
【爬虫数据抓包】获取指定CSDN博主的全部文章信息
【爬虫数据抓包】获取指定CSDN博主的全部文章信息前言方法步骤打开主页获取指定用户博文数获取主页博文信息存储数据至excel中读取excel中文章的url完整代码结果展示前言之前一直零散的搞点儿爬虫玩玩,没有系统学习爬虫的基础原理,今天开始学习B站老师的课,才知道自己有多么差劲。跟着老师练习了简单的requests.get/post进行数据抓包,感觉挺有意思,就想着能不能把我的blog信息爬取下来
·
【爬虫数据抓包】获取指定CSDN博主的全部文章信息
前言
之前一直零散的搞点儿爬虫玩玩,没有系统学习爬虫的基础原理,今天开始学习B站老师的课,才知道自己有多么差劲。跟着老师练习了简单的requests.get/post进行数据抓包,感觉挺有意思,就想着能不能把我的blog信息爬取下来存储到excel里面。
方法步骤
打开主页
以我的主页为例:
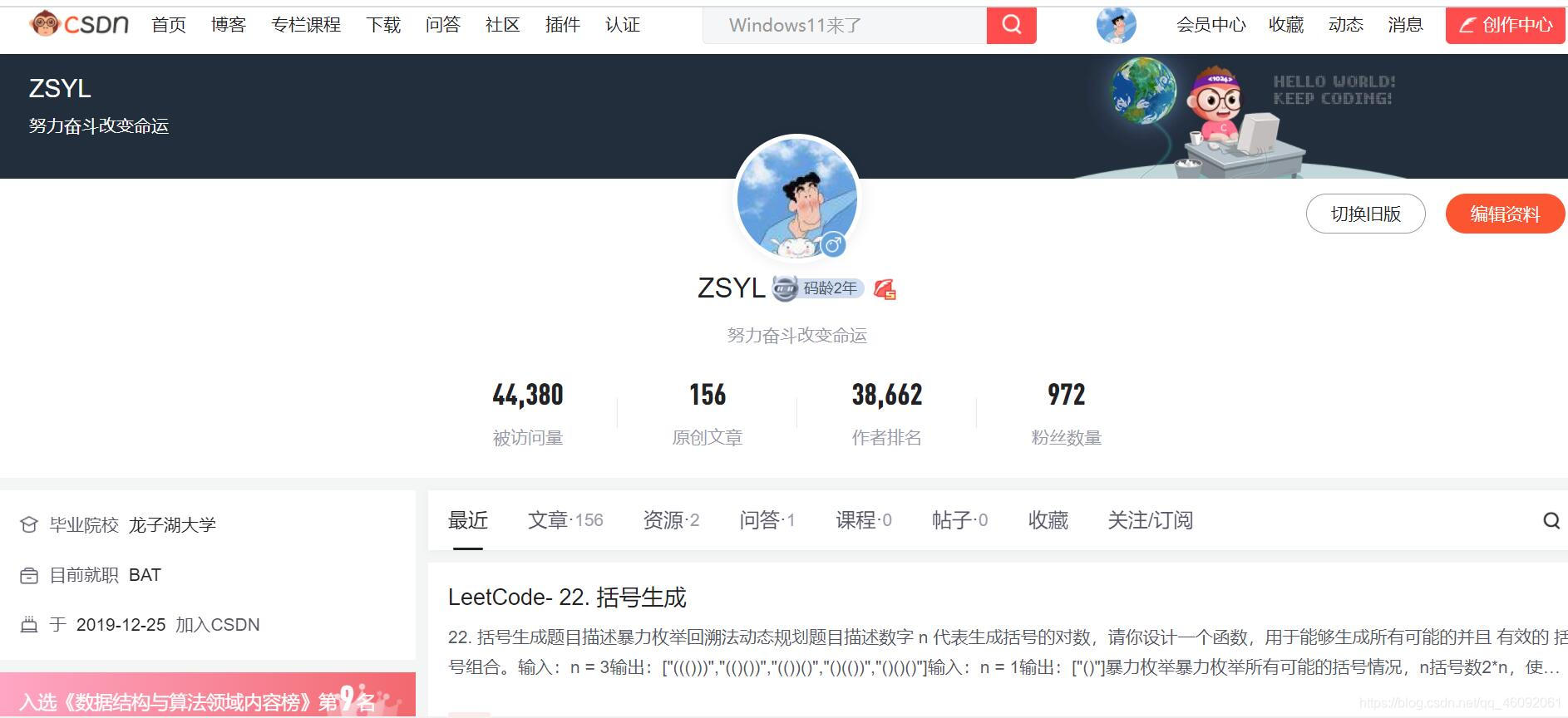
F12:检查网页源代码NetWork:刷新,查看服务器发来的数据包Fetch/XHR:数据更具体Preview:查看json格式的数据

