1 什么是决策树
决策树(Decision Tree)是一种基本的分类与回归方法,本文主要讨论分类决策树。决策树模型呈树形结构,在分类问题中,表示基于特征对数据进行分类的过程。它可以认为是if-then规则的集合。每个内部节点表示在属性上的一个测试,每个分支代表一个测试输出,每个叶节点代表一种类别。
决策树的优点:
1)可以自学习。在学习过程中不需要使用者了解过多的背景知识,只需要对训练数据进行较好的标注,就能进行学习。
2)决策树模型可读性好,具有描述性,有助于人工分析;
3)效率高,决策树只需要一次构建,就可以反复使用,每一次预测的最大计算次数不超过决策树的深度。
举一个通俗的例子,假设一位母亲在给女儿介绍对象时,有这么一段对话:
母亲:给你介绍个对象。
女儿:年纪多大了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女生的决策过程就是典型的分类决策树。相当于对年龄、外貌、收入和是否公务员等特征将男人分为两个类别:见或者不见。假设这个女生的决策逻辑如下:
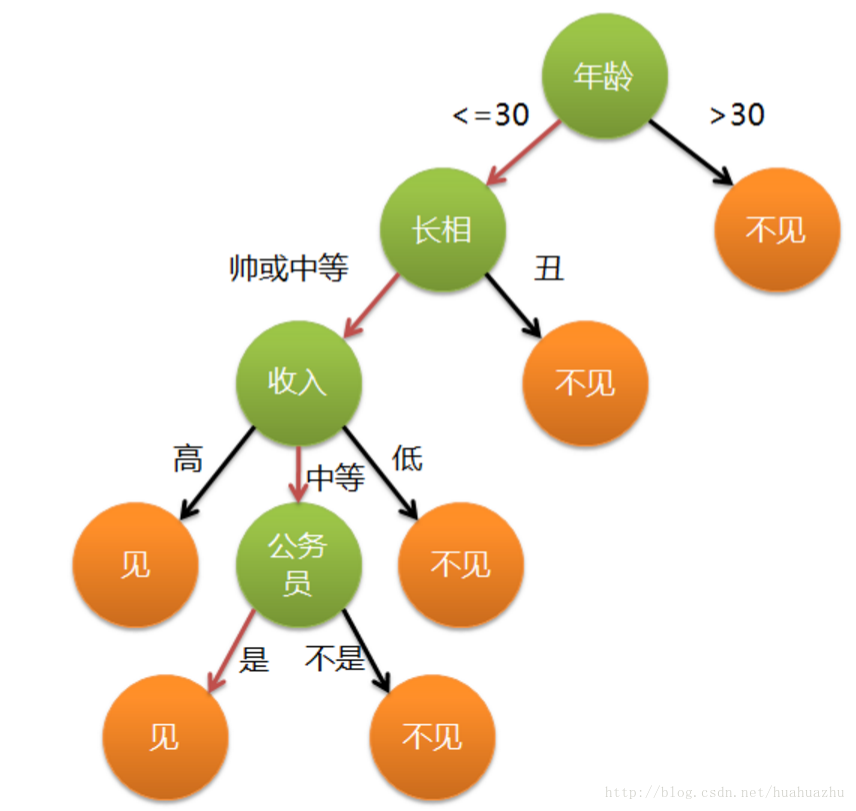
上图完整表达了这个女孩决定是否见一个约会对象的策略,其中绿色结点(内部结点)表示判断条件,橙色结点(叶结点)表示决策结果,箭头表示在一个判断条件在不同情况下的决策路径,图中红色箭头表示了上面例子中女孩的决策过程。
这幅图基本可以算是一棵决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
2 构建决策树
2.1 构建决策树的基本步骤
决策树构建的基本步骤如下:
1. 开始,所有记录看作一个节点
2. 遍历每个特征的每一种分裂方式,找到最好的分裂特征(分裂点)
3. 分裂成两个或多个节点
4. 对分裂后的节点分别继续执行2-3步,直到每个节点足够“纯”为止
如何评估分裂点的好坏?如果一个分裂点可以将当前的所有节点分为两类,使得每一类都很“纯”,也就是同一类的记录较多,那么就是一个好分裂点。
具体实践中,到底选择哪个特征作为当前分裂特征,常用的有下面三种算法:
ID3:使用信息增益g(D,A)进行特征选择
C4.5:信息增益率 =g(D,A)/H(A)
CART:基尼系数
一个特征的信息增益(或信息增益率,或基尼系数)越大,表明特征对样本的熵的减少能力更强,这个特征使得数据由不确定性到确定性的能力越强。
2.2 构建决策树例子
下面就以一个经典的打网球的例子来说明如何构建决策树。我们今天是否去打网球(play)主要由天气(outlook)、温度(temperature)、湿度(humidity)、是否有风(windy)来确定。样本中共14条数据。
NO. Outlook temperature humidity windy play
1 sunny hot high FALSE no
2 sunny hot high TRUE no
3 overcast hot high FALSE yes
4 rainy mild high FALSE yes
5 rainy cool normal FALSE yes
6 rainy cool normal TRUE no
7 overcast cool normal TRUE yes
8 sunny mild high FALSE no
9 sunny cool normal FALSE yes
10 rainy mild normal FALSE yes
11 sunny mild normal TRUE yes
12 overcast mild high TRUE yes
13 overcast hot normal FALSE yes
14 rainy mild high TRUE no
下面将分别介绍使用ID3和C4.5算法构建决策树。
2.2.1 使用ID3算法构建决策树
ID3算法是使用信息增益来选择特征的。
2.2.1.1 信息增益的计算方法
信息增益的计算方法如下:
1、计算数据集D的经验熵
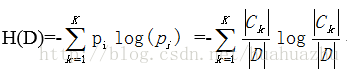
其中|D|是数据集中所有样本个数,k是目标变量的类别数,|Ck |是该分类下的样本个数。
2、遍历所有特征,对于特征A:
计算特征A对数据集D的经验条件熵H(D|A)
计算特征A的信息增益g(D,A)=H(D)-H(D|A)
选择信息增益最大的特征作为当前分裂特征。
2.2.1.2 计算是否打球的经验熵
在本例子中,目标变量D就是play是否打球,即yes打球和no不打球。|D|=14。K就是目标变量play是否打球的分类数,有两类yes打球和no不打球。yes打球这个分类下有9个样本,而no不打球这个分类下有5个样本,
所以信息熵H(D)=H(play)=-((9/14)*log(9/14)+(5/14)*log(5/14))= 0.651756561173
