTML标签的属性、类名、层级关系等进行精确筛选。
示例:提取特定类名下的所有图片
# 使用 CSS 选择器筛选具有 class="gallery" 的 div 下的所有 img
img_tags = soup.select('div.gallery img')
for img in img_tags:
src = img.get('src')
print(src)
执行结果 :
https://example.com/image1.jpg
/static/image2.png
image3.gif
代码逻辑分析 :
soup.select('div.gallery img'):CSS选择器语法,表示选择所有类名为gallery的<div>标签下的<img>标签。- 这种方式比多次调用
find()或find_all()更加简洁高效。
示例:筛选具有特定 alt 属性的图片
# 选择所有 alt 属性包含 "图片2" 的 img 标签
img_tags = soup.select('img[alt="图片2"]')
for img in img_tags:
print(img.get('src'))
执行结果 :
/static/image2.png
CSS选择器语法说明 :
| 选择器写法 | 含义说明 |
|---|---|
img[alt] |
所有具有 alt 属性的 img 标签 |
img[alt="图片2"] |
alt 属性等于 “图片2” 的 img 标签 |
img[alt^="图片"] |
alt 属性以 “图片” 开头的 img 标签 |
img[alt*="内容"] |
alt 属性包含 “内容” 的 img 标签 |
CSS选择器的灵活性使其在爬虫开发中非常实用,特别是在面对复杂页面结构时,能够精准定位目标元素。
在实际项目中,我们可以结合 CSS 选择器与 find() 、 find_all() 等方法,构建更强大的数据提取逻辑。例如:
# 查找所有具有 class="thumbnail" 的 img 标签
thumbnails = soup.select('img.thumbnail')
# 查找所有父级为 div 且 class 为 item 的 img 标签
items = soup.select('div.item > img')
这些方法的结合使用,将极大地提升爬虫数据提取的效率和准确性。
4. 图片下载与本地存储
在构建完整的图片爬取系统时,除了能够精准提取图片链接之外,还需要实现图片的下载与本地存储功能。这一过程不仅仅是简单的文件操作,更需要考虑路径管理、文件命名策略、数据完整性、异常处理等关键问题。本章将深入解析图片下载与存储的实现流程,并通过代码演示、流程图分析、参数说明和优化策略,帮助读者构建稳定、高效且具备扩展性的图片下载模块。
4.1 图片下载的基本流程
图片下载本质上是通过HTTP协议获取图片资源的二进制数据,然后将其保存为本地文件。这一过程涉及网络请求、数据处理和文件写入三个核心步骤。在Python中,常用的图片下载方式包括使用 requests 库结合 open() 函数进行写入,或者使用更底层的 urllib.request 模块直接处理。
4.1.1 使用urllib库发起图片请求
urllib 是Python标准库中的一个网络请求模块,虽然功能不如 requests 库强大,但在简单场景下足够使用。以下是一个使用 urllib.request 下载图片的示例代码:
import urllib.request
image_url = 'https://example.com/images/sample.jpg'
file_path = './downloads/sample.jpg'
urllib.request.urlretrieve(image_url, file_path)
代码逻辑分析:
- 第1行 :导入
urllib.request模块。 - 第3行 :定义要下载的图片链接。
- 第4行 :指定本地保存路径。
- 第6行 :使用
urlretrieve函数直接下载图片并保存到本地。
参数说明:
image_url:图片的完整URL地址。file_path:本地保存路径及文件名,路径必须存在,否则会抛出异常。
优点:无需额外安装依赖,适合简单项目。
缺点:缺乏异常处理机制,不支持Session、Headers设置等高级功能。
4.1.2 二进制数据的处理与保存
为了更灵活地控制下载过程,我们可以使用 requests 库获取响应的二进制数据,然后手动写入文件:
import requests
image_url = 'https://example.com/images/sample.jpg'
file_path = './downloads/sample.jpg'
response = requests.get(image_url, stream=True)
if response.status_code == 200:
with open(file_path, 'wb') as f:
for chunk in response.iter_content(1024):
f.write(chunk)
代码逻辑分析:
- 第4行 :发起GET请求,并设置
stream=True以支持流式下载。 - 第5行 :判断响应状态码是否为200(成功)。
- 第6行 :以二进制写入模式打开本地文件。
- 第7-8行 :使用
iter_content方法分块读取响应内容,防止内存溢出。
参数说明:
stream=True:表示以流的方式下载数据,适用于大文件。iter_content(1024):每次读取1024字节的数据块。'wb':以二进制写入模式打开文件。
优势分析:
- 可以自定义Headers、Cookies等参数。
- 支持更复杂的异常处理逻辑。
- 更适用于生产环境或大型项目。
4.2 文件路径管理与目录创建
在进行图片下载时,合理的文件路径管理对于项目的可维护性和健壮性至关重要。我们需要确保目标目录存在,避免因路径不存在而引发错误。此外,合理的文件命名策略也能有效避免文件覆盖和命名冲突。
4.2.1 os模块创建文件夹与路径拼接
Python的 os 模块提供了强大的路径操作功能,以下是一个自动创建下载目录并拼接文件路径的示例:
import os
download_dir = './downloads'
if not os.path.exists(download_dir):
os.makedirs(download_dir)
file_name = 'sample.jpg'