在这里我们可以看到我博客相关数据,如:下载内容:2,问答ask:1,博文数blog:156 等。
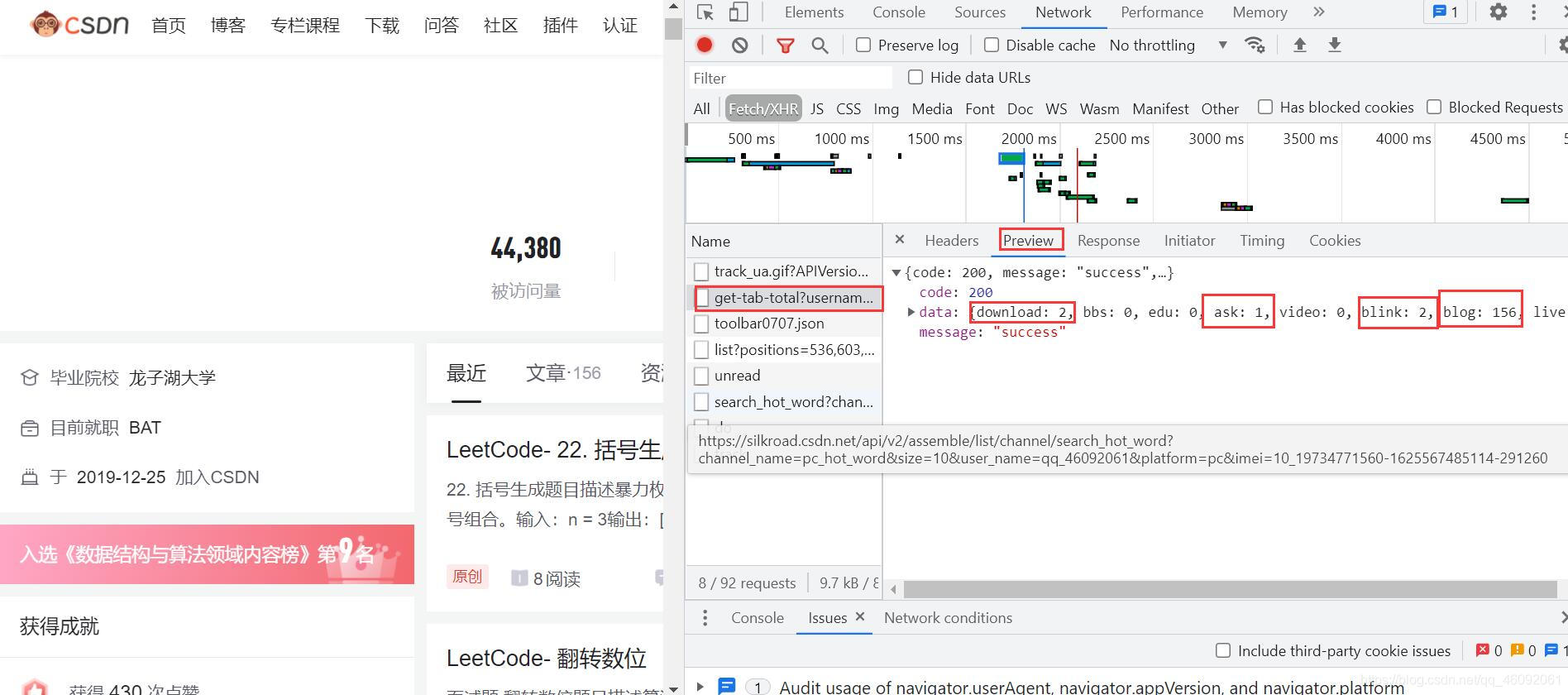
Headers:这里面有我们的请求体,请求参数,请求方式,以及 响应头等。

最下面是我们的请求参数:

获取指定用户博文数
params:请求参数response.json():返回服务器发送回来的json类型data数据
# 获取文章数
def getArticalCount(username):
# 请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4542.2 Safari/537.36'}
# 请求地址
url = 'https://blog.csdn.net/community/home-api/v1/get-tab-total'
# 请求参数
params = {'username': username}
response = requests.get(url, params=params, headers=headers)