注意本文中log(x)均按照以e为底的。
2.2.1.3 计算outlook天气特征的信息增益
计算outlook天气特征对数据集D的经验条件熵为:
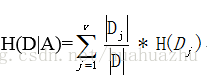
其中|D|是数据集中所有样本个数,j是当前特征的不同取值个数, |Dj|是第j个取值的样本个数, H(Dj)是该取值的样本的基于目标变量的信息熵。
具体计算如下:
特征A(天气)有三个不同的取值{sunny、overcast、rainy},即v=3,根据特征A(天气)的取值,将数据集D划分为三个子集:
其中sunny的子集中有5个样本,2个打球(play=yes),3个不打球(play=no);
Overcast的子集中有4个样本,都为打球(play=yes)
Rainy的子集中有5个样本,3个打球(play=yes),2个不打球(play=no)。
每个子集可以分别计算熵,具体公式如下
H(D|A)=H(play|outlook)=(5/14)sunny熵 + (4/14)*overcast熵+ (5/14)*rainy熵=(5/14)(-(2/5)log(2/5)-(3/5)*log(3/5)) + (4/14)(-(4/4)log(4/4)) + (5/14)(-(3/5)*log(3/5)-(2/5)*log(2/5))= 0.480722619292
所以天气特征的信息增益为:g(D,A)=g(D,outlook)=H(D)-H(D|A)= 0.17103394188
2.2.1.4 计算temperature温度特征的信息增益
计算temperature特征的经验条件熵。特征A(temperature温度)有三个不同的取值{hot,mild,cool},则v=3。根据特征的取值,将数据集D划分为三个子集:
其中hot的子集中有4个样本,2个打球(play=yes),2个不打球(play=no);
Mild的子集中有个6样本,4个打球(play=yes),2个不打球(play=no);
Cool的子集中有4个样本,3个打球(play=yes),1个不打球(play=no)。具体公式如下:
H(D|A)=H(play|temperature)=(4/14)hot熵+(6/14)*mild熵+(4/14)*cool熵 = (4/14)(-(2/4)log(2/4)-(2/4)*log(2/4)) + (6/14)(-(4/6)log(4/6)-(2/6)*log(2/6)) + (4/14)(-(3/4)*log(3/4)-(1/4)*log(1/4))= 0.631501022177
所以temperature温度特征对应的信息增益为
g(D,A)=g(D,temperature)=H(D)-H(D|A)= 0.0202555389952
2.2.1.5 计算humidity湿度特征的信息增益
计算humidity湿度特征的经验条件熵。特征A(humidity)有两个不同的取值{high,normal},v=2。根据特征的取值将数据集D划分为两个子集:
其中high的子集,有7个样本,3个打球(play=yes),4个不打球(play=no);
Normal的子集,有7个样本,6个打球(play=yes),1个不打球(play=no)。每个子集可以分别计算熵,具体公式如下:
H(D|A)=H(play|humidity)=(7/14)high熵+(7/14)*normal熵= (7/14)(-(3/7)log(3/7)-(4/7)*log(4/7)) + (7/14)(-(6/7)*log(6/7)-(1/7)*log(1/7)) =0.546512211494
所以特征humidity湿度的信息增益为:g(D,A)= g(D,humidity)=H(D)-H(D|A)= 0.105244349678
2.2.1.6 计算windy是否刮风的信息增益
计算windy是否刮风特征的经验条件熵。特征A(windy)有两个不同的取值{TRUE,FALSE},v=2。根据特征的取值将数据集D划分为两个子集:
其中TRUE的子集,有6个样本,2个打球(play=yes),4个不打球(play=no);
FALSE的子集,有8个样本,6个打球(play=yes),2个不打球(play=no)。每个子集可以分别计算熵,具体公式如下:
H(D|A)=H(play|humidity)=(6/14)TRUE熵+(8/14)*FALSE熵= (6/14)(-(2/6)log(2/6)-(4/6)*log(4/6)) + (8/14)(-(6/8)*log(6/8)-(2/8)*log(2/8)) =0.594126154766