file_path = os.path.join(download_dir, file_name)
代码逻辑分析:
- 第3行 :定义下载目录路径。
- 第4-5行 :检查目录是否存在,若不存在则创建。
- 第7-8行 :使用
os.path.join安全拼接路径,避免平台差异。
参数说明:
os.makedirs():递归创建目录,即使父目录不存在也不会报错。os.path.join():跨平台兼容路径拼接工具,避免手动拼接带来的错误。
| 方法 | 说明 |
|---|---|
os.makedirs(path) |
创建多级目录 |
os.path.exists(path) |
判断路径是否存在 |
os.path.join(path1, path2) |
路径拼接 |
4.2.2 文件命名策略与去重机制
为了避免下载的图片文件被覆盖,可以采用时间戳、哈希值或唯一ID作为文件名。以下是基于时间戳的命名策略示例:
import time
timestamp = int(time.time())
file_name = f'image_{timestamp}.jpg'
逻辑说明:
- 使用当前时间戳作为文件名的一部分,确保每次下载的文件名唯一。
- 可结合图片链接的哈希值或内容哈希值进一步增强唯一性。
去重机制:
若需避免重复下载相同图片,可以记录已下载图片的URL或哈希值:
import hashlib
def get_hash(url):
return hashlib.md5(url.encode()).hexdigest()
downloaded_hashes = set()
image_url = 'https://example.com/images/sample.jpg'
url_hash = get_hash(image_url)
if url_hash not in downloaded_hashes:
downloaded_hashes.add(url_hash)
# 执行下载操作
4.3 图片链接的处理与优化
在实际爬取过程中,图片链接可能以相对路径或缺少协议的方式存在,直接使用这些链接会导致下载失败。因此,我们需要对图片链接进行标准化处理,包括协议补全、域名补全、相对路径转换等。
4.3.1 绝对路径与相对路径的转换
当图片链接为相对路径时,需要将其转换为绝对URL。可以使用 urllib.parse 模块的 urljoin 函数实现:
from urllib.parse import urljoin
base_url = 'https://example.com/images/'
relative_url = 'photo.jpg'
absolute_url = urljoin(base_url, relative_url)
print(absolute_url) # 输出:https://example.com/images/photo.jpg
代码逻辑分析:
- 第3-4行 :定义基础URL和相对路径。
- 第6行 :使用
urljoin将两者合并为完整URL。
优势说明:
- 自动处理路径层级,如
../等。 - 支持不同格式的相对路径处理。
4.3.2 协议替换与域名补全技巧
有时图片链接会缺少协议头(如 //example.com/image.jpg ),此时应补全为 https:// 或 http:// :
def complete_url(url):
if url.startswith('//'):
return 'https:' + url
elif not url.startswith('http'):
return 'https://' + url
return url
image_url = '//example.com/images/photo.jpg'
print(complete_url(image_url)) # 输出:https://example.com/images/photo.jpg
逻辑说明:
- 检查链接是否以
//开头,若是则补全为https:。 - 若链接不以
http开头,则默认添加https://。
流程图示意:
graph TD
A[原始图片URL] --> B{是否以//开头?}
B -->|是| C[补全为https:]
B -->|否| D{是否以http开头?}
D -->|是| E[保留原URL]
D -->|否| F[添加https://]
C --> G[返回完整URL]
E --> G
F --> G
优化建议:
- 可结合正则表达式对URL进行更复杂的处理。
- 在项目中引入
urllib3或requests.utils中的requote_uri等工具函数提升健壮性。
通过本章内容的学习,我们不仅掌握了图片下载的核心技术流程,还学会了如何通过路径管理、文件命名策略、URL标准化等手段提升爬虫系统的稳定性和可维护性。下一章我们将进入爬虫进阶阶段,探讨反爬虫机制的应对策略与项目整合实践。
5. 爬虫进阶与规范实践
5.1 反爬虫机制的初步应对
网络爬虫在实际开发过程中,常常会遇到网站设置的反爬虫机制,如IP封禁、验证码验证、User-Agent识别等。为避免被网站屏蔽,开发者需要掌握一些基本的反爬策略应对技巧。
5.1.1 User-Agent伪装与代理IP使用
User-Agent(简称UA)是浏览器在发送请求时附带的标识信息,用于告诉服务器当前使用的操作系统、浏览器类型等信息。许多网站会根据UA来判断是否为爬虫请求。
User-Agent伪装示例:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
response = requests.get('https://example.com', headers=headers)
print(response.text)
参数说明:
- headers :设置请求头,伪装为浏览器访问。
- User-Agent :模拟Chrome浏览器在Windows 10上的访问。
代理IP使用:
代理IP可以防止IP被封,通过更换不同的IP地址发起请求。
proxies = {
'http': 'http://10.10.1.10:3128',
'https': 'http://10.10.1.10:1080',
}
response = requests.get('https://example.com', headers=headers, proxies=proxies)
参数说明:
- proxies :设置代理服务器地址,支持HTTP和HTTPS协议。
5.1.2 设置请求间隔与请求频率控制