print(params)
print(response.json())
return response.json()['data']['blog']
获取主页博文信息
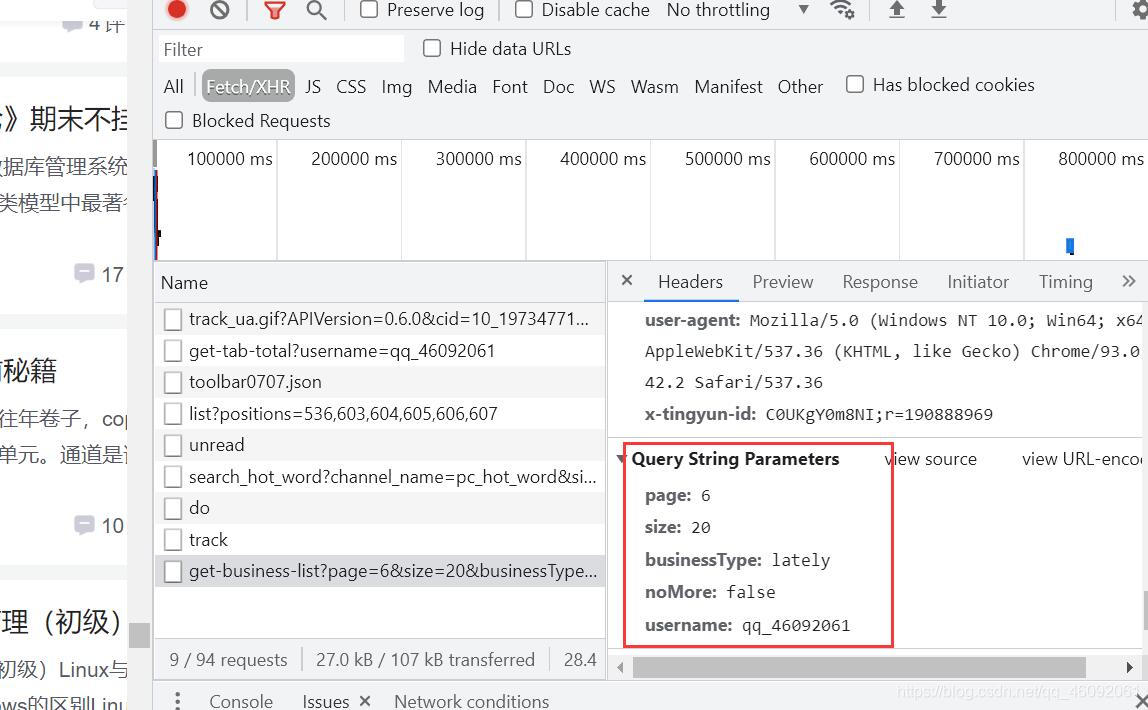
- 鼠标滑轮一直往下滑动,你会发现
Fetch/XHR,会有新的数据库更新

这里面有我们需要的请求url,及请求参数,于是我们想要的东西就够了。
# 获取数据抓包,返回json数据集
def getData(url, params):
# 请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4542.2 Safari/537.36'}
# 获取请求对象
response = requests.get(url, params=params, headers=headers)
# 返回数据抓包内容,json格式
return response.json()
分析发现参数中的size:代表一页有20篇文章,于是page参数知道怎么传了吗?
