
Python量化投资(四):搭建股票舆情分析平台(一)
本文介绍了利用自然语言处理技术实现股票舆情分析的量化投资方法。作者首先通过Python爬取个股新闻数据,尝试使用百度API进行情感分析,但发现通用模型在金融领域的适用性有限。随后改用SnowNLP框架,通过准备专业股票语料库重新训练模型,实现了更准确的股票情感分析。该方法解决了人工监测个股舆情效率低、主观性强的问题,为量化投资提供了自动化舆情监控工具。文章还展望了后续将分析结果导入数据库并构建BI
主导的BI项目终于结项了,随着项目的结束,也进入到了春节假期,春节太冷,于是在家又搞起了量化投资研究,前面文章通过三步走分别实现了第一个量化选股策略、搭建了自己的股票数据仓库以及股票分析BI驾驶舱。趁着假期继续学习和记录我的量化投资之旅。
由于市场风云变换,个股时不时会受到市场或者自身经营面的影响,股价此起彼伏,这时就需要投资者时刻关注市场及行业动向,特别是个股的基本面分析等,之前我的方法是每天早上起床第一件事就是打开股票软件查看新闻动态、个股公告、投资者论坛等,分析当前股票基本面及舆论情况,因为股价在很大程度上会受到投资者情绪影响,这时不得不去判断当前个股所处的舆情状态是偏积极还是偏消极,然而,人工监测判断的方法,只适用于一两个个股,超过3个则比较占用自己的时间了,且相对来说带有主观性。这时候,我们是否可以利用机器来做舆情判断,答案是可以的。现在人工智能如火如荼,而人工智能领域的其中一个方向——自然语言处理(NLP),则可以帮到我们。

在开篇之前,先回顾一版自己的量化投资框架如下:
个人量化投资整体思路:
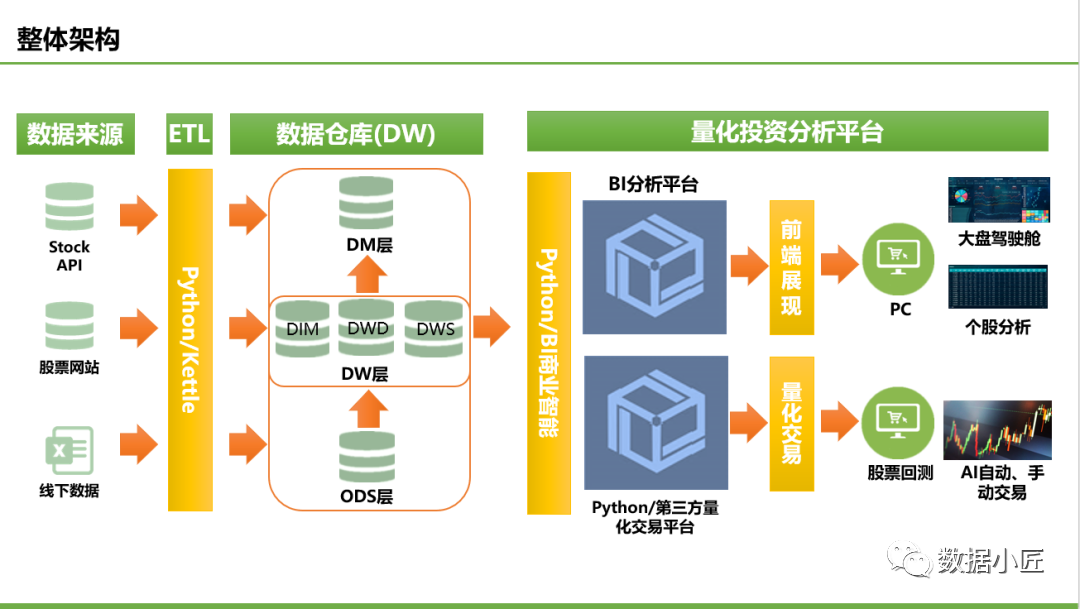
舆论分析思路
通过每天自动爬取个股相关新闻、公告及论坛文章,通过NLP技术,自动判别每篇文章是积极的,还是消极的,通过一段时间内的积极和消极新闻的占比,确定该股票此时是处于利好还是利空。然后每天定时抓取判别后导入股票数据仓库,通过BI建立股票舆情平台。
新闻数据爬取
通过Python的request包遍历爬取金融网的个股资讯标题
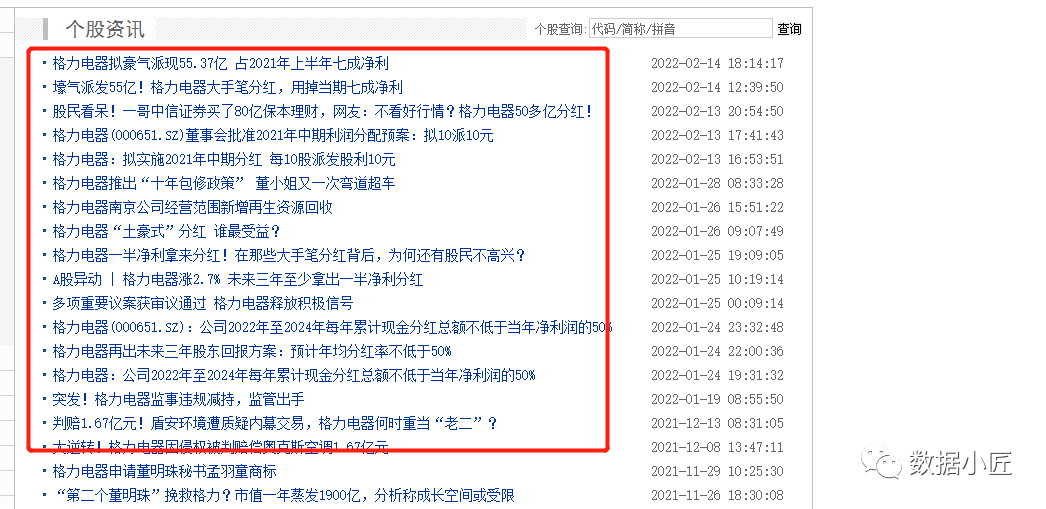
通过查看网页源文件,获取对应信息的xpath地址,爬取相关信息。
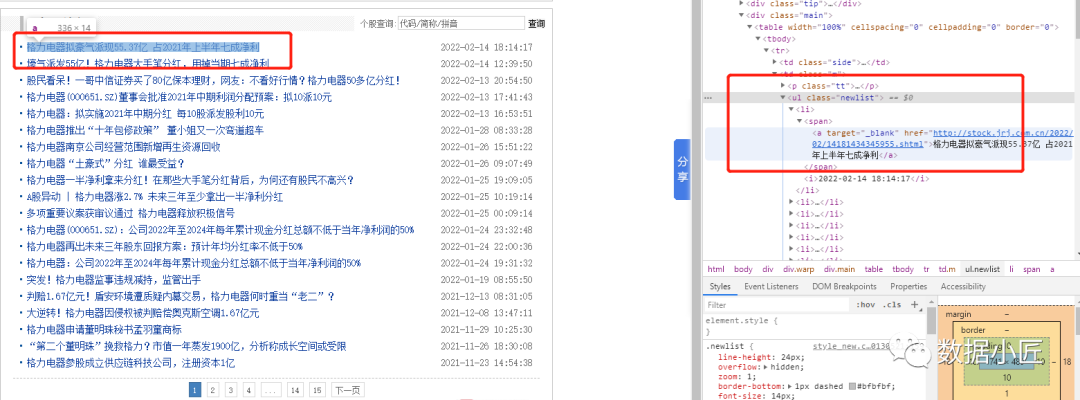
# 导入必要的包import requestsimport matplotlib.pyplot as pltimport pandas as pdfrom lxml import etree############################## 1、舆情数据抓取 ################################## 获取url下的最大page数 