所以特征humidity湿度的信息增益为:g(D,A)=g(D,windy)=H(D)-H(D|A)= 0.057630406407
2.2.1.7 确定root节点
对比上面四个特征的信息增益,
g(D,A)=g(D,outlook) = 0.17103394188
g(D,A)=g(D,temperature) = 0.0202555389952
g(D,A)= g(D,humidity) = 0.105244349678
g(D,A)=g(D,windy) = 0.057630406407
可以看出outlook的信息增益最大,所以选择outlook作为决策树的根节点。
特征A(天气)有三个不同的取值{sunny、overcast、rainy},即v=3,根据特征A(天气)的取值,将数据集D划分为三个子集:
其中sunny的子集中有5个样本,2个打球(play=yes),3个不打球(play=no);
Overcast的子集中有4个样本,都为打球(play=yes)
Rainy的子集中有5个样本,3个打球(play=yes),2个不打球(play=no)。
每个子集可以分别计算熵。
sunny熵= -(2/5)*log(2/5)-(3/5)*log(3/5)>0
overcast熵=-(4/4)*log(4/4)=0
rainy熵=-(3/5)*log(3/5)-(2/5)*log(2/5)>0
上面overcast熵=0,也就是这部分已经分好类了,都为打球,所以直接就可以作为叶子节点了,不需要再进行分类了。
而sunny熵、rainy熵都大于0,还需要按照上面根节点选方式继续选择特征。
2.2.1.7.1 计算outlook为sunny的数据集
No. Outlook
天气 temperature温度 humidity湿度 windy
是否有风 play
1 sunny hot high FALSE no
2 sunny hot high TRUE no
8 sunny mild high FALSE no
9 sunny cool normal FALSE yes
11 sunny mild normal TRUE yes
1、计算outlook这个分支样本的信息熵
yes打球这个分类下有2个样本,而no不打球这个分类下有3个样本,
所以信息熵H(D)=H(play)=-((2/5)*log(2/5)+(3/5)*log(3/5))= 0.673011667009
注意本文中log(x)均按照以e为底的。
2、计算temperature特征的信息增益
计算temperature特征的经验条件熵。特征A(temperature温度)有三个不同的取值{hot,mild,cool},则v=3。根据特征的取值,将数据集D划分为三个子集:
其中hot的子集中有2个样本, 2个不打球(play=no);
Mild的子集中有个2样本,1个打球(play=yes),1个不打球(play=no);
Cool的子集中有1个样本,1个打球(play=yes)。具体公式如下:
H(D|A)=H(play|temperature)=(2/5)hot熵+(2/5)*mild熵+(1/5)*cool熵 = (2/5)(-(2/2)log(2/2)) + (2/5)(-(1/2)log(1/2)-(1/2)*log(1/2)) + (1/5)( -(1/1)log(1/1))= -(2/5) log(1/2)= 0.277258872224
所以temperature温度特征对应的信息增益为
g(D,A)=g(D,temperature)=H(D)-H(D|A)= 0.395752794785
3、计算湿度特征的信息增益
计算humidity湿度特征的经验条件熵。特征A(humidity)有两个不同的取值{high,normal},v=2。根据特征的取值将数据集D划分为两个子集:
其中high的子集,有3个样本, 3个不打球(play=no);
Normal的子集,有2个样本,2个打球(play=yes)。每个子集可以分别计算熵,具体公式如下:
H(D|A)=H(play|humidity)=(3/5)high熵+(2/5)*normal熵= (3/5)(-(3/3)log(3/3)) + (2/5)(-(2/2)*log(2/2)) =0
所以特征humidity湿度的信息增益为:g(D,A)= g(D,humidity)=H(D)-H(D|A)= 0.673011667009
湿度特征划分,已经将信息熵将为0,所以我感觉就不用继续计算了,直接把湿度作为分裂的特征即可。
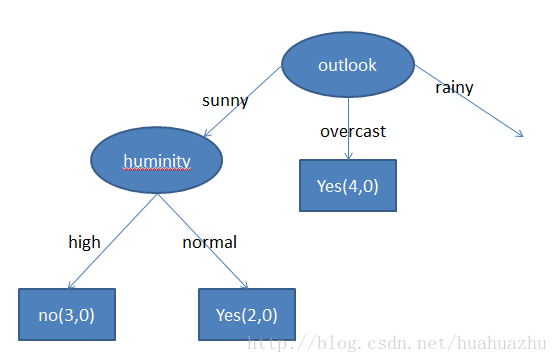
2.2.1.7.2 计算outlook为rainy的数据
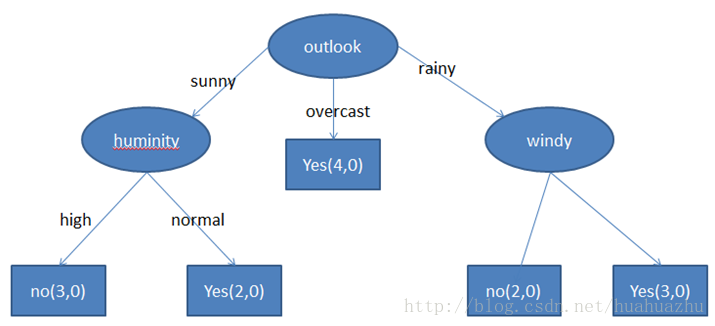
同理计算此部分数据后,最终得出的决策树如下。