存储数据至excel中
# 保存json对象数据到excel中
def saveData(url, username, save_path):
# 创建工作博
wb = openpyxl.Workbook()
# 床架工作表
ws = wb.active
ws.title = 'CSDN用户文章信息'
# print(list(json_data[0].keys()))
# 请求参数
params = {'page': '6', 'size': '20', 'businessType': 'blog', 'noMore': 'false', 'username': username}
blogs = getArticalCount(username)
print('用户%s的博客数:%d' %(username, blogs))
index = 1
for i in range(int(blogs/20+1)):
# 修改请求参数
params['page'] = str(i+1)
print(params)
# 获取数据
json_data = getData(url, params=params)
print(json_data)
if i == 0:
# 添加表头数据
ws.append(list(json_data['data']['list'][0].keys()))
# print(list(json_data['data']['list'][0].values()))
# print(json_data['data']['list']) 列表对象,里面20篇文章
if i > blogs:
break
for article in json_data['data']['list']:
print(article)
ws.append(list(article.values()))
print('正在爬取第%d篇文章' % index)
index += 1
wb.save(save_path)
print('爬取成功!!!')
读取excel中文章的url
数据存完了,我们可以读出来做其他的事情,比如给博主刷波评论,点波赞之类的。(* ̄︶ ̄)
如果你觉得我的文章有用,请您最后给我点个赞呦,蟹蟹您!
# 读取文件访问所有文章
def read_excel(excelUrl, username):
# 获取工作簿
wb = openpyxl.load_workbook(excelUrl)
# 获取sheet
ws = wb.active
rows = getArticalCount(username)
# 读取部分行 部分列,获取所有url
for row in ws.iter_rows(min_row=2, max_row=rows+1, min_col=4, max_col=4):
for cell in row:
requests.get(cell.value)
print('访问', cell.value, '成功', end='\t\t')
# 换行
print()
完整代码
# 爬取用户主页所有文章,使用数据抓包的方式
import requests
import openpyxl
# 获取数据抓包,返回json数据集
def getData(url, params):
# 请求头
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4542.2 Safari/537.36'}
# 获取请求对象
response = requests.get(url, params=params, headers=headers)
# 返回数据抓包内容,json格式
return response.json()
# 获取文章数
def getArticalCount(username):
# 请求头
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4542.2 Safari/537.36'}
# 请求地址
url = 'https://blog.csdn.net/community/home-api/v1/get-tab-total'
# 请求参数
params = {'username': username}
response = requests.get(url, params=params, headers=headers)
print(params)
print(response.json())
return response.json()['data']['blog']
# 保存json对象数据到excel中
def saveData(url, username, save_path):
# 创建工作博
wb = openpyxl.Workbook()
# 获取工作表
ws = wb.active
ws.title = 'CSDN用户文章信息'
# print(list(json_data[0].keys()))
# 请求参数
params = {'page': '6', 'size': '20', 'businessType': 'blog', 'noMore': 'false', 'username': username}
blogs = getArticalCount(username)
print('用户%s的博客数:%d' %(username, blogs))
index = 1
for i in range(int(blogs/20+1)):
# 修改请求参数
params['page'] = str(i+1)
print(params)
# 获取数据
json_data = getData(url, params=params)
print(json_data)
if i == 0:
# 添加表头数据
ws.append(list(json_data['data']['list'][0].keys()))
# print(list(json_data['data']['list'][0].values()))
# print(json_data['data']['list']) 列表对象,里面20篇文章
if i > blogs:
break
for article in json_data['data']['list']:
print(article)
ws.append(list(article.values()))
print('正在爬取第%d篇文章' % index)
index += 1
wb.save(save_path)
print('爬取成功!!!')
# 读取文件访问所有文章
def read_excel(excelUrl, username):
# 获取工作簿
wb = openpyxl.load_workbook(excelUrl)
# 获取sheet
ws = wb.active
rows = getArticalCount(username)
# 读取部分行 部分列,获取所有url
for row in ws.iter_rows(min_row=2, max_row=rows+1, min_col=4, max_col=4):
for cell in row:
requests.get(cell.value)
print('访问', cell.value, '成功', end='\t\t')
print()
if __name__ == '__main__':
# 请求的url
url = 'https://blog.csdn.net/community/home-api/v1/get-business-list'
# 指定用户名(唯一)
username = 'qq_46092061'
# 保存路径
save_path = './CSDN用户文章信息.xlsx'
# 保存
saveData(url, username, save_path)
read_excel(save_path, username)
结果展示



加油!
感谢!
努力!

加入社区!打开量化的大门,首批课程上线啦!
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)