url='http://stock.jrj.com.cn/share,000651,ggxw.shtml'def get_max_page(url):page_data = requests.get(url).content.decode("gbk")data_tree = etree.HTML(page_data)if page_data.find("page_newslib"):max_page = data_tree.xpath("//*[@class=\"page_newslib\"]//a[last()-1]/text()")return int(max_page[0])else:return 1# 解析指定页面的数据并保存至本地url ='http://stock.jrj.com.cn/share,000651,ggxw.shtml',code = '000651'def download_page(url, code):try:page_data = requests.get(url).content.decode("gbk")data_tree = etree.HTML(page_data)titles = data_tree.xpath("//*[@class = \"newlist\"]//li/span/a/text()") # 获取标题urls = data_tree.xpath("//*[@class = \"newlist\"]//li/span/a/@href") # 获取urlc = {"titles": titles, "url": urls}data = pd.DataFrame(c)data['code'] = codereturn dataexcept:print("服务器超时")# 解析每个页面的数据def parse_pages(url, code):max_page = get_max_page(url)df1 = pd.DataFrame()for i in range(1, max_page + 1):if i != 1:url = "http://stock.jrj.com.cn/share," + str(code) + ",ggxw_" + str(i) + ".shtml"data = download_page(url, code)df1 = pd.concat([df1,data])return df1# 下载指定的股票的新闻数据def download_news(codes):df2 = pd.DataFrame()for code in codes:print(code)url = "http://stock.jrj.com.cn/share," + str(code) + ",ggxw.shtml"data = parse_pages(url, code)df2= pd.concat([df2,data])return df2
百度apiNLP情感分析