2.2.2 使用C4.5算法构建决策树
C4.5使用信息增益率来进行特征选择。由于前面ID3算法使用信息增益选择分裂属性的方式会倾向于选择具有大量值的特征,如对于NO.,每条数据都对应一个play值,即按此特征划分,每个划分都是纯的(即完全的划分,只有属于一个类别),NO的信息增益为最大值1.但这种按该特征的每个值进行分类的方式是没有任何意义的。为了克服这一弊端,有人提出了采用信息增益率(GainRate)来选择分裂特征。计算方式如下:
gr(D,A)= g(D,A)/H(A),
其中g(D,A)就是ID3算法中的新增增益。
2.2.2.1 计算各特征的信息增益率
1、outlook天气特征的信息增益率
H(A)=H(outlook)= -(5/14)*log(5/14) - (5/14)*log(5/14) - (4/14)*log(4/14)= 1.09337471756
而上面已经计算了g(D,A)=g(D,outlook) = 0.17103394188
gr(D,A)=gr(play,outlook)= g(D,A)/H(A)= 0.156427562421
2、temperature温度特征的信息增益率
H(A)=H(temperature)= -(4/14)*log(4/14) - (6/14)*log(6/14) - (4/14)*log(4/14)= 1.07899220788
而上面已经计算了g(D,A)=g(D,temperature) = 0.0202555389952
gr(D,A)=gr(play,outlook)= g(D,A)/H(A)= 0.0187726462224
3、humidity湿度特征的信息增益率
H(A)=H(humidity)= -(7/14)*log(7/14) - (7/14)*log(7/14)= 0.69314718056
而上面已经计算了g(D,A)=g(D, humidity) = 0.105244349678
gr(D,A)=gr(play,humidity)= g(D,A)/H(A)= 0.151835501362
4、windy是否刮风特征的信息增益率
H(A)=H(windy)= -(8/14)*log(8/14) - (6/14)*log(6/14)= 0.6829081047
而上面已经计算了g(D,A)=g(D, windy) = 0.057630406407
gr(D,A)=gr(play, windy)= g(D,A)/H(A)= 0.0843896946168
对比上面4个特征的信息增益率,outlook天气特征的信息增益率最大,所以outlook作为root节点。其他计算方法类似。
2.3 决策树实践
2.3.1 决策树代码实现
此代码是基于ID3算法的信息增益来实现的。
from math import log
import operator
import treePlotter
import sys
reload(sys)
sys.setdefaultencoding("utf-8")
def createDataSet():
dataSet = [[1, 1, 'yes'],
[1, 1, 'yes'],
[1, 0, 'no'],
[0, 1, 'no'],
[0, 1, 'no']]
labels = ['no surfacing','flippers']
return dataSet, labels
def calcShannonEnt(dataSet):
numEntries = len(dataSet)
labelCounts = {}
for featVec in dataSet:
currentLabel = featVec[-1]
if currentLabel not in labelCounts.keys(): labelCounts[currentLabel] = 0
labelCounts[currentLabel] += 1
shannonEnt = 0.0
for key in labelCounts:
prob = float(labelCounts[key])/numEntries
shannonEnt -= prob * log(prob,2)
return shannonEnt
def splitDataSet(dataSet, axis, value):
retDataSet = []
for featVec in dataSet:
if featVec[axis] == value:
reducedFeatVec = featVec[:axis]
reducedFeatVec.extend(featVec[axis+1:])
retDataSet.append(reducedFeatVec)
return retDataSet
