
量化交易学习日记6-根据区间日期读取个股的L2数据的函数
登录聚宽账号(确保你已经有账号并填写了正确的用户名和密码)于是专门去写了一个方法来根据区间日期读取个股的L2数据。之前导入数据转换成dataframe太麻烦了。我的文件存储结构是这样的。
·
我的文件存储结构是这样的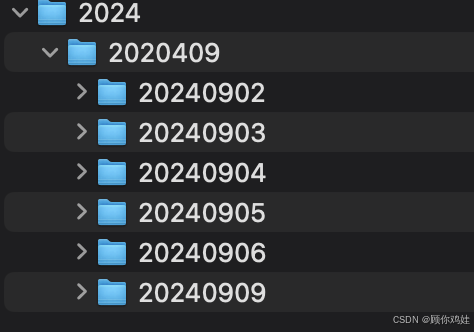
之前导入数据转换成dataframe太麻烦了
dic={}
for i in range(2,7):
dic[f'df_090{i}']=pd.read_csv(f'/Users/gusuqi/Downloads/2024090{i}/601881.SH/逐笔成交.csv',encoding='gbk')
for i in range(2,7):
dic[f'df_090{i}']=dic[f'df_090{i}'][['万得代码','自然日','时间','BS标志','成交价格','成交数量','叫买序号','叫卖序号']]
dic[f'df_090{i}']['成交价格']=dic[f'df_090{i}']['成交价格']/10000
dic[f'df_090{i}']['成交数量']=dic[f'df_090{i}']['成交数量']/100
dic[f'df_090{i}']['成交额']=dic[f'df_090{i}']['成交价格']*dic[f'df_090{i}']['成交数量']*100
于是专门去写了一个方法来根据区间日期读取个股的L2数据。
贴上代码
def get_data(start_date,end_date,code):
# 登录聚宽账号(确保你已经有账号并填写了正确的用户名和密码)
auth('','')
# 获取指定时间段内的交易日
trade_days = get_trade_days(start_date=start_date, end_date=end_date)
# 将所有交易日的格式转换为 'YYYYMMDD' 格式,并去掉 '-'
formatted_trade_days = [day.strftime('%Y%m%d') for day in trade_days]
# 创建一个字典,用来放每一天的 dataframe
dic = {}
for i in formatted_trade_days:
year = i[:4] # 提取前四位数字,表示年份
year_month = i[:6] # 提取前六位数字,表示年份和月份
# 动态构造路径
file_path = f'/Volumes/PSSD/{year}/{year_month}/{i}/{code}/逐笔成交.csv'
# 读取 CSV 文件
dic[f'df_{i}'] = pd.read_csv(file_path, encoding='gbk')
# 保留所需的列
dic[f'df_{i}'] = dic[f'df_{i}'][['万得代码', '自然日', '时间', 'BS标志', '成交价格', '成交数量', '叫买序号', '叫卖序号']]
# 对列进行计算
dic[f'df_{i}']['成交价格'] = dic[f'df_{i}']['成交价格'] / 10000
dic[f'df_{i}']['成交数量'] = dic[f'df_{i}']['成交数量'] / 100
dic[f'df_{i}']['成交额'] = dic[f'df_{i}']['成交价格'] * dic[f'df_{i}']['成交数量'] * 100
return dic
调用示例:
dic=get_data('20230504','20230505','000001.SZ')
dic['df_20230505']
结果: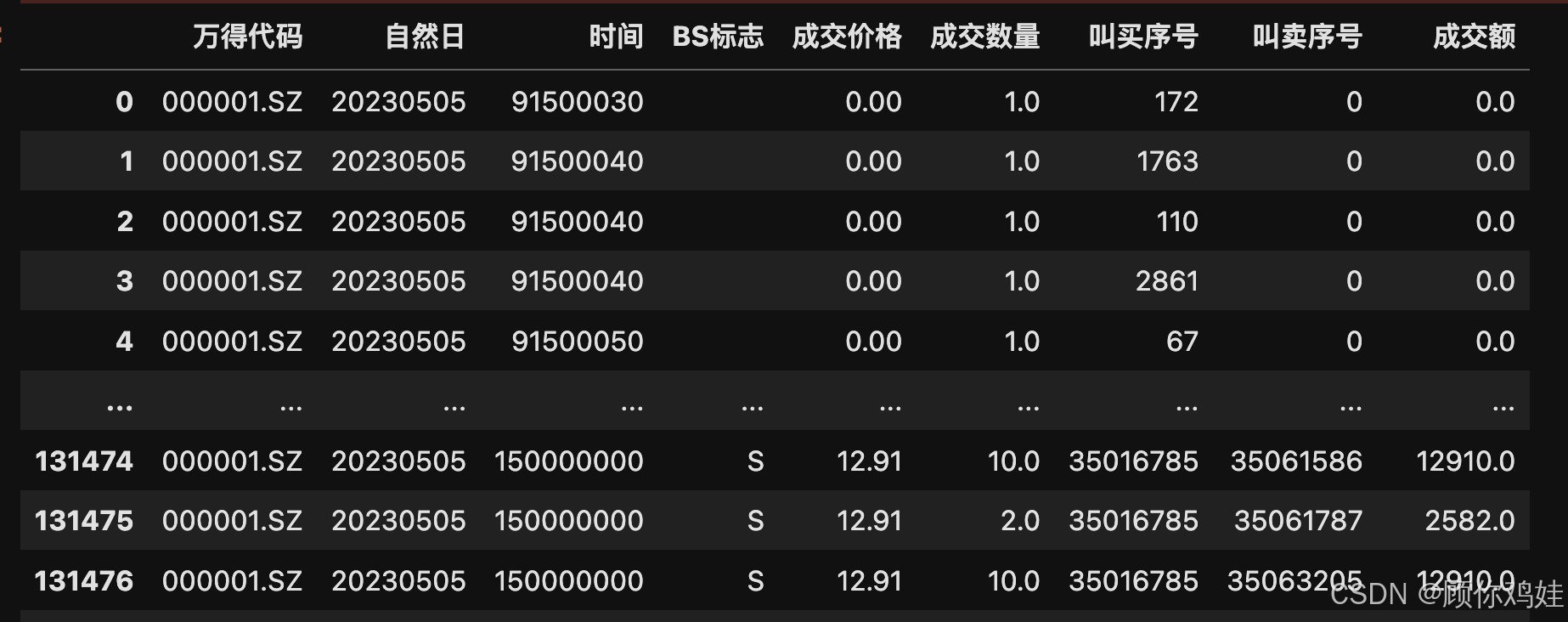

加入社区!打开量化的大门,首批课程上线啦!
更多推荐



 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)