在获取了股票的新闻数据之后,接下来对每支股票的所有新闻进行情感分析,最便捷的方法是直接通过第三方接口调用,如百度智能云有提供免费和付费的自然语言处理接口,可以借此进行对股票新闻的情感分析,但需要注意的是,免费的公共接口算法不透明,可能跟实际应用场景存在偏离,而且有一定次数的免费使用限制,超过次数则按次收费(作为长期大量使用者,使用超限是分分钟的事儿)。
在使用百度智能云apiNLP之前,需要先注册并获取APP_ID、API_KEY以及SECRET_KEY。获取的方式如下:
首先,登录并注册百度人工智能平台(https://ai.baidu.com/):

进入控制台创建自然语言处理应用:

创建完后,会有专门的APP_ID、API_KEY以及SECRET_KEY,并且可提供500000次的免费调用次数,超过则需付费调用(按2.5元/千次收费)。
我们先用百度apiNLP做一下情感分析如下:
from aip import AipNlp# 对指定股票的所有新闻数据进行情感分析并进行统计 code = '000651'def analyze(titles):APP_ID = 'xxxxxxx'API_KEY = 'xxxxxxx'SECRET_KEY = 'xxxxxxx'aipNlp = AipNlp(APP_ID, API_KEY, SECRET_KEY)# nlp情感分析result = aipNlp.sentimentClassify(titles)positive_prob = result['items'][0]['positive_prob']nagative_prob = result['items'][0]['negative_prob']confidence = result['items'][0]['confidence']dic = {'positive_prob':positive_prob,'nagative_prob':nagative_prob,'confidence':confidence}return dic# 对指定的股票进行情感分析并保存到本地data = df,i = 1def analyze_stocks(data):df3 = pd.DataFrame()for i in range(0,len(data)):data1 = data.loc[[i]]titles = data.loc[[i]].values[0][0]stock_dict = analyze(titles)data1['positive_prob'] = stock_dict['positive_prob']data1['nagative_prob'] = stock_dict['nagative_prob']data1['confidence'] = stock_dict['confidence']df3 = pd.concat([df3,data1])time.sleep(0.5)return df3