def chooseBestFeatureToSplit(dataSet):
numFeatures = len(dataSet[0]) - 1
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0; bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature
def majorityCnt(classList):
classCount={}
for vote in classList:
if vote not in classCount.keys(): classCount[vote] = 0
classCount[vote] += 1
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
def createTree(dataSet,labels):
classList = [example[-1] for example in dataSet]
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList)
bestFeat = chooseBestFeatureToSplit(dataSet)
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel:{}}
del(labels[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueVals = set(featValues)
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree
def classify(inputTree,featLabels,testVec):
firstStr = inputTree.keys()[0]
secondDict = inputTree[firstStr]
featIndex = featLabels.index(firstStr)
key = testVec[featIndex]
valueOfFeat = secondDict[key]
if isinstance(valueOfFeat, dict):
classLabel = classify(valueOfFeat, featLabels, testVec)
else: classLabel = valueOfFeat
return classLabel
def storeTree(inputTree,filename):
import pickle
fw = open(filename,'w')
pickle.dump(inputTree,fw)
fw.close()
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr)
if __name__ == '__main__':
fr = open('play.tennies.txt')
lenses =[inst.strip().split(' ') for inst in fr.readlines()]
lensesLabels = ['outlook','temperature','huminidy','windy']
lensesTree =createTree(lenses,lensesLabels)
treePlotter.createPlot(lensesTree)
import matplotlib.pyplot as plt
decisionNode = dict(boxstyle="sawtooth", fc="0.8")
leafNode = dict(boxstyle="round4", fc="0.8")
arrow_args = dict(arrowstyle="<-")
def getNumLeafs(myTree):
numLeafs = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
def getTreeDepth(myTree):
maxDepth = 0
firstStr = myTree.keys()[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth: maxDepth = thisDepth
return maxDepth
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args )
def plotMidText(cntrPt, parentPt, txtString):
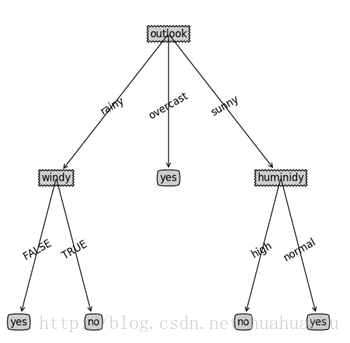