频繁的请求会触发网站的反爬机制,因此应合理控制请求频率。
示例代码:
import time
import requests
urls = ['https://example.com/page{}'.format(i) for i in range(1, 6)]
for url in urls:
response = requests.get(url)
print(f"请求 {url},状态码:{response.status_code}")
time.sleep(2) # 每次请求间隔2秒
逻辑说明:
- time.sleep(2) :每次请求后暂停2秒,模拟用户访问节奏,降低被封风险。
5.2 Robots协议与爬虫伦理规范
5.2.1 Robots.txt文件解析与遵循原则
robots.txt 是网站根目录下的一个文本文件,用于告知搜索引擎或爬虫哪些页面可以抓取,哪些禁止抓取。
robots.txt 示例:
User-agent: *
Disallow: /private/
Disallow: /admin/
Crawl-delay: 2
参数说明:
- User-agent: * :适用于所有爬虫。
- Disallow :禁止爬取的路径。
- Crawl-delay :请求间隔时间(单位:秒)。
读取robots.txt的Python代码示例:
import requests
robots_url = 'https://example.com/robots.txt'
response = requests.get(robots_url)
print(response.text)
5.2.2 合法合规的爬虫开发原则
- 遵守目标网站的robots.txt文件。
- 控制请求频率,避免对服务器造成压力。
- 不爬取敏感信息,如用户隐私、账号密码等。
- 若需大规模抓取数据,建议联系网站管理员获取授权。
5.3 图片爬虫完整项目实现
5.3.1 模块整合与代码结构设计
我们将前面章节的知识整合,构建一个完整的图片爬虫项目。
项目结构:
image_crawler/
│
├── crawler.py # 主程序
├── config.py # 配置文件
├── utils.py # 工具函数
└── images/ # 图片存储目录
utils.py 示例代码:
import os
def create_dir(path):
if not os.path.exists(path):
os.makedirs(path)
crawler.py 示例代码:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
from utils import create_dir
headers = {
'User-Agent': 'Mozilla/5.0'
}
def fetch_page(url):
response = requests.get(url, headers=headers)
return response.text
def parse_images(html, base_url):
soup = BeautifulSoup(html, 'html.parser')
images = soup.find_all('img')
return [urljoin(base_url, img.get('src')) for img in images]
def download_image(url, path):
response = requests.get(url, headers=headers)
with open(path, 'wb') as f:
f.write(response.content)
def main():
start_url = 'https://example.com/gallery'
html = fetch_page(start_url)
image_urls = parse_images(html, start_url)
save_dir = 'images'
create_dir(save_dir)
for i, url in enumerate(image_urls):
filename = os.path.join(save_dir, f'image_{i}.jpg')
download_image(url, filename)
print(f"已下载图片:{filename}")
if __name__ == '__main__':
main()
5.3.2 异常处理与日志记录机制
为提高程序的健壮性,我们需要添加异常处理和日志记录功能。
增强版异常处理代码:
import logging
logging.basicConfig(filename='crawler.log', level=logging.INFO)
def fetch_page(url):
try:
response = requests.get(url, headers=headers, timeout=10)
response.raise_for_status() # 抛出HTTP错误
return response.text
except requests.exceptions.RequestException as e:
logging.error(f"请求失败:{url},错误信息:{e}")
return None
参数说明:
- timeout=10 :设置请求超时时间为10秒。
- raise_for_status() :如果响应状态码不是200,抛出异常。
- logging :将错误信息写入日志文件,便于后续排查问题。
优化建议:
- 可以引入 logging 模块记录每次请求的详细信息。
- 使用 try-except 块包裹关键操作,确保程序在异常情况下不会崩溃。
- 引入 retrying 模块实现失败重试机制。
(注:章节内容到此结束,未包含总结性语句)
简介:Python网络爬虫广泛应用于数据采集与信息提取,本文重点讲解如何使用Python爬取网页中的图片资源。通过requests发起请求,BeautifulSoup解析HTML,结合正则表达式提取图片链接,并利用urllib和os模块实现图片下载与本地存储。教程包含完整代码示例与实战流程,适合初学者掌握图片爬虫核心技术,同时提醒开发者遵守Robots协议,合理合法进行数据抓取。

加入社区!打开量化的大门,首批课程上线啦!
更多推荐


 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)