爬取格力电器000651的新闻并进行舆情分析,通过设定阈值:积极概率positive_prob>=0.7为积极,positive_prob<=0.5为消极,介于0.5和0.7之间为中性,结果如下:
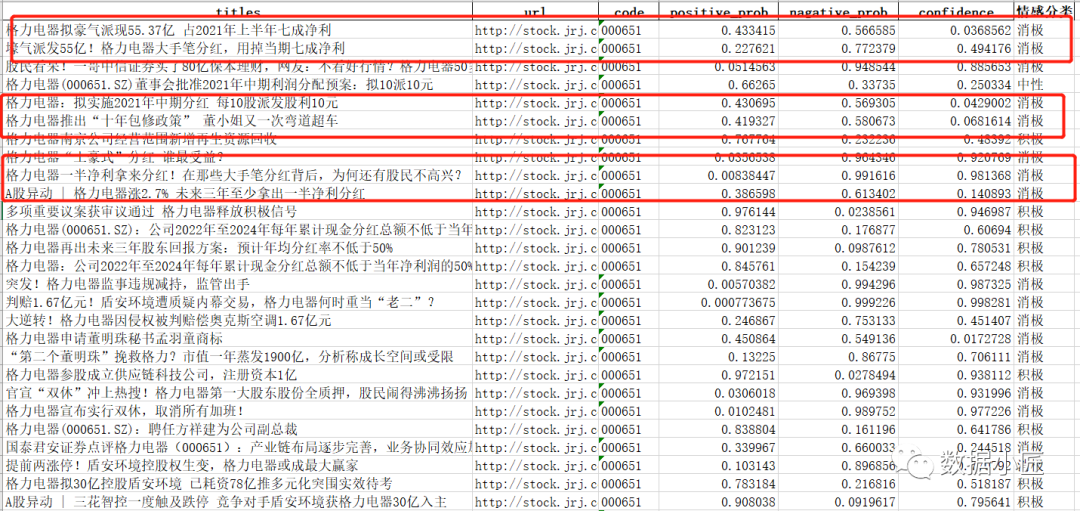
从分析结果可以看出,通过人工识别,大部分情感倾向是被判断正确了,但是还是有一部分被误判,比如作为价值投资者,上市公司大笔分红,理应该是利好(短线投机者除外),而模型却判定为了消极。这不得不让我再去看一下百度apiNLP的算法原理,发现百度apiNLP提供的通用情感分析算法,主要是基于商品评价或文章作为语料库训练的,也即是该算法存在场景限制。而股票情感分析,可能并不太适用,因为股票分析存在很多金融专业知识,利好利空,还需通过金融知识来判定。
SnowNLP情感分析
基于以上问题,小匠决定利用SnowNLP自己训练关于股票情感分析的模型,通过研究发现,SnowNLP是基于朴素贝叶斯算法的情感识别,而且通用的情感分析模型,也是基于在线商城平台的评价,如果需要对股票领域进行情感分析,可以导入数据进行训练。具体步骤如下:
通过分析源码,发现SnowNLP包的路径sentiment文件夹里面的,有如下文件:neg.txt、pos.txt,这两个文件分别为消极情绪语料、积极情绪语料,是默认的语料库。而sentiment.marshal和sentiment.marshal.3文件,均为通过默认语料训练得到的模型,其区别在于前者是Python3版本之前的序列化文件,后者是Python3版本的序列化文件。
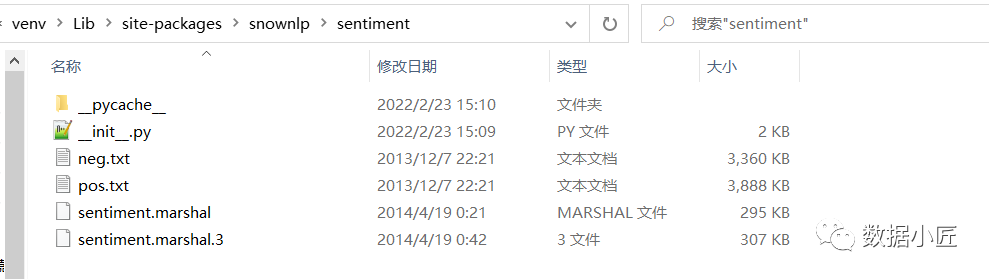
因此,我们只要准备一份关于股票的消极情绪语料、积极情绪语料进行重新训练模型,并保存模型即可。之后直接调用用于股票的情感分析。具体代码如下:
from snownlp import SnowNLPfrom snownlp import sentiment# 重新训练模型sentiment.train(r'E:\Python\Model\7.Python量化投资\db_stock\model\舆情分析\neg.txt',r'E:\Python\Model\7.Python量化投资\db_stock\model\舆情分析\pos.txt') # 训练用户提供的自定义的新的训练分词词典的负面情感数据集和正面情感数据集sentiment.save(r'E:\Python\Model\7.Python量化投资\db_stock\model\舆情分析\sentiment2.marshal') # 保存训练后的模型print(sentiment.data_path) # 查看or设置snownlp提供的默认情感分析模型的路径