代码执行:直接执行tree.py即可。画出的决策树的图如下:
2.3.2 使用sckit-learn实现决策树
使用sckit-learn机器学习算法包来实现上面的打网球例子代码如下
import numpy as np
from sklearn import tree
from sklearn.model_selection import train_test_split
import pydotplus
def outlook_type(s):
it = {'sunny':1, 'overcast':2, 'rainy':3}
return it[s]
def temperature(s):
it = {'hot':1, 'mild':2, 'cool':3}
return it[s]
def humidity(s):
it = {'high':1, 'normal':0}
return it[s]
def windy(s):
it = {'TRUE':1, 'FALSE':0}
return it[s]
def play_type(s):
it = {'yes': 1, 'no': 0}
return it[s]
play_feature_E = 'outlook', 'temperature', 'humidity', 'windy'
play_class = 'yes', 'no'
data = np.loadtxt("play.tennies.txt", delimiter=" ", dtype=str, converters={0:outlook_type, 1:temperature, 2:humidity, 3:windy,4:play_type})
x, y = np.split(data,(4,),axis=1)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)
clf = tree.DecisionTreeClassifier(criterion='entropy')
print(clf)
clf.fit(x_train, y_train)
dot_data = tree.export_graphviz(clf, out_file=None, feature_names=play_feature_E, class_names=play_class,
filled=True, rounded=True, special_characters=True)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf('play1.pdf')
print(clf.feature_importances_)
answer = clf.predict(x_train)
y_train = y_train.reshape(-1)
print(answer)
print(y_train)
print(np.mean(answer == y_train))
answer = clf.predict(x_test)
y_test = y_test.reshape(-1)
print(answer)
print(y_test)
print(np.mean(answer == y_test))
运行结果:
DecisionTreeClassifier(class_weight=None, criterion='entropy', max_depth=None,
max_features=None, max_leaf_nodes=None,
min_impurity_split=1e-07, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=None, splitter='best')
[ 0.45572593 0. 0.36381472 0.18045935]
['0' '1' '0' '1' '0' '0' '1' '1' '1']
['0' '1' '0' '1' '0' '0' '1' '1' '1']
1.0
['0' '1' '1' '1' '1']
['0' '1' '1' '1' '1']
1.0
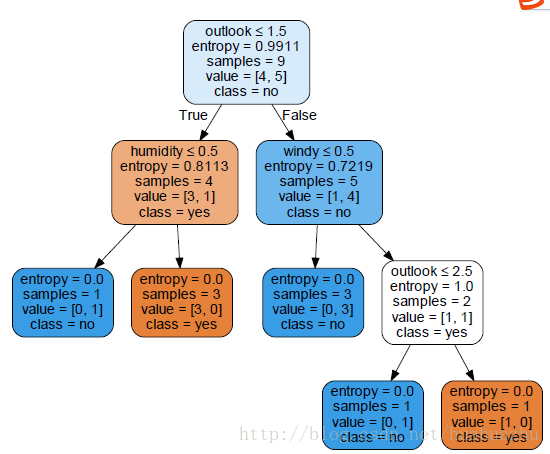
输出的pdf格式的图如下:
转载自https://blog.csdn.net/huahuazhu/article/details/73167610](https://blog.csdn.net/huahuazhu/article/details/73167610)









 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)