需要注意的是需要修改sentiment目录下__init__.py文件中的data_path,来指定我们自己的模型路径,这样在以后导入snownpl.sentiment时,即可直接使用股票预测功能,来判断目标的情感值。
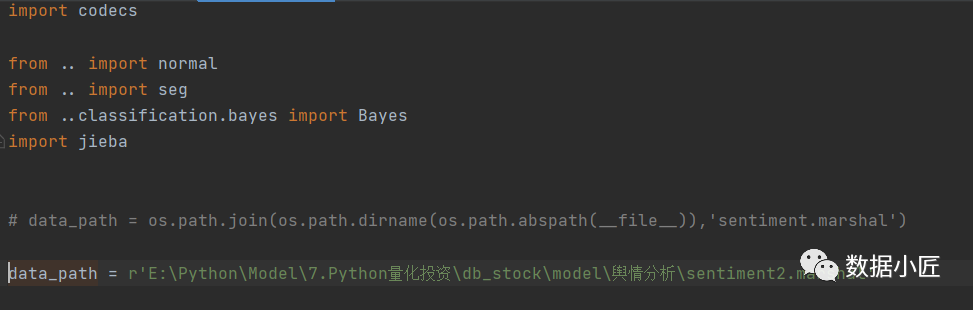
最后,利用训练好的股票舆情分析模型判别个股新闻情感倾向:
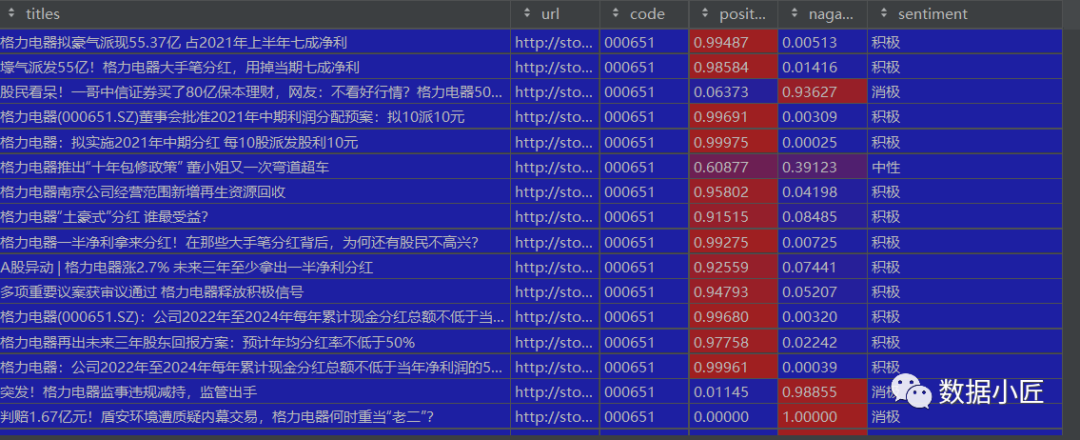
# 网页抓取舆论信息codes = ['000651', '601318', '000002']df = ss.download_news(codes)df.reset_index(inplace=True, drop=True)# nlp情感识别df3 = pd.DataFrame()for i in range(0, len(df)):data1 = df.loc[[i]]titles = df.loc[[i]].values[0][0]data1['positive_prob'] = SnowNLP(titles).sentimentsdata1['nagative_prob'] = 1 - SnowNLP(titles).sentimentsif data1['positive_prob'].values >= 0.7:data1['sentiment'] = '积极'elif data1['positive_prob'].values >= 0.5:data1['sentiment'] = '中性'else:data1['sentiment'] = '消极'df3 = pd.concat([df3, data1])
分析结果发现,基本上已经判断正确
结语
此次项目主要讲述了数据小匠量化投资逻辑的整体框架,通过Python编程批量抓取了上市公司近期的新闻资讯,先是调用百度云apiNLP接口实现情感识别,发现诸多局限性如:存在限量收费和特定场景限制。最后是利用了强大的SnowNLP包,通过分析源码,修改源码,自主准备基于股票情感的语料库,训练股票情感分析模型,应用模型。下一步将会把分析结果导入数据库,进而基于BI平台搭建股票舆情分析平台。PS:感兴趣的朋友可以关注本公众号,并后台回复“股票NLP”获取完整代码和股票分析语料库。

加入社区!打开量化的大门,首批课程上线啦!
更多推荐


 32